https://raytracing-docs.nvidia.com/optix7/guide/index.html#acceleration_structures#traversable-objectsacceleration struct를 AS라고 표현 예정이다.
geometry acceleration struct는 GAS,
instance acceleration struct는 IAS로 표현여기 내용은 이해가 안 돼서 무슨 소리인지 이해 못하고 적음Traversable objects
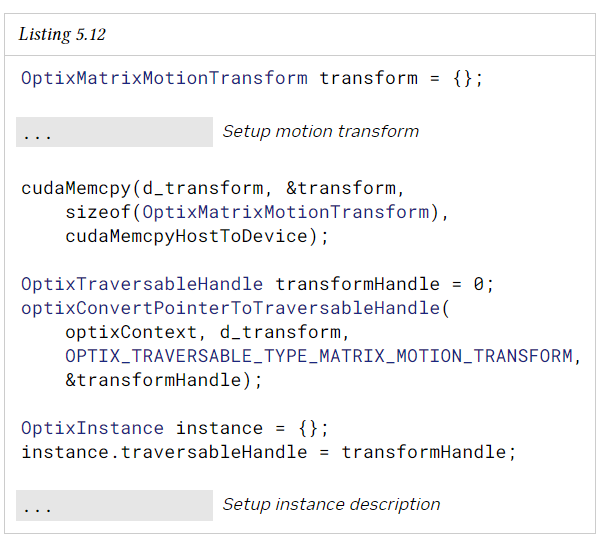
instance-AS의 instance는 geometry-AS뿐만 아니라 transform traversable을 참조할 수 있다. transform traversable은 Application에서 관리한다. Application은 이러한 traversable을 특정 형식으로 device memory에 수동으로 생성해야 한다. optixConverterPointerToTraversableHandle을 변환하는 함수는 raw pointer를 지정된 유형의 traversable handle로 변환한다. 그런 다음 traversable handle을 사용하여 traversable을 서로 연결할 수 있다.
device memory에서 모든 traversable object는 64-byte로 정렬이 되어있어야 한다. traversable을 메모리의 다른 위치로 이동하면 traversable handle이 쓰레기 값이 된다. Application은 새 traversable handle을 생성하고 무효화된 traversable handle을 참조하는 다른 traversable을 업데이트해야 한다.
traversable handle은 opaque하기에 Application은 traversable handle에 대한 포인터의 매핑에 의존해서는 안된다.
5.9.1 Traversal of a single geometry acceleration structure
optixTrace 함수에 전달되는 traversable handle은 geometry-AS에서 생성된 traversable handle로 전달할 수 있다. 이는 단일 geometry-AS object가 scene graph의 root를 나타내는 scene에 유용하다.
module과 pipeline은 단일 geometry-AS traversable로 지원해야 하는 경우, OptixPipelineCompileOptions::traversableGraphFlag를 OPTIX_TRAVERSABLE_GRAPH_FLAG_ALLOW_ANY에서 OPTIX_TRAVERSABLE_GRAPH_FLAG_ALLOW_SINGLE_GAS로 변경하는 것이 더 좋다.
이는 traverse 중에 다른 traversable type에 대한 지원이 필요하지 않다는 정보를 OptiX에게 전하는 것이다.
5.10 Motion blur
OptiX의 motion 지원은 확률적 시간 샘플링을 사용하여 motion blur가 있는 이미지를 렌더링하는 것을 목표로 한다. optiX는 장면의 일부로 transform motion과 vertex motion (흔히 deformation motion이라고도 불린다.)이라는 2가지 type의 motion을 지원한다.
scene traversal graph를 설정하고 AS를 build할 때 motion option은 AS와 traversable motion transform별로 지정할 수 있다. runtime에 time parameter가 trace call에 전달되어 선택한 시점의 scene에 대한 ray intersection을 수행한다.
optiX motion 기능의 일반적인 설계는 많은 parameter를 제공하여 높은 수준의 자유도를 제공하는 것과 동시에 높은 traverse 성능을 제공하는 것 사이에서 균형을 맞추기 위해서 노력하고 있다.
OptiX는 다음과 같은 주요 기능을 지원한다.
- vertex and transformation motion
- Matrix뿐 아니라 SRT(scale rotation translation) transform까지
- 임의의 시간 범위([0,1]로 제한하지 않는다.) 그리고 플래그를 사용하여 시간 범위 밖의 동작을 지정할 수 있다.
- tansformation 사이의 연결(ex> SRT transformation 위에 행렬 변환)
- ray별 timestamps
motion이 포함되는 Scene description은 optix가 제공하는 traversable object와 해당 motion option에 쉽게 mapping되어야 한다. 따라서 motion option이 scene description에서 직접 파생되어 성능 중심의 조정 없이도 높은 traverse 성능을 제공한다는 idea다. 그러나 피사체의 복잡성으로 인해 이 section에서 설명하는 몇 가지 예외가 있다.
이 section에서는 다양한 traversable type에 대한 motion option의 사용법과 성능 하락을 피하기 위해 scene option을 가장 잘 매핑하는 방법을 자세히 설명한다.
optiX에서 motion을 활성화하려면 OptixMotionOptions 구조체의 numKeys 값을 1보다 크게 설정해야 한다. numKeys가 1보다 크면 motion이 활성화되고, 그렇지 않다면 motion이 비활성화 된다. motion이 비활성화되면 timeBegine, timeEnd 및 flags는 모두 무시된다. 이외에도 motion blur를 추가하려면 모든 module을 usesMotionBlur와 ovverideUseMotionBlur가 true로 설정된 상태로 컴파일하고 링크해야 된다.5.10.1 Basics
motion은 OptixMatrixMotionTransform, OptixSRTMotionTrasnform 및 AS traversable에 지원된다. 일반적인 motion의 특성은 motion key의 수, flag, 첫 번째 key와 마지막 key에 해당하는 시작 및 종료 motion 시간 등 motion 옵션으로 traversable마다 지정된다. 나머지 motion key는 시작 시간과 종료 시간 사이에 균등한 간격을 준다. motion key는 특정 시점의 데이터이며 데이터는 인접한 key 사이에서 interpolation된다. 모든 옵션은 OptixMotionOptions 구조체에 지정된다.
motion option은 항상 traversable (AS or motion transform) 별로 지정된다. traversable의 motion option 간에는 종속성이 없으며, motion이 있는 geometry AS를 참조하는 instance가 있다면 motion이 있는 intance AS를 빌드할 때 필요가 없다. motion transform도 마찬가지이다. instance가 motion transform을 child traverse 가능으로 참조하더라도 instance AS 자체에 모션이 있을 수도 없을 수도 있다.
motion transform은 motion 시작 시간이 종료 시간보다 엄격하게 작은 motion key를 2개 이상 지정해야 한다. 그러나 AS는 OptixMotionOptions field가 0으로 설정된 OptixAccelBuildOptions도 허용한다. 이렇게 하면 AS의 motion이 효과적으로 비활성화되고 motion flag와 함께 motion 시작 및 종료 시간이 무시된다.
optiX는 instance의 static transform 외에도 static tansform traversable도 지원한다. static transform은 scene의 motion transform을 위한 것이다. traversable graph에 motion transform(OptixMatrixMotionTransform, OptixSRTMotionTransform)이 없는 경우 모든 static transform은 instance transform에 적용해야 한다. 그러나 motion transform이 있는 경우 motion transform을 적용하기 전에 traversable (ex> geometry-AS)에 static transform을 먼저 적용해야 한다. 예를들어 motion transform을 월드 좌표로 지정할 수 있지만, 이를 적용하는 geometry를 먼저 scene에 먼저 배치해야 한다.(object-world 간 transform은 일반적으로 instance transform을 사용하여 수행됨). 이 경우 GAS를 가리키는 static transform을 world-to-transform에 사용할 수 있으며 motion transform을 가리키는 instance transform은 transform으로 identity matrix를 갖게 된다.
motion boundary 조건은 flag를 사용하여 지정한다. 기본적으로 시간 범위를 벗어난 시간에 대한 동작은 마치 시간이 범위에 고정된 것처럼 보이므로 정적으로 표시되어 보인다. 또는 시작 시간 전에 traversable을 제거하려면 OPTIX_MOTION_FLAG_START_VANISH를 설정하고, 종료 시간 이후에 제거하려면 OPTIX_MOTION_FLAG_END_VANISH를 설정한다.

optiX는 motion key당 하나의 transform(SRT or Matrix)을 지정하는 두 가지 유형의 motion transform, SRT와 3x4 affine matrices를 제공한다. transform은 instance transform과 마찬가지로 항상 object-to-world transform으로 지정된다. traverse 중 optiX는 가장 가까운 두 개의 key에 대해 컴포넌트 별 linear interpolation을 수행한다. SRT의 회전 컴포넌트(쿼터니언으로 표현)는 예외이며, OptiX는 성능상의 이유로 nlerp 보간을 사용하여 두 SRT의 보간된 쿼터니언이 단위 길이를 갖도록 한다. 그 결과 속도가 일정하지 않더라도 직교 공간에서 scale을 유지하며 부드럽게 rotation할 수 있다.
vertex motion의 경우 OptiX는 Application에서 제공한 vertex data 사이에 선형 보간을 적용한다. intersection program을 사용하고 custom primitive에 대해 AABB가 제공된 경우, intersection 시에도 AABB가 선형 보간 된다. 따라서 motion key의 AABB는 기본 custom primitive의 motion path를 모두 포함할 수 있도록 커야 한다.
optixTrace와 같이 시간 파라미터를 갖고 traversable 설정된 motion option을 준수하는 device 측의 함수가 몇 가지 있다.
traversable은 AS의 계층 구조를 나타내는 개념이다. 이 구조는 ray tracing을 최적화하기 위해 사용된다.
다양한 유형의 변환을 지원하며, 이러한 변환은 OptixStaticTransform, OptixMatrixMotionTransform 및 OptixSRTMotionTransform과 같은 구조체로 표현된다.
traversable graph는 Optix ray tracing engine에서 사용되는 개념으로 GAS, IAS의 계층 구조를 나타낸다.
이 graph는 ray tracing에서 ray가 geometry와 상호작용을 하는 방식을 얘기한다.
만면 traversable은 GAS와 IAS를 포함하는 개념으로, Traversable은 ray tracing에서 ray가 geometry와 상호작용하는 방식을 정의하는데 사용되는 데이터 구조이다.static transform은 OptixStaticTransform 구조체로 정의하며, object-to-world 변환을 정의하기 위해서 3x4 row-major한다.
motion transform은 물체의 움직임을 표현하기 위한 변환이다.
vertex motion는 vertex들의 위치가 시간에 따라 변화하는 motion을 의미한다.5.10.2 Motion geometry acceleration structure
optixAccelBuild를 사용하여 motion AS를 빌드한다. motion option은 build option(OptixAccelBuildOptions)의 일부이며 모든 build input에 적용된다. build input은 모든 motion key에 대해 primitive vertex buffer (OptixBuildInputTriangleArray, OptixBuildInputCurveArray, OptixBuildInputSphereArray), radius buffer (OptixBuildInputCurveArray, OptixBuildInputSphereArray), AABB buffer (OptixBuildInputCustomPrimitiveArray 및 OptixBuildInstanceArray)를 지정해야 한다. 이러한 buffer는 순회하는 동안 interporlation되어 시작 시간과 종료 시간 사이의 연속적인 motion vertex와 AABB를 얻는다.

