인프런 데이터베이스 강의 (섹션6-섹션7) 기록
관계형 데이터베이스
두 개의 테이블에 분산해서 저장하고 읽어와 출력에는 이를 합쳐서 보여줄 수 있음.
중복을 제거할 수 있다는 것이 장점.
RENAME TABLE: 테이블 이름 수정 가능
author라는 테이블을 기존의 topic 테이블에서 따로 분리해 만들어 중복하여 저장하는 author의 프로필이나 이름을 생략. 대신 author_id를 topic 테이블에 author 대신 넣어줌.
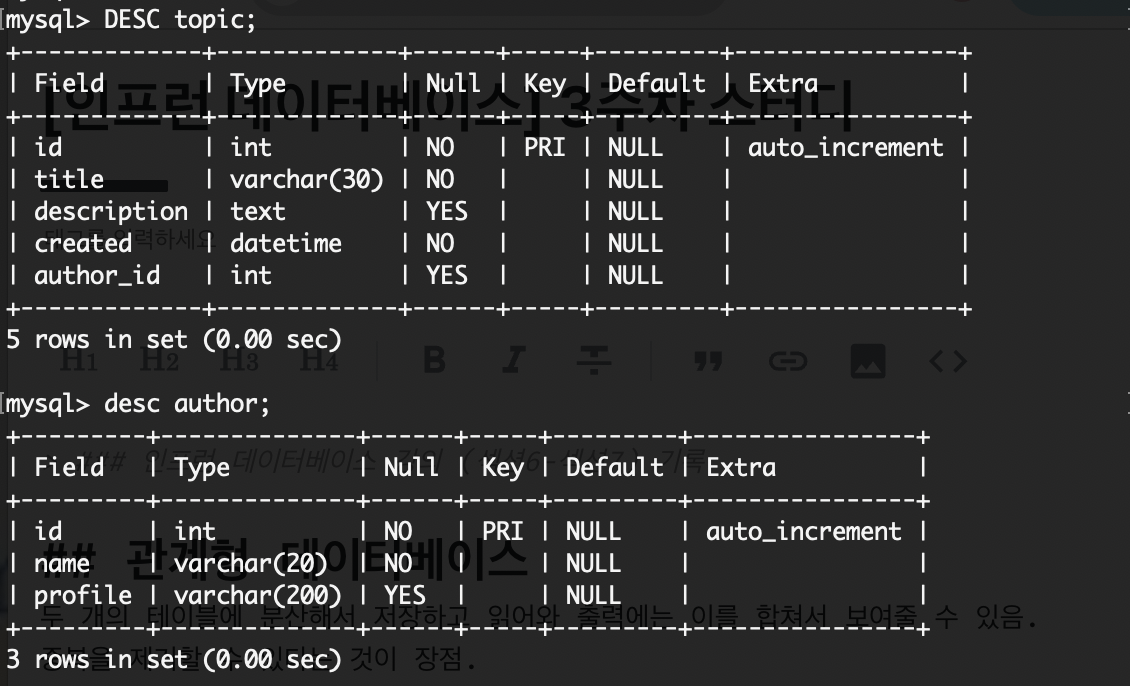 )
)
아래와 같은 형태로 출력됨.
