모델 평가란?
- 모델의 일반화 성능을 개선하려면 당연히 그 모델의 일반화 성능을 알 수 있는 방법이 필요하다.
검증 방법
- 홀드아웃 검증
# 홀드아웃(hold-out)방법
# -----------------------------------
# 홀드아웃(hold-out)방법으로 검증 데이터의 분할
from sklearn.model_selection import train_test_split
# train_test_split()함수를 이용한 홀드아웃 방법으로 분할
tr_x, va_x, tr_y, va_y = train_test_split(train_x, train_y,
test_size=0.25, random_state=71, shuffle=True)
# -----------------------------------
# 홀드아웃(hold-out)방법으로 검증을 수행
from sklearn.metrics import log_loss
from sklearn.model_selection import train_test_split
# Model 클래스를 정의
# Model 클래스는 fit으로 학습하고 predict로 예측값 확률을 출력
# train_test_split 함수를 이용하여 홀드아웃 방법으로 분할
tr_x, va_x, tr_y, va_y = train_test_split(train_x, train_y,
test_size=0.25, random_state=71, shuffle=True)
# 학습 실행, 검증 데이터 예측값 출력, 점수 계산
model = Model()
model.fit(tr_x, tr_y, va_x, va_y)
va_pred = model.predict(va_x)
score = log_loss(va_y, va_pred)
print(score)
# -----------------------------------
# KFold 클래스를 이용하여 홀드아웃 방법으로 검증 데이터를 분할
from sklearn.model_selection import KFold
# KFold 클래스를 이용하여 홀드아웃 방법으로 분할
kf = KFold(n_splits=4, shuffle=True, random_state=71)
tr_idx, va_idx = list(kf.split(train_x))[0]
print(tr_idx, va_idx)
tr_x, va_x = train_x.iloc[tr_idx], train_x.iloc[va_idx]
tr_y, va_y = train_y.iloc[tr_idx], train_y.iloc[va_idx]- 교차 검증
# 교차 검증 방법으로 데이터 분할
from sklearn.model_selection import KFold
# KFold 클래스를 이용하여 교차 검증 분할을 수행
kf = KFold(n_splits=4, shuffle=True, random_state=71)
for tr_idx, va_idx in kf.split(train_x):
tr_x, va_x = train_x.iloc[tr_idx], train_x.iloc[va_idx]
tr_y, va_y = train_y.iloc[tr_idx], train_y.iloc[va_idx]
# 교차 검증을 수행
from sklearn.metrics import log_loss
from sklearn.model_selection import KFold
# Model 클래스를 정의
# Model 클래스는 fit으로 학습하고, predict로 예측값 확률을 출력
scores = []
# KFold 클래스를 이용하여 교차 검증 방법으로 분할
kf = KFold(n_splits=4, shuffle=True, random_state=71)
for tr_idx, va_idx in kf.split(train_x):
tr_x, va_x = train_x.iloc[tr_idx], train_x.iloc[va_idx]
tr_y, va_y = train_y.iloc[tr_idx], train_y.iloc[va_idx]
# 학습 실행, 검증 데이터의 예측값 출력, 점수 계산
model = Model()
model.fit(tr_x, tr_y, va_x, va_y)
va_pred = model.predict(va_x)
score = log_loss(va_y, va_pred)
scores.append(score)
# 각 폴더의 점수 평균을 출력
print(np.mean(scores))- 층화 k-겹 검증
- 분류 문제에서 폴드마다 포함되는 클래스의 비율을 서로 맞출 때가 자주 있는데 이것을 층화추출(startified sampling)이라고 부른다.
- 테스트 데이터에 포함되는 각 클래스의 비율은 학습 데이터에 포함되는 각 클래스의 비율과 거의 같을 거라는 가정에 근거하여 검증의 평가를 안정화하려는 방법이다. 특히 다중 클래스 분류에서 극단적으로 빈도가 적은 클래스가 있을때, 랜덤으로 분할했을 때는 각 클래스의 비율이 달라져 평가의 불균형이 커질 가능성이 있으므로 층화추출을 하는 게 중요하다.