motion option은 일반적으로 GAS의 motion option에 직접 매핑되어야 하는 mesh data에 의해 정의된다. 예를 들어, triangle mesh의 vertex motion 값이 3개인 경우 GAS에는 motion key가 3개 있어야 한다. motion이 없는 mesh와 마찬가지로 단일 GAS 내에서 mesh를 결합하여 잠재적으로 traverse 성능을 향상시킬 수 있다. (각 mesh의 instance가 하나만 있고 mesh가 겹치거나 서로 가까운 경우 일반적으로 권장된다.) 그러나 이러한 mesh는 GAS별로 지정되므로 동일한 motion option을 공유해야 한다. interactive application에서와 같이 한 frame에서 다른 frame으로 mesh를 업데이트해야 하는 경우 일반적인 절충안이 적용된다. 적어도 하나의 mesh 정점이 변경되면 전체 GAS를 다시 빌드하거나 다시 맞춰야 한다.
custom intersection program을 사용하여 실제 vertex data와 GAS의 motion option을 분리할 수 있다 intersection program은 모든 종류의 intersection routine을 허용한다. 예를들어 motion key-triangle intersection을 구현할 수 있지만 삼각형의 전체 motion path를 둘러싸는 GAS에 AABB를 전달하여 AABB 위에 static GAS를 build할 수 있다. 그러나 일반적으로 이 방법은 두 가지 이유로 권장되지 않는다. 첫째, AABB는 motion이 거의 없어도 크기가 매우 빠르게 증가하는 경향이 있다. 둘째, hardware intersection routine을 사용하지 못하게 된다. 이 두 가지 효과는 모두 성능에 큰 영향을 미칠 수 있다.
5.10.3 Motion instance acceleration sturcture
geometry acceleration struct와 마찬가지로 instance acceleration의 motion option은 build option의 일부로 지정된다. GAS와 눈에 띄는 차이점은 IAS의 motion option이 거의 성능에만 영향을 미친다는 점이다. 따라서 motion instance-AS를 빌드할지 여부는 렌더링의 정확성(교차할 수 있는 instance 결정)에는 영향을 미치지 않지만 메모리 사용량과 traverse에는 영향을 미친다. 유일한 예외는 vanish flag인데, 이는 IAS의 시간 범위를 벗어나는 모든 ray time 동안 IAS의 모든 instance를 교차할 수 없도록 강제하기 때문이다.
다음에서는 우수한 성능을 달성하고 성능 저하를 피하기 위한 motion option 설정에 대한 지침을 제공한다. 여기서는 일반적으로 traverse 성능의 주요 변별자이자 메모리 사용량의 유일한 요소인 motion key의 수에 초점을 맞출 것이다. IAS build에 사용되는 최적의 motion key는 instance가 참조하는 traversable의 양과 선형성에 따라 달라진다. 시작 시간 및 종료 범위는 일반적으로 현재 frame을 rendering하는 데 필요한 시간에 따라 정의됩니다. 여기서 제시된 권장 사항은 향후 변경될 수 있다.
다음 조언은 단순화된 heuristic으로 간준된다. motion 사용 여부에 대한 더 자세한 내용은 아래에 나와있다. RTCores Version 1.0(Turing architecture)의 경우 IAS에 motion을 사용하지 말고 하드웨어 가속 traverse를 활용할 수 있는 static IAS를 빌드하는 것이 좋다. 다른 device(RTCores가 없는 디바이스 또는 RTCore version >= 2.0)의 경우, instance 중 motion transform 또는 motion AS를 traverse 가능한 자식으로 참조하는 경우 motion IAS를 build하는 것이 좋다.
motion IAS를 구축하는 경우, 높은 메모리 비용을 피하기 위해 적은 수의 motion key(2 or 3)를 사용하는 것으로 충분한 경우가 많다. 또한 참조된 motion transfom 중 하나에 motion key가 많다고 해서 많은 수의 key를 사용할 필요는 없다. (ex> instance 중 하나에서 traverse 가능한 참조된 motion key의 최대 motion key). motion option은 traverse 가능한 object 간에 종속성이 없으며 IAS에 많은 수의 motion key가 있으면 메모리 overhead가 높아진다. instance가 static traversable만 참조하는 경우 IAS에 motion을 사용하면 안된다.
motion blur 사용 시 추가 고려 사항:
-
motion을 킬 것인지
인스턴스화된 traversable의 전체 motion 양이 최소가 아닌 경우 AS는 motion을 켜고(motion key의 수가 1보다 큰) 빌드해야 된다. 단일 instance의 경우 이는 시간 경과에 따른 AABB 변화량으로 정량화할 수 있다. 따라서 단순한 이동(ex> 행렬 모션 변환으로 인한)의 경우 metric은 AABB의 크기와 비교한 이동의 양이다. Scale의 경우, 여러 시점에서의 AABB 크기 비율이다. 충분히 많은 instance화된 traverse이 시간에 따른 AABB의 변화가 최소가 아닌 경우 motion IAS를 구축한다.
반대로 static IAS는 다수의 instance traversable에 motion이 전혀 없거나 매우 적을 경우 더 높은 travese 성능을 제공할 수 있다. 후자는 회전에서 발생할 수 있다. 오브젝트의 중심을 중심으로 회전하면 object의 AABB에 다소 작은 차이가 발생한다. 그러나 회전 pivot point가 중심이 아닌 경우 오브젝트의 AABB에 큰 차이가 없다.
일반적으로 인스턴스의 motion 양을 실제로 정량화하기는 어렵기 때문에, 충분히 많은 instance traversable에 motion이 있거나 motion이 있을 것으로 예상되는 경우 motion으로 전환한다. 그러나 IAS을 사용하거나 사용하지 않는 것이 정확히 언제 이득이 되는지 예측하기는 어렵다.
- motion이 활성화된 경우 몇 개의 키를 정의해야 하는지
IAS에 필요한 motion key의 수를 결정하는 합리적인 지표는 instance화된 traversable motion의 선형성이다. motion key, rotation 도는 motion transform의 계층적 집합이 많은 motion transform이 있는 경우 IAS에 motion key가 많으면 traverse 성능이 향상될 수 있다. 단순한 이동, 오브젝트 중심 회전, 작은 양의 스케일 또는 이 모든 것을 함께 사용하는 것과 같은 transform은 일반적으로 두 개의 motion key IAS로 잘 처리할 수 있다.
마지막으로, IAS의 품질은 instance의 참조된 traversable의 motion key 수에 의해서도 영향을 받는다. 따라서 IAS의 motion option은 참조된 motion transform의 motion 옵션과 일치하도록 하는 것이 바람직하다. 예를 들어, 모든 instance가 키가 3개인 motion transform을 참조하는 경우 IAS에도 3개의 motion key를 사용하는 것이 합리적이다. 이 경우에도 기본 transform이 non-linear motion을 생성하는 경우에만 더 많은 모션 키를 사용하는 것이 도움이 된다는 위의 설명은 여전히 적용된다.
정리하면 motion key의 수는 IAS의 성능에 영향을 미치는데, motion key가 많은 경우 motion blur를 사용하는 것이 순회 성능을 높일 수 있다.
하지만 간단한 변환, 객체 중심 주위의 회전, 작은 양의 스케일 도는 그것들을 모두 함께하는 변환은 일반적으로 2개의 motion IAS로 잘 처리된다. 따라서 motion key의 수가 많으면 항상 효율적이란 것이 아니다.5.10.4 Motion matrix transform
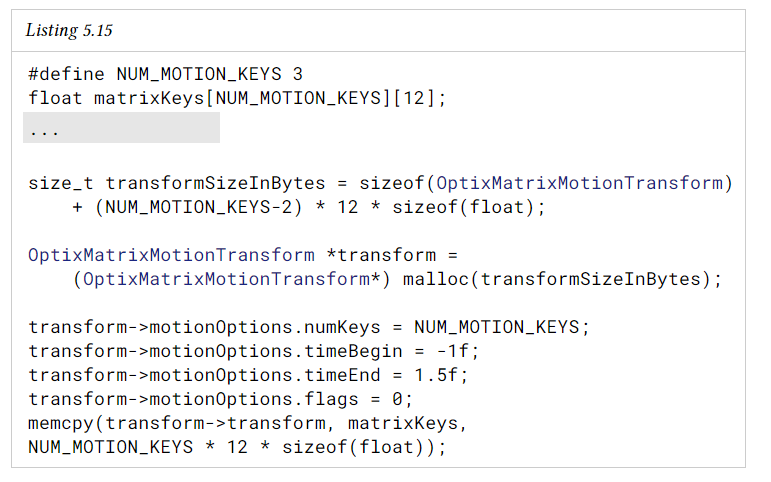
motion matrix transform traversable (OptixMatrixMotionTransform)은 motion matrix를 사용하여 traverse하는 동안 ray를 transform한다. traversable은 각 motion key에 대해 3x4 row-major의 주요 object-to-world 변환 matrix를 제공한다. 최종 motion matrix는 가장 가까운 motion key에서 행렬의 요소를 interpolation하여 traverse 중에 주성한다.
OptixMatrixMotionTransform 구조체는 motion key의 수에 따라 동적인 크기를 갖느다. 이 구조체는 편의를 위해 header와 처음 두 motion key를 지정하여, 2개 이상의 key를 사용하는 경우 추가 key에 필요한 크기를 계산한다.
5.10.5 Motion scale/rotate/translate transform
motion transform, OptixSRTMotionTransform의 동작은 Matrix mmmotion transform, OptixMatrixMotionTransform에서 motion key별 object-to-world transform은 단일 3x4 행렬 대신 SRT를 분해로 지정된다. 각 motion key는 16개의 float로 구성된 OptiixSRTData 유형의 구조체이다.

16개의 float는 motion transform의 곱이 되는 scaling, rotation, translation의 세 가지 구성 요소를 지정한다.
- Scale

scale, shear, translation을 포함하는 Affine transformation을 정의한다. 변환을 사용하면 scale, shear 및 후속 회전에 대한 pivot point를 정의할 수 있다.
- 쿼터니언 R

- translation T

회전 후에 적용된다. 일반적으로 이 변환에는 pivot point transform을 취소하기 위한 행렬의 역변환이 포함된다.
시간 t에 대한 효과적인 transformation을 구하기 위해, S,R,T의 구성 요소를 선형 보간하고 이후 정규화를 한다. 그런다음 C=TxRxS로 곱하여 결합된 변환을 얻는다. 이 변환은 시간t에서 효과적인 object-to-world 변환이며, 시간t에 효과적인 변환 행렬을 얻을 수 있다.

5.10.6 Transforms trade-offs
transforms를 사용할 때는 몇 가지 trade-off를 생각해야 한다.
- STRs와 matrix motion transforms 비교
회전이 포함된 모든 변환에는 SRT를 사용한다. SRT만이 왜곡 없이 부드러운 회전을 생성한다. 또한 회전을 근사화하기 위해 행렬 변환을 과도하게 샘플링하는 것을 방지한다. 그러나 두 개의 인접한 SRT key로 인한 최대 회전 각도는 180도 미만이어야 하므로 쿼터니언의 dot product는 양수이어야 한다. 이렇게 하면 최단 경로를 사용하여 회전이 보간된다. 180도 이상의 회전이 필요한 경우 두 key 사이의 회전이 180도 미안이 되도록 추가 key를 지정해 줘야한다. optiX는 runtime에 nlerp를 사용하여 쿼터니언을 interpolation한다. nlerp는 최상의 traverse 성능을 제공하지만 회전 속도가 일정하지 않다. 회전 속도의 변화는 회전의 양에 직접적으로 의존한다. 거의 일정한 회전 속도가 필요한 경우 더 많은 SRT key를 사용해야 할 수 있다.
