https://raytracing-docs.nvidia.com/optix7/guide/index.html#acceleration_structures#accelstruct다음 API function들을 설명할 것이다.
optixAccelComputeMemoryUsage
optixAccelBuild
optixAccelRelocate
optixConvertPointerToTraversableHandle
optiX는 Scene의 geometry 데이터와 ray의 교차점 검색을 최적화하기 위한 acceleration structures를 제공한다. acceleration struction에는 geometry primitive와 instance의 두가지 유형의 데이터가 포함될 수 있다.
acceleration는 함수 집합을 사용하여 장치에서 생성된다. 이러한 함수를 사용하면 build라고 하는 acceleration structure 생성의 중첩 및 파이프라이닝이 가능하다. 함수는 하나 이상의 OptixBuildInput 구조체를 사용하여 geometry와 build를 제어하기 위한 파라미터 세트를 지정한다.
acceleration structure에는 크기 제한이 있다. instance acceleration structure의 경우 인스턴스 수에 상한이 있고, geometry acceleration structure의 경우 geometry primitives의 수, 즉 빌드 입력에 있는 프리미티브의 총 수에 motion key의 수를 곱한 수로 제한된다.
build input 타입은 다음과 같이 지원된다.
- Instance acceleration structures
OPTIX_BUILD_INPUT_TYPE_INSTANCES
OPTIX_BUILD_INPUT_TYPE_INSTANCES_POINTERS - A geometry acceleration structure containing built-int triangles
OPTIX_BUILD_INPUT_TYPE_TRIANGLES - A geometry acceleration structure containing built-in cureve primitives
OPTIX_BUILD_INPUT_TYPE_CURVES - A geometry acceleration structure containing build-int spheres
OPTIX_BUILD_INPUT_TYPE_SPHERES - A geometry acceleration structure containing custom primitives
OPTIX_BUILD_INPUT_TYPE_CUSTOM_PRIMITIVES
geometry 빌드를 위해 각 build input은 삼각형 집합, curve 집합, 구체 집합, 축으로 정렬된 경계 상자에 의해 경계가 지정된 사용자 정의 primitive 집합으로 구분한다.
여러 build input을 optixAccelBuild 함수에 배열로 전달하여 서로 다른 mesh를 acceleration structure로 합칠 수 있다.
모든 build input은 같은 유형의 입력으로 일치시켜야 한다.

instance acceleration structure는 단일 build input이 있으면 instance 배열로 지정한다. 각 instance에는 ray transformation, 다른 geometry acceleration structure를 참조하는 OptixTraversableHandle, transform node, 또 다른 instance acceleration structure를 포함한다.
build를 준비하기 위해 메모리 크기는 build 입력 및 파라미터 세트를 optixAccelComputeMemoryUsage에 전달하여 쿼리한다. 이 함수는 3가지 크기를 반환한다.
- outputSizeInBytes
acceleration structure의 결과에 대한 메모리 크기를 반환된다. 이 크기는 상한으로 accelration structure의 최종 크기보다 크다. - tempSizeInBytes
build 중에 사용될 임시 메모리의 크기 - tempUpdateSizeInBytes
acceleration structure를 업데이트하는데 필요한 임시 메모리 크기

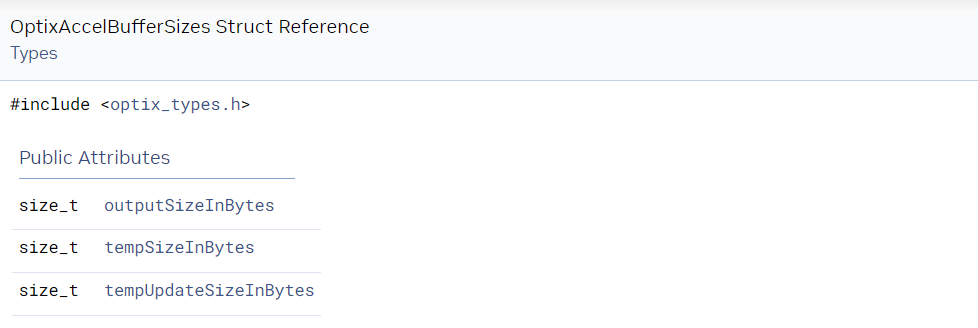
Application은 이 크기들을 이용해서 장치의 출력 및 임시 메모리 버퍼를 위한 메모리를 할당한다. 이러한 버퍼에 대한 포인터는 128바이트 경계(???)에 맞춰 정렬되어야 한다.
이러한 버퍼는 빌드 기간 동안 계속 사용된다. 따라서 버퍼는 현재 활성 상태인 다른 빌드 요청과 공유하면 안된다.
optixAccelComputeMemoryUsage 함수는 device에서 어떤 활동도 시작하지 않으며, 할당된 메모리를 가리키기 위해 device memory 또는 입력 버퍼의 내용을 가리키는 포인터가 필요하지 않는다.
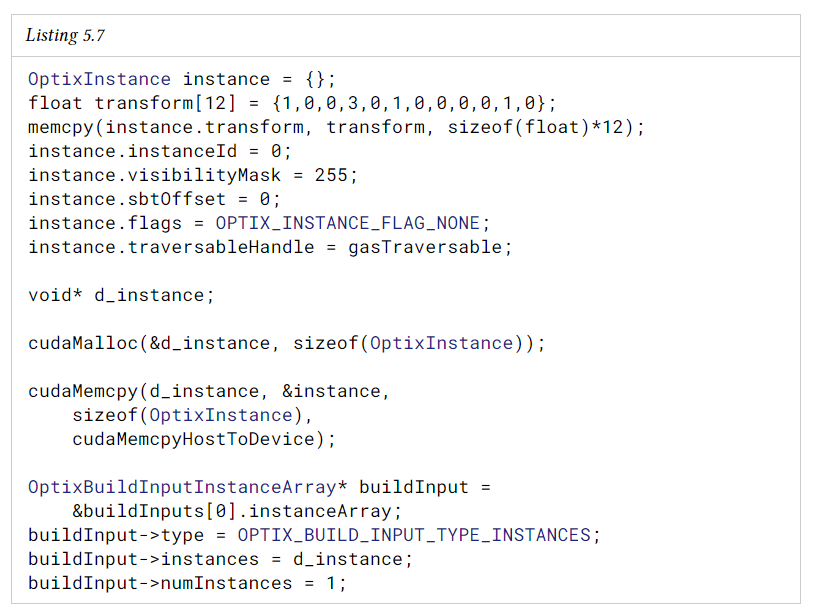
optixAccelBuild 함수는 optixComputeMemoryUsage와 동일한 optixBuildInpute 구조체 배열을 받아 이 입력으로부터 단일 acceleration structure를 build한다. 이 acceleration structure는 build input에 따라 geometry 또는 instance를 포함할 수 있다.
