시계열 분류를 위한 심층 반지도 학습 Deep Semi-supervised Learning for Time-Series Classification
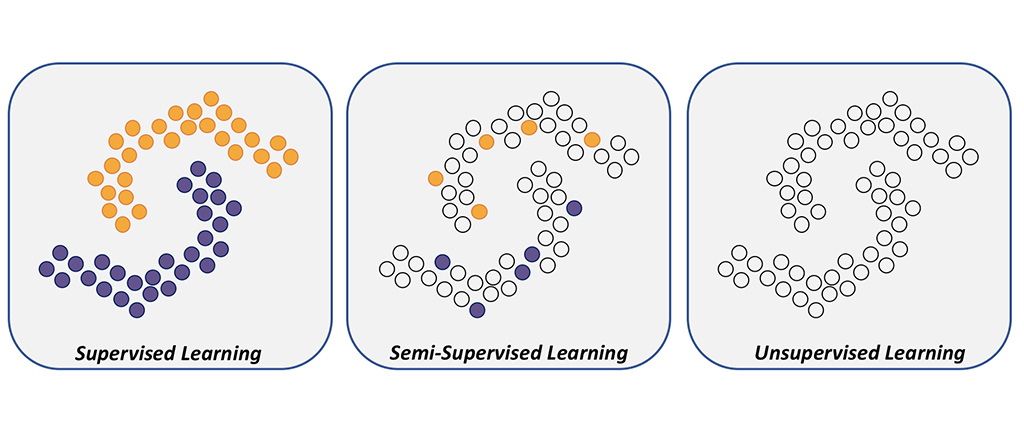
반지도 학습 : 학습 데이터 중 일부는 라벨링이 되어 있고, 나머지는 라벨링이 되어 있지 않은 상태. 이를 통해 라벨링된 데이터가 부족한 상황에서도 모델을 효과적으로 학습시킬 수 있다.
반지도 학습 예시
-
이미지 분류
- 예시: 고양이와 개를 분류하는 모델
- 라벨링된 데이터: {고양이 사진 100장 : '고양이', 개 사진 100장: '개'}
- 라벨링되지 않은 데이터: 1000장의 사진이 있지만 어떤 사진이 고양이인지 개인지 라벨이 없다.
- 활용: 라벨링된 200장의 사진과 라벨링되지 않은 1000장의 사진을 함께 사용하여 반지도 학습 모델을 학습. 모델은 라벨링 데이터를 통해 기본적인 분류 능력을 학습하고, 라벨되지 않은 데이터를 통해 더 많은 특징을 학습하여 성능을 향상시킨다.
- 예시: 고양이와 개를 분류하는 모델
-
텍스트 분류
- 예시: 긍정/부정 리뷰를 분류하는 모델
- 라벨된 데이터: 500개 긍정 리뷰 + 500개 부정 리뷰 라벨링
- 라벨되지 않은 데이터: 5000개의 리뷰가 있지만, 긍정인지 부정인지 라벨이 없다.
- 활용: 라벨된 1000개의 리뷰와 라벨되지 않은 5000개의 리뷰를 함께 사용하여 모델을 학습합니다. 모델은 라벨된 데이터에서 기본적인 분류를 학습하고, 라벨되지 않은 데이터에서 추가적인 패턴을 학습합니다.
- 예시: 긍정/부정 리뷰를 분류하는 모델
-
시계열 데이터
- 예시: 특정 제품의 판매량을 예측하는 모델
- 라벨링 데이터: 1년치의 일별 판매량 데이터가 라벨링 되어 있다.
- 라벨링되지 않은 데이터: 추가적으로 5년치의 일별 데이터가 있지만 라벨이 없다.
- 활용: 1년치 라벨된 데이터와 5년치 라벨되지 않은 데이터를 함께 사용하여 모델을 학습. 모델은 라벨링 데이터를 통해 기본적인 패턴을 학습하고, 라벨되지 않은 데이터를 통해 더 많은 시계열 패턴을 학습한다.