회전의 복잡성으로 인해 SRT Transform을 참조하는 instance로 IAS를 빌드하면 상대적으로 속도가 느려질 수 있다. 실시간 또는 interactive application의 경우 matrix transform을 사용하여 IAS를 빠르게 다시 빌드하거나 다시 맞추는 것이 유리할 수 있다.
- motion transform을 위한 motion options
motion transform의 motion option은 Scene 설정에서 파생되어 필요에 따라 사용해야 한다. key의 수는 Scene description에 지정된 transform의 수에 따라 정의된다. 시작, 종료 시간은 frame에 필요한 시간 또는 장면 설명에서 지정한 경우 더 엄격해야 한다.
- 불규칙한 key를 다루는 방법
optiX는 motion option에서 일정한 시간 간격만 지원한다. 불규칙한 key는 규칙적인 키에 맞게 resampling해야 하며, 필요한 겨우 key 수가 훨씬 더 많아질 수 있다.
이에 대한 실용적인 예로 회전을 수행하는 motion matrix 변환을 만들 수 있다. 행렬 요소는 key 사이에 선형 보간되므로 회전은 실제 회전이 아니라 scale/shear/trnaslation이 된다. 시작적 아티펙트를 방지하려면 잠재적으로 많은 matrix motion key로 회전을 샘플링해야 한다. 이러한 샘플링은 행렬의 선형 보간을 통해 회전 근사치의 최대 오차를 제한한다. 샘플링은 불규칙한 motion key를 출력하여 모션 key의 수를 최소화하는 것이 아니라 많은 키로 회전을 over-sampling해야 한다.
각 key의 motion 시작 및 종료 시간이 다르고 valid motion flag가 설정된 불규칙한 key에 대한 해결 방법으로 중복 motion trnasformation을 사용해서는 안된다. 이 중복을 사용하면 모든 복사본을 교차하고 motion 시간을 ray time과 비교해야 하므로 traverse overhead가 발생한다.
5.11 Opacity micromaps
초고화질, 고해상도 불투명도(alpha) contents는 일반적으로 매우 일관성이 있거나 국부적으로 유사하다. 일반적으로 mesh 내에는 삼각형 경계와 반드시 일치하지 않는 완전히 투명하거나 불투명한 큰 영역이 있다. 따라서 miss 또는 hit로 간단히 분류할 수 있는 ray-triangle hit에 대해 임의 hit program이 호출되는 경우가 많다. 중복되고 잠재적으로 비용이 많이 드는 any-hit program의 overhead를 줄이기 위해 OptiX opacity micromaps(OMMs)을 사용하면 완전히 불투명하거나 투명한 것으로 알려진 삼각형 내 영역에서 any-hit program call을 culling할 수 있다.
OMM은 sub-triangle 레벨에서 정의되며, 균일하게 세분화된 4^N 개의 microtriangle mesh로 인코딩되어 2^N*2^N barycentric grid에 배치된다.
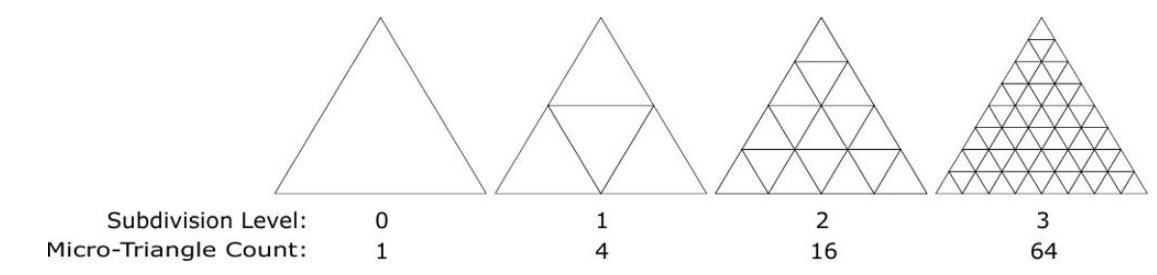
OMM은 microtriangle 당 opaque, transparent, unknown-opque 또는 unknown-transparent로 네 가지 불투명도 상태 중 하나를 지정한다. OMM은 기존 텍스처 매핑과 마찬가지로 불투명도 디테일을 추가하기 위해 GAS의 하나 이상의 기본 triangle에 적용된다.
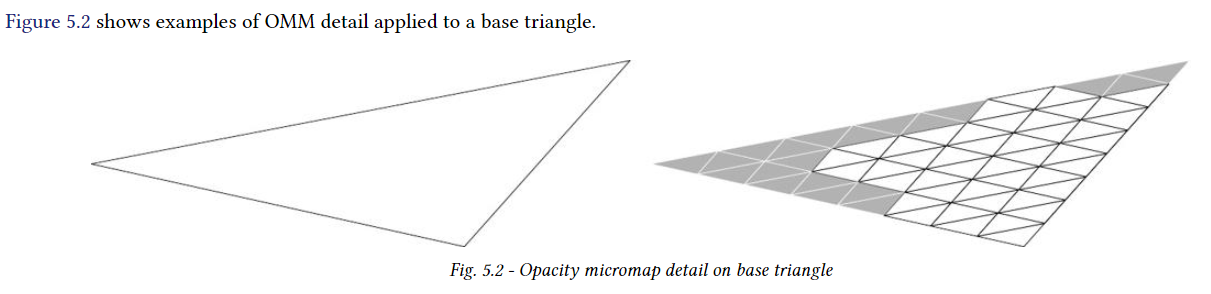
OMM을 사용해서 식물 및 잎사귀 같이 극도로 세부적인 장면을 묘사할 수 있게 한다. 전통적으로는 높은 해상도의 불투명 정보를 이용해서 alpha texture를 통해 구성되지만 ray tracing의 경우 shader에서 비용이 많이 드는 alpha-test가 필요하다.
OMM은 원래 기하학을 근사하여 셰이더 호출을 전혀 필요하지 않게 하거나, 품질 손실 없이 필요한 셰이더 호출 수를 크게 줄일 수 있다.5.11.1 Opacity micromap arrays
triangle과 달리 OMM은 GAS에 직접적으로 저장되지 않고 별도의 리소스인 opacity micromap array에 상주한다. 개별 OMM은 GAS 내에서 triangle에 의해 참조될 수 있다. OMM storage는 GAS와 분리되어 있기 때문에 scene의 여러 GAS 내에서 재사용할 수 있다. 가속 구조와 마찬가지로 OMM array는 device에서 optixOpacityMicromapArrayComputeMemoryUsage 및 optixOpacityMicromapArrayBuild 함수를 사용하여 생성한다.
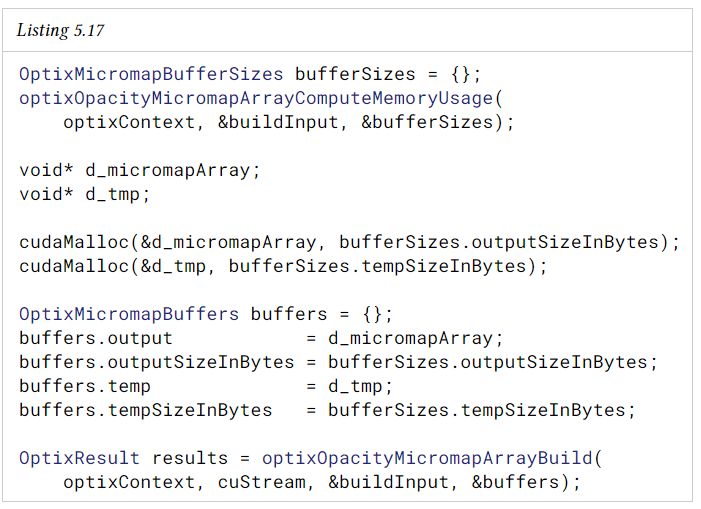
이 함수는 배열의 OMM 집합을 지정하는 단일 OptixOpacityMicromapArrayBuildInput 구조체를 사용한다. build input은 raw OMM 데이터의 device buffer와 OMM별 OptixOpacityMicromapDesc 구조체가 있는 장치 버퍼를 지정한다. descriptor는 각 OMM의 형식과 크기, raw OMM 데이터 버퍼 내 위치를 지정한다. 또한 입력은 OptixOpacityMicromapHistogramEntry 구조체의 host 버퍼를 지정한다. 이는 build input의 opacity micromap에 대한 histogram을 input type 및 subdivision level combination에 따라 구간별로 지정한다. 형식과 세분 조합이 동일한 histogram bin의 개수는 합산된다. input buffer의 descriptor는 input histogram과 카운트가 일치하기만 하면 특정 순서로 표시할 필요가 없다.
OMM array를 사용할 때 사용.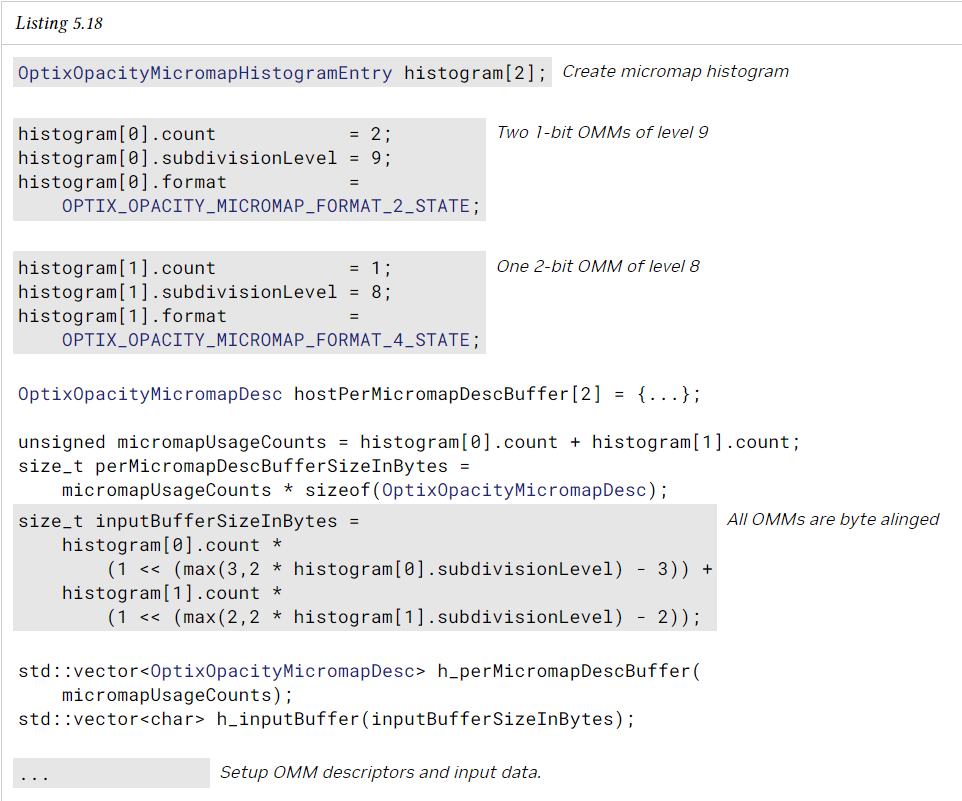

OMM array는 opaque 데이터 구조지만, 메모리 관리는 Application이 담당한다. OMM array에 필요한 메모리 양은 빌드 입력을 optixOpacityMicromapArrayComputeMemoryUsage에 전달하여 query할 수 있다.
optixOpacityMicromapArrayBuild에 의해 생성된 OMM 배열은 build input에 참조된 device buffer를 참조하지 않는다. 모든 관련 데이터는 이러한 buffer에서 다른 형식일 수 잇는 OMM array output buffer로 복사된다. Application은 build 후에 OMM array를 valid하지 않고 input memory를 자유롭게 해제할 수 잇다.