- 반대로 이진 분류에서 양성과 음성 중 어느 하나에 치우치지 않을 때는 클래스의 비율에 별로 영향이 없으므로 층화추출을 사용하지 않아도 된다.
from sklearn.model_selection import StratifiedKFold
# StratifiedKFold 클래스를 이용하여 층화추출로 데이터 분할
kf = StratifiedKFold(n_splits=4, shuffle=True, random_state=71)
for tr_idx, va_idx in kf.split(train_x, train_y):
tr_x, va_x = train_x.iloc[tr_idx], train_x.iloc[va_idx]
tr_y, va_y = train_y.iloc[tr_idx], train_y.iloc[va_idx]- 그룹 k-겹 검증
- 상황에 따라 학습 데이터와 테스트 데이터가 랜덤으로 분할되지 않을 때도 있다.
- 예를 들어 각 고객에게 여러 행동 이력이 있고 각각의 행동을 예측하는 문제일 때는 고객 단위로 데이터가 분할되는 경우가 많다. 즉, 학습 데이터와 테스트 데이터에 동일한 고객 데이터가 포함되지 않도록 분할한다.
- sklearn에는 GroupFold ㅡㅋㄹ래스가 준비되어 있으나 분할을 섞는 기능과 분할의 난수 시드를 정하는 기능이 없어서 사용하기 어렵다.
from sklearn.model_selection import KFold, GroupKFold
# user_id열의 고객 ID 단위로 분할
user_id = train_x['user_id']
unique_user_ids = user_id.unique()
# KFold 클래스를 이용하여 고객 ID 단위로 분할
scores = []
kf = KFold(n_splits=4, shuffle=True, random_state=71)
for tr_group_idx, va_group_idx in kf.split(unique_user_ids):
# 고객 ID를 train/valid(학습에 사용하는 데이터, 검증 데이터)로 분할
tr_groups, va_groups = unique_user_ids[tr_group_idx], unique_user_ids[va_group_idx]
# 각 샘플의 고객 ID가 train/valid 중 어느 쪽에 속해 있느냐에 따라 분할
is_tr = user_id.isin(tr_groups)
is_va = user_id.isin(va_groups)
tr_x, va_x = train_x[is_tr], train_x[is_va]
tr_y, va_y = train_y[is_tr], train_y[is_va]
# (참고)GroupKFold 클래스에서는 셔플과 난수 시드를 지정할 수 없으므로 사용하기 어려움
kf = GroupKFold(n_splits=4)
for tr_idx, va_idx in kf.split(train_x, train_y, user_id):
tr_x, va_x = train_x.iloc[tr_idx], train_x.iloc[va_idx]
tr_y, va_y = train_y.iloc[tr_idx], train_y.iloc[va_idx]- LOO 검증
- 데이터가 적으면 가능한 한 많은 데이터를 사용하려 하고 학습에 걸리는 연산 시간도 짧으므로 폴드 수를 늘리는 방법을 고려할 수 있다.
- 가장 극단적일 때는 폴드 수가 학습 데이터의 행위수와 동일하며 검증 데이터는 각각 1건이다. 이 방법을 LOO(leave-one-out)검증이라고 한다.
from sklearn.model_selection import LeaveOneOut
loo = LeaveOneOut()
for tr_idx, va_idx in loo.split(train_x):
tr_x, va_x = train_x.iloc[tr_idx], train_x.iloc[va_idx]
tr_y, va_y = train_y.iloc[tr_idx], train_y.iloc[va_idx]-
추가로, LOO 검증의 경우 GBDT나 신경망과 같이 순서대로 학습을 진행하는 모델에서 조기 종료를 사용하면 검증 데이터에 가장 최적의 포인트에서 학습을 멈출 수 있어 모델의 성능이 과대 평가된다.