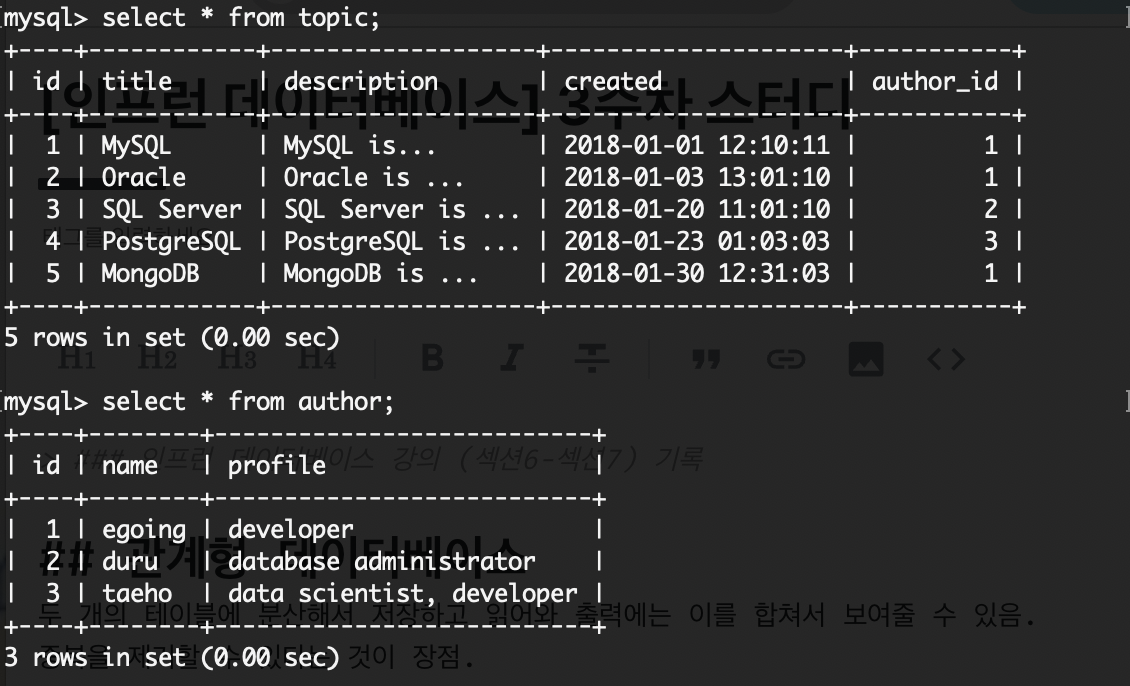 )
)
조인(JOIN)
두 개의 분리된 테이블을 하나의 형태로 합쳐서 출력할 수 있음.
위의 테이블에서 연결 고리는 author_id라고 할 수 있음.
SELECT * FROM topic LEFT JOIN author ON topic.author_id = author.id;topic의 author_id와 author 테이블의 id값이 같은 것을 기준으로 두 테이블을 합쳐서 출력함.
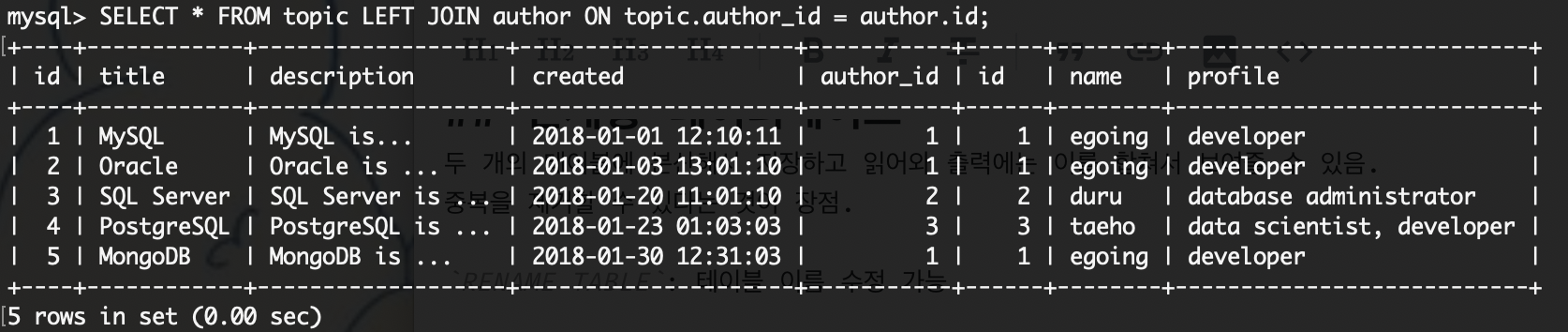
author의 아이디나, author 아이디를 생략하려면 SELECT 문의 뒤에 보여주고 싶은 속성명만 적어준다.