5.11.2 Usage
5.11.2.1 Construction of the geometry geomeyry acceleration structure
Application은 traiangle geometry input 당 하나의 OMM array을 GAS 빌드에 GAS build에 연결할 수 있다. 다음은 OMM array와 AS hierarchy 간의 관계를 보여준다.
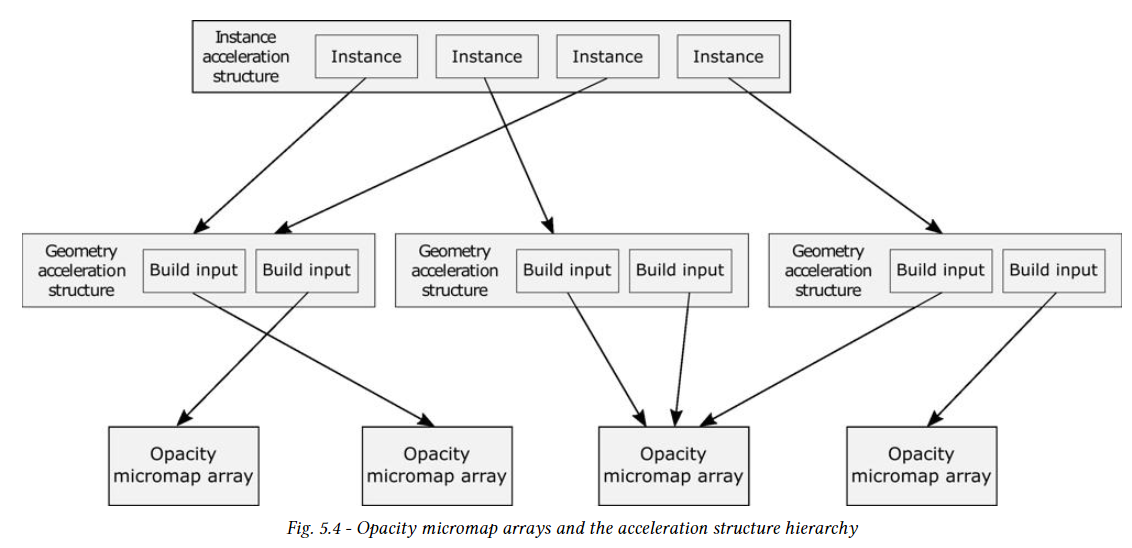
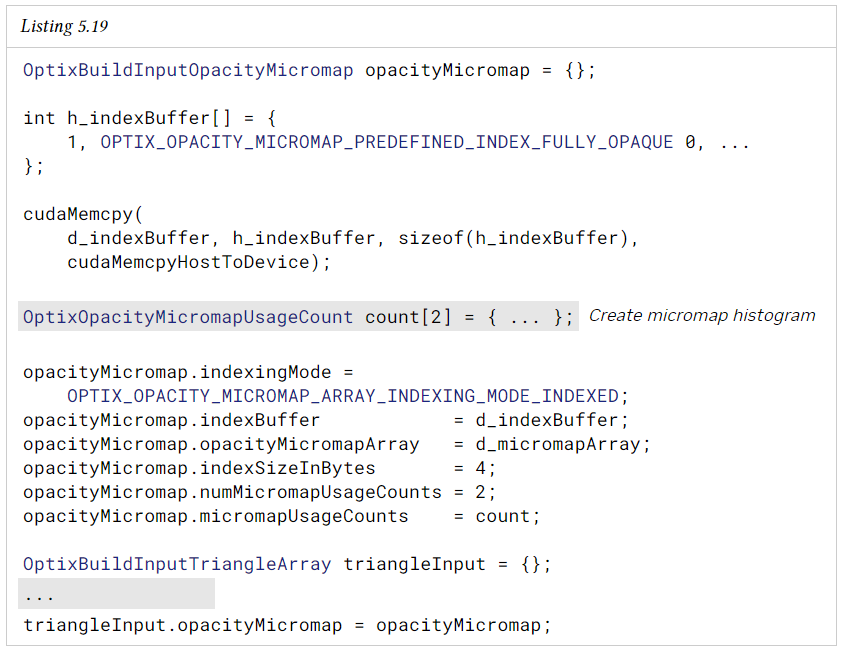
OMM array는 OptixBuildInputOpacityMicromap 구조체를 사용하여 지정한다. OMM은 device memory의 index 버퍼를 사용하여 indexing할 수 있으며, 삼각형 당 하나의 OMM index가 있다. 실제 index 대신 미리 정의된 index (OPTIXOPACITY_MICROMAP_RPEDEFINED_INDEX* 형식의 이름)를 사용하여 이 triangle에 대한 OM이 없지만 triangle의 opacity가 균일한 상태이며 선택한 동작이 전체 triangle에 적용됨을 나타낼 수 있다.
또한 이 입력은 OptixOpacityMicromapUseageCount 구조체의 host buffer를 지정한다. 이는 AS build input의 opacity micromap에 대한 사용 횟수를 input format과 subdivision level combination에 따라 bin 단위로 지정한다. format과 subdivision level combination이 동일한 bin의 개수는 합산된다. GAS build input에서 OMM을 중복으로 사용하는 경우 이 count에 포함되며, OMM 배열에 있지만 GAS build input에서 참조되지 않은 OMM은 이 count에 포함되지 않는다. 이 buffer는 OMM array build에 전달되는 histogram과 다르며, 이 histogram은 GAS build input에 의한 사용 여부와 관계없이 OMM array에 있는 OMM의 발생 횟수만 지정한다는 점을 유의해야 한다.
OPTIX_BUILD_FLAG_ALLOW_OPACITY_MICROMAP_UPDATE build flag를 사용하여 GAS를 build한 경우, GAS를 업데이트할 때 다른 OMM array와 OMM index를 할당할 수 있다. OMM array를 입력으로 사용하는 GAS build는 계속해서 이 OMM array를 참조한다. OMM array를 새 OMM 데이터로 덮어쓰면 해당 배열을 참조하는 모든 GAS는 오래된 것이 되므로 업데이트해야 한다.
OptixOpacityMicromapHistogramEntry에서의 histogram은 특정 유형의 opacity micromap이 array를 만들 때 입력되는 수를 의미한다.
OptixOpacityMicromapUsageCount가 host buffer에 있는 이유는 AS build가 CPU에서 실행되기 때문이다. 따라서 AS build에 입력을 CPU에서 읽을 수 있도록 host memory에 저장된다.
이와 달리 OMM index buffer는 device 메모리에 있다.5.11.2.2 Traversal
OMM을 사용하여 triangle rendering을 하려면 OptixPipelineCompileOptions 구조체에서 allowOpacityMicromap를 사용하여 pipeline에서 OMM을 활성화해야 한다. OMM이 사용되지 않는 것으로 알려진 경우 flag를 지정하지 않는 것이 더 효율적이다. flag가 생략된 상태에서 ray traversal 중에 OMM이 발생하면 동작이 정의되지 않는다.
ray가 OMM이 부착된 삼각형과 교차하면 삼각형의 barycentric space 내 교차점을 사용하여 OMM을 통해 해당 위치의 불투명도를 조회한다. OMM은 microtriangle을 불투명, 투명 또는 알 수 없음으로 분류한다.
- Opaque
hit는 OPTIX_GEOMETRY_FLAG_DISABLE_ANYHIT flag가 설정된 geometry에 대한 hit로 처리된다. - Transparent
hit는 무시되고 traverse가 재개된다. - Unknown
hit는 OPTIX_GEOMETRY_FLAG_DISABLE_ANYHIT flag가 설정되지 않은 geometry에 대한 hit로 처리된다.
두 microtriangle 상태인 unknown-opaque, unknown-transparent로 처리된다. 그러나 OPTIX_RAY_FLAG_FORCE_OPACITY_MICROMAP_2_STATE flag 또는 OPTIX_INSTANCE_FLAG_FORCE_OPACITY_MICROMAP_2_STATE instance flag를 사용하면 각각 불투명 및 투명으로 강제 지정할 수 있다. 이 재정의는 해석의 유연성을 제공한다. 일부 ray tracing effect에서는 정확한 해상도가 필요하지 않으며 모든 hit program call을 제거해도 시각적으로 허용된다. 예를 들어 부드러운 그림자는 더 낮은 해상도의 프록시를 사용하여 해결할 수 있다. OMM은 훨씬 더 세밀한 제어를 제공하고 가능한 geometry 전체 상태를 대처하기 위한 것이므로 OMM이 부착된 triangle의 경우 OPTIX_GEOMETRY_FLAG_DISABLE_ANYHIT flag가 무시된다.
ray flag와 instance flag는 여전히 opaque hit의 상태를 변경할 수 있지만, 이러한 flag는 OMM hit 분류가 발생한 후에만 적용된다. 즉, OMM이 평가된 후에는 OPTIX_RAY_FLAG_DISABLE_ANYHIT ray flag 또는 OPTIX_INSTANCE_FLAG_DISABLE_ANYHIT instance flag를 사용해도 투명한 microtriangle miss를 hit로 전환할 수 없다.
OPTIX_INSTANCE_FLAG_DISABLE_OPACITY_MICROMAPS instance flag를 사용하여 OMM을 끄고 개별 instance에 대해 geometry에 지정된 동작으로 되돌릴 수 있다. 이 flag는 참조된 BLAS가 원래 OPTIX_BUILD_FLAG_ALLOW_DISABLE_OPACITY_MICROMAPS build flag를 사용하여 빌드된 경우에만 유효하다. instance 단위로 OMM을 비활성화하면 특정 세부 수준 체계를 구현하는 데 유용할 수 있다.
5.11.3 Encoding
OMM은 microtriangle당 1비트 또는 2비트로 구성된 bit mask이다.
1bit OMM은 각 microtriangle당 transparent (OPTIX_OPACITY_MICROMAP_STATE_TRANSPARENT) 또는 opaque (OPTIX_OPACITY_MICROMAP_STATE_OPAQUE)으로 인코딩하여 광선을 추적하는 동안 any-hit program을 호출할 필요가 없다.
any-hit program에서 해결해야 하는 불투명도 부분이 있는 경우 2bit OMM이 사용된다. 2bit OMM은 각 microtriangle을 transparent, opaque, unknown-transparent (OPTIX_OPACITY_MICROMAP_STATE_UNKNOWN_TRANSPARENT) or unknown-opaque (OPTIX_OPACITY_MICROMAP_STATE_UNKNOWN_OPAQUE) 중 하나로 인코딩한다.
OMM microtriangle 상태는 barycentric space에서 공간 채우기 곡선에 따라 구성된다.
microtriangle을 기본 삼각형 barycentric space에 매핑하는 것은 헤더 파일 optix_micromap.h를 포함하면 사용할 수 있는 함수 optixMicromapIndexToBaseBarycentrics로 구현되어 있다.