-
LOO 검증이 아니더라도 폴드 수가 많아지면 과적합 문제가 발생할 수 있다. 대처 방법 중 하나로는 각 폴드에서 한 번 조기 종료하고, 그 평군 등으로부터 적절한 반복수의 견적을 낸 뒤에 해당 반복 수를 고정하고 다시 교차 검증을 실행하는 방법이 있다.
시계열 데이터의 검증 방법
- 학습 데이터에는 테스트 데이터와 같은 기간의 데이터가 포함되어 있지 않다. 이러한 경우는 주의 깊게 검증해야 한다.
- 시계열 데이터에서는 시간상 비슷한 데이터가 섞이면 예측하기 쉬워져 모델의 성능을 과대 평가할 위험성이 커지므로 주의해야 한다.
- 시계열 데이터의 홀드아웃 검증
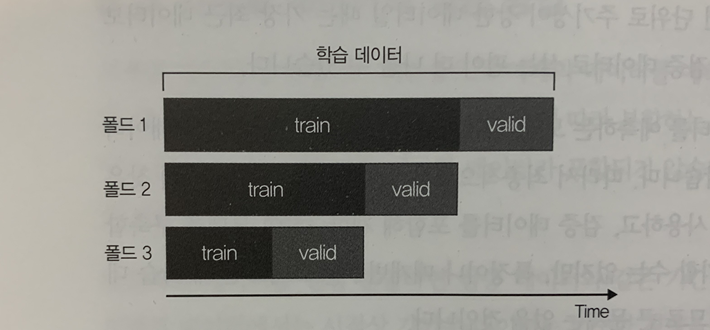
- 가장 간단한 방법은 아래의 이미지처럼 학습 데이터 중에 테스트 데이터와 가장 가까운 기간을 검증 데이터로 삼는 방법이다. 시계열에 따른 홀드아웃 검증이라고 할 수 있다.

-
다만 데이터가 주기성을 갖는다면 데이터 나눌 때 이를 고려해야한다. 예를 들면 1년 단위로 주기성이 강한 데이터일 때는 가장 최근 데이터보다 테스트 데이터의 1년 전 기간을 검증 데이터로 삼는 편이 나을 수 있다.
-
이 방법은 홀드아웃 검증의 응용이므로 마찬가지로 데이터를 유효하게 사용하지 못한다는 단점이 있다. 검증 데이터는 어느 기간으로 한정되는 만큼 그 밖의 기간을 적절히 예측할 수 있는 모델인지 여부를 확인하기 어렵고, 단순히 검증 데이터의 수가 부족하여 결과가 안정되지 않을 수도 있다.
- 시계열 데이터의 교차 검증(1)
- 시계열 데이터의 홀드아웃 검증의 단점을 해결하는 방법으로 교차 검증의 개념을 도입한 방법이 있다. 아래의 이미지와 같이 시계열에 따라 데이터를 분할한 뒤 학습 데이터와 검증 데이터의 시간적인 관계성을 유지하면서 평가를 반복하는 방법이다.
- 이러한 시계열에 따른 분할 방법에는 시점의 근접성 외에 시간적인 순서에도 주의한다.
- 각 폴드에서 학습 데이터 기간은 제공된 학습 데이터의 가장 처음부터 지정할 수도 있고 검증 데이터 직전의 1년간으로 지정할 수도 있다. 제공된 학습 데이터의 처음부터 지정할 때는 폴드마다 학습 데이터의 길이가 다르다는 점을 유의해야 한다.