SELECT topic.id, title, description, created, name, profile FROM topic LEFT JOIN author ON topic.author_id = author
.id;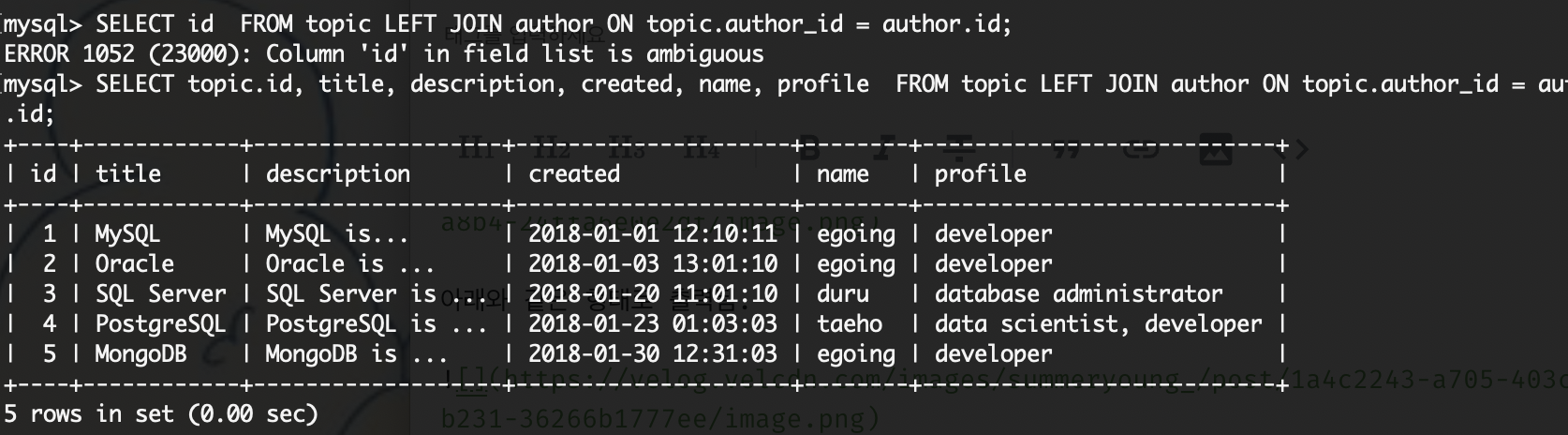
하지만 위의 예시처럼 id를 선택할 경우 해당 id가 topic 테이블의 속성을 말하는지, author 테이블의 속성을 말하는지 모르기 때문에 <테이블명>.<속성명>의 형식으로 확실하게 명시하여준다.
또, 출력되는 표의 속성명을 다르게 수정하고 싶을 때는 AS를 사용해 별칭을 만들어줄 수 있다.
SELECT topic.id AS topic_id, title, description, created, name, profile FROM topic LEFT JOIN author ON topic.author
_id = author.id;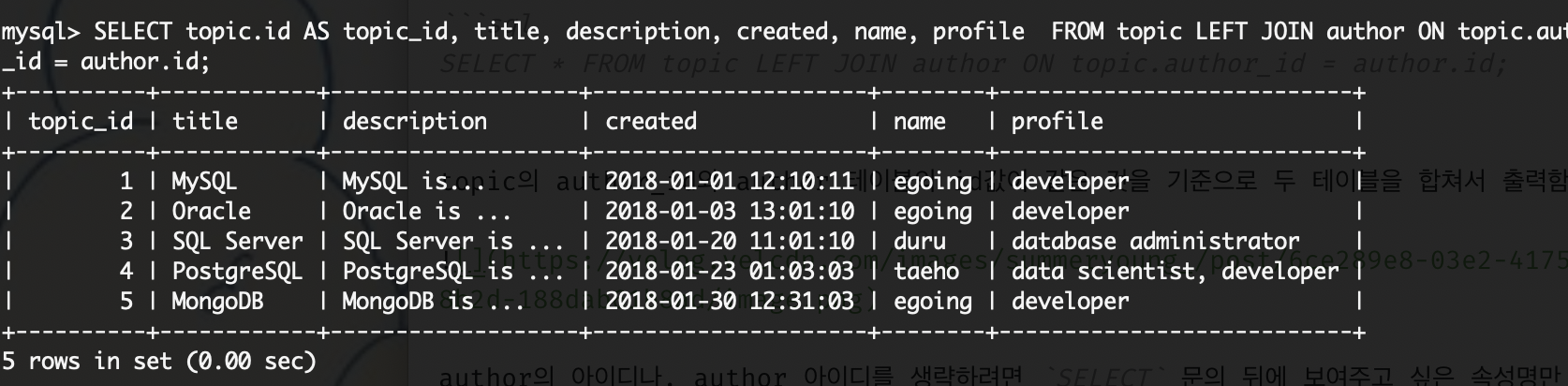
이렇게 테이블을 분리하게되면, 수정 및 유지 보수에서 이점을 얻을 수 있음.
인터넷과 데이터베이스의 관계
데이터베이스 서버
MySQL을 설치하면 데이터베이스 클라이언트와 데이터베이스 서버 2가지를 설치하게됨. 데이터베이스 서버에 실제로 데이터가 저장되며 데이터베이스 클라이언트 쪽에서 이 데이터베이스 서버에 접속할 수 있음.