- 예시: 특정 제품의 판매량을 예측하는 모델
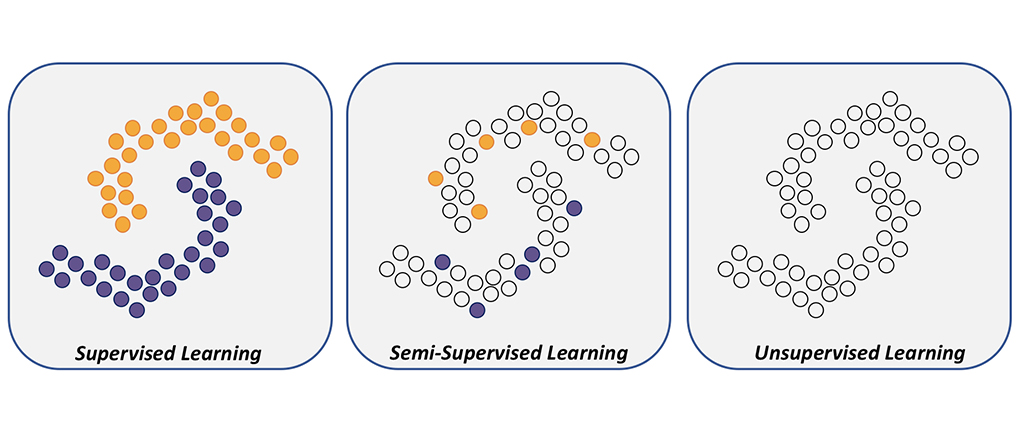
그림1. 지도학습, 준지도학습, 비지도학습 [1]
반지도 학습의 장점
- 라벨링 비용 절감: 라벨링 작업은 시간과 비용이 많이 들기 때문에, 일부 데이터만 라벨링하고 나머지는 라벨링 없이도 학습할 수 있다.
- 더 나은 성능: 분류되지 않은 데이터를 활용함으로써 더 많은 정보를 학습할 수 있어 모델 성능 향상
주요 기술
- Pseudo-Labeling: 모델이 라벨되지 않은 데이터에 대해 예측한 라벨을 사용하여 추가 학습 수행
- Consistency Regularization: 모델이 라벨되지 않은 데이터에 대해 일관된 예측을 할 수 있도록 학습
- MixMatch: 여러 반지도 학습 기법을 결합하여 사용하는 방법
논문 요약
연구 목적
이미지 분류에서 사용되는 반지도 학습(semi-supervised learning, SSL) 모델을 시계열 분류에 적용할 수 있는지를 조사하고, 필요한 모델 적응 및 데이터 증강 전략 논의
주요 내용
- 모델 적응: 이미지에서 시계열로 도메인 전환에 맞추어 MixMatch, Virtual Adversarial Training (VAT), Mean Teacher, Ladder Net와 같은 주요 SSL 모델을 조정. 백본 아키텍처(fully convolutional network, FCN)를 사용하고 시계열 데이터에 맞춘 데이터 증강 전략 포함.
- 실험 평가: 대규모 공개 시계열 분류 문제를 사용하여 제안된 방법을 평가. 이를 통해 레이블된 샘플이 매우 적은 시나리오에서 SSL 모델이 기존의 강력한 지도 학습 및 반지도 학습 모델보다 성능이 크게 향상됨을 발견.
- 통합 구현 및 비교: SSL 모델을 통합 재구현하고, 엄격한 평가 체계 하에서 다양한 알고리즘 비교함. 시계열 분류 분야에서 아직 부족한 부분이기에 의미 있는 연구
배경 및 관련 연구
- 시계열 분류(TSC): 시계열 데이터는 여러 실제 애플리케이션에서 쉽게 수집될 수 있지만, 라벨링은 비용이 크다. SSL은 이러한 상황에서 소량의 라벨된 데이터와 대량의 라벨되지 않은 데이터를 함께 사용하여 ML 모델을 훈련한다.
- 반지도 학습(SSL): 이미지 데이터에서 여러 SSL 방법이 제안되었으며, 시계열 데이터에도 적용 가능한지 연구가 진행 중.
- 시계열용 SSL: 전통적인 반지도 학습 모델이 시계열 분류에 사용되었으나, 신경망 기반 SSL 알고리즘 연구는 제한적.
주요 내용
- 백본 아키텍처: FCN을 시계열 데이터의 백본 아키텍처로 사용. FCN은 다양한 시계열 문제에서 뛰어난 성능을 보였으며, 반지도 학습 방법들과 잘 결합될 수 있다.
- 데이터 증강: 시계열 데이터의 특성에 맞춘 데이터 증강 전략을 제안. RandAugment를 사용하여 다양한 증강 정책을 랜덤하게 적용하고, Gaussian 노이즈 추가, 시간 및 크기 변환 등의 방법을 사용.
- 평가 및 튜닝: Hyperband와 Optuna를 사용하여 모델 튜닝을 수행했으며, 공정하고 신뢰할 수 있는 모델 비교를 위해 엄격한 평가 체계를 따름.
