26.03.09(월) 26.03.12(목)- 기록
버블 정렬(bubble sort)
- 인접한 두 원소를 비교하는 정렬
- (왼쪽 원소) > (오른쪽 원소)일 때
swap
=> 즉, v[i] > v[i+1]이면 swap - 가장 큰 원소부터 오른쪽에 정렬되기에, 데이터가 하나씩 정렬되면서 비교에서 제외
- 시간 복잡도: O(n^2)
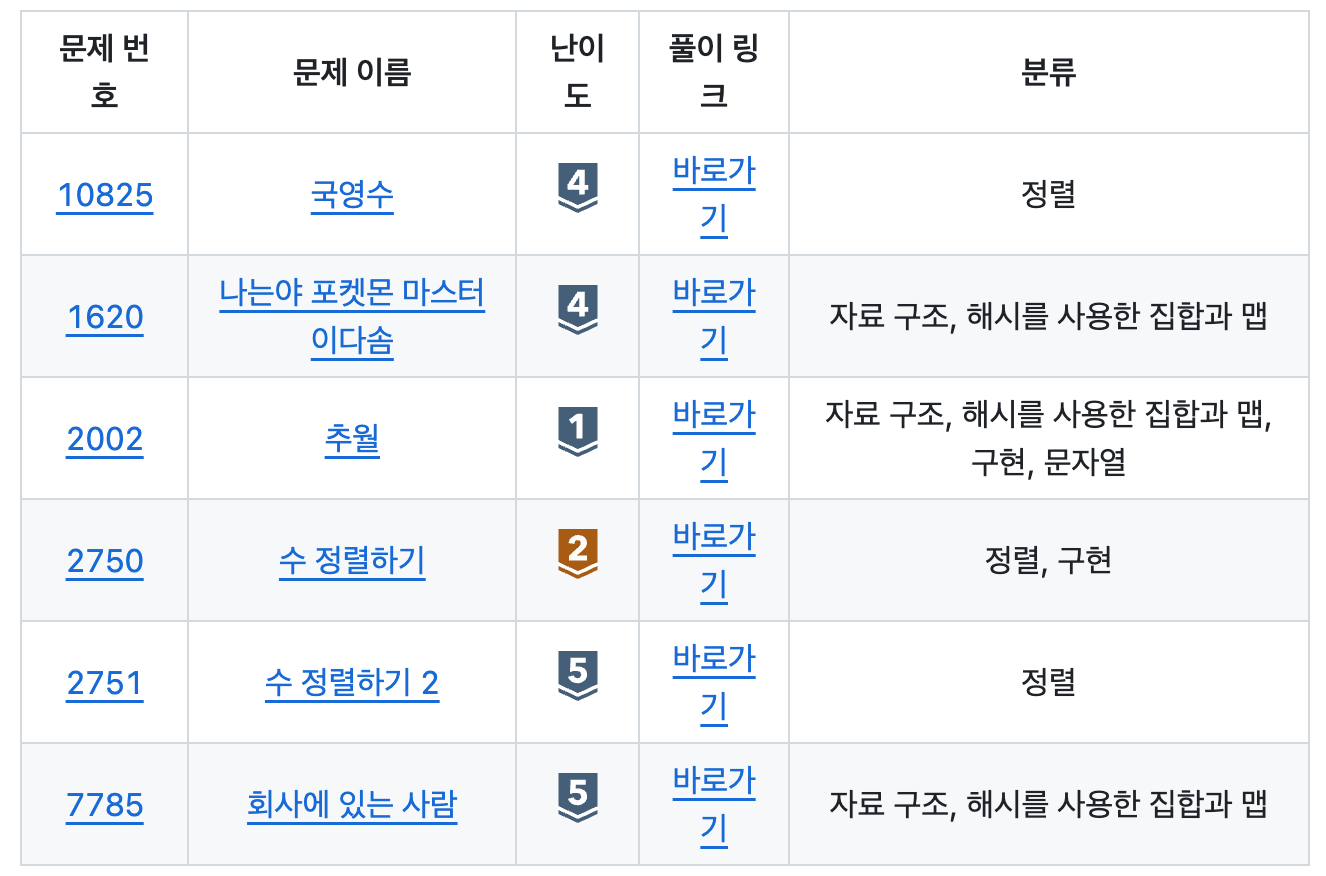
BOJ 2750: 수 정렬하기
#include <iostream>
using namespace std;
int main() {
ios::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int n;
cin >> n;
int arr[n];
for (int i=0; i<n; i++) {
cin >> arr[i];
}
for (int i=0; i<n; i++) {
for (int j=0; j<n-1; j++) {
if (arr[j] > arr[j+1]) swap(arr[j], arr[j+1]);
}
}
for (int i : arr) cout << i << endl;
}브론즈2인만큼 그냥 기본 버블 정렬하는 문제. 그런데 c++을 쓴지 진짜 오랜만이라 벡터나 다른거 쓰는걸 까먹어서 앞으로는 약간 주기적으로 풀면서 좀 익히고 정리해야할 것 같다. 버블 정렬 항상 하던건데 계속 sort를 써서 퀵소트로 자동으로 처리했어서 코드로 적는거 까먹어서 복기하는데 조금 고민했다. 대충 반복문 2개 돌려야하는 부분만 기억났고 인덱스 어떻게 해야하지? 순간 고민했는데 금방 떠올렸긴한데, 이게 맞나? 싶은 느낌. 그래서 제미나이한테 코드리뷰를 맡겨봤다.
