
7장 성능 및 비용 최적화(3)
이어서 계속
성능 최적화의 기본 원칙
- 앞에서 쿼리 성능을 높이는 방법을 논의했지만, 테이블의 레이아웃이나 저장 위치, 접근 방법 등은 변경하지 않는 방법만 다뤘다. 여기서는 이런 요인을 다루는 것이 쿼리 성능에 어떤 극적인 영향을 미칠 수 있는지 나온다.
네트워크 오버헤드 최소화하기
- 빅쿼리는 전 세계적으로 접근이 가능한 서비스다.
- 구글 클라우드 스토리지 또는 클라우드 펍/섭 등의 GCP 리소스와 함께 작업할 때 데이터셋을 동일 리전에 배치하면 최적의 성능을 얻을 수 있다.
압축한 부분 응답
- REST API를 직접 호출할 때 압축한 부분 응답을 승인해 네트워크 오버헤드를 최소화할 수 있다.
- 압축한 부분 응답을 수락하려면 HTTP 헤더에서 gzip을 수락하도록 지정하고 사용자 에이전트 이름에 'gzip' 문자열이 나타나는지 확인한다.
여러 요청 일괄 처리하기
- 대용량의 데이터셋을 판다스 데이터 프레임에 로드하려면 빅쿼리 API가 아닌 스토리지 API를 사용해서 데이터를 판다스 데이터 프레임에 로드하는 옵션을 매직 커맨드에 지정할 수 있다.
- 우선, 스토리지 API 파이썬 클라이언트 라이브러리를 아브로 및 판다스 지원버전을 설치해야한다.
- 주피터에서는 다음 방법으로 설치할 수 있다.
%pip install google-cloud-bigquery-storage[fastavro, pandas]- 이후 %%bigquery 매직 커맨드를 사용하면 된다. 단, 다음과 같이 스토리지 API 옵션을 추가한다.
%%bigquery df --use_bqstorage_api --project $PROJECT
SELECT
start_station_name
, end_station_name
, start_date
, duration
FROM `bigquery-public-data`.london_bicycles.cycle_hire- 쿼리에 의해 반환되는 데이터 양이 작으면 매직 커맨드는 자동으로 빅쿼리 API를 대신 사용한다. 따라서 노트북 셀에서는 항상 이 플래그를 사용해도 문제가 되지 ㅇ낳는다.
- 노트북 세션 내의 모든 매직 셀에서 --use_bqstorage_api를 기본적으로 활성화하려면 컨텍스트 플래그를 설정한다.
import google.cloud.bigquery.magics
google.cloud.bigquery.magics.context.use_bqstorage_api = True효율적인 저장 포맷 선택하기
- 쿼리 성능은 테이블 데이터가 저장되는 위치와 형식에 따라 달라진다.
- 내부 데이터 소스와 외부 데이터 소스의 비교
- 빅쿼리는 구글 클라우드 스토리지, 클라우드 빅테이블, 구글 시트 같은 외부 소스에 대한 직접 쿼리를 지원하지만, 네이티브 테이블(?)을 사용하면 가장 빠른 쿼리 성능을 얻을 수 있다.
- 구글 클라우드 스토리지에서 데이터를 쿼리해야 할 때는 가능하면 압축된 컬럼 형식(예를 들면 파케이)으로 저장한다, JSON 또는 CSV 같은 행 기반 형식은 마지막 수단으로 사용한다.
- 스테이징 버킷에서 수명 주기 관리 설정하기
- 데이터를 구조체의 배열로 저장하기
- 지리타입으로 데이터 저장하기
스캔 크기를 줄이기 위해 테이블 파티셔닝하기
SELECT
start_station_name
, AVG(duration) AS avg_duration
FROM `bigquery-public-data`.london_bicycles.cycle_hire
WHERE EXTRACT(YEAR FROM start_date) = 2015
GROUP BY start_station_name
ORDER BY avg_duration DESC
LIMIT 5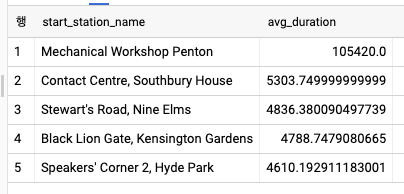
- 위의 쿼리와 결과는 2015년에 해당하는 값을 찾기 위해 전체 테이블을 읽어야 한다. 아에서는 처리 중인 데이터의 크기를 줄일 수 있는 다양한 방법이 나온다.