5.12 Displaced micro-meshes
Scene의 기하학적 복잡성이 점점 더 증가하여 수십억 또는 수조 개의 triangle 범위로 이동함에 따라 storage 요구 사항(및 GAS build time)이 크게 증가한다. 평균 이하의 storage cost으로 geometry 품질을 획기적으로 향상시킨다는 목표를 달성하기 위해 OptiX는 내장된 micro mesh triangle primitive를 제공한다.
초고해상도 geometry contents는 일반적으로 일과성이 있으며, 새로운 primitive를 compact함을 위해 이를 제공한다. Displacement micro-maps(DMM)은 기본 삼각형에 고주파 기하학적 디테일을 추가하여 displacement micro mesh를 생성한다. 개별 DMM은 기존 텍스처 매핑과 마찬가지로 base triangle을 변조하여 디테일을 추가하는 방법에 대한 정보만 저장한다.
primitive은 native hardware를 지원하는 NVIDIA Ada Lovelace generation GPUs (RtCores version 3.0)와 함께 도입되었다. 또한 OptiX는 이전의 모든 RTX 지원 GPU(RtCores Version 1.0 및 2.0 포함)에 대한 소프트웨어 지원도 제공된다.
displacement mapping이라고 하면 모델링하기 힘든 굴곡들을 displacement map으로 적용하여 이미지의 밝기와 어둡기로 굴곡이 있게 모델링 해준다.5.12.1 Displaced micro-meshes
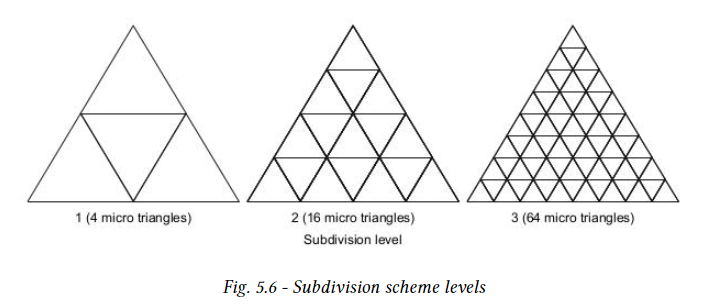
DMM는 정삼각형에 displacement 방향이 있는 scalar displacement field를 적용하여 구성된다. 삼각형의 초기 displacement position은 삼각형의 barycentric grid의 균일한 2Nx2N 세분으로 정의된다. 균일한 테셀레이션이 적용되어 4N개의 micro triangle이 생성된다. Application은 세분화 레벨 N과 이에 따라 추가된 microtriangle의 양을 지정한다. Optix는 0에서 5까지의 세분화 레벨을 지원하므로 최대 1024개의 microtriangle을 생성할 수 있다.
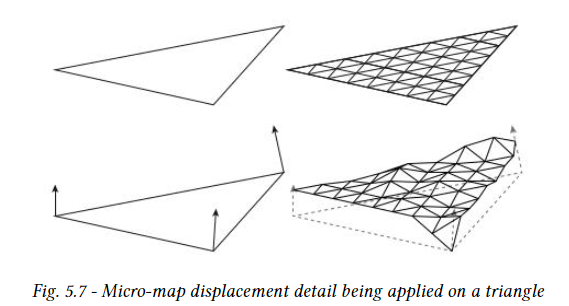
microtriangle의 정점 위치는 다음과 같이 계산된다. 각 displaced triangle vertex 또는 micro vertex에는 [0,1] 범위의 스칼라 변위량이 연관되어 잇으며, 이 스칼라 볌위량은 변위 방향을 따라 기본 삼각형에서 마이크로 버텍스를 변위하는 데 사용된다. 입력 변위 방향은 기본 삼각형의 세 꼭지점에 대해 Application에서 정의한다. 변위 방향의 길이는 가능한 최대 변위량을 지정한다. 기본 삼각형에서 변위 마이크로 메시를 계산하는 데 사용되는 스칼라 변위값은 DMM에 compact하게 함께 저장된다.
optiX는 GAS의 pretansform 메커니즘과 유사한 base triangle을 정의하는 추가적인 option 메카니즘을 제공한다. Application에서 제공하는 입력 정점을 직접 사용하는 대신 Application에서 정의한 편향에 따라 변위 방향을 따라 정점을 변위하여 base triangle을 정의할 수 있다. 이렇게 세 개의 vertex position로 구성된 input triangle은 Application에서 GAS build 작업에 vertex별 입력 변위 방향, 스케일 및 bias와 함께 제공된다. 이러한 input이 결합되어 base triangle과 변위 방향이 생성되며, 이는 가능한 변위 범위를 함께 정의한다. 다음 그림은 기본 정점과 스케일 변위 방향에서 예시를 볼 수 있다. 더 간단히 말하자면, 베이스 triangle 정점 위치와 변위 방향은 다음 방정식으로 계산된다.

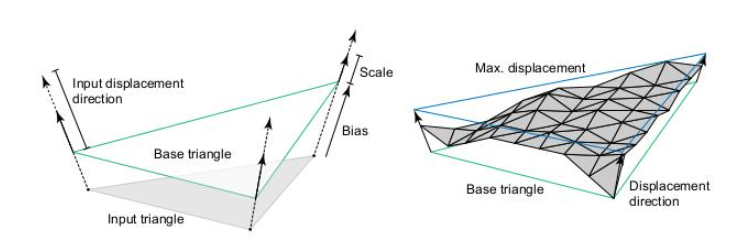
사진의 왼쪽을 보면 GAS input으로 구성된 기본 삼각형과 scaling 된 base triangle과 scaing된 변위 방향이다. 오른쪽은 변위된 micro mesh이다. 녹색 및 파란색 삼각형은 편향된 기본 삼각형 꼭지점과 스케일된 변위 방향으로 구성되며 가능한 변위의 최소 및 최대 경계를 정의한다.
위치 bias 및 변위 방향 스케일은, 선택 사항이지만 변위 범위에 대한 추가 제어 기능이 있다. 바이어스된 입력 정점(base vertex)과 스케일링된 변위 방향은 가능한 변위를 포함하는 경계 프리즘을 정의하며, 최소 및 최대 변위는 각각 삼각형 cap을 형성한다.
base triangle pose와 스케일링된 변위 방향은 micro vertex의 barycentric position에 따라 각 micro vertex에 대해 선형적으로 보간된다. 그런 다음 최종 micro triangle vertex 위치는 interpolation된 기준 위치에서 보간된 변위 방향을 따라 첨부된 DMM의 해당 micro vertex 항목에 지정된 양만큼 계산된다. 이 프로세스는 다음 방정식으로 요약할 수 있다.

정밀도와 성능에 대한 참고 사항
모든 연산은 32bit 정밀도로 수행되지만, 스케일링된 변위 벡터는 중간중간 AS에 절반인 16bit 부동소수점 정밀도로 저장된다. 변위량은 간결성을 위해 11bit 비정규값을 사용하여 표현되먀, 보간된 변위 방향을 따라 최소 및 최대 삼각형 cap 사이에 균일하게 분포된 2048개의 가능한 변위를 허용한다. 성능상의 이유로 변위된 마microtriangle 주위에 경계 prizmoid 를 가능한 단단하게 유지하는 것이 좋다. 이렇게 하면 11bit 변위 범위를 잘 활용할 수 있다. bias 및 스케일을 prizm을 조이는 도구로 사용할 수 있다. 그러나 인접한 변위 micromesh triangle primitive가 동일한 bias와 scale을 사용하여 watertighness에 필요한 edge에서의 bit 정확도를 보장하도록 하는 것은 Application의 책임이다.
5.12.2 Displacement micro-maps
DMM은 base triangle과 독립적인 micro vertex의 scalar 변위 값을 compact하게 포함한다. 이 개념은 opacity micro map, normal map 도는 기타 텍스처와 매우 유사하다. 변위 마이크로 맵은 scalar 변위 값의 저장소, 세분화 수준 및 변위 값의 인코딩 형식의 집합체이다.
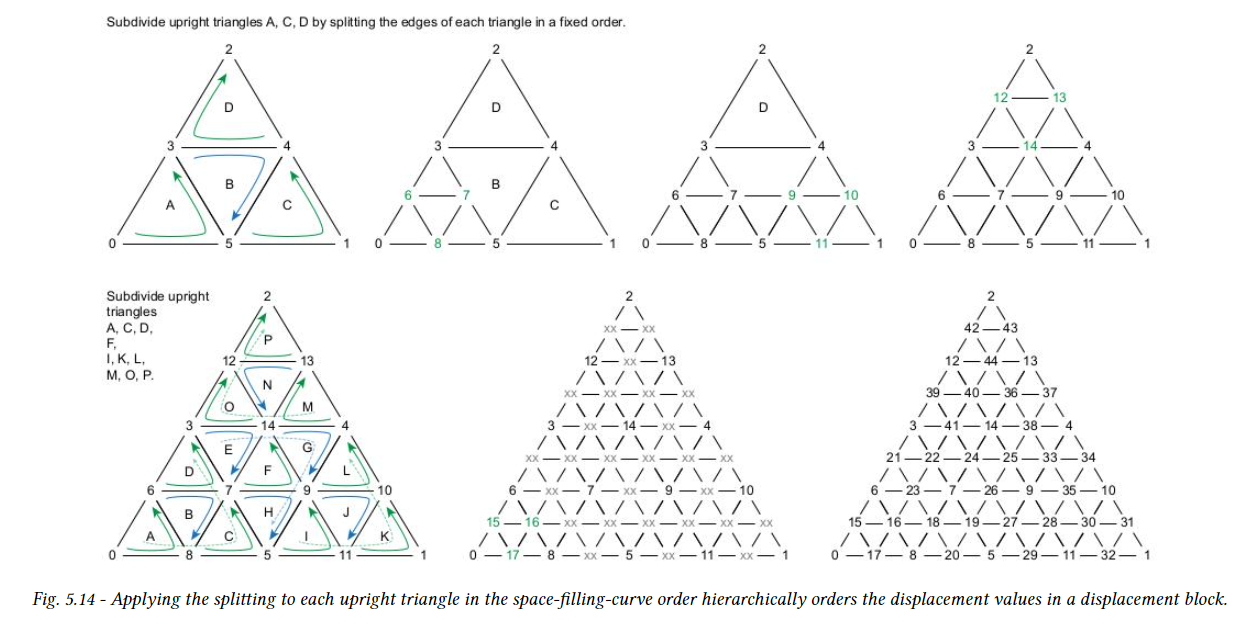
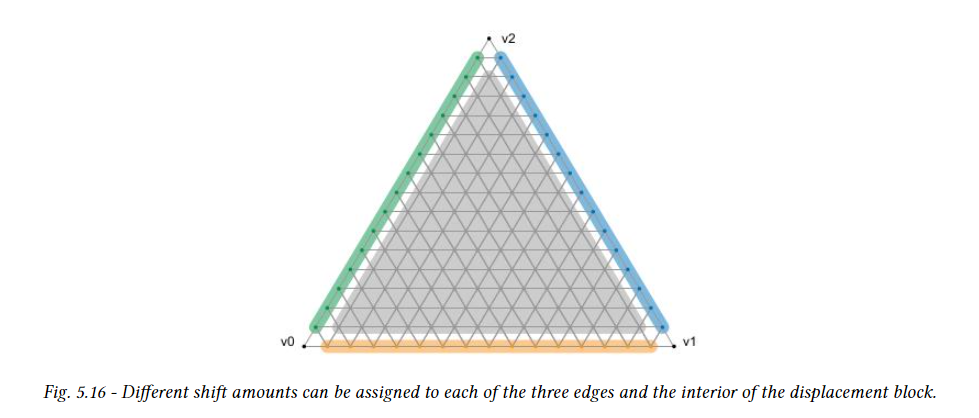
변위량은 변위 블록에 저장되며, 각 블록은 microtriangle 영역을 포함한다. 이 삼각형 영역을 하위 삼각형이라 하며 정확히 하나의 변위 블록에 해당한다. 세분화 수준과 인코딩 형식에 따라 주어진 변위 마이크로 맵에 대한 모든 변위 값을 저장하려면 하나 이상의 변위 블록(각각 하위 삼각형)이 필요하다. optix는 하위 triangle 당 각각 64개, 256개, 1024개의 microtriangle을 포함하는 세 가지 블록 인코딩을 제공한다. 다양한 인코딩을 통해 변위 정밀도와 저장 요구 사항 간의 균형을 맞출 수 있다.