일단 지적받은 부분은 아래와같다.
-
가변길이 배열(VLA) 주의사항
코드에서 벡터를 안쓰고 그냥 배열을 썼는데, 대부분의 gcc 같은 컴파일러에서 허용해주긴하지만 c++ 표준이 아니니std;:vector<int> arr(n);를 사용하라는 지적. 이게 메모리 관리 측면에서도 안전하다고 한다. 배열의 크기는 컴파일 타임에 결정되어야한다고. -
정렬 로직 최적화
버블 정렬 자체가 한 번 끝까지 반복을 돌고 나면 맨 끝의 요소는 확정이 되는 구조인데, 위에 적은 j 인덱스는 이미 정렬이 끝난 마지막 요소까지 확인을 하고 있으니j< n-1를j<n-1-i로 범위를 줄이라는 지적이 있었는데 맞는말이라 수정하였다.
=> 버블 정렬 정의에 적혀있는데 이걸 근자감으로 문제를 풀고 정독했다^^. 먼저 읽고 구현했으면 좀 더 신경써서 처리했을텐데..하하ㅏ -
조기종료 조건 추가
이 부분은 생각치 못한 거였는데, 정렬이 완료된 배열이 들어와도 위의 코드는 O(n^2)의 시간을 끝까지 다 쓰는데, 만약 한 번의 반복을 끝까지(0부터 n까지 1번 돌았을 때) 단 한 번도 swap이 일어나지 않았다면 이미 정렬된 상태이므로 그대로 바로 출력하도록break을 걸어주는 편이 좋다고한다. -
endl보다\n을 사용하는것
시간제한이 빡세지 않을 것 같은 문제라 그냥endl을 쓰긴했는데,endl은 단순히 줄바꿈만 하지 않고 출력 버퍼를 비우는(flush) 작업까지 수행하기에 속도가 느리다고 한다. 알고리즘 문제 푸는 건\n을 쓰는 습관을 들이라는 지적.
- flush는 대화형(inetractive) 문제에서 필수적이라고 한다.
예) 대화형 문제의 로직
- 내 프로그램이 질문 -> 2. 이때 flush를 하지 않으면 상대(채점 시스템)은 내 질문을 읽지 못함 -> 3. 상대의 대답을 기다리기 위해 내 프로그램은 멈춰버림(deadlock)
=> 아마 제미나이가 대화형 AI라 이런 예시를 들은거 같은데, 왠지 전에 자바 수업에서 소켓 통신 사용할 때, 문자열 보내는 것도 정말 꼬박꼬박 flush를 해주는 귀찮음을 줄이고자 자동flush가 되도록 어떤 처리를 해주었던걸 생각하면 맞는 말인듯 하다.