- 안티 패턴 : 테블 접미사 및 와일드 카드
- 연도별 필터링이 매우 일반적일 때, 읽고 있는 데이터를 줄이는 한가지 방법은 접미사를 각 테이블의 이름에 붙여 여러 테이블에 데이터를 저장하는 것이다.
- 이 방법으로 2015년의 데이터를 쿼리할 때 모든 행을 읽을 필요 없이 cycle_hire_2015 테이블만 읽으면 된다.
CREATE OR REPLACE TABLE test AS (
SELECT * FROM `bigquery-public-data`.london_bicycles.cycle_hire
WHERE EXTRACT(YEAR FROM start_date) = 2015
)
- 1년치의 데이터만 활용해서 테이블을 새로 만듬
SELECT
start_station_name
, AVG(duration) AS avg_duration
FROM ch07eu.cycle_hire_2015
GROUP BY start_station_name
ORDER BY avg_duration DESC
LIMIT 5- 와일드 카드 및 테이블 접미사를 사용해 여러 해를 검색하는 것도 가능하다.
SELECT
start_station_name
, AVG(duration) AS avg_duration
FROM `ch07eu.cycle_hire_*`
WHERE _TABLE_SUFFIX BETWEEN '2015' AND '2016'
GROUP BY start_station_name
ORDER BY avg_duration DESC
LIMIT 5- 파티션을 나눈 테이블 *
-
파티션을 나눈 테이블을 사용하면 모든 관련 데이터를 단일 논리 테이블에 저장하면서도 해당 데이터의 하위 집합을 효율적으로 쿼리할 수 있다.
-
예를 들어 지난 해 데이터의 전체를 저장하고 있지만, 대부분 지난주의 데이터만 쿼리하는 경우, 데이터를 시간별로 분할하면 지난 7일 분량의 파티션만 스캔해야 하는 쿼리를 실행할 수 있다. 이렇게 하면 쿼리 비용, 슬록 활용도 및 시간 면에서 비용을 절감할 수 있다.
-
파티션을 나눈 테이블은 빅쿼리가 관리하는 파티션으로 분할된 특별 테이블이다. 다음을 사용해 런던 cycle_hire 데이터 셋의 파티션 버전을 생성할 수 있다.
CREATE OR REPLACE TABLE ch07eu.cycle_hire_partitioned
PARTITION BY DATE(start_date) AS
SELECT * FROM `bigquery-public-data`.london_bicycles.cycle_hire- 그런 다음 2015년에 평균 대여 시간이 가장 긴 대여소를 찾으려면 파티션을 나눈 테이블을 쿼리해 필터 절에서 파티션 컬럼(start_date)을 사용해야 한다.
SELECT
start_station_name
, AVG(duration) AS avg_duration
FROM ch07eu.cycle_hire_partitioned
WHERE start_date BETWEEN '2015-01-01' AND '2015-12-31'
GROUP BY start_station_name
ORDER BY avg_duration DESC
LIMIT 5
-- 위의 쿼리는 start_date 컬럼을 읽어야 하므로 연도별로 샤딩한 테이블보다 조금 더 많은 데이터를 처리한다.
SELECT
start_station_name
, AVG(duration) AS avg_duration
FROM ch07eu.cycle_hire_partitioned
WHERE EXTRACT(YEAR FROM start_date) = 2015
GROUP BY start_station_name
ORDER BY avg_duration DESC
LIMIT 5
-- 이와 같은 구성은 단점이 존재한다. 처리해야할 데이터가 늘어나 절감 효과가 없다.
-- 파티셔닝의 이점을 얻으러면 빅쿼리 런타임이 파티션 필터를 정적으로 판별할 수 있어야 한다.- 빅쿼리에 날짜/시간 컬럼이 아닌 처리 시간을 기준으로 테이블을 자동으로 분할하도록 요청할 수 있다. 이렇게 하려면 _PARTITIONTIME 또는 _PARTITIONDATE를 파티션 컬럼으로 사용한다.
- 이것들은 수집 시간을 나타내며 실제로 데이터셋에 존재하지 않는 의사(pseudo) 컬럼이다. 그러나 쿼리에서 이런 의사 컬럼을 사용해서 스캔되는 행을 제한할 수 있다.
