Reversible Instance Normalization (1)
이 논문에서는 시계열 데이터에 대한 새로운 정규화 기법인 Reversible Instance Normalization (RevIN)을 제안한다. RevIN은 기존 인스턴스 정규화 기법을 기반으로 하지만, 역정규화 단계를 추가하여 모델 출력에서 원래 데이터 분포를 복원할 수 있게 한다.
기존에는 전역 정규화 혹은 모델 자체적 분포 학습에 의존했지만, RevIN은 인스턴스 단위 정규화/역정규화로 문제를 직접 다룰 수 있음
입출력층에 정규화/역정규화 연산을 추가하는 방식으로 적용할 수 있음
작동 원리
1) 입력 데이터 x를 인스턴스 평균과 분산으로 정규화하여 xhat을 얻는다.
입력층에서 정규화:
- 각 시계열 인스턴스 x(i)에 대해 평균 E[x(i)]와 분산 Var[x(i)] 계산
- 이를 이용해 인스턴스 정규화를 수행하여 xhat(i) 얻기
- xhat(i) = γ * ((x(i) - E[x(i)]) / sqrt(Var[x(i)] + ε)) + β
- 이 때, γ, β : learnable한 affine 변환 파라미터
2) 모델이 정규화된 xhat을 입력받아 예측값 y_tilde를 출력
3) 모델 출력 y_tilde를 역정규화하여 원래 데이터 분포로 되돌린다
- 이렇게 하면 입력에서 제거된 평균, 분산 정보가 출력에 다시 더해짐
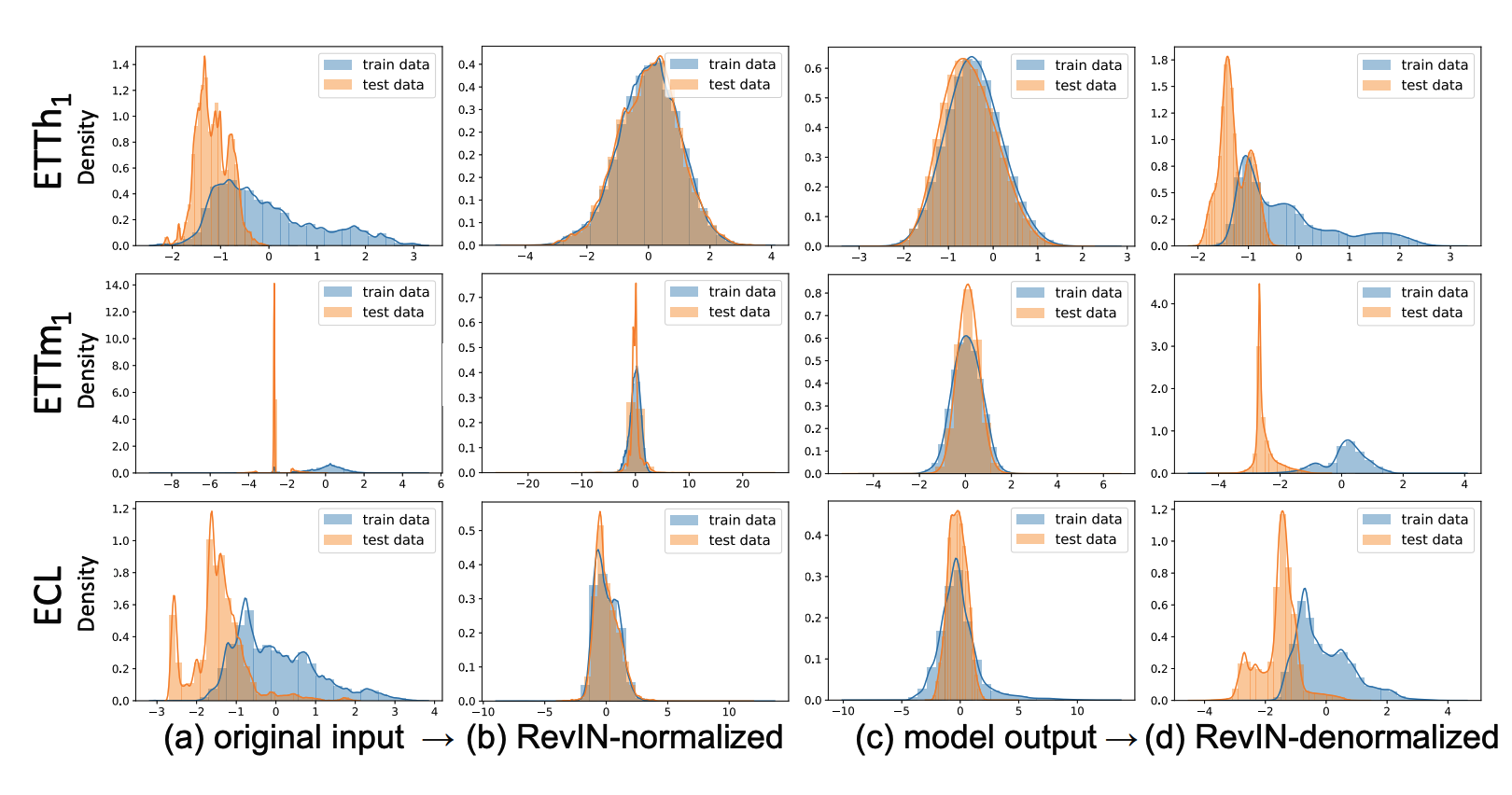
효과
- 입력 정규화로 분포 차이를 줄여 보정된 데이터를 다루게 되어 모델 학습 용이
- 출력 역정규화로 원래 데이터 분포 특성을 복원할 수 있음
- 결과적으로 시계열 예측 성능이 크게 향상됨
- 입력 정규화로 서로 다른 시계열 인스턴스 간 분포 차이 줄일 수 있음
기존 방법과의 차이점:
- 기존에는 입력 전처리로 전역 정규화를 사용하거나 모델이 직접 원래 분포를 학습해야 했다
- RevIN은 입력과 출력 층에 인스턴스 정규화/역정규화를 적용하여 훈련을 쉽게 하고도 원래 분포를 복원할 수 있다
- 이를 통해 시계열 데이터의 분포 변화 문제를 효과적으로 해결할 수 있다
Reference
Reversible Instance Normalization for Accurate Time-Series Forecasting against Distribution Shift

사실천재