위의 요소를 전부 반영해 수정한 코드는 아래와 같이 나온다.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
ios::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int n;
cin >> n;
vector<int> v(n);
for (int i=0; i<n; i++) {
cin >> v[i];
}
for (int i=0; i<n; i++) {
bool swapped = false;
for (int j=0; j<n-1-i; j++) {
if (v[j] > v[j+1]) {
swap(v[j], v[j+1]);
swapped = true;
}
}
}
for (int i : v) cout << i << "\n";
}합병 정렬 (merge sort)
-
분할 정복(divide and conquer) 방식으로 설계된 알고리즘
=> 처음 분할 정복이라는 단어를 들었을 때는 느끼지 못했는데 지금 생각해보면 컴퓨터 네트워크에서 DNS 쿼리 관련해서도 이런 거랑 비슷한 느낌을 받았다. 잘게 쪼개서 처리하는 부분이? -
하나의 배열을 절반으로 나눔 -> 나눈 배열들을 정렬 -> 다시 하나의 배열로 합치기
-
시간 복잡도: O(nlogn)
+분할 정복
- 한 번에 해결할 수 없는 문제를 작은 문제로 분할해 해결하는 알고리즘
- 주로 재귀함수로 구현
- 크게 3단계로 구성
1. Divide: 문제 분할- Conquer: 쪼개진 작은 문제 해결
- Combine: 해결된 작은 문제들을 다시 합침
BOJ 2751: 수 정렬하기2
#include <iostream>
#include <vector>
using namespace std;
void merge(vector<int> &v, int s, int m, int e) {
int i =s;
int j = m+1;
vector<int> tmp;
while (i <= m && j <= e) {
if (v[i] <= v[j])tmp.push_back(v[i++]);
else tmp.push_back(v[j++]);
}
if (i > m) {
while (j <= e) tmp.push_back(v[j++]);
}
else {
while (i <= m) tmp.push_back(v[i++]);
}
for (int i : tmp) {
v[s++] = i;
}
}
void mergeSort(vector<int> &v, int s, int e) {
if (s < e) {
int mid =(s+e)/2;
mergeSort(v,s, mid);
mergeSort(v, mid+1, e);
merge(v, s,mid,e);
}
}
int main() {
ios::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int n;
cin >> n;
vector<int> v(n);
for (int i=0; i<n; i++) cin >> v[i];
mergeSort(v, 0,n-1);
for (int i : v) cout << i << "\n";
}이전에 자료구조 수업을 들을 때 구현을 안했어서 합병 정렬을 처음 구현해보는건데, 이미지로는 쪼개서 합치고..하는게 그냥 그러려니 하는데 그걸 구현하는건 또 쉽지 않았다. 재귀함수를 써야하는건 알았는데 배열을 "쪼개주는 부분"과 "합치는 부분"을 함수를 나눠서 작성하는게(?) 조금 중요한 부분인 것 같다. 나눠서 작성해야하는 것까지는 뭔가 혼자 생각하다가 + 적당히 수업에서 들은걸로 기억했는데, 각 함수에서 어디까지 진행해야할 지 + 벡터를 반환해줘야할지-각 작은 단위 벡터를 반환해서 합치고, 합치고...지금 생각하면 이거 절대 안되겠지만?- 등 이래저래 많은 방법을 생각했다가 전부 실패했다.
mergeSort에서 이제 배열을 쪼개는 역할을 하는데, s와 e의 중간인 m이라는 변수에서 계속 절반 부분의 인덱스를 저장해주면서 배열을 반씩 쪼개 재귀적으로 mergeSort를 호출하는게 중요한 부분인 것 같은 기분.
재귀함수에서는 무한루프를 돌지 않게 하기 위한 바닥 설정이 중요한 것 같은데 여기서는 if (s<e)에서 이걸 체크해 만약에 s==e, 즉 배열의 크기가 1로 한 개의 요소만 남았을 때, 돌아가서 배열 크기가 1인 두 배열을 merge 해주면서 이제 천천히 합쳐지는? 느낌...이다.
merge에서 이제 두 배열을 합쳐주는건데 사실 이걸 두 함수로 나누고 각 함수에서 할 역할을 정해 떠올리는게 어려웠지 합치는 부분의 구현은 간단했던 것 같다.
- 인덱스를 사용해서 배열을 두 개로 사용할 수 있게
- 두 배열의 시작 부분
i와j를 잘 설정해주기 - 두 배열을 왼쪽부터 비교해 작은거를 순서대로 임시배열(
tmp)에push_back을 통해 넣어주기 i또는j가 끝에 도달했을 때 (i > m이거나j > e일 때) 반복문 종료 후, 남은 배열 요소 전부를tmp에push_back해주기.tmp배열에 저장한 값대로 실제 배열(벡터) 인덱스s부터e까지 업데이트.