DMM은 모든 하위 삼각형에서 이러한 인코딩 중 하나만 사용할 수 있으며, 이를 통해 변위 블록의 데이터 레이아웃을 정의한다. 변위 마이크로 맵의 최대 세분화 수준은 5(1024 microtriangle)이다. 가능한 전체 세분 레벨 및 블록 인코딩은 다음 그림에서 확인할 수 있다. 인접한 하위 삼각형은 구성상 가장자리를 공유하지만 해당 변위 블록은 가장자리에서 변위값을 공유하지 않는다. 대신, 두 변위 블록은 edge의 micro vertex에 대해 동일한 변위 값을 지정해야 한다.
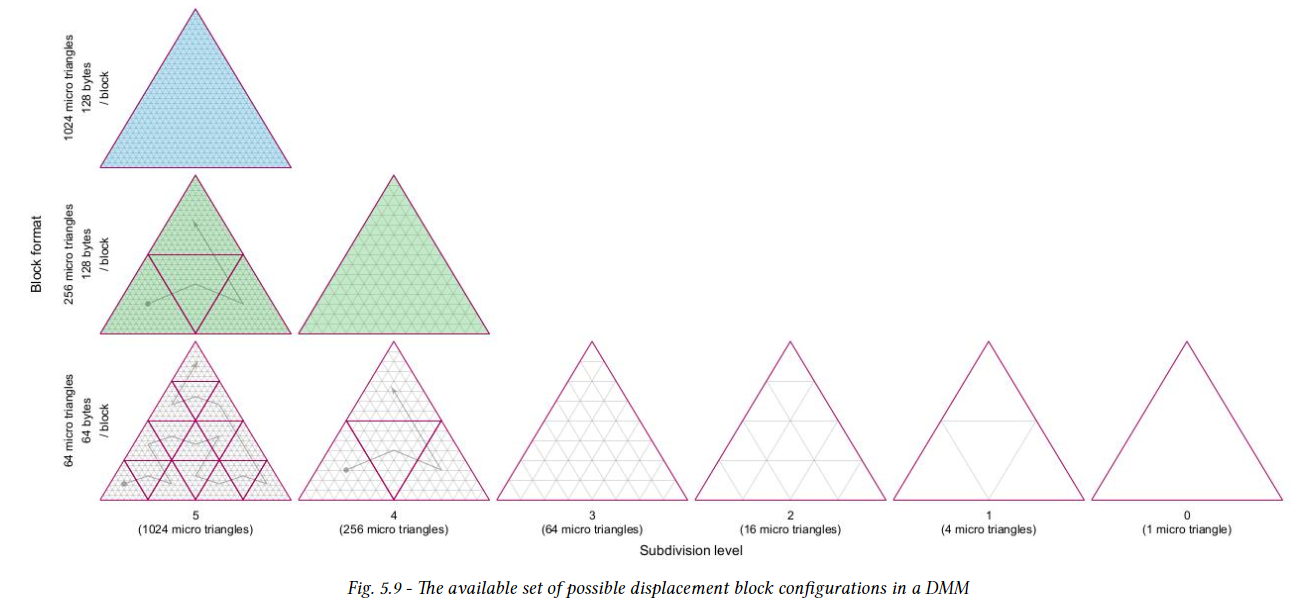
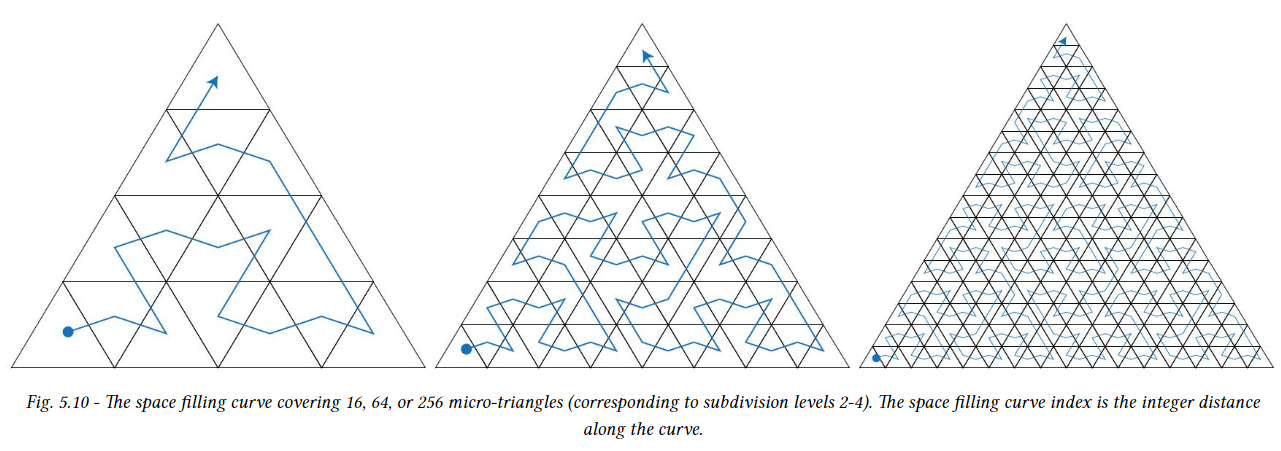
하위 삼각형은 위 그림에 표시된 것 처럼 공간을 채우는 곡선을 따라 구성되며 DMM의 모든 microtriangle을 포함한다. 이 curve는 barycentric grid 내에서 하위 삼각형의 상대적 배치와 메모리에서 변위 블록의 예상 순서를 정의한다. 공간 채우기 곡선은 계층적이며 이론적으로 모든 세분화 레벨에 적용할 수 있다. 따라서 이 곡선은 하위 삼각형 내의 microtriangle과 DMM 내의 전역 삼각형의 순서도 지정한다. 이 curve는 OMM에서 사용하는 것과 동일한 공간 채우기 curve이다.
위 그림에서 볼 수 있듯이 블록 인코딩 및 세분화 레벨에 따라 DMM의 전체 microtriangle 수를 커버하기 위해 여러 블록이 필요할 수 있다. 이러한 경우 블록의 순서는 회색 경로로 표시된 대로 공간 채우기 곡선을 따른다.
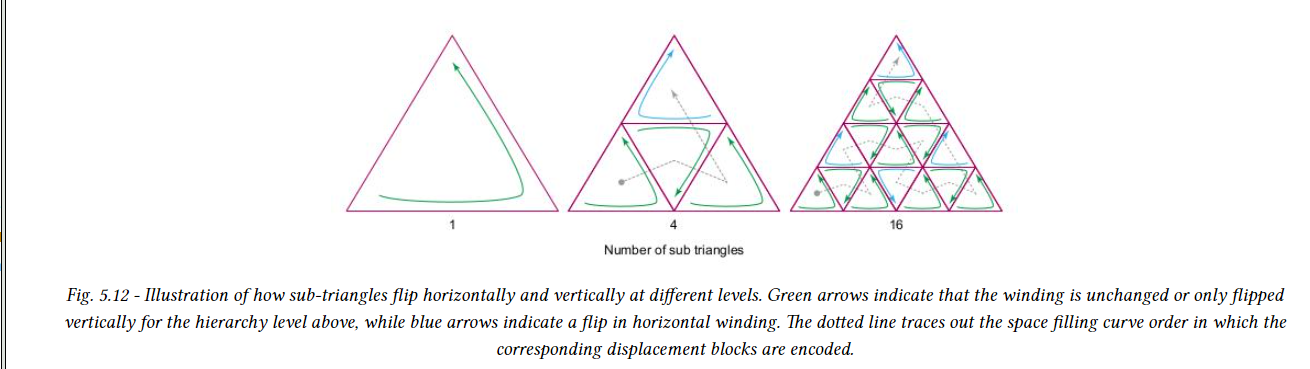
계층적 순서를 연속적으로 유지하기 위해 일부 하위 삼각형은 뒤집어지고 다르게 감겨있다. 아래 그림의 하위 삼각형은 A는 v0, v01, v20 모서리 꼭지점으로 구성된다. 중간 삼각형인 M은 v20에서 시작하여 v12로 이동한 다음 v01로 이동한다. 아래 그림에서 볼 수 있듯이 M은 수직적으로 뒤집히고 C는 수평으로 뒤집히므로 이 두 삼각형 모두에 대해 winding이 뒤집힌다.
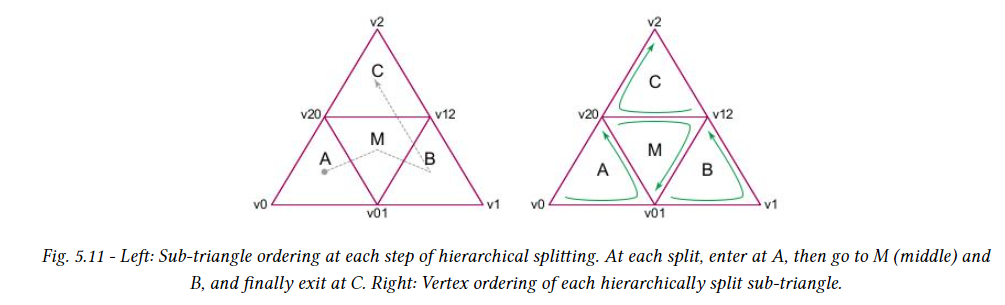
변위 블록의 변위 값을 설정할 때 감기 방향을 뒤집는 것을 고려해야 한다. 하위 삼각형 a에 해당하는 변위 블록의 첫 번째 변위 값은 v0에 있고, 하위 삼각형 M에 해당하는 변위 블록의 첫 번째 변위 값은 v20에 있으며 하위 삼각형 C에 해당하는 변위 블록의 첫 번째 변위 값은 v12에 있다. 아래 그림는 DMM의 하위 삼각형의 가능한 세 가지 개수(1,4 또는 16)에 대한 모든 하위 삼각형의 방향을 보여준다.