높은 카디널리티 키에 기반한 클러스터링 테이블
(카디널리티란 카디널리티는 전체 행에 대한 특정 컬럼의 중복 수치를 나타내는 지표이다.)
- 파티셔닝과 마찬가지로 클러스터링은 쿼리 시 적은 양의 데이터를 읽을 수 있는 방식으로 빅쿼리에 데이터를 저장하는 방법이다.
- 분할된 테이블은 여러 개의 독립 테이블(파티션당 하나)과 유사하게 작동하지만, 클러스터링된 테이블은 정렬된 형식을 단일 테이블로 저장한다.
- 이렇게 데이터가 정렬되어 있으면 성능 저하 없이 무제한의 고유한 값을 저장할 수 있으며 필터를 적용할때 빅쿼리가 요청된 값의 범위를 포함하지 않는 파일을 열지 않고 건너 뛸 수 있다.
- 클러스터링은 반복되지 않으며 기본 데이터 타입(INT64, BOOL, NUMERIC, STRING, DATE, GEOGRAPHY 및 TIMESTAMP)을 가진 컬럼에서 수행할 수 있다.
- 일반적으로 수백만 명의 고객이 있는 경우 customerID 컬럼처럼 고윳값이 매우 많은 컬럼을 클러스터링한다. 카디널리티가 높지 않지만 자주 사용되는 컬럼이 있다면 한 번에 2개 이상의 컬럼으로 클러스터링할 수도 있다.
- 여러 컬럼으로 클러스터링하면 클러스터링 컬럼의 접두사로 필터링해서 클러스터링의 이점을 실현할 수 있다.
-- 클러스터링된 테이블을 생성하는 쿼리
CREATE OR REPLACE TABLE ch07eu.cycle_hire_clustered
PARTITION BY DATE(start_date)
CLUSTER BY start_station_name, end_station_name
AS (
SELECT * FROM `bigquery-public-data`.london_bicycles.cycle_hire
)- 파티션 컬럼으로 클러스터링 하기
-
파티션을 나눈 테이블을 날짜 컬럼이나 수집 시간을 기준으로 날짜별로 파티션된다. 시(hour)를 기준으로 분할해야 한다면, 사용할 수 있는 방법은 날짜를 기준으로 파티셔닝한 다음 적절한 다른 속성과 함께 시별로 클러스터링하는 것이다.
-
따라서 일반적인 패턴은 파티션 기준과 동일한 컬럼을 기준으로 클러스터링 하는 것이다. 예를 들어 로그 이벤트가 발생하는 타임스탬프인 event_time 컬럼으로 파티션을 나누면 파티셔닝에 사용된 날짜 경계보다 작은 임의의 기간에 대해 매우 빠르고 효율적인 쿼리를 수행할 수 있다. 예전대, 10분 동안의 데이터만 쿼리하며 그보다 오래된 데이터는 스캔할 필요 없다.
- 재클러스터링
- 빅쿼리는 클러스터된 테이블에서 클러스터링 컬럼의 값을 기준으로 데이터를 정렬하며, 불필요한 데이터를 효율적으로 스캔하고 삭제하기 위해 최적의 크기로 구성된 스토리지 블록으로 구성한다.
- 그러나 파티셔닝과 달리 빅쿼리는 데이터가 스트리밍될 때 클러스터 내에서 데이터 정렬을 유지하지 않는다. 빅쿼리는 효율적인 데이터 정리 및 스캔 속도를 유지하기 위해 주시적으로 데이터를 재클러스터링한다.
- 클러스터링의 부가적인 장점
- 빅쿼리는 클러스터링된 테이블을 읽을 때 데이터 읽기를 방지하는 모든 최적화를 수행한다. 따라서 클러스터 테이블에서 SELECT * ... LIMIT 10을 수행하면 10행이 반환되는 즉시 실행 엔진이 데이터 읽기를 중지할 수 있다.
- 다만 쿼리 엔진이 여러 병렬 워커를 사용하는 방식으로 인해 어떤 최적화가 먼저 완료될지 모르므로 검색되는 데이터의 양은 결정적이지 않다.
- 좋은 점은 큰 테이블에서 훨씬 적은 비용으로 쿼리를 실행할 수 있다는 점이다.
- '조기 중지' 비용 절감의 놀라운 부수 효과는 클러스터링 컬럼을 필터링하지 않아도 성능 이점을 누릴 수 있다는 것이다.