build operation은 지정된 CUDA stream의 device에서 실행되며 CUDA 커널 실행과 유사하게 장치에서 비동기적으로 실행된다. Application은 host 측 thread를 차단하거나 cudaStreamSynchronize 또는 CUDA Event와 같은 사용 가능한 CUDA 동기화 기능을 사용하여 다른 CUDA stream과 동기화하도록 선택할 수 있다.
반환된 traversable handle은 host에서 계산되며 빌드가 완료될 때까지 기다리지 않고 함수에서 즉시 반환된다. 가속 시간에 핸들을 생성함으로써 builder에 대한 입력을 기반으로 custom handle을 생성할 수 있다.(?)
optixAccelBuild에 의해 만들어진 acceleration structure는 build input에 참조된 device buffer를 수정하지 않는다. 모든 관련 데이터는 이러한 버퍼에서 가속 출력 버퍼로 복사되며, 다른 형식으로 복사될 수 있다.
Application은 acceleration structure를 빌드 후에 참조된 device buffer를 해제시켜도 된다. 하지만, instance build의 경우 다른 instance acceleration structure, geometr instance acceleration structure와 transform node들을 계속 참조하므로 메모리 해제를 하면 안된다.
다음은 단일 acceleration structure를 build 하는 예제이다.
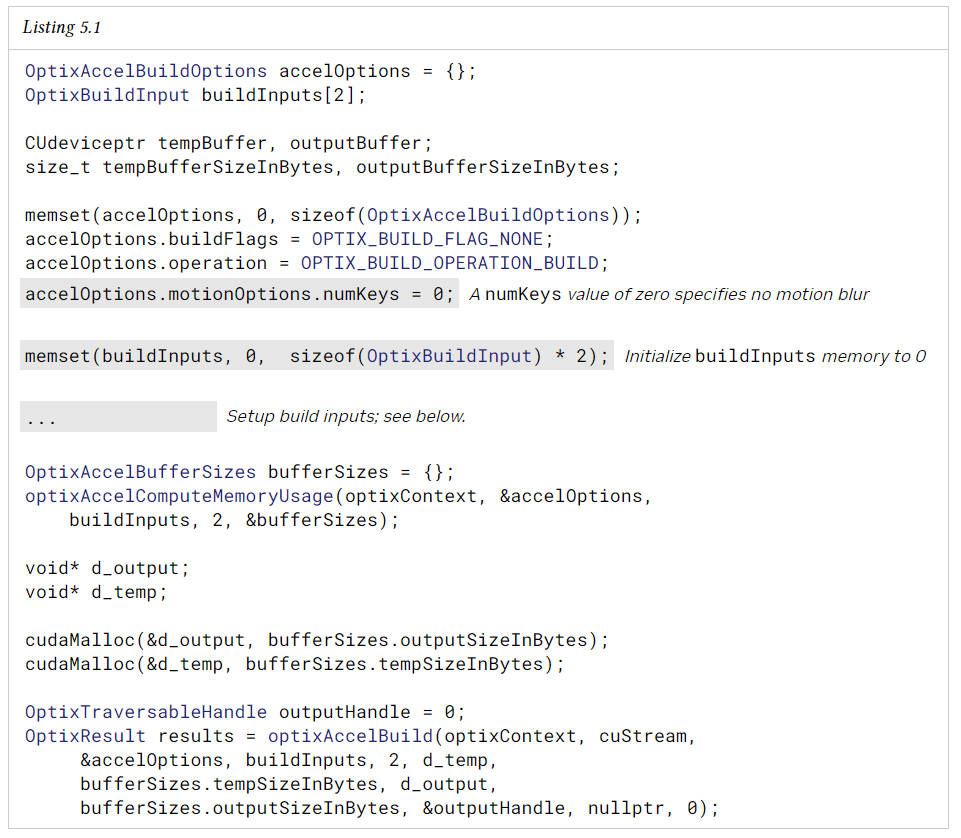
향후 버전과의 호환성을 보장하려면 특정 빌드 입력으로 채우기 전에 OptixBuildInput 구조체를 0으로 초기화해야 한다.
5.1 Primitive build inputs
triangle build input은 motion key당 하나의 버퍼(motion이 없는 경우 단일 triangle vertex buffer)로 디바이스 메모리에 있는 triangle vertex buffer array를 참조한다.
선택적으로 devcice memory의 index buffer를 사용하여 triangle을 indexing할 수 있다. 다양한 vertex 및 index 형식이 입력으로 지원되지만, 더 효율적으로 내부 형식(입력과 크기가 다를 수 있음)으로 변환할 수 있다.
