
✏️ 04. 교차검증
데이터 전처리(Preprocessing)
-
모든 데이터 분석 프로젝트에서 데이터 전처리는 반드시 거쳐야 하는 과정이다. 대부분의 데이터 분석가가 좋아하지 않는 과정이지만, 분석 결과 / 인사이트와 모델 성능에 직접적인 영향을 미치는 과정이기 때문에 중요하게 다루어지는 과정이다.
-
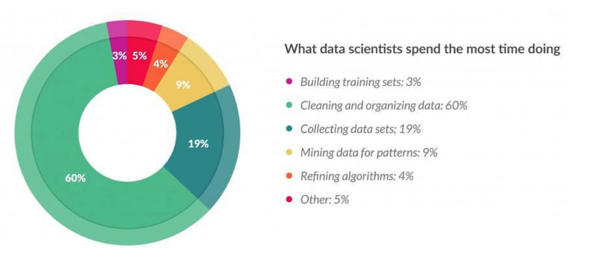
한 설문조사에 의하면, 분석가의 80% 시간을 데이터 수집 및 전처리에 사용한다고 하니, 얼마나 중요한 과정인지 짐작할 수 있다. 물론 지루하고 반복 작업의 연속이기 때문에 시간이 많이 들어가는 측면도 있을 것이다.
-
실무에 사용되는 데이터셋은 바로 분석이 불가능할 정도로 지저분(messy)하다. 분석이 가능한 상태로 만들기 위해 아래와 같은 전처리 방식이 자주 사용된다.
- 데이터 클린징
- 결손값 처리(Null, NaN 처리)
- 데이터 인코딩(레이블, 원-핫 인코딩)
- 데이터 스케일링
- 이상치(Outlier) 제거
- Feature 선택, 추출 및 가공
데이터 인코딩
-
머신러닝 알고리즘은 문자열 데이터 속성을 입력 받지 않는다.
-
문자형 카테고리형 속성은 모두 숫자값으로 변환/인코딩 되어야 한다.
- 레이블(Label) 인코딩, 원-핫(One-Hot) 인코딩, Feature Scaling 방식에 대해 알아보자.
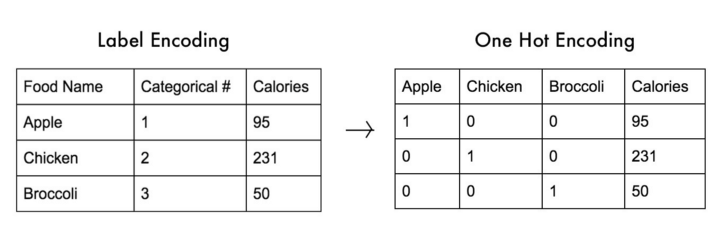
레이블(Label) 인코딩
- Label Encoding이란 문자열의 unique값을 숫자로 바꿔주는 방법이다.
from sklearn.preprocessing import LabelEncoder
fruit=['바나나', '사과', '사과', '포도', '딸기', '포도', '바나나']
print(sorted(set(fruit)))
encoder = LabelEncoder()
labels = encoder.fit_transform(fruit)
print(labels)
# outputs
# ['딸기', '바나나', '사과', '포도']
# [1 2 2 3 0 3 1]-
fruit라는 변수를 내림차순으로 정렬하여 고유값에 번호를 매긴것을 확인할 수 있다.
-
문제점
- 숫자값으로 변환되어 숫자의 ordinal한 특성이 반영되기 독립적인 관측값간의 관계성이 생긴다.
- 숫자값을 가중치로 잘못 인식하여 값에 왜곡이 생긴다
- ex) 1+2 = 3, 1<2<3<4
-
이러한 특성은 예측 성능의 저하를 일으키고, 레이블 인코딩은 선형회귀와 같은 ML알고리즘에는 보통 적용하지 않는다. 하지만 트리계열의 ML알고리즘은 숫자의 ordinal 특성을 반영하지 않으므로 레이블 인코딩도 별 문제 없다.
원-핫(One-Hot) 인코딩
-
원-핫 인코딩은 Feature의 유형에 따라 새로운 Feature를 추가해 고유 값에 해당하는 컬럼에만 1을 표시한다.
-
나머지 컬럼에는 0을 표시한다.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
fruit=['바나나', '사과', '사과', '포도', '딸기', '포도', '바나나']
# Step1: 모든 문자를 숫자형으로 변환
encoder = LabelEncoder()
encoder.fit(fruit)
labels = encoder.transform(fruit)
# Step2: 2차원 데이터로 변환
labels = labels.reshape(-1, 1)
# Step3: One-Hot Encoding 적용
oh_encoder = OneHotEncoder()
oh_encoder.fit(labels)
oh_labels = oh_encoder.transform(labels)
print(oh_labels.toarray())
print(oh_labels.shape)
# [[0. 1. 0. 0.]
# [0. 0. 1. 0.]
# [0. 0. 1. 0.]
# [0. 0. 0. 1.]
# [1. 0. 0. 0.]
# [0. 0. 0. 1.]
# [0. 1. 0. 0.]]
# (7, 4)-
이처럼 One-Hot Encoding은 각 범주를 고유한 이진 벡터로 나타내는 방법이다.
-
모델은 범주간의 관계를 학습하지 않고, 각 범주가 독립적으로 다루어지기 때문에 더욱 정확한 학습이 가능해진다.
Feature Scaling
-
표준화
-
데이터의 feature 각각이 평균이 0이고 분산이 1인 가우시안 정규 분포를 가진 값으로 변환
-
𝑥𝑖 = (𝑥𝑖−𝜇𝜎) / 𝜎 [𝜎 : 표준 편차, 𝜇 : 평균]
-
[20, 30, 40] → [-1.22, 0, 1.22]
-
데이터 분포의 중심을 0으로 변경(Zero-Centered)
-
-
정규화
-
𝑥𝑖 = (𝑥𝑖−min(𝑥)) / (max 𝑥 −min(𝑥))
-
[20, 30, 40] → [0, 0.5, 1]
-
데이터의 최소값을 0으로, 최대값을 1로 변경
-
📌 참고 문헌
-
책
- 📕 파이썬 머신러닝 완벽 가이드 / 권철민
-
참조 자료
-
해당 챕터의 실습 및 예제 코드는 아래 링크의 Machine Learning 참조 해주시면 됩니다.