마지막 5번이 조금 신기한 부분. 이 부분은 다른 사람들이 구현한 블로그글 참고해서 썼다. 도대체 어떻게 바꾸지??하다가 결국 역시 임시배열을 써주기는 해야했다. 음, 여기까지인데 역시 기본?이라고 해야하나 약간 잘해야하는데? 잘못해서 아쉬운. 기분이다. 이전에는 그냥 c++에 있는 sort 써서 문제를 풀어버렸는데 정말 이렇게 직접 구현하는건 쉽지 않은 것 같다.
이것도 제미나이?한테 코드리뷰를 또 맡겨봤다. 궁금하기도 하고 딱히 코드리뷰 받을데가 없다. 그리고 요즘 AI가 코딩 잘하니까ㅏ 다른 블로그 글들 직접 찾아보는 것도 좋은 방법이겠지만... 시간이슈?로.. 하하.
-
잘했던 부분: 안정 정렬 유지
이것도 사실 그냥 참고해서 구현하다보니 이대로 하게된건데if (v[i] <= v[j])의 부분에서 "=" 덕에 값이 같을 때 순서가 뒤바뀌지 않는 합병 정렬의 장점을 살렸다는데..음, 어차피 임시배열에 둘 중 뭘 저장할지 고르는거니까 사실 크게 상관없지 않나? 싶기도 하다. -
매변 일어나는 메모리 할당
merge함수 내에서vector<int> tmp를 선언하는 것을 지적한다 -> 그러면 도대체 어떻게 하라고? 싶었지만, 합병 정렬이 재귀호출이 많이 일어나는데, 그걸 합칠 때마다 새 벡터를 만들고 지우는건 좋지 않다고한다. -> 그래서 어떻게 해결? 하하.main()에서 원본 배열과 같은 크기의tmp벡터를 하나 만들고merge()에서 참조로 넘겨서 재사용하라고 한다. 근데 이게 진짜 좋은걸까 잘 모르겠다. 일단 하라는대로 해서 백준 돌려보면 메모리+시간이 나오니까 한 번 시도해볼까싶다. -
정수 오버플로우 방지
int mid = (s+e)/2에서 아주 큰 배열에서는s+e가 정수(int) 범위를 넘을 수도 있다는 위험을 지적한다. 그럴싸해서 해결책인int mid = s + (e-s)/2로 바꾸면 좋겠다하는 생각이 들긴했다. 빼고 절반으로 나눈걸 더해서 가운데값을 찾으면 오버플로우 날 확률이 주니까...일단...? -
push_back()보다 인덱스 접근
앞에서tmp를 메인에 만들라고 했는데 미리 크기를 지정하고 인덱스로 값을 넣는게 더 효율적이라고 한다...

생각보다 꽤 줄어서 놀랐다. + 시간도 줄었다. 코드는 아래처럼 수정했다.
#include <iostream>
#include <vector>
using namespace std;
void merge(vector<int> &v, vector<int> &tmp, int s, int m, int e) {
int i =s;
int j = m+1;
int k = s;
while (i <= m && j <= e) {
if (v[i] <= v[j]) tmp[k++] = v[i++];
else tmp[k++] = v[j++];
}
while (j <= e) tmp[k++] = v[j++];
while (i <= m) tmp[k++] = v[i++];
for (int l=s; l<= e; l++) {
v[l] = tmp[l];
}
}
void mergeSort(vector<int> &v, vector<int> &tmp, int s, int e) {
if (s < e) {
int mid = s + (e-s)/2;
mergeSort(v, tmp, s, mid);
mergeSort(v, tmp, mid+1, e);
merge(v, tmp, s,mid,e);
}
}
int main() {
ios::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int n;
cin >> n;
vector<int> v(n);
vector<int> tmp(n);
for (int i=0; i<n; i++) cin >> v[i];
mergeSort(v,tmp, 0,n-1);
for (int i : v) cout << i << "\n";
}std::sort
앞에서도 말했지만, c++에서는 사실 직접 구현하지 않아도 퀵정렬을 sort()를 사용해 처리할 수 있는걸로 알고 있다. 굳이 따지자면 지금까지는 이 sort()를 정말 단순히 정렬할 때만 썼는데, 인자를 잘 설정해주면 다양하게 써먹을 수 있다-고 한다.