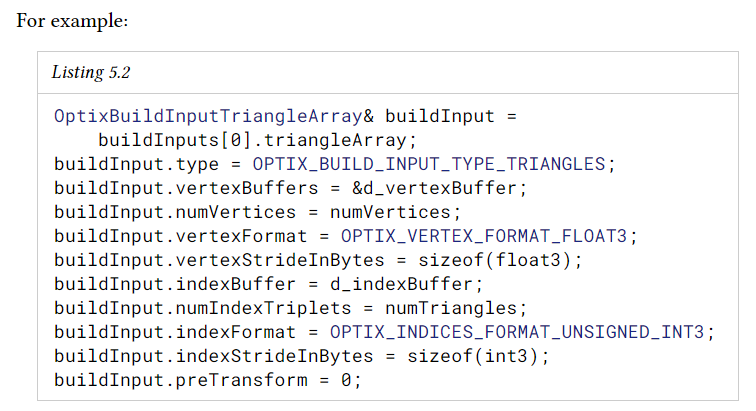
preTransform은 device memory에 있는 3x4 row-major transform matrix이다. 포인터는 16바이트로 정렬되어 있어야 하며, 행렬은 12개의 부동 소수점으로 되어있다. 이 옵션을 지정하면 runtime traversal overhead 없이 build 시 모든 vertex에 transform이 적용된다.
curve build input과 sphere input build도 triangle build input과 유사하다.
custom primitives에 대한 acceleration build input은 OptixBuildInputCustomPrimitiveArray 구조체를 사용한다. 각 custom primitive는 축으로 정렬된 바운딩 박스(AABB)로 표현되는데, 이는 x,y,z 값의 범위로 정의되는 직사각형이며 primitive를 완전히 둘러싸고 있어야 한다. AABB의 메모리 레이아웃은 구조체 OptixAaBB에 정의되어 있다. AABB는 motion key당 하나의 버퍼가 있는 장치 메모리의 버퍼 배열로 구성된다. 각 custom primitives의 정확한 모양은 해당 SBT(Shader binding table) record의 intersection program에 따라 달라진다.

optixAccelBuild 함수는 호출당 여러 빌드 입력을 허용하지만, 하나의 primitive(triangle, curve, sphere, aabb)로 통일되어야 한다. 단일 geometry acceleration structure에서 build input type이 혼합되는 것은 허용되지 않는다.
각 빌드 입력은 프로그램 dispatch를 제어하는 Shader binding table(SBT)의 하나 이상의 연속되는 record에 매핑된다.
SBT에 여러 레코드가 필요한 경우 Application은 해당 빌드 입력에 대한 primitive별 SBT record index가 있는 디바이스 버퍼를 제공해야 한다. 하나의 SBT record만 요청되면 모든 primitive가 동일한 SBT record를 참조한다. geometry acceleration structure당 참조되는 SBT record 수에는 제한이 있다는 점을 유의해야 한다.

또한 각 build input은 각 SBT record에 하나씩 OptixgeometryFlags 배열을 지정한다. 하나의 record에 대한 flag는 이 SBT record에 매핑된 모든 primitives에 적용된다.
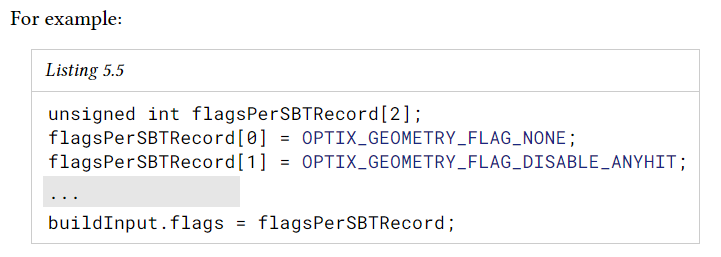
flag는 다음과 같다.
- OPTIX_GEOMETRY_FLAG_NONE
any-hit program을 여러 번 호출할 때 기본 동작을 적용하여 acceleration structure가 모든 최적화를 적용할 수 있도록 한다. - OPTIX_GEOMETRY_FLAG_REQUIRE_SINGLE_ANYHIT_CALL
acceleration structure builder와 관련된 일부 최적화를 비활성화 한다. 기본적으로 traversal는 교차하는 각 primitives에 대해 모든 hit program을 두 번 이상호출 할 수 있다. 이 flag를 설정하면 primitive와 hit할 때마다 모든 hit program이 한 번만 호출되도록 한다. 그러나 이 flag를 설정하면 traversal 성능이 변할 수 있다. 일부 rendering 알고리즘의 정확성을 위해 이 flag를 사용해야할 수 있다. (ex> 불투명도 또는 투명도 정보가 any-hit program에 누적되는 경우) - OPTIX_GEOMETRY_FLAG_DISABLE_ANYHIT
해당 SBT record에 any-hit program이 포함되어 있더라도 traversal가 이 primitives에 대해 any-hit program을 호출해서는 안 됨을 나타낸다. 이 flag를 설정하면 일반적으로 SBT에 any-hit program이 없더라도 성능이 향상된다.
build input 내의 primitives는 0부터 indexing 된다. 이 primitives index는 intersection, any-hit 및 closest-hit program 내에서 액세스할 수 있다. Application이 build input의 모든 primitive에 대해 이 인덱스를 offset하도록 선택하면 런타임에 오버헤드가 발생하지 않는다. 이는 연속적인 build input에 대한 데이터가 device memory에 연속적으로 저장될 때 특히 유용할 수 있다. primitiveIndexOffset 값은 교집합 intersection primitive를 report할 때만 사용된다.

5.2 Curve build inputs
삼각형과 custom primitive 외에도 optiX는 geometric primitives로서 곡선과 구를 지원한다. Curve는 머리카락, 모피, 카펫 섬유와 같이 길고 얇은 가닥을 표현하는데 사용된다. curve의 또 다른 변형인 리본(방향이 지정된 curve)은 풀잎 및 이와 유사한 용도로 사용할 수 있다. 장면에는 수천 또는 수백만 개의 커브가 포함될 수 있으며, 최종 이미지에서 커브의 폭은 몇 픽셀을 넘지 않는 경우가 많다.
각 curve는 제어점이라고 하는 3차원의 일련의 정점과 다양한 반경으로 정의되는 swept surface이다. optiX는 이러한 특성을 가진 curve를 제공한다.