데이터베이스 클라이언트
데이터베이스 서버는 직접 다룰 수 없고 반드시 데이터베이스 클라이언트를 사용해야함. 터미널에서 지금껏 사용하던 것은 CLI를 사용해 접근하는 데이터베이스 클라이언트 중 하나인 mysql-monitor 였음.
mysql-monitor의 장점(CLI):
- 명령어를 사용해서 제어
- mysql을 설치하면 같이 설치되며 어디에서나 실행할 수 있음.
MySQL Workbench는 GUI 형식의 데이터베이스 클라이언트.
./mysql -uroot -p -h localhost--h: 접속하려는 데이터베이스 서버의 주소를 적어주는 부분
localhost=127.0.0.1: 스스로의 컴퓨터를 가리키는 뜻.
인터넷
동작을 위해서는 최소 2대의 컴퓨터가 필요함. 인터넷은 컴퓨터들이 모여 이루는 사회라고 볼 수 있음.
한 대의 컴퓨터는 다른 컴퓨터에게 정보를 요청하고, 다른 컴퓨터는 정보를 응답함. 요청하는 쪽을 클라이언트, 응답하는 쪽은 서버라고 함.
웹에 비유를 하면 웹 브라우저(웹 클라이언트)가 웹 서버 측에 요청을 보내게됨.
MySQL Workbench
SQL문을 생성해서 서버로 전달하는 것이 모든 서버 클라이언트들의 동작.
아래처럼 GUI를 사용해 스키마를 새로 만들 수 있는데 이 역시도 결국 SQL문이 만들어지고 실행되는 형식.
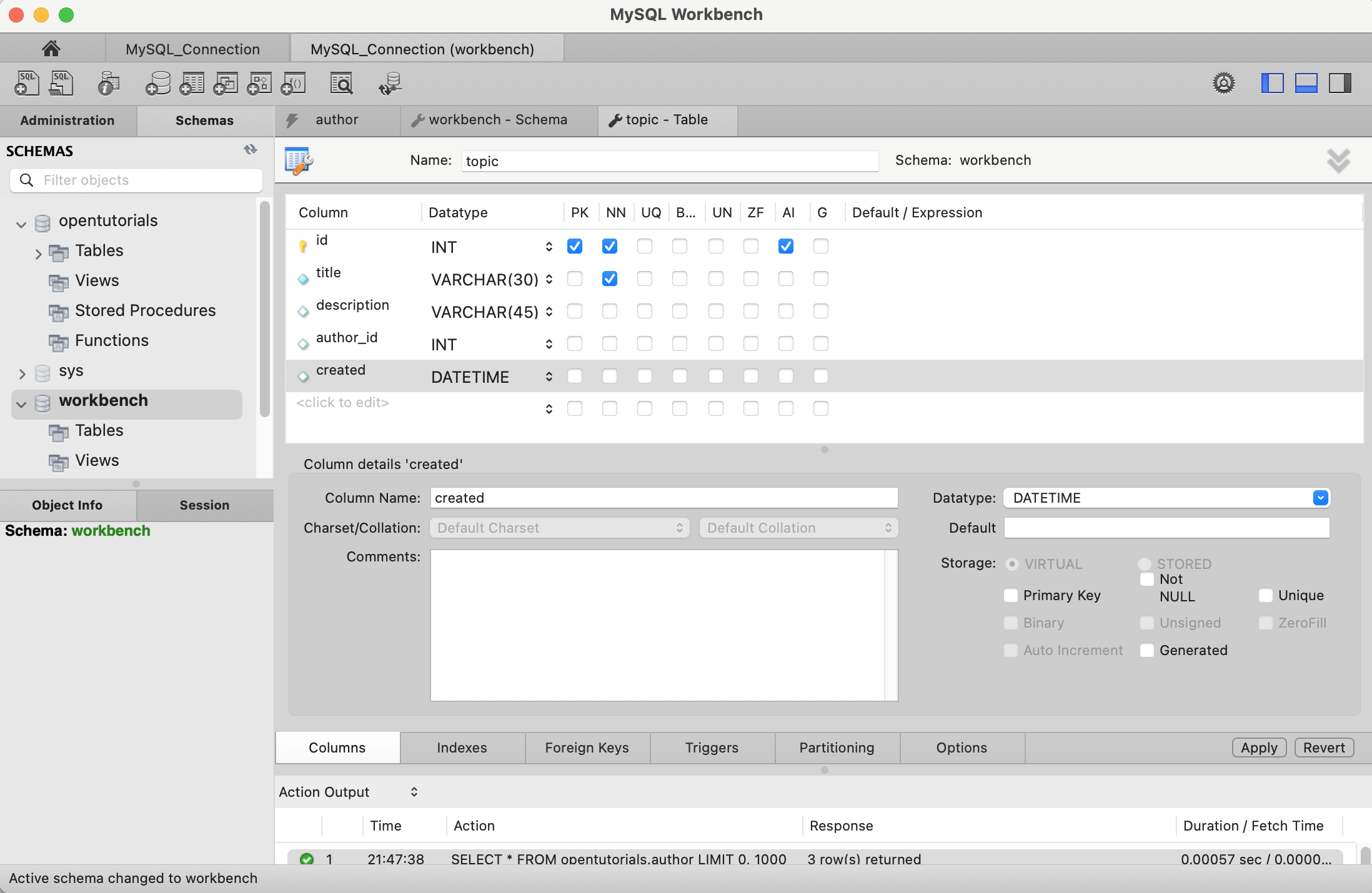
아래 처럼 테이블 생성 시 속성들을 GUI를 사용해 설정할 수 있게된다.