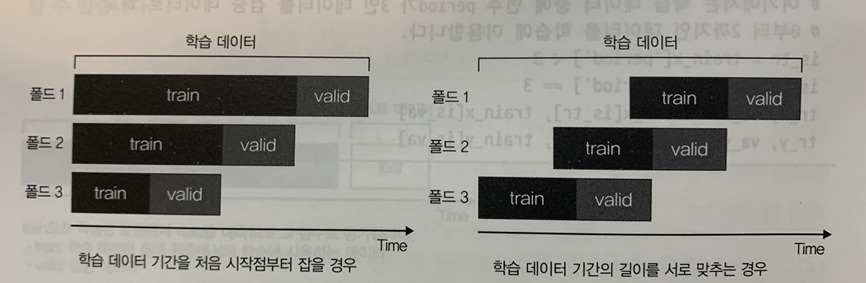
- 이 방법에서 우려되는 문제는 일정 시점 이상의 오래된 데이터를 검증 데이터로 삼으면 해당 검증 데이터보다 과거의 학습 데이터만 쓸 수 있는 만큼 실제로 사용할 데이터가 적어진다는 점이다. 학습 데이터가 적은 부분의 검증 점수는 참고가 되지 않으므로 어딘가에서 중단해야 한다. 또한 오래된 데이터는 테스트 데이터와 성질이 달라 참고가 되지 않을 수도 있다.
# 변수 period를 기준으로 분할(0부터 2까지가 학습 데이터, 3이 테스트 데이터)
# 변수 period가 1, 2, 3의 데이터를 각각 검증 데이터로 하고 그 이전 데이터를 학습에 사용
va_period_list = [1, 2, 3]
for va_period in va_period_list:
is_tr = train_x['period'] < va_period
is_va = train_x['period'] == va_period
tr_x, va_x = train_x[is_tr], train_x[is_va]
tr_y, va_y = train_y[is_tr], train_y[is_va]
# (참고)periodSeriesSplit의 경우, 데이터 정렬 순서밖에 사용할 수 없으므로 쓰기 어려움
from sklearn.model_selection import TimeSeriesSplit
tss = TimeSeriesSplit(n_splits=4)
for tr_idx, va_idx in tss.split(train_x):
tr_x, va_x = train_x.iloc[tr_idx], train_x.iloc[va_idx]
tr_y, va_y = train_y.iloc[tr_idx], train_y.iloc[va_idx]- 시계열 데이터의 교차 검증(2)
- 데이터에 따라서는 행 데이터의 시간적인 전후 관계보다는 행 데이터 간의 시간상 가까운 정도에만 주의해도 충분할 때가 있다. 그런 경우 검증데이터보다 미래의 데이터를 학습 데이터에 포함해도 문제가 없으므로 아래와 같이 단순히 시간상으로 구분해 분할하는 방법을 채택할 수 있다.
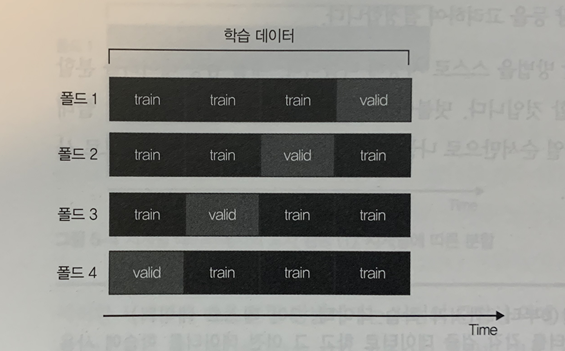
- 시계열에 따라 실행하는 방법과의 차이점은 검증 데이터 이전의 데이터가 아닌, 검증 데이터 이외의 학습 데이터 전체를 사용한다는 점이다.
- 주의점
- 시계열 데이터에서는 문제의 설계나 데이터의 성질, 분할되는 방법에 따라 수행할 검증이 달라진다.
- 또한 검증 방법뿐만 아니라 특징 생성도 주의해야 한다. 테스트 데이터에 이용할 수 있는 정보가 무엇인지를 의식하고 검증 데이터에 대해서도 종합적인 조건으로 특징을 생성하지 않으면 해당 데이터에만 유리한 검증이 되므로 올바르게 평가할 수 없다.
참고 : 데이터가 뛰어노는 AI 놀이터, 캐글

데이터 분석하고 있습니다