- curve geometry는 B-spline curve, quadratic B-spline curve, Catmull-Rom spline curve, Bezier curve, 또는 선형 세그먼트로 정의된다.
- curve primitive의 단면은 원이다.
- quadratic B-spline curve의 경우 단면은 리본이라고 하는 평면 방향 curve를 표현할 수 있는 직선 세그먼트일 수도 있다. 이는 curve 축을 따라 움직이는 직선을 swept하여 형성되는 ruled surfaces 이다.
- radius는 각 제어점에 지정된다. radius는 위치와 동일한 spline 기준을 사용하여 커브를 따라 보간된다.
- 리본의 경우 normal을 지정할 수 있지만 필수는 아니다.
- linear curve는 spherical end caps이 있으며, segment 사이의 매끄러운 연결을 위해 구형 'elbows'가 있다. 기본적으로 end of cubic, quadratic spline은 개방형이며, caps가 없다. end of cubic, quadratic spline의 flat and caps은 OptixBuildInputCurveArray::endcapFlags 및 OptixBuiltinlSOption::curveEndcapFlags를 OPTIX_CURVE_ENDCAP_ON으로 설정하여 활성화할 수 있다.
spline curves는 일련의 다항식 세그먼트로 구성된다.
각 segment는 curve type에 따라 2개 또는 3개 또는 4개의 제어점으로 정의된다.
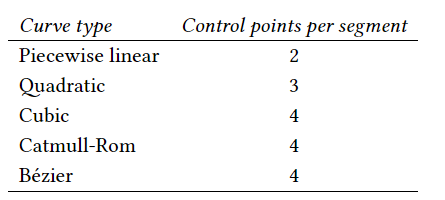
optiX는 각 다항식 세그먼트를 고유한 primitive ID를 가진 primitive로 간주한다.
curve build input (OptixBuildInputcurveArray)은 motion key 당 하나의 버퍼(motion이 없는 경우 단일 vertex buffer)로 device memory에 있는 vertex buffer array를 참조한다. 이와 병행하여 device memory에 있는 motion key당 하나의 버퍼로 구성된 radius vuffer array가 있어 각 motion key의 각 control vertex에서 radius 값을 제공한다. device memory에는 (필수) index 버퍼가 있다. 리본은 vertex buffer와 평행한 optional normal vertex를 참조할 수도 있다.
각 curve strand의 B-spline 제어점은 vertex buffer에 순차적으로 나타낸다. index array에는 segment 당 하나의 index, 즉 세그먼트의 첫 번째 제어점의 index가 포함된다.
예를 들어, 세 개의 세그먼트가 있는 직육면체 curve는 6개의 정점을 갖습니다. index array에는 {10,11,12}가 포함될 수 있으며, 이 경우 3개의 세그먼트는 제어점을 갖는다. : {v[10], v[11], v[12], v[13]}, {v[11], v[12], v[13], v[14]}, {v[12], v[13], v[14], v[15]}.
기본의 vertex buffer는 quadratic B-spline 제어점을 저장하는 반면, 노멀 버퍼는 리본 세그먼트의 경계에 있는 노멀을 포함한다. 세 개의 세그먼트가 있는 리본 strand는 5개의 제어점을 저장한다. 노멀을 지정하면 세 개의 세그먼트에 4개의 normal이 필요하다. curve 세그먼트를 따라 선형적으로 보간된다. 예를 들어 리본 가닥에 인덱스 {0,1,2} 가 있다. 이 경우 세그먼트의 제어점은 {v[0], v[1], v[2]}, {v[1], v[2], v[3]}, {v[2], v[3], v[4]}, normal의 경우 {n[0], n[1]}, {n[1], n[2]} and {n[2], n[3]}. 를 사용한다. 인덱스 i인 세그먼트 제어점은
{v[i], v[i+1], v[i+2]}, normal은 {n[i], n[i+1]}를 사용한다. 리본 strand에는 노멀보다 제어점이 하나 더 있다는 점을 유의해야 한다. index는 정점과 노멀을 모두 주소 지정하는데 사용되므로, normal은 strand 끝에 사용되지 않는 벡터로 채워야 한다.
strand의 끝에 end cap이 나타난다. optiX는 세그먼트 제어 포인트의 중첩을 확인하여 strand를 감지한다. B-spline strand 내에서 인접한 세그먼트는 제어점 중 하나를 제외하고 모두 겹친다.
즉, indexArray[N+1]이 indexArray[N]+1과 같지 않는 한, 세그먼트 N은 한 strand의 끝이고 세그먼트 N+1은 다른 strand의 시작이다.
curve 부분은 정확히 이해x5.3 Sphere build inputs
curve와 비슷하게 optiX는 구에 대한 geometric primitves를 제공한다. 구는 분자, 스프레이, 연기 등을 표현하기 위해 다양한 Application에서 사용할 수 있다.
각 구체는 3차원 중심점과 반지름으로 정의된다.
sphere build input(OptixBuildInputSphereArray)은 motion key당 하나의 buffer(motion이 없는 경우 단일 버퍼)로 중심점을 저장하는 device memory의 vertex buffer array를 참조한다. 이와 병행하여 device memory의 device memory에는 motion key당 하나의 buffer로 구성된 radius buffer array가 있어 각 motion key의 각 vertex에 radius를 제공한다. 모든 구체가 motion key당 동일한 반경을 갖는 경우 단일 radius flag가 설정되어 있으면 radius buffer당 하나의 radius이면 된다.
5.4 Instance build inputs
instance build input은 device memory에 OptixInstance 구조체의 버퍼를 지정한다. 이러한 구조체는 연속된 구조체의 배열 또는 해당 구조체에 대한 포인터 배열로 지정할 수 있다. 각 instance 설명은 다음과 같다.
- A child tranversable handle
- A static 3x4 row-major object-to-world matrix transform
- A userID
- An SBT offset
- A visibility mask
- Instance flags
Instance는 Geometry Accleration structure의 handle을 받아서 만들어진다.