추가
정보가 많아지며 생기는 문제점들이 존재함. 데이터가 많아질수록 무언가를 찾을 때 시간이 오래 걸리는 문제들이 존재함.
index
이를 해결하기 위해 사용자들이 자주 검색하는 컬럼(속성)에 색인(index)을 걸어줌. 이렇게 색인을 걸 경우, 데이터가 들어올 때 데이터베이스가 해당 컬럼의 데이터를 잘 정렬해 정리해둠. 후에 요청 시 빠르게 응답할 수 있음.
modeling
테이블을 효율적으로 잘 설계해야함. 정규화, 비정규화 등. 데이터가 많아지면서 이를 관리/설계해야할 필요성을 느낄 시 공부.
backup
데이터가 날라가면 문제가 발생하기에 잘 백업해두어야함. 하드 디스크의 고장 등의 문제가 있을 수 있기에 정보를 안전하게 잘 보장해야함. 데이터를 복제해서 보관하여 백업하는 것이 중요.
mysqldump나 binary log를 찾아보기
cloud
컴퓨터를 데이터베이스 서버로 쓰지 않고, 거대한 회사가 운영하는 인프라 위의 컴퓨터를 임대해서 사용하는 것이 클라우드 컴퓨팅. 이는 원격 제어를 통해 먼 곳에 있는 컴퓨터를 제어. 백업 등을 알아서 관리해주기에 편리함.