- 인자로 배열의 처음 시작 위치와 끝 위치를 전달
- 기본(아무것도 설정하지 않으면) 오름차순으로 정렬해서 반환
- 내림차순을 위해서는 세 번째 인자에 greater<>()을 넣어줘야함
- 세 번째 인자에 비교함수(cmp)를 넣으면 원하는 조건대로 정렬 가능
- 비교함수가 false를 반환할 경우 swap한다는 것을 유념해 비교함수 넣기.
BOJ 10825번: 국영수
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
struct student {
string name;
int kr;
int math;
int en;
};
bool comp(const student &s1, const student &s2) {
if (s1.kr == s2.kr) {
if (s1.en == s2.en) {
if (s1.math == s2.math) {
return s1.name < s2.name;
}
return s1.math > s2.math;
}
return s1.en < s2.en;
}
return s1.kr > s2.kr;
}
int main() {
ios::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int n;
cin >> n;
vector<student> v(n);
for (int i=0; i<n; i++) {
cin >> v[i].name;
cin >> v[i].kr;
cin >> v[i].en;
cin >> v[i].math;
}
sort(v.begin(),v.end(),comp);
for (student s : v) {
cout << s.name << "\n";
}
}- 구조체 정의하기
학생 구조체를 만들어서, 그 안에 이름, 국어, 영어, 수학의 성적을 담도록 정의.
struct student {
string name;
int kr;
int en;
int math;
}sort를 사용할건데, 구조체의 안에있는 요소를 기준으로 할거라 비교함수를 정의해줘야한다.
bool comp(const student &s1, const student &s2) {
if (s1.kr == s2.kr) {
if (s1.en == s2.en) {
if (s1.math == s2.math) {
return s1.name < s2.name;
}
return s1.math > s2.math;
}
return s1.en < s2.en;
}
return s1.kr > s2.kr;
}앞에서 정리했듯이 false를 반환되면 swap이 일어나는 것이니 그거 유의해서 규칙을 잘 정의하려고 했다.

처음에는 if문(조건)으로 체크해서 false를 반환하는 식으로 코드를 짰는데 잘 안돌아가서, 비교문 자체를 return하는 식으로 변경했더니 잘 수정돼서 그대로 갔다.
셋(set)
- 키(key)라고 불리는 원소의 집합
- 키값을 정렬된 상태로 저장
- 키값을 중복없이 저장
- 검색, 삽입, 삭제에서의 시간 복잡도 O(logN)
- 랜덤한 인덱스의 데이터에 접근 불가
set의 반복자
| 메소드 | |
|---|---|
s.begin() | set의 마지막 부분에 대한 주소값 반환 |
s.end() | set의 마지막 부분에 대한 주소값 반환 |
set의 용량
| 메소드 | |
|---|---|
s.size() | s에 저장되어 있는 크기 |
s.max_size() | s가 가질 수 있는 최대 크기 |
set의 삽입, 삭제
| 메소드 | |
|---|---|
s.insert() | s에 저장된 요소 삭제 |
s.erase() | s에 저장된 요소 삭제 |
s.swap() | s1과 s2를 서로 교환 |
s.clear() | s의 요소들 전부 삭제 |
set의 기능
| 메소드 | |
|---|---|
s.find | 찾는 값이 있으면 해당 위치의 iterator 반환, 아니면 s.end() 반환 |
s.count() | set에 저장된 요소들의 갯수 반환 |
C++ 셋의 구조: BST(Binary Search Tree)
- 하나의 parent(root)에 최대 2개 child가 있음
- 부모의 왼쪽 서브 트리값들은 모두 부모 노드보다 작음
- 부모의 오른쪽 서브 트리값들은 모두 부모 노드보다 큼
BOJ 7785번: 회사에 있는 사람
#include <iostream>
#include <set>
#include <vector>
using namespace std;
int main() {
ios::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int n;
cin >> n;
set<string> people;
for (int i=0; i<n; i++) {
string name, state;
cin >> name;
cin >> state;
if (state == "enter") people.insert(name);
else people.erase(name);
}
vector<string> v (people.begin(), people.end());
for (int i=v.size()-1; i>=0; i--) {
cout << v[i] << "\n";
}
}셋을 배우고나서 하는거라 일단 셋을 사용했다. 셋이 자동으로 정렬해서 값을 저장해주니까, 사람들 이름을 굳이 다시 정렬하지 않아도 괜찮으니 셋을 사용하는 쪽으로 하라고 이렇게 알려준 것 같다. 대신 관건은 마지막 부분에서 정렬된 것의 역순으로 출력해야해서 어떻게 해야할까 고민이 되었다.