Instance array는 이러한 intance의 array를 얘기하는 것이고, Instance Acceleration Structure는 Instance array를 입력받아서 만들어진 acceleration structure이다.triangle과 AABB input과는 다르게 optixAccelBuild는 빌드 호출 당 하나의 instance build input만 허용한다.
가능한 instance 수(Optixinstance 구조체의 버퍼 크기), SBT offset, visibility mask, user ID에 대한 상한이 있다.
OPTIX_BUILD_INPUT_TYPE_INSTANCE_POINTERS build input은 instanceDescs가 device memory에 있는 optixInstane 구조체에 대한 포인터의 device memory array를 참조하는 OPTIX_BUILD_INPUT_TYPE_INSTANCES build input의 변형이다.
Instance flag는 Instance에 연결된 geometry acceleration structure를 travel하는 동안 만나는 primitives에 적용된다. 이 flag는 모든 부모 instance acceleration structure를 travel하는 동안 설정된 모든 instance flag를 재정의 한다.
- OPTIX_INSTANCE_FLAG_DISABLE_TRIANGLE_FACE_CULLING
triangle에 대한 face culling을 비활성화 한다. optixTrace에 전달된 culling ray flag를 override한다. - OPTIX_INSTANCE_FLAG_FLIP_TRIANGLE_FACING
intersection하는 동안 triangle normal vector의 방향을 뒤집는다. 이는 culling에도 영향을 준다. - OPTIX_INSTANCE_FLAG_DISABLE_ANYHIT
primitive 교차로에 대한 any-hit call을 비활성화한다. 이는 ray flag에 의해서 override 될 수 있다. - OPTIX_INSTANCE_FLAG_ENFORCE_ANYHIT
primitive intersection에 대한 any-hit call을 강제한다. 이는 ray flag에 의해서 override 될 수 있다.
visibility mask는 ray mask와 결합되어 이 instance에 대한 visibility를 결정한다. rayMask & instance.mask == 0 조건이 참이면 instance가 컬리된다. visibility mask는 ray와 instance를 8개의 (program??) 그룹 중 하나에 할당하는 것으로 해석할 수 있다. instance와 ray가 적어도 하나 이상의 공통 그룹을 가질 때만 instance가 travels된다.
sbtOffset은 OptixShaderBindingTable의 hitgroupRecordBase 파라미터로 지정된 hit groups(intersection, any-hit, closest-hit)에 대한 SBT에 대한 offset이다. 이 instance의 primitive 부분이 교차하는 경우 실행할 hit group program을 선택하기 위해 SBT에 간단한 덧셈 오프셋으로 사용된다.
insatnce의 자식이 transform object (OptixStaticTransform, OptixMatrixMotionTransform, OptixSRTMotion Tranform, travelsable object)의 경우, transform chain 끝에 있는 geometry acceleration structure의 primitive에 닿을 때, instance의 sbtOffset 값이 여전히 적용된다. 지원되는 최대 SBT offset은 OPTIX_DEVICE_PROPERTY_LIMIT_MAX_SBT_OFFSET과 함께 optixDeviceContextGetProperty를 사용하여 query할 수 있다. 여러 level의 insatnce acceleration structure object가 있는 traversal graph에서는 offset이 합산된다. 즉, geometry acceleration structure의 offset은 순회 가능한 그래프에 있는 모든 조상 instance의 합한 값이다. 지원되는 최대 합산 SBT offset는 단일 instance의 최대 SBT offset과 같다.
단일 geometry acceleration struct만 사용해서 ray tracing이 가능하지만, instance acceleration struct로 단일 geometry acceleration struct를 감싸서 ray tracing할 수도 있다.
이렇게 intance acceleration struct를 통해서 하면 추가적인 옵션을 더 넣을 수 있다는 장점이 있다.5.5 Build flags
acceleration structure는 OptixBuildFlags 열거형을 통해서 조정할 수 있다. acceleration structure에서 vertex에 대한 임의의 접근(random access)을 활성화 하려면 OPTIX_BUILD_FLAG_ALLOW_RANDOM_VERTEX_ACCESS를 사용한다.
빌드 성능, runtime travels 성능, acceleration struct memory 사용량 간의 절충점을 조정하려면, OPTIX_BUILD_FLAG_PREFER_FAST_TRACE 및 OPTIX_BUILD_FLAG_PREFER_FAST_BUILD를 사용하면 된다.
특히 curve primitive의 경우, 이러한 flag들은 분할 제어를 한다. (???)
OPTIX_BUILD_FLAG_PREFER_FAST_TRACE와 OPTIX_BUILD_FLAG_PREFER_FAST_BUILD는 상호배제적이다. 여러 flag를 혼합해서 사용하려면 상호배제적이면 안되고 OR 연산자를 통해서 혼합할 수 있다.
5.6 Dynamic updates
acceleration structure를 만드는데는 cost가 많이들 수 있다. Application은 수정된 vertex data 또는 bounding box를 사용하여 기존 acceleration struct를 업데이트하도록 선택할 수 있다. 기존 accerleration struct를 업데이트 하는 것은 일반적으로 재구축보다 훨씬 빠르다. 하지만 update 시 폭발이나, 많은 전환 등의 효과로 데이터가 너무 많이 변경되면 acceleration struct의 구조의 품질이 저하될 수 있다.(mesh의 일부분이 변경되는 경우에도) acceleration struct가 저하되면 수정된 input data로 처음부터 acceleration struct 구축한 경우와 비교하여 traverse 성능이 느려질 수 있다.
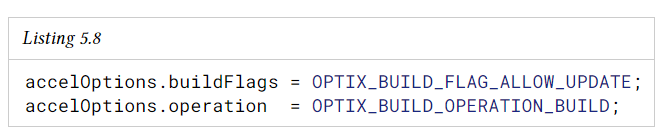
acceleration struct의 업데이트를 허용하려면 acceleration struct를 처음 build할 때 build flag에 OPTIX_BUILD_FLAG_ALLOW_UPATE를 주면 된다.
