https://raytracing-docs.nvidia.com/optix7/guide/index.html#program_pipeline_creation#program-group-creation이번 section에서 설명할 API 목록은 다음과 같다.
optixModuleCreate
optixModuleDestroy
optixProgramGroupCreate
optixProgramGroupGetStackSize
optixPipelineCreate
optixPipelineDestroy
optixPipelineSetStackSize
program은 먼저 OptixModule 유형의 모듈로 컴파일된다. 하나 이상의 모듈을 결합하여 OptixProgramGroup 유형의 prgram group을 생성한다. 그런 다음 이러한 program group은 GPU의 OptixPipeline에 link된다. 이는 소프트웨어에서 흔히 볼 수 있는 컴파일 및 프로세스와 유사하다. 또한 program group은 해당 프로그램과 관련된 SBT record의 헤더를 초기화하는 데 사용된다.
optixModuleCreate, optixProgramGroupCreate, optixPipelineCreate의 세 가지 생성 메서드는 선택적으로 log 문자열을 받는다. 이 문자열은 컴파일 오류 또는 컴파일 결과에 대한 자세한 정보 등을 받기 위해서 사용된다. 문자열 출력이 잘리는 것을 감지하기 위해 log message의 크기가 출력 매개변수로 나온다. 전체 출력을 얻기 위해 함수를 다시 호출하면 불필요하고 긴 작업이 필요하거나 cache hit에 대한 다른 출력이 발생할 수 있으므로 함수를 다시 호출하지 않는 것이 좋다. 오류가 발생한 경우 log string에 보고되는 정보는 device context로 callback(regist 필요)에 의해서도 보고된다.
이러한 create 함수에는 두 가지 메커니즘이 모두 제공되므로 logger의 어떤 출력이 어떤 API 호출에 해당하는지 확인할 필요 없이 병렬 생성 작업에서 컴파일 오류를 추출할 수 있는 편리한 메커니즘을 사용할 수 있다.
OptixMoudle 객체의 symbol은 unresolved 상태일 수 있으며 변수 및 device 함수에 대한 extern 참조를 포함할 수 있다.
이러한 symbol은 pipeline module에 정의된 symbol을 사용하여 pipeline 생성 중에 해결할 수 있다. symbol이 중복될 경우 오류가 발생한다.
pipeline에는 특정 ray tracing 실행에 필요한 모든 프로그램이 포함되어 있다. Application은 각 실행에 대해 다른 pipeline을 사용하거나 여러 ray generation program을 단일 pipeline으로 결합할 수 있다.
대부분의 optiX API 함수는 GPU state를 갖고있지 않다. pipeline에서 실행 가능한 binary program을 정의하는 streamming assembly(SASS) instruction은 예외적으로 GPU state를 갖는다. OptixPipeline은 컴파일된 SASS와 관련된 CUDA resource를 소유하며, pipeline이 소멸될 때까지 이 리소르를 보유한다. 이 할당은 pipeline에서 컴파일된 코드의 양에 비례하며, 일반적으로 수십 kilobyte에서 megabyte에 이른다. 그러나 대용량 static initializer를 사용하는 경우 훨씬 더 많은 메모리를 필요로 하는 복잡한 pipeline을 생성할 수 있다. 가능하면 pipeline의 수와 크기에 주의를 기울어야 한다.
module lifetime은 module을 참조하는 program group의 lifetime까지 연장해야 한다. module을 사용하여 OptixProgramGroup 객체를 통해 OptixPipeline을 생성한 후에는 optixModuleDestroy 함수를 사용하여 module을 소멸할 수 있다.
6.1 Program input
optiX program은 nvidia에서 독점적으로 사용하는 중간 표현인 OptiX-IR 또는 병렬 스레드 실행을 위한 명어 세트인 PTX로 인코딩 된다. Optix-IR은 symbol debugging이 가능하고 향상된 최적화 및 향후 기능을 위해 보다 여러가지 코드 표현을 포함한다. Optix-IR은 일반 텍스트 형식으로 저장되는 PTX와 달리 NVIDIA tool에서만 읽을 수 있는 바이너리 형식이다.
PTX는 GPU에서 사용하는 어셈블리어라고 생각하면 된다.PTX program을 생성하려면 NVIDIA nvcc offline compiler 또는 nvrtc JIT 컴파일러를 사용한다. CUDA source file을 컴파일 한다. OptiX-IR program을 생성하려면 nvcc로 UDA source file을 컴파일 한다. Optix program device api를 제공하려면 source file에 optix device header를 포함해야 한다.
nvcc를 사용하면 optix용 코드를 생성할 때는 PTX에서 OptiX-IR 입력으로 전환하는 것이 좋다.
PTX는 계속 지원되지만 symbolic debugging과 같은 모든 Optix-IR 기능은 제공하지 않을 수 있다.
nvcc를 이용한 OptiX-IR program을 생성하는 방법은 다음과 같다.

nvcc 명령 옵션는 nvcc --help와 함께 표시되는 컴파일러 옵션의 사용 설명의 일부를 자세히 설명하겠다.
nvcc 및 nvrtc 컴파일레 대한 다음 요구사항을 유의해야 한다.
- optix program의 stramming multiprocessor(SM) target은 module이 컴파일 되는 GPU의 SM 버전보다 작거나 같아야 한다.