우선 제일 먼저 생각한건, 그냥 셋을 벡터로 만들고, 반복문을 사용해서 인덱스를 통해 역순으로 출력하는 것이었다. 그 코드는 위쪽이고...
셋 역순 출력하는 방법을 찾다가 반복자를 사용하는 방법이 있어서 해당 방법을 사용해봤다.
set<string>::reverse_iterator it(people.rbegin());
for (; it != people.rend(); ++it) {
cout << *it << "\n";
}reverse_iterator: 역방향 반복자. 일반적인 iterator가 첫 요소에서 끝요소로 이동하면, 이 반복자는 뒤에서부터 앞으로 이동.people.rbegin(): set의 마지막 요소를 가리키는 시작점.people.rend(): set의 첫번째 요소의 앞부분을 가리키는 끝점.*: 역참조 연산자. 반복자(iterator)인it이 가리키고 있는 메모리 주소의 실제 저장하는 값을 꺼내라는 의미.
위의 코드를 조금 수정해서 아래처럼 됐다.
#include <iostream>
#include <set>
using namespace std;
int main() {
ios::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int n;
cin >> n;
set<string> s;
for (int i=0; i<n; i++) {
string name, state;
cin >> name;
cin >> state;
if (state == "enter") s.insert(name);
else s.erase(name);
}
set<string>::reverse_iterator iter;
for (iter=s.rbegin(); iter != s.rend(); iter++) {
cout << *iter << "\n";
}
}항상 반복문 통해서 인덱스로만 접근했어서 그런가 반복자를 사용하는 것 자체가 뭔가 낯설었는데 reverse_iterator가 아니라 iterator를 한 번 써보니까 좀 더 느낌이 잘 와닿았다.
맵 (Map)
- 다양한 자료형의 데이터를 key-value 쌍으로 저장
- 키값을 정렬된 상태로 저장
- 키값을 중복 없이 저장
- 검색/삽입/삭제에서의 시간 복잡도는 O(logN)
- 랜덤한 인덱스의 데이터에는 접근 불가
- 키값을 인덱스처럼 접근해서 key-value 삽입이 가능함
삽입/삭제/검색
insert: pair<string,int>("a",5);와 같은 형태로 삽입 (중복삽입 시도 시 추가X)
erase: 키값을 통해 해당 원소 삭제
find: 키값을 통해 원소 검색
BOJ 1620번: 나는야 포켓몬 마스터 이다솜
#include <iostream>
#include <map>
#include <string>
#include <cctype>
using namespace std;
int main() {
ios::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int n,m;
cin >> n >> m;
map<int, string> arr1;
map<string, int> arr2;
for (int i=0; i<n; i++) {
string s;
cin >> s;
arr1.insert(pair<int,string>(i,s));
arr2.insert(pair<string, int>(s,i));
}
for (int i=0; i<m; i++) {
string q;
cin >> q;
if (isdigit(q[0])) {
int tmp = stoi(q);
tmp--;
cout << arr1.find(tmp)-> second << "\n";
}
else cout << arr2.find(q)->second+1 << "\n";
}
}일단 포켓몬 이름-번호를 키-값의 쌍으로 저장하고 있어야하니까 맵으로 저장해야한다는 것은 알았다. 다만 이후에 들어오는 값이 문자인지 숫자인지 구분해야하는 것과 문자/숫자에 따라 대응되는 포켓몬 이름/번호를 찾아줘야한다는 것이 남았었다.
일단 문자/숫자 여부를 확인하는 것은 isdigit()을 사용해주었다. 처음에는 string 자체를 isdigit()의 인자로 넣어주었는데, 문자 하나만 넣어야한다. 왜냐하면 들어온 문자가 0~9 사이의 10진수 숫자인지에 대해 판별해주는 것이다. 그래서 첫 글자 하나만 (코드에는 q[0]으로 그냥 처리했다.) 판별해 이게 숫자면 stoi()를 통해 문자열을 정수로 바꿔 정수처럼 사용할 수 있게했다. 이렇게 하면 두 자릿수가 나오더라도 문제가 없으니.