이전에 빌드한 acceleration struct를 update하려면 OPTIX_BUILD_OPERATION_UPDATE로 연산을 설정한 다음 동일한 출력 데이터로 optixAccelBuild를 호출해야 한다. 다른 모든 옵션은 원래 build와 동일해야 한다. update는 출력 데이터에서 즉시 수행된다.
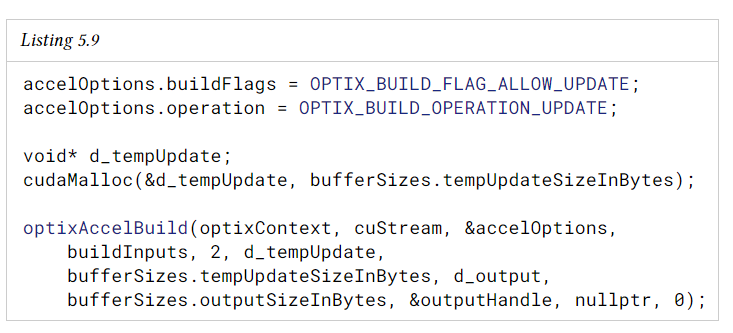
acceleration struct를 update하려면 일반적으로 원래의 build와 다른 크기의 임시 메모리가 필요하다.
기존 acceleration struct를 update할 때는 device pointer 또는, buffer contents만 변경할 수 있다. build input 수, build input type, build flag, instance acceleration struct의 travelable handle, vertex, index, AABB, instance, SBT record 또는 motion key의 수는 변경할 수 없다. 이러한 항목을 변경하려면 GPU 오류와 같은 정의되지 않은 동작이 발생할 수 있다.
그러나 다음 두 가지의 경우에는 geometry acceleration struct 또는 instance acceleration struct를 다시 build하거나 각각의 masking 및 flag를 사용하는 것이 더 효율적이다.
- index를 사용할 때 연결성을 변경하거나 일반적으로 shuffled vertex position을 사용하면 작동하지만 acceleration struct의 품질을 크게 저하할 수 있다.
- 애니메이션 작업 중에 카메라에 보이지 않아야 하는 geometry를 아주 멀리 이동하거나 변형된 형태로 변환하여 씬에서 제거해서는 안된다. 이렇게 geometry를 변경하면 acceleration struct의 품질도 저하된다.
acceleration struct flag OPTIX_BUILD_FLAG_ALLOW_UPDATE를 설정하면 curve primitive를 처리할 때 가속 구조체의 성능이 저하될 수 있다.
acceleration struct를 업데이트하려면 업데이트하려는 acceleration struct를 자식으로 직간접적으로 사용하고 있는 다른 acceleration struct도 업데이트하거나 다시 build 해야 한다.
보통 Dynamic update는 뒤에서 설명할 compact(메모리 양을 줄임) 한 후, 다시 update 하는 것을 얘기한다.
5.7 Relocation
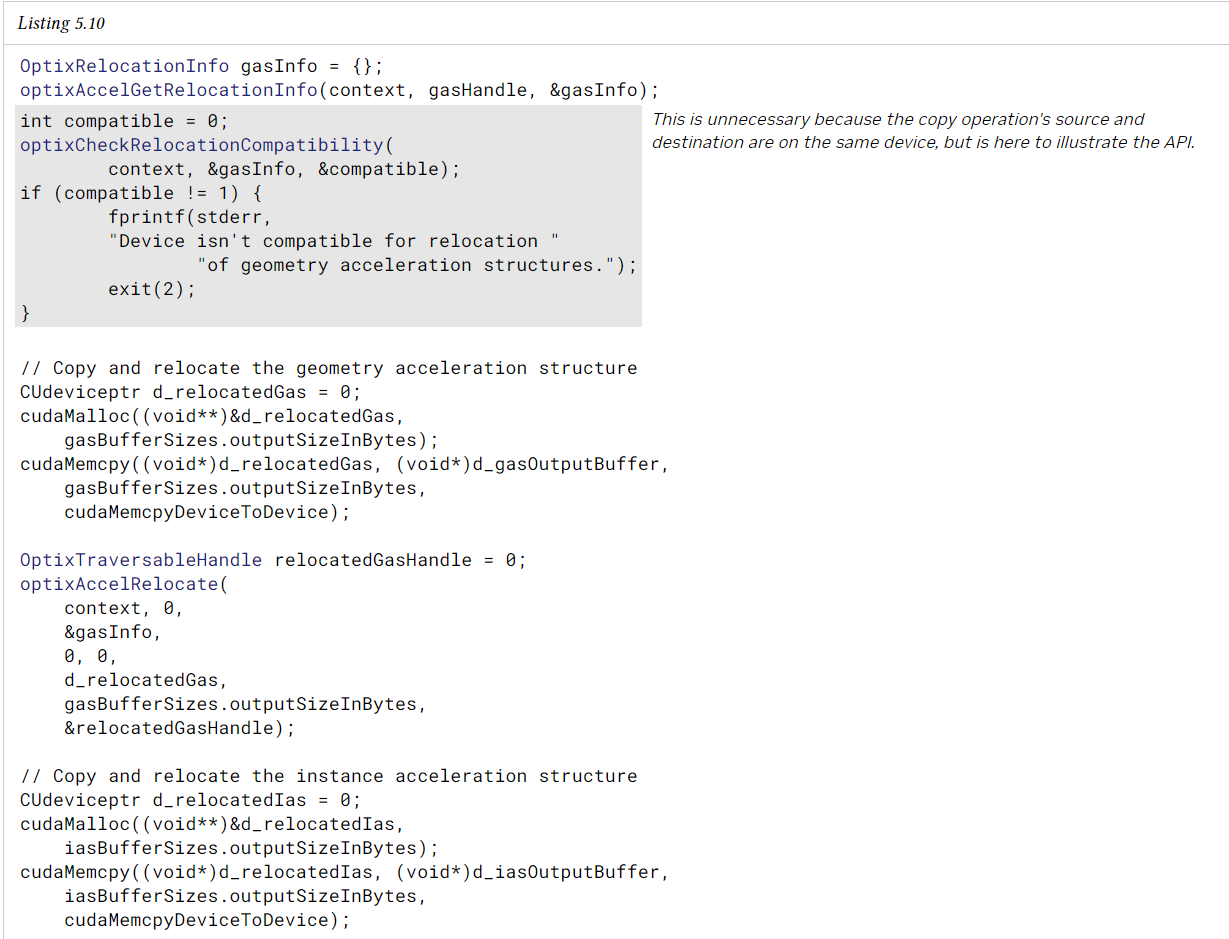
geometry acceleration struct는 복사 및 이동이 가능하지만, 복사된 acceleration struct를 업데이트하고, 새로운 traversal handle을 생성하기 위해 optixAccelRelocate를 호출할 때까지는 사용할 수 없다. compacted acceleration struct를 포함하여 모든 acceleration struct를 relocation할 수 있다.