5.12.2.1 Displacements blocks
블록 내에서 로컬로 변위 값의 순서(microvertex의 순서)는 공간 채우기 곡선을 기반으로 하는 계층적 분할 방식이다. 처음 세 값은 이 블록이 적용되는 하위 삼각형의 정점에 해당한다.(하위 삼각형에 대한 세분 레벨0) 다음 세 값은 하위 삼각형의 가장자리를 분할할 때 정점에 해당한다.(하위 삼각형에 대한 세분 레벨1). 특히 각 세분 레벨은 아래 그림과 같이 이전 세분 레벨의 두 정점을 연결하는 모든 가장자리에 새 정점을 추가하여 각 삼각형을 네 개로 분할한다.
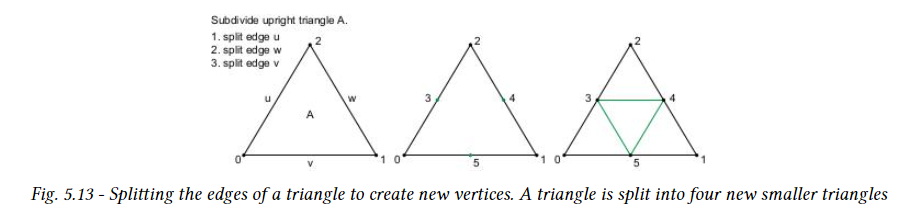
모든 세분화 수준에서 새 정점의 순서는 다음 규칙에서 파생된다. 계층적 세분은 수직으로 뒤집힌 삼각형이 아닌 직립 삼각형만 분할하여 실행된다. 주어진 직각 삼각형에 대해 위의 그림과 같이 먼저 가장자리 u, 그 다음 w, 마지막으로 v를 분할하여 새 정점을 도입한다.
다음으로 공간 채우기 곡선에 따라 삼각형을 반복하여 모든 직립 삼각형에 대해 위와 같이 새 정점을 도입하여 분할을 계속한다. 주어진 세분 레벨에 대해 모든 삼각형이 분할되면 아래 그림과 같이 다음 세분 레벨에 대해 이 과정을 반복한다.
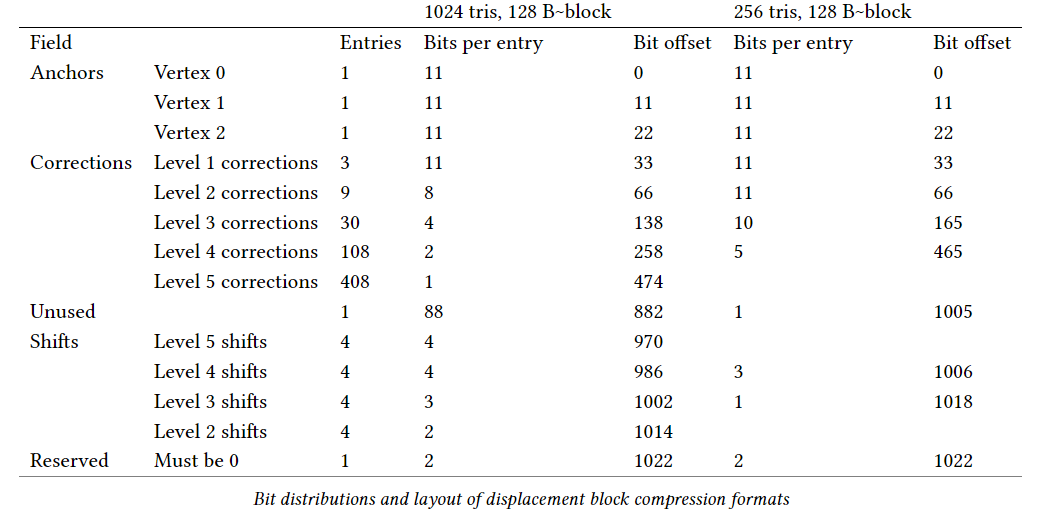
5.12.2.1.1 Uncompressed displacement block format
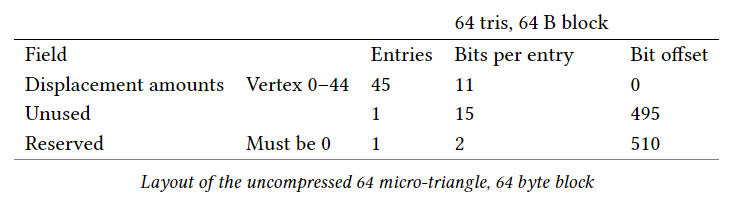
가장 간단한 블록 형식은 64개의 microtriangle(세분화 레벨3)으로 덮는 것이다. 45x11 bit 변위 값은 위의 vertex indexing 체계에서 다음과 같은 순서로 bit-packing되어 저장된다. 이 값에 대한 저장 요구 사항은 495b이다. 나머지 두 비트는 나중에 사용하기 위해(블록의 맨 끝에) 예약되어있다. 블록의 총 크기는 아래 표에서 표시된 것처럼 최대 512b(64B)까지 packing된다.
5.12.2.1.2 Compressed displacement block formats
256 및 1024 microtriangle block format(각각 세분화 레벨 4 및 5에 해당)을 사용하면 64 microtriangle format볻 더 높은 압축률을 달성할 수 있다. 256 microtriangle format과 1024 마이크로 triangle format은 모두 128B를 차지하며, 압축되지 않은 64 microtiangle foramt에 비해 각각 21ㅐ와 8배의 압축률을 제공한다. 64 microtriangle format은 11b 변위량의 모든 조합을 나타낼 수 있지만, 256 및 1024 microtiangle format은 그럴 수 없으며 대신 국부적으로 유사한 변위에 의존하여 압축을 추출한다. 따라서 이러한 압축 포멧을 사용하면 인코더가 압축률과 기하학적 정확도를 교환할 수 있다.
압축 방식은 마이크로 맵을 형성하는 데 사용되는 자연 재귀적 세분화에 의존하며, 각 세분화 수준은 점점 더 적은 수의 보정 비트를 사용하면서 점점 더 많은 정점을 도입한다. 가장 거친 세분화 수준에서는 시작 정점에 11bit anchor point 3개가 지정된다. 각 세분화 수준에 새로운 정점은 하위수준에서 인접한 두 정점의 평균을 내어 형성한다. 예측 단계에서는 비정규값을 정수로 취급하고 인접한 값 A와 B의 반올리된 평균으로 값을 예측한다.
다음 단계에서는 예측을 올바른 위치로 위 또는 아래로 조정하여 수정한다.
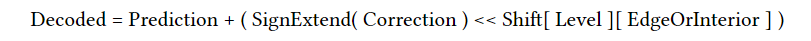
아래 그림이 해당 과정을 설명해준다.
위 그림의 왼쪼게는 세 개의 anchor point가 세분화 레벨 0에 있다. 가운데 세 개의 새로운 정점(녹색)이 세분 레벨 1에 도입되었다. 변위량은 두 이웃의 평균을 구하여 예측한 후 보정을 적용한다.
보정 움직임이 작거나 손실된 상태로 저장할 수 있는 경우 예측을 보정하는 데 사용되는 비트 수가 직접 인코딩하는 데 필요한 비트 수보다 작을 수 있다. 보정 계수의 bit 폭은 레벨별로 가변적이다. 기본 anchor point는 부호화되지 않은 반면(11b 비정규) 보정 계수는 부호화된다.(2의 보수). shift 값을 사용하면 전체 비트 폭보다 작은 값으로 보정을 저장할 수 있다. shift 값은 아래 그림에서 볼 수 있듯이 각 edge의 정점을 서로 및 내부 마이크로 정점과 독립적으로 shift할 수 있도록 4가지 변형으로 레벨당 저장된다. 이를 통해 가장 자리에서 shift 값을 선택하여 인접한 subtriangle과 DMM이 가장자리에서 일치하도록 하여 waterlighness를 보장할 수 있다. 예측에 보정을 추가할 때 디코딩된 위치가 wrapping된다는 점을 유의해야 한다. 저장된 값을 기반으로 wrapping을 피하거나 wrapping 결과를 의미있게 만드는 것이 인코더의 몫이다.
위 그림에서 별도의 shift를 사용하면 인접한 하위 triangle과 가장자리를 일치시킬 때 더 잘 제어할 수 있다. 도한 anchor point는 항상 변위 블록에 압축되지 않은 상태로 저장되므로 shift 값이 anchor point에 적용되지 않는다는 점을 유의해야 한다.
두가지 압축 블록 포맷은 모두 동일한 예측 및 보정 체계를 따르며, 다양한 필드에 비트 할당만 다르다. 포멧 레이아웃에 대한 개요는 아래 표에서 확인할 수 있다.
5.12.2.2 Edge decimation
서로 다른 DMM이 적용된 인접한 triangle을 사용되는 세분화 레벨이 다를 수 있다. 이렇게 하면 메시에서 변위 디테일의 양을 부드럽게 변경할 수 있다. 그러나 인접한 base triangle 간의 세분화 레벨 차이는 한 레벨로 제한된다. 하지만 레벨의 변화는 메시 전체에 전파하면 된다. 예를들어 레벨 3 base triangle이 레벨 4옆에 있고, 레벨 4 옆에 레벨5를 두는 식으로 할 수 있다.
인접한 base triangle의 세분화 수준이 서로 다른 경우 공유하는 가장자리의 세그먼트 수는 2의 배수만큼 달라진다. 이로인해 아래 그림의 왼쪽 이미지와 같이 균열을 유발하는것이 T-juction이 생깁니다. 다양한 해상도에서 waterlightness을 유지하기 위해 아래 그림의 오른쪽에 표시된 것처럼 고해상도 삼각형의 가장자리 따라 sitching 패턴이 사용된다.
인접한 변위된 micro mesh triangle 내부와 triangle 사이에 균열이 없는지 확인하는 것은 application의 책입이다. 변위된 micro mesh triangle의 가장자리는 인접한 변위된 micro mesh triangle의 topology와 일치하도록 가장자리 decimation을 요구하도록 flag를 설정할 수 있다.
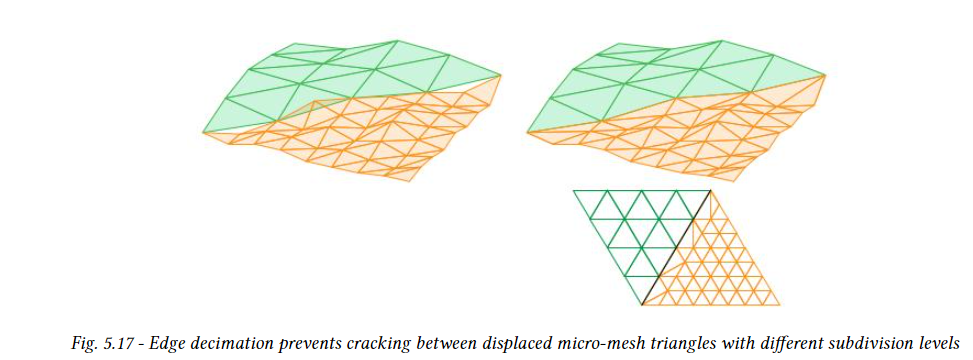
위 그림에서 왼쪽은 세분화 수준이 다른 두 개의 인접한 삼각형을 보여줍니다. 이를 처리하지 않으면 공유 가장자리를 따라 균열이 생긴다. 오른쪽에서는 T-juction의 정점을 생략하고 가장자리를 따라 stiching pattern을 사용하여 연결성을 변경했습니다.