관건은 이름이 나오면 포켓몬 번호를, 번호가 나오면 이름을 찾아줘야했던 건데. 맵은 키값을 기준으로 대응되는 값(value)를 찾아오기에 어떻게 해야할지 고민이 많았다. map<string, int> 이렇게 만들면 이름으로 번호는 찾을지언정, 번호로 이름을 찾기는 또 다른 문제니 말이다.
사실 처음에는 그냥 반복문 전체를 돌면서 찾게 했는데 당연히 시간초과가 났다. 다른 방법이 있긴하겠지만...? 직관적으로 떠올린것은 map<string, int>와 map<int, string> 이렇게 두 개의 맵을 만들어서 각각 이름/번호로 찾으면 되는 것이었다. (좀 무식한 방법인가? 싶기도한데...)
초기화할 때, 인덱스를 사용해 번호를 넣어주는 식으로 맵 초기화를 진행했고, 위에 쓴대로 키가 이름인 맵과 키가 번호인 맵 2가지를 만들어서 각각 find()를 통해 찾을 수 있게 하였다. 예상하지 못한 오류는 그냥 find()만해서 끝이 아니라 또 그 값을 이용할거라 m.find(key)->second 이렇게 적어주어야했다.
이것도 제미나이한테 코드리뷰를 맡겼다.
- 맵에 값 저장할 때
insert()대신 간단하게
arr1.insert(pair<int, string>(i,s));위에 처럼 저장을 했는데-이걸 블로그 정리글에서 보면서 써서...
arr1[i] = s;위의 방법대로 해서 굳이 pair를 만들어서 넣지 않아도 가능한 식이었다^^.....
-
맵의 요소 접근
위의 코드에서 나는find()를 사용하고, 또 거기서->second이런식으로 접근을 했는데, 그 만약 맵에 반드시 데이터가 존재한다면 그냥 바로arr2[q]이렇게만 접근해도 값(value)를 얻을 수 있다고한다. -
해시맵
그리고 이거는 검색 속도 최적화를 위해서 그냥 맵이 아니라#include<unordered_map해서 해시맵을 쓰라고 한다. 시간 복잡도가 O(logN) -> O(1)으로 줄어든다고...
+) 해시맵 vs 맵
맵(map)은 자료가 정렬되어 보관되지만, 해시맵(HashMap)은 정렬하지 않은채로 자료를 보관함. 맵은 이진 탐색 트리로 접근하고, 해시맵은 배열로 접근한다고... 시간복잡도가 더 빠르긴 하지만, 탐색 성능이 안정적이지 못해, STL의 공식 컨테이너에 속하지 않고 따로 구현된 STL 라이브러리를 사용해야한다고 한다....
BOJ 2002: 추월
#include <iostream>
#include <map>
#include <vector>
using namespace std;
int main() {
ios::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int n;
cin >> n;
map<string, int> car;
vector<int> index(n);
for (int i=0; i<n; i++) {
string s;
cin >> s;
car[s] = i;
}
for (int i=0; i<n; i++) {
string s;
cin >> s;
index[i] = car[s];
}
int cnt = 0;
for (int i=0; i<n; i++) {
for (int j=i+1; j<n; j++) {
if (index[i]>index[j]) {
cnt++;
break;
}
}
}
cout << cnt;
}아이디어 떠올리는게 제일 힘들었다. 일단 차량이름(?)하고, 들어온 순서를 키-값 쌍으로해서 저장해야하는것은 알겠는데, 이걸 후에 나가는 순서대로 이름이 들어왔을 때 어떻게 비교할지가 진짜 안떠올랐다. 여기저기서 그냥 힌트를 받았는데. 차량이름이 아니라 차량이 들어왔던 순서로 나가는 차를 벡터/배열로 받는 것이다.
추월 했다는 말이 나의 뒤에 있는 인덱스가 나보다 작으면 = 나보다 먼저 들어갔던 차가 되니까, 맵에서 차가 들어온 순서를 값으로 가지고 있다가, 나가는 차의 입력에 대응되는 그 순서를 벡터에 저장해주고, 후에 벡터 순회하면서 만약 내 뒤에 있는 값들 중 나보다 순서가 작은게 있으면 나는 추월한 차라고 생각해서 cnt++을 통해 추월한 차의 수를 하나씩 업데이트해주었다.
시간제한이 2초라 벡터 순회는 그냥 for 문 이중으로 써서 확인하는 식으로 짰다.