relocation은 acceleration struct의 메모리 위치를 변경할 때 사용하는 것으로, 이는 다른 device나 메모리 위치로 이동할 때 사용된다.복사본이 원래 device에 있을 필요는 없다. 이렇게 하면 acceleration struct를 다시 빌드하지 않고도 acceleration struct 데이터를 호환되는 다른 장치로 복사할 수 있다.
acceleration struct를 relocation하려면 acceleration struct의 traversal handle과 acceleration struct의 optixAccelGetRelocationInfo 함수를 사용하여 optixRelocationInfo 객체가 채워진다. 그런 다음 이 객체를 사용하여 device로의 재배치가 가능한지 여부를 결정할 수 있다.(OptixDeviceContext에 지정된 대로) 이 작업은 optixCheckRelocationCompatibility 함수를 사용하면 할 수 있다. 대상 device가 호환되는 경우, source acceleration struct는 이후 optixAccelRelocate를 호출하여 해당 device로 복사할 수 있다.
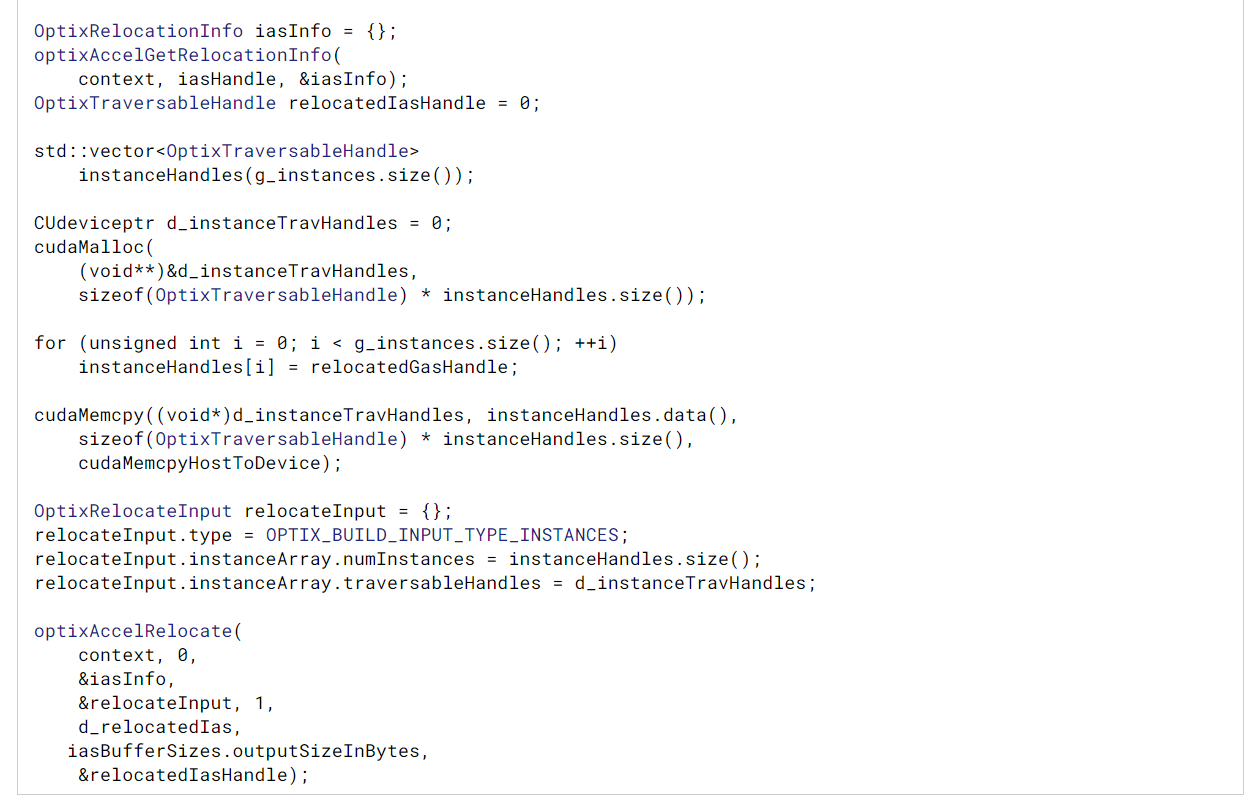
instance acceleration struct가 참조하는 traversal와 삼각형 geometry acceleration struct가 참조하는 OMM(opacity micromap???)은 relocate해야 한다. optixAccelRelocate에 대한 인자인 relocateInputs와 numRelocateInputs는 relocated traversal와 OMM을 지정하는데 사용한다.
instance acceleration struct가 참조하는 traversal와 geometric acceleration struct가 참조하는 OMM은 추가적으로 재배치해줘야 한다는 말
relocate 후 relocated acceleration struct는 source 대신 relocated travelsal과 OMM을 참조한다. relocated input numRelocateInputs의 수는 source acceleration struct를 build하는 데 사용된 build input numBuildInputs의 수와 일치해야 한다. relocate input은 source acceleration struct를 빌드하는데 사용되는 빌드 numRelocateInputs는 0일 수 있으며, source acceleration struct의 travelsable 및 OMM에 대한 값을 유지한다. OptixRelocateInputInstanceArray는 device buffer를 지정한다.