5.12.3 Displaced micro-mesh API
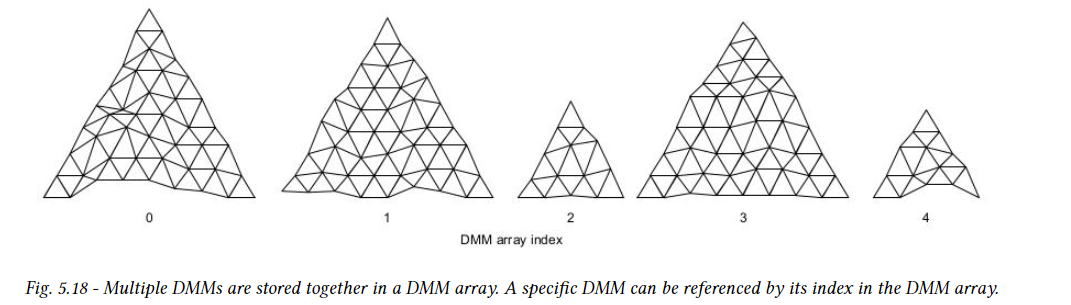
스칼라 변위 값은 GAS에 직접 저장되지 않고 별도의 리소스인 DMM array에 저장되는 DMM의 형태로 간결하게 지정된다. GAS를 구축할 때 DMM array를 참조할 수 있으며, 아래 그림과 같이 GAS에서 triangle 통해 개별 DMM을 참조할 수 있다. DMM storage는 GAS와 분리되어 있기 때문에 scene의 여러 GAS 내에서 그리고 여러 GAS 간에 DMM을 재사용할 수 있습니다. AS와 유사학게 DMM array device에서 optixDisplacementMicromapArrayComputeMemoryUsage 함수와 optixDisplacementMicromapArrayBuild 함수를 이용해서 생성된다.
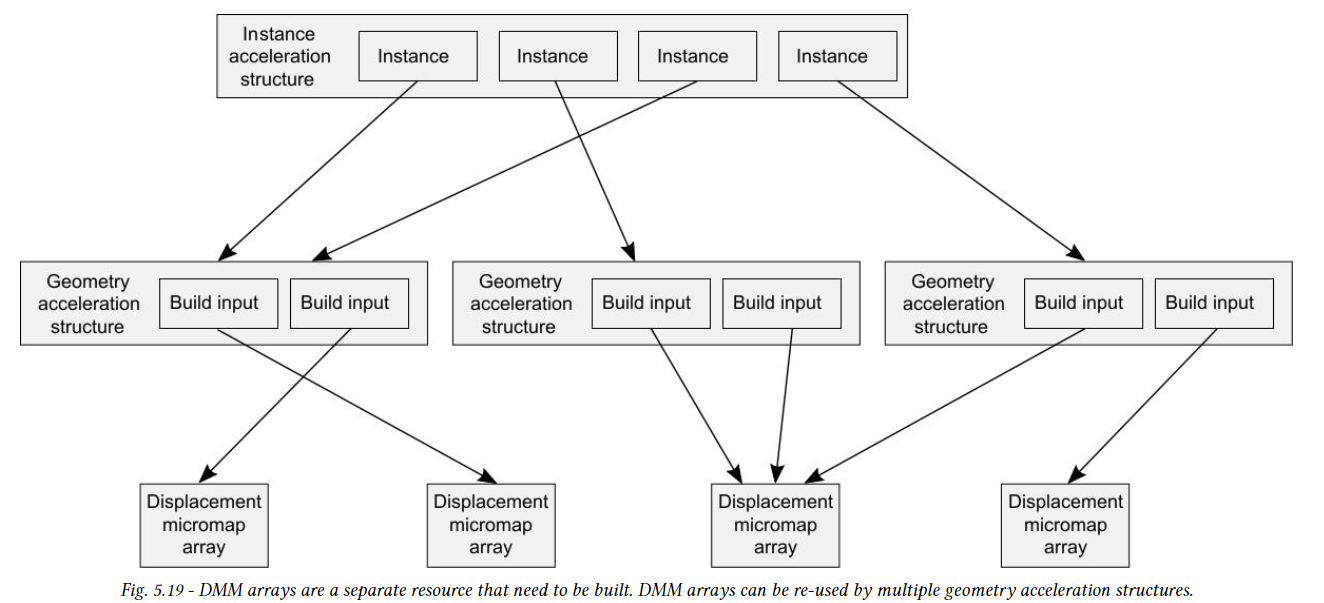
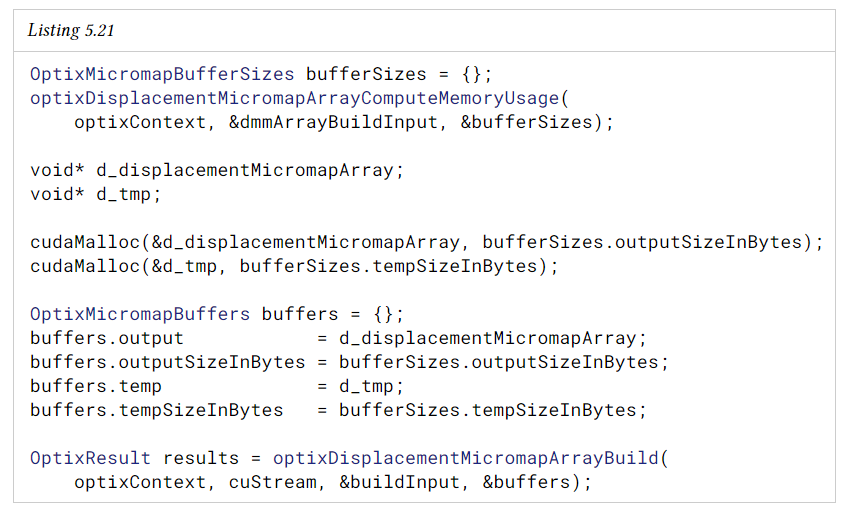
이 함수는 배열의 DMM 집합을 지정하는 단일 OptixDisplacementMicromapArrayBuildInput 구조체를 사용한다. build input은 이전 section에서 설명한 대로 형식과 데이터 레이아웃이 포함된 변위 블록의 device buffer를 지정한다. DMM array는 서로 다른 세분화 수준과 형식을 가질 수 있는 DMM의 모음이다 따라서 build input은 DMM 별 OptixDisplacementMicroDesc 구조체가 있는 device buffer도 참조한다. descriptor는 각 DMM과 해당 변위 블록의 포맷과 크기, DMM 변위 값 버퍼 내 위치를 지정한다. DMM에 여러 개의 변위 블록이 필요한 경우 (예> 256microtriangle/128byte block type의 세분 레벨 5 DMM), 변위 블록 이전 섹션에서 설명한 대로 하위 삼각형의 순서대로 메모리에 연속적으로 저장되어야 합니다.
build input은 또한 OptixDisplacementMicromapHistogramEntry 구조체의 호스트 버퍼를 지정한다. 이는 build input DMM에 대한 histogram을 input format 및 세분화 수준 조합에 따라 구간별로 지정합니다. 형식과 세분 조합이 동일한 히스토그램 bin의 개수는 함산된다. input buffer의 descriptor는 input histogram과 count가 일치하기만 하면 특정 순서로 표시할 필요가 없습니다. AS build와 마찬가지로 DMM 배열 빌드에는 빠른 trace 및 빠른 build 플래가 있으며, 각각 트레이스 성능 또는 빌드 속도에 유리하도록 설계되어있다. 비대화형 렌더러의 경우 일반적으로 빠른 트레이스를 사용하는 것이 좋다. 또한 AS 빌드와 유사하게 optixDisplacementMicromapArrayComputeMemoryUsage를 호출할 때 device data를 사용할 준비가 되어있지 않아도 되며, 메모리 크기 계산을 위해 histogram 정보와 DMM array build용 flag만 사용된다.
DMM 배열은 opaque 데이터 구조이지만 메모리 관리는 Application이 담당한다. OMM 배열에 필요한 메모리 양은 빌드 입력을 optixDisplacementMicromapArrayComputeMemoryUsage에 전달하여 query할 수 있다.
optixDisplacementMicromapArrayBuild에 의해 생성된 DMM array는 build input에서 참조된 device buffer를 참조하지 않는다. 모든 관련 데이터는 이러한 버퍼에서 다른 형식일 수 있는 DMM 배열 출력 버퍼로 복사된다. Application은 build 후 DMM array를 무효화하지 않고 입력 메모리를 자유롭게 해제할 수 있다.
5.12.3.2 Geometry acceleration structure build for DMM triangles
변위 micro-mesh triangle 유형의 primitive는 일반 삼각형과 동일한 build input structure (OptixBuildInputTriangleArray)를 사용한다. 그러나 일반 삼각형을 변위 micro-mesh triangle로 변환하기 위해 추가 변위 정보(OptixBuildInputDisplacementMicromap 구조체)를 제공한다. DMM array의 DMM은 변위량만 저장하며, 다른 모든 정보는 GAS build input의 일부로만 지정된다.
Application은 GAS build에 삼각형 입력당 하나의 DMM 배열을 연결할 수 있다. DMM 배열은 멤버 DMM을 통해 설정된다. DMM array에 대한 indexing은 명시적 index buffer 또는 build input의 N번째 triangle이 참조된 DMM 배열의 N번째 DMM을 사용한다고 가정하여 암시적 일대일 매핑을 통해 이루어진다. base triangle의 정점에서의 변위 방향, 선택적 바이어스 및 스케일, 추가 flag(edge deciment flag)는 GAS build에 buffer로 제공된다.
변위 방향과 선택적 bias 및 scale은 vertex별 attribute이며, 해당 buffer는 vertex position buffer와 마찬가지로 인덱싱 된다. flag buffer는 triangle별 attribute가 포함되며, N번째 flag는 build input의 N번째 primitive에 적용된다. 현재 사용 가능한 flag는 edge deciment flag뿐이며 edge에 ege deciment를 겆굥해야 하는 경우 교차저메 신호를 보낸다. optix는 edge deciment을 자동으로 적용하지 않으며, edge에 edge deciment이 필요한지 여부를 확인하지 않아도 된다.
DMM array index buffer가 사용되는 경우, index 사이의 간격과 단일 index의 바이트 크기는 displacementMicromapIndexStrideInBytes와 displacementMicromapIndexSizeInBytes를 사용하여 설정된다. index는 DMM index offset member를 사용하여 상수로 offset할 수도 있다. 변위 방향과 bias 및 배율은 실수 또는 반정밀도 값으로 지정할 수 있습니다. 그러나 변위 방향의 경우 API는 편의상 실수 값을 허용하며, 값은 내부적으로 반 포맷으로 변환되고 모든 연산은 반정밀을 사용하여 수행됩니다.
입력은 또한 OptixDisplacementMicromapUsageCount 구조체의 host buffer를 지정한다. 이는 가속 구조 빌드 입력의 DMM에 대한 사용 횟수를 입력 포맷과 세분화 수준 조합에 따라 bin 단위로 지정한다. 포맷과 세분 조합이 동일한 bin의 갯수는 합산된다. GAS build input에서 DMM을 중복 사용하면 이 카운트에 포함해야 하며, DMM 배열에 있지만 GAS build input에서 참조하지 않은 DMM은 이 count에 포함하지 않아야 합니다. 이 버퍼는 GAS build input의 사용 여부와 관계없이 DMM array의 DMM 발생만 지정하는 DMM 배열 빌드에 전달되는 히스토그램과는 다르다.
GAS update에서 DMM array에 대한 참조나 triangle에서 DMM으로의 인덱싱은 변경할 수 없다.