예) AWS, Google Cloud, AZURE 등
3주차 추가 과제
테이블 생성
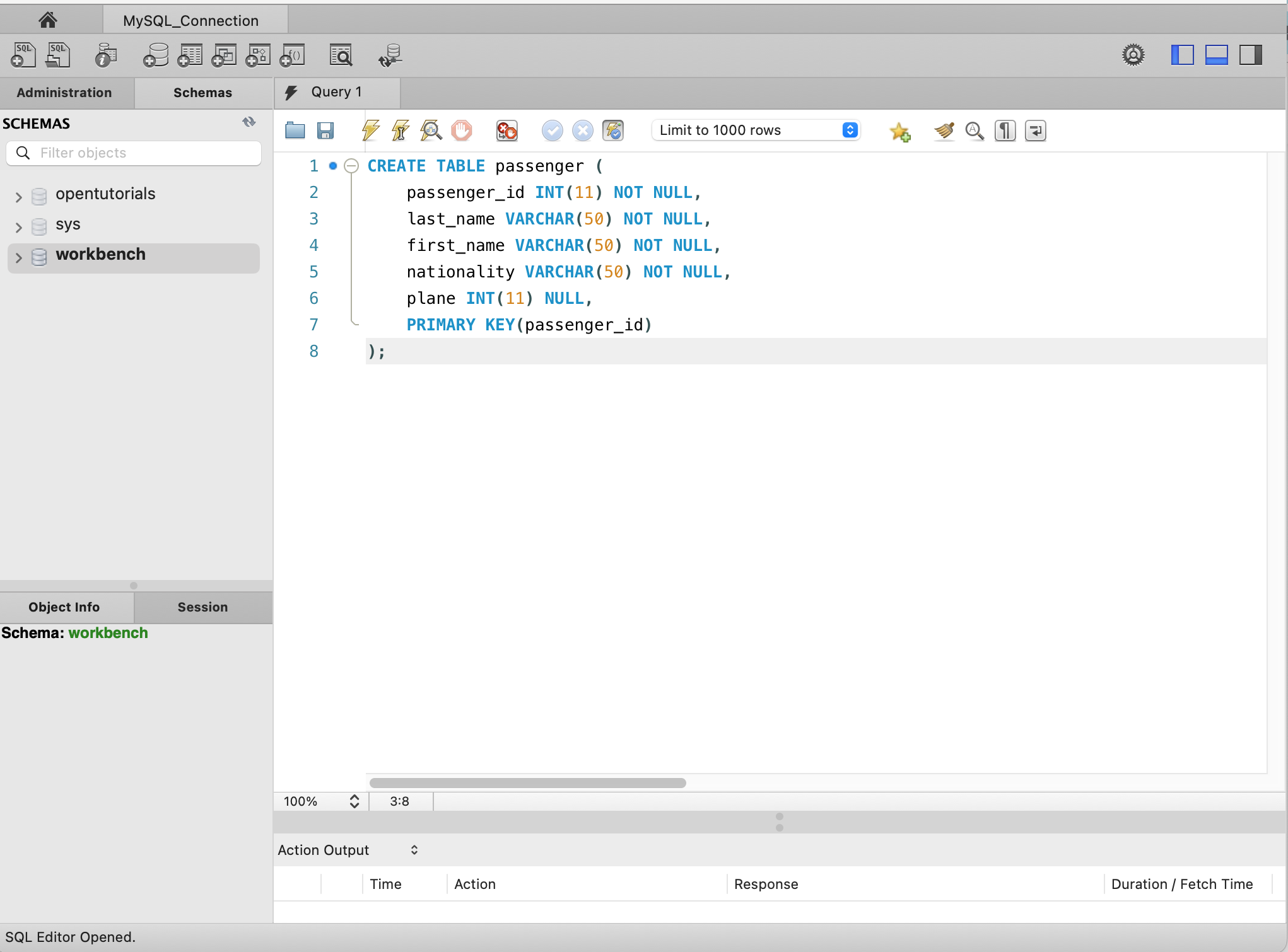
passenger와 plane 두 개의 테이블을 생성.
CREATE TABLE passenger (
passenger_id INT(11) NOT NULL AUTO_INCREMENT,
last_name VARCHAR(50) NOT NULL,
first_name VARCHAR(50) NOT NULL,
nationality VARCHAR(50) NOT NULL,
plane INT(11) NULL,
PRIMARY KEY(passenger_id)
);
CREATE TABLE plane(
plane_id INT PRIMARY KEY AUTO_INCREMENT,
departure VARCHAR(45) NOT NULL,
arrival VARCHAR(45) NOT NULL,
departure_time DATETIME NOT NULL,
gate INT NOT NULL,
meal BOOLEAN
);