OptixRelocateInputInstanceArray::traversableHandles handle instance 당 하나씩, 재배치된 traversable에 대한 handle이다.
OptixRelocateInputInstanceArray::traversableHandles은 아마 0이며, source input에서 traversable 및 OMM에 대한 모든 reference를 유지한다.
geometric bounds of the accelerationstruct는 업데이트 되지않으므로 OptixRelocateInputInstanceArray::traversableHandles은 relocated source traversable에 대응해야 한다는 점을 유의해야 한다.
OptixRelocateInputTriangleArray는 reloacted OMM, OptixRelocateInputTriangleArray::opacityMicromap을 지정할 수 있다. OptixRelocateInputTriangleArray::opacityMicromap는 0일 것이고, source input에서 OMM에 대한 모든 참조를 유지한다.
OptixRelocateInputTriangleArray::numSbtRecords는 해당 값인 OptixBuildInputTriangleArray::numSbtRecords와 동일해야 한다.
다음 예제는 geometry와 instance acceleration struct를 동일한 device의 새로운 CUDA 할당으로 relocate하는 것이다.
5.8 Compacting acceleration structures
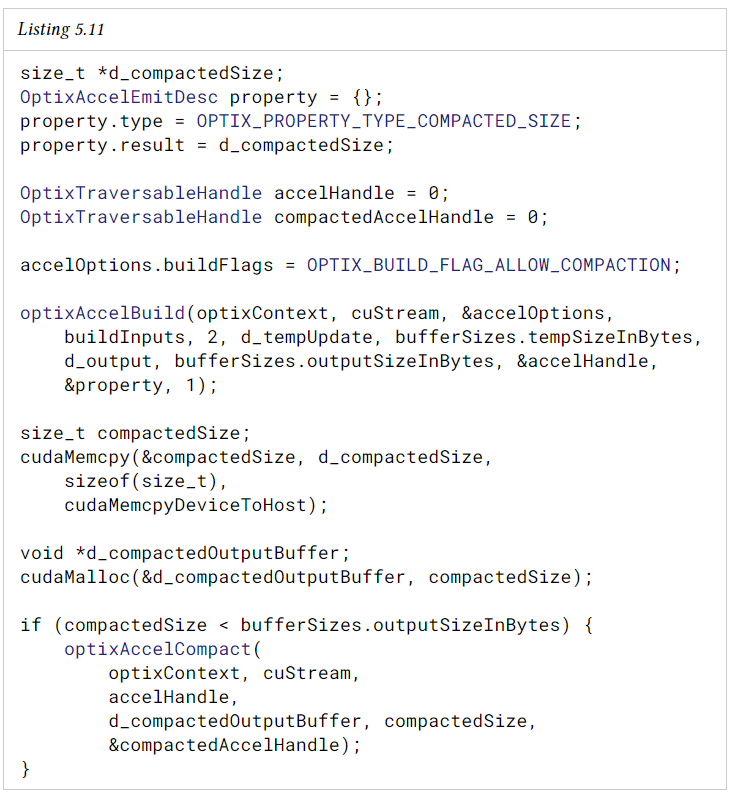
acceleration structure를 구축 후, post-process로 acceleration structure를 compact할 수 있다.
이 과정은 메모리 사용량을 크게 줄일 수 있지만 추가적인 pass가 필요하다. build 및 compaction 작업은 device synchronization로 인해 성능이 저하되지 않도록 일괄적으로 수행하는 것이 가장 좋다. 압축된 크기는 acceleration structure type과 properties 및 device 아키텍처에 따라 달라진다.
post-process로서 acceleration structure를 compact하는 과정은 다음과 같다.
-
optixAccelBuild 함수의 인자로 OptixAccelBuildOptions를 넘길 때 OPTIX_BUILD_FLAG_ALLOW_COMPACTION flag를 주어야 한다.
-
optixAccelBuild에 전달된 optixAccelEmitDesc 구조체에서 emit property, OPTIX_PROPERTY_TYPE_COMPACTED_SIZE를 설정해야 한다. 이 property는 device에서 생성되며 새 출력 버퍼를 할당하는 데 필요한 경우 host에 다시 복사해야 한다. 그런 다음 Application은 optixAccelCompack를 사용하여 acceleration struct를 compact하도록 선택할 수 있다.
-
optixAccelCompack 함수의 호출이 좋지 않은 경우, compact pass를 피하기 위해 if(compactedSize < outputSize) (또는 비슷한 경우)로 피해야 한다. 이 검사는 device memory에서 host memory로 압축된 크기 복사본 (optixAccelBuild에서 query한 대로)이 필요하다는 점을 알아야 한다.
압축되지 않은 acceleration struct와 마찬가지로, compacted acceleration struct 또한 traverse, update, relocated할 수도 있다.
compacted acceleration structure는 uncompacted acceleration structure를 참조하지 않는다. Application은 compacted acceleration structure를 release하지 않고, uncompacted acceleration structure를 자유롭게 사용할 수 있다. 그러나 compacted acceleration structure의 메모리는 uncompacted acceleration structure와 메모리가 겹치면 안된다.
compacted acceleration structure는 uncompacted acceleration structure가 OPTIX_BUILD_FLAG_ALLOW_UPDATE build flag를 사용하여 빌드된 경우에만 dynamic update를 지원한다. dynamic update에 필요한 임시 메모리의 양은 uncompacted acceleration structure와 compacted acceleration structure에서 동일하다. 다음 build flag를 사용하면 compacting post-process를 활성화할 때 메모리를 절약하는 효과가 적어진다.
- OPTIX_BUILD_FLAG_ALLOW_UPDATE
- OPTIX_BUILD_FLAG_PREFER_FAST_BUILD