실험 결과
- 반지도 학습 모델의 성능: 특히 라벨이 적은 시나리오에서 반지도 학습 모델이 강력한 지도 학습 및 자가 지도 학습 모델보다 성능이 우수했음.
- 모델 전이 가능성: 이미지 분류에서 시계열 분류로 SSL 모델을 성공적으로 전이할 수 있음을 확인
- 강력한 지도 학습 기준의 필요성: 강력한 지도 학습 모델이 반지도 학습 모델의 성능을 현실적으로 평가하는 데 중요함을 확인
- 새로운 방법의 우수성: 제안된 방법들이 기존의 반지도 학습 및 자가 지도 학습 방법보다 우수한 성능을 보였음
- 모델 성능 순위: 이미지 도메인에서의 모델 성능 순위와 유사하게, 1위 : MixMatch, 2위 : VAT
결론
본 연구는 깊은 반지도 학습 모델이 시계열 분류 문제에서도 우수한 성능을 발휘할 수 있음을 밝혔다. 이 연구는 시계열 분류에 있어 강력한 반지도 학습 모델을 사용하는 것이 유리함을 시사하고 있다.
부록
반지도 학습의 시계열 데이터 적용 사례
데이터셋
- Crop: 작물 성장 데이터를 포함한 시계열 데이터.
- Electric Devices: 전기 장치의 사용 패턴 데이터
- FordB: 포드 자동차의 센서 데이터
- Pamap2: 신체 활동 모니터링 데이터
- SITS: 위성 이미지 시계열 데이터
- WISDM: 스마트폰의 센서 데이터
반지도 학습 모델
- Ladder Network: 데이터 노이즈를 줄이고, 고차원 특징을 학습하는 모델
- Logistic Regression: 선형 모델로, 주로 비교 대상으로 사용됨
- Mean Teacher: 두 개의 네트워크를 사용하는 모델로, 하나는 학생 네트워크, 다른 하나는 교사 네트워크. 교사 네트워크는 학생 네트워크의 파라미터를 업데이트.
- MixMatch: 라벨된 데이터와 라벨되지 않은 데이터를 혼합하여 학습하는 모델
- Random Forest: 결정 트리의 앙상블 모델