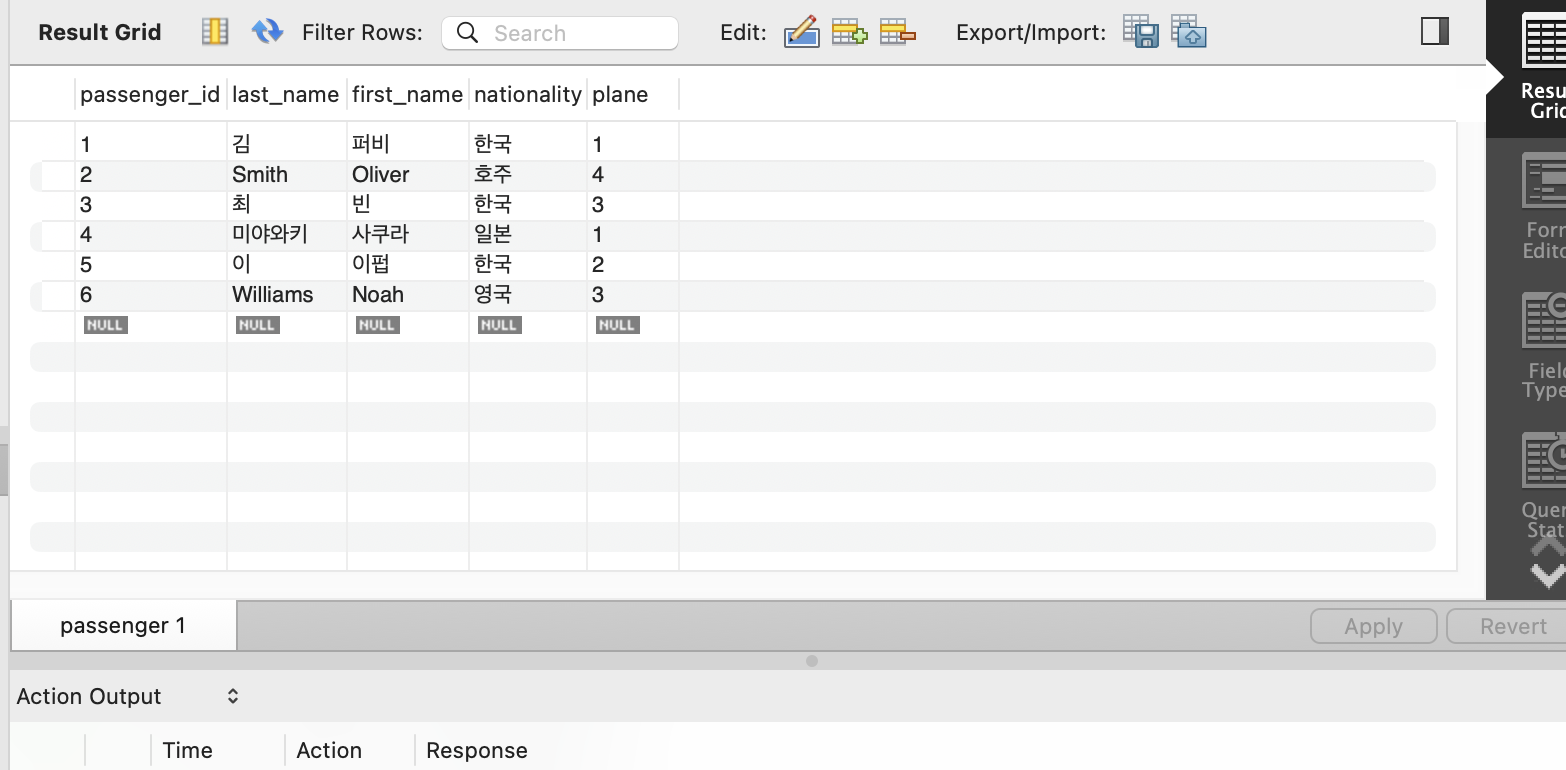
데이터 삽입
INSERT INTO passenger (last_name, first_name, nationality, plane)
VALUES ("김", "퍼비", "한국", 1);
INSERT INTO passenger (last_name, first_name, nationality, plane)
VALUES ("Smith", "Oliver", "호주", 4);
...
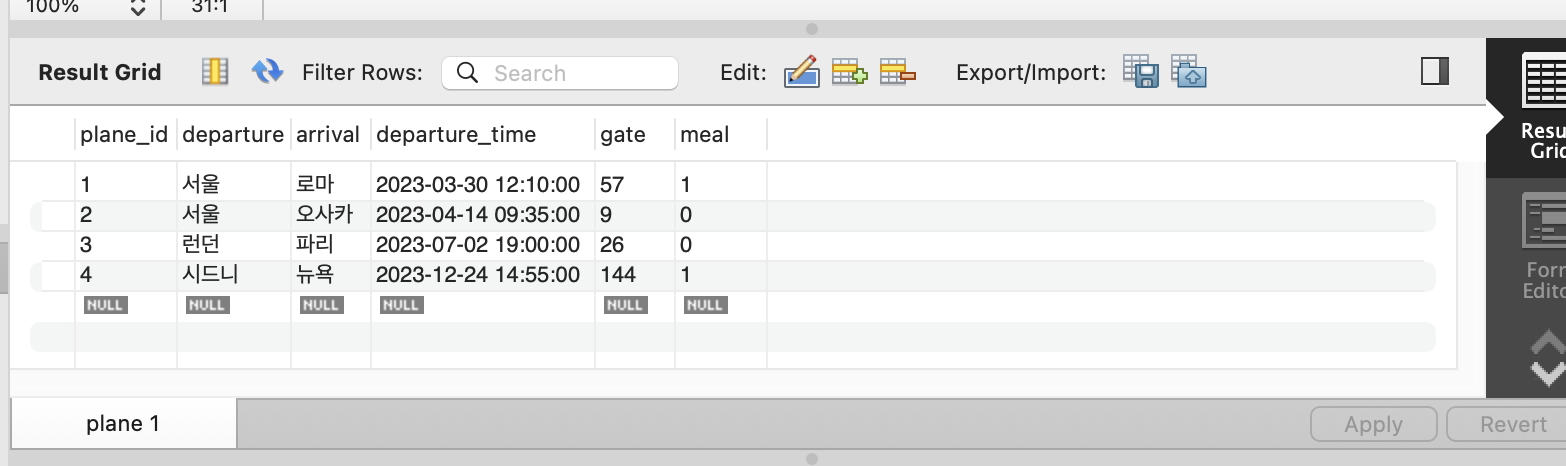
INSERT INTO plane (departure, arrival, departure_time, gate, meal)
VALUES ("서울", "로마", "2023-03-30 12:10:00", 57, true);
INSERT INTO plane (departure, arrival, departure_time, gate, meal)
VALUES ("서울", "오사카", "2023-04-14 09:35:00", 9, false);
...
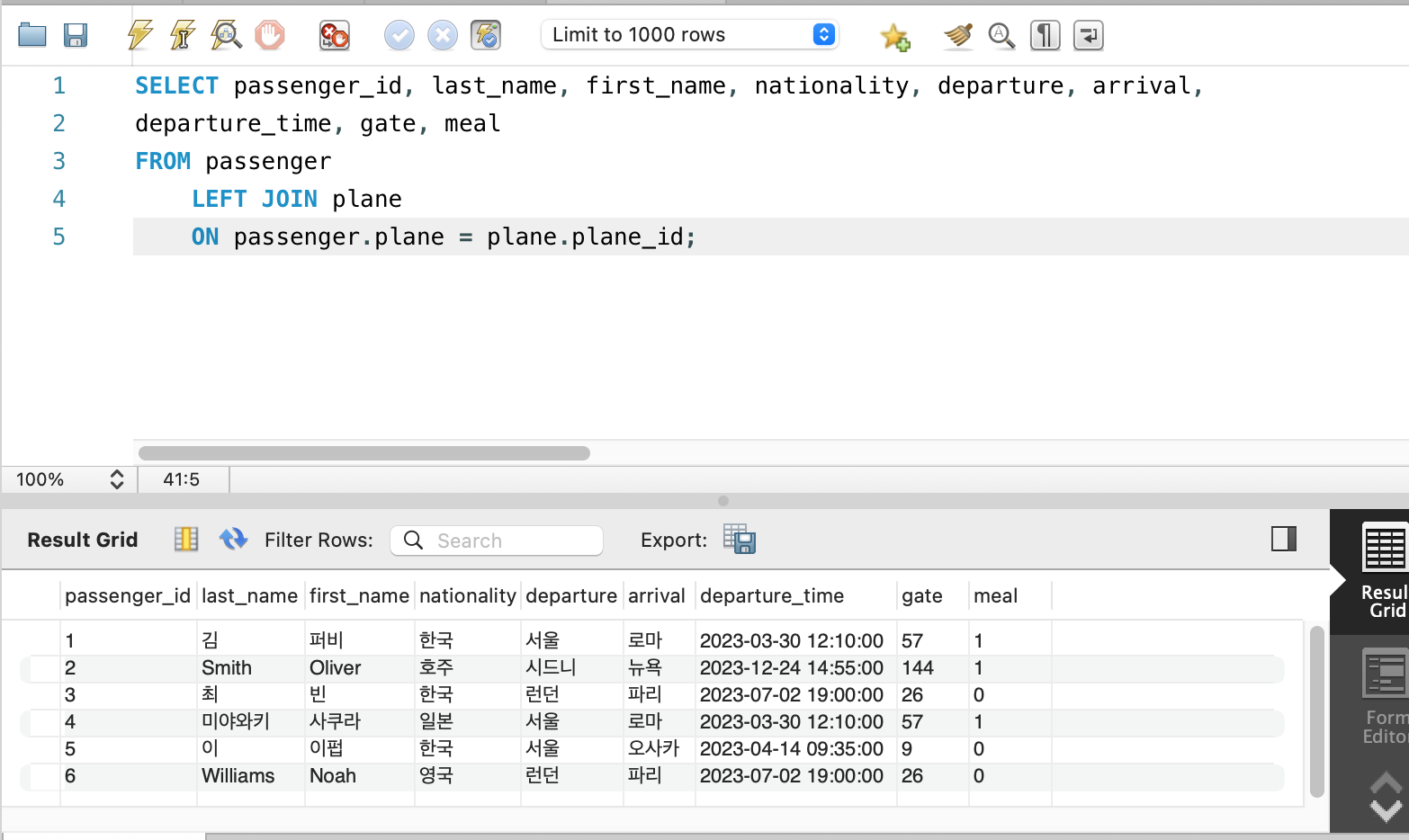
조인(JOIN) 활용 쿼리 조회
SELECT passenger_id, last_name, first_name, nationality, departure, arrival,
departure_time, gate, meal
FROM passenger
LEFT JOIN plane
ON passenger.plane = plane.plane_id;