- Self-Supervised Learning: 자기 지도 학습 방법으로, 주로 시계열 데이터의 전처리와 특징 추출에 사용됨
- Supervised: 전통적인 지도 학습 모델
- VAT (Virtual Adversarial Training): 데이터의 노이즈에 강인한 모델을 만들기 위해 가상 적대적 예제를 사용하는 모델
실험 결과
각 모델의 성능은 다양한 라벨 수 (nl)에 대해 측정되었으며, 성능은 가중 평균 수신자 조작 특성 곡선 아래 영역 (wAUC)으로 평가
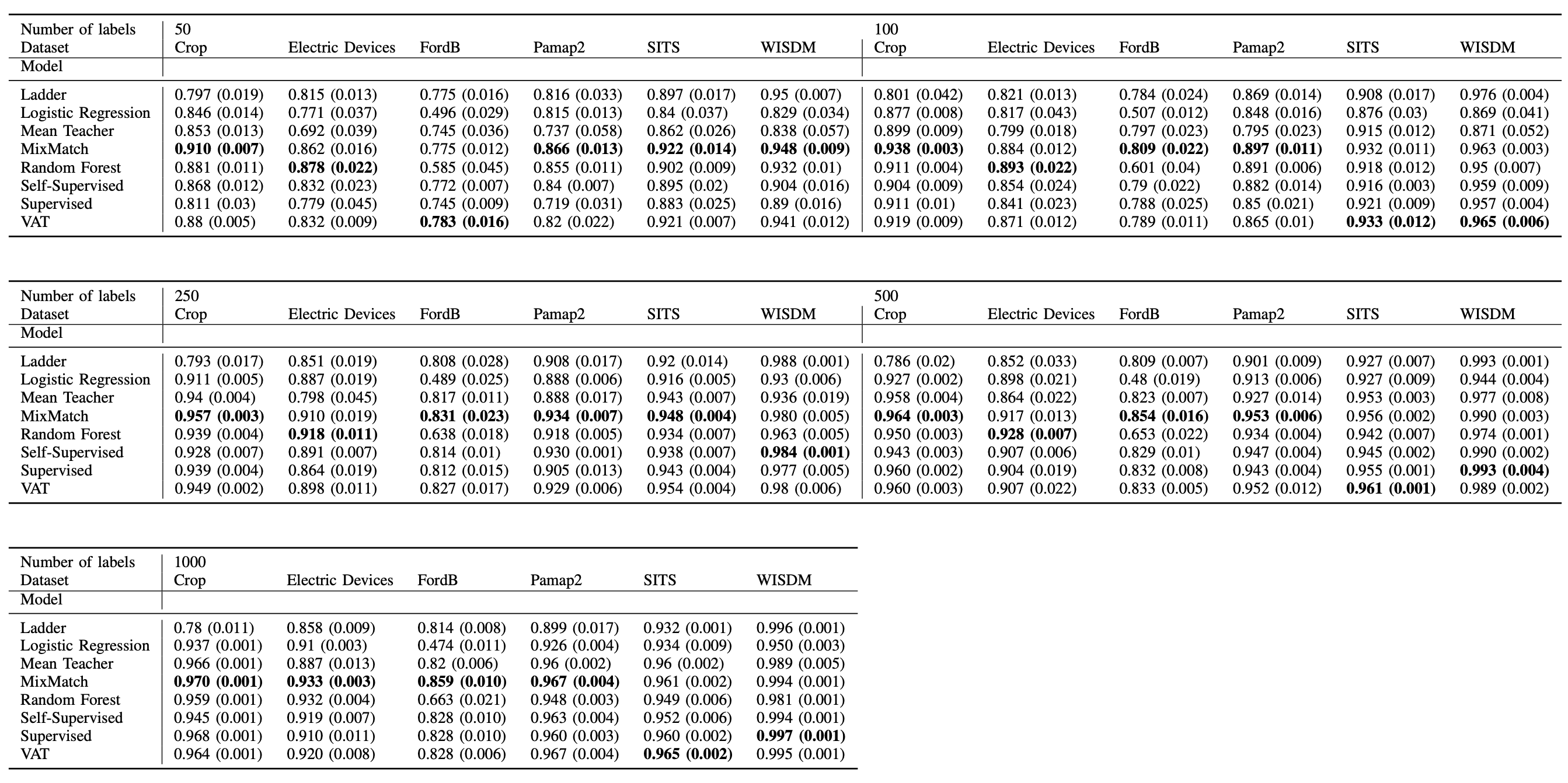
표1. 다양한 레이블 수를 가진 데이터 집합에 대한 모델 결과 [2]
결과
-
가장 좋은 성능 MixMatch 모델 요약
-
50개 라벨
- Crop: 0.910 (0.007)
- Electric Devices: 0.862 (0.016)
- FordB: 0.775 (0.012)
- Pamap2: 0.866 (0.013)
- SITS: 0.922 (0.014)
- WISDM: 0.948 (0.009)
-
100개 라벨
- Crop: 0.938 (0.003)
- Electric Devices: 0.884 (0.012)
- FordB: 0.809 (0.022)
- Pamap2: 0.897 (0.011)
- SITS: 0.932 (0.011)
- WISDM: 0.963 (0.003)
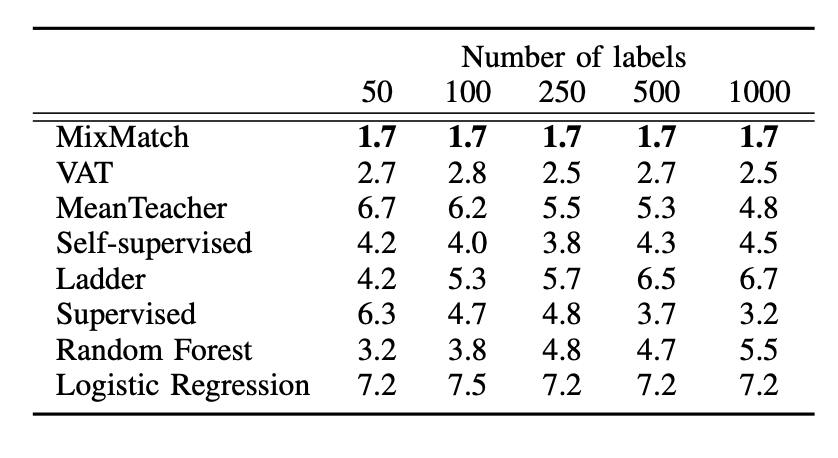
표2. 모델랭킹 [3]
Reference
[1] https://www.kdnuggets.com/2019/11/tips-class-imbalance-missing-labels.html
[2] https://link.springer.com/chapter/10.1007/978-981-19-6153-3_15
[3] https://arxiv.org/pdf/2102.03622

사실천재