- 지원되는 최소 GPU(Maxwell)에 대한 코드를 생성하려면 SM 5.0에 대한 아키텍처 타겟(예: --gpu-architecture=compute_50)을 사용한다. optiX는 내부적으로 코드를 재작성하므로 이러한 타겟은 최신 GPU에서도 작동한다.
- CUDA toolkit 10.2 이상은 SM 5.0 target에 대한 사용 중단 경고를 표시한다. 이러한 경고는 컴파일러 옵션 -Wno-deprecated-gpu-targets로 안 뜨게 할 수 있다.
- 만약 Maxwell GPU에 대한 지원이 필요하지 않은 경우, 다음 상위 GPU architecture target인 SM 6.0(Pascal)을 사용하여 이러한 경고를 표시하지 않을 수 있다.
- --mecahine=64 (-m64)를 사용하는 것이 좋다. optiX에서는 64bit code만 지원된다.
- --optix-ir 또는 --ptx로 출력 유형을 정의한다. obj나 cubin으로 컴파일하면 안된다.
- 디버깅을 위해 디버그 플래그 -G를 사용한다. symbolic debugging은 현재 optix-IR만 지원되며 PTX에는 지원되지 않지만 디버그 지원으로 컴파일된 PTX는 Optix에 대한 입력으로 사용할 수 있다. 또한 환경변수 OPTIX_FORCE_DEPRECATED_LAUNCHER를 1로 설정해야 할 수 있다. 중단점에 도달할 수 없는 경우 애플리케이션을 시작하기 전에 이 환경 변수를 설정해야 한다.
- --relocatable-device-code=true(-rdc)를 활성화 해라. command nvcc는 nvrtc에서 지원하지 않는 --key-device-function 옵션도 사용할 수 있다. 이 flag를 사용하면 CUDA 컴파일러가 직접 또는 연속 dead code로서 callable를 제거하지 못하도록 한다.
- 더 작고 빠른 코드를 얻으면 --use_fast_math를 활성화하면 된다. 이 flag를 사용하면 삼각 함수 및 역수에 대해 .approx instruction을 활성화하여 느린 배정밀도 부동 소수점이 실수로 사용되는 것을 방지할 수 있다. 성능상의 이유로 리 flag를 설정하는 것이 좋으며, 정밀도가 더 필요한 사용 사례에는 예외적이다.
- Nsight Compute로 코드를 프로파일링하려면 --generate-line-info를 활성화하고 application code의 OptixModuleCompileOptions에서 debugLevel = OPTIX_COMPILE_DEBUG_LEVEL_MODERATE를 설정해야 한다.
6.2 Programming model
optix programming model은 CUDA의 multiple instruction, multiple data(MIMD) 하위 집합을 지원한다. 실행은 다른 스레드와 독립적이야 한다. 따라서 공유 메모리 사용과 barrier 와 가튼 warp 전체 또는 block 전체 동기화는 입력 PTX code에서 허용되지 않는다. math, texture, atomic operation, control flow, memory로의 data loading을 포함한 다른 모든 GPU 명령어는 허용된다. vote와 ballot과 같은 특수한 warp-wide instruction은 허용되지만, 전체 CUDA 프로그램 모델과 달리 locality of threads가 보장되지 않고 실행 중에 인접 스레드가 변경될 수 있으므로 예기치 않은 결과를 초래할 수 있다. 하지만 warp-wide instruction 명령어는 예를 들면 warp-aggregated atomic add을 구현하는 등 해당 알고리즘이 localitiy와 무관한 경우 안전하게 사용할 수 있다. PTX IR에 정의된 PTX의 특수 레지스터는 OptiX에서 다음과 같이 해석된다.
locality of thread는 스레드가 작업을 수행할 때 메모리와 디스크에서 데이터를 읽는 것을 얘기한다. 데이터는 종종 연속적이거나 가까운 위치에 저장된다. 하드웨어는 이를 통해 블록 메모리를 빠른 캐시로 로드하여 연속적/가까운 메모리 위치에 대한 액세스가 빨라진다.
처음 네 개의 레지스터는 각각 threadIdx, blockDim,blockIdx, gridDim으로 CUDA 내제되어 액세스할 수 있지만 다른 모든 특수 레지스터는 PTX inline 어셈블리를 사용해야 한다. 위의 모든 레지스터 사용은 PTX 또는 Optix IR 입력 모두 적용된다.
메모리 모델은 ray generation에서 시작되는 단일 실행 인덱스의 실행 내에서만 일관되며, optixTrace 또는 호출 가능한 program에서 도달한 후속 프로그램에서만 일관성이 유지된다. 여기에는 스택 할당 변수에 대한 쓰기가 포함된다. 다른 실행 인덱스로부터 쓰기는 실행이 완료될 때까지 사용할 수 없다. 필요한 경우, launch index가 순서가 필요하지 않은 경우 atomic operation을 사용하여 launch index 간에 데이터를 공유할 수 있다. memory fence는 지원하지 않는다.
입력 PTX에는 하나 이상의 optix program이 포함되어야 한다. program type은 pipeline 실행 중에 program을 사용할 수 있는 방법에 영향을 준다. 이러한 프로그램 유형은 프로그램 ㅣ름 앞에 다음 접두사를 붙여 지정한다.

특정 함수를 두 개 이상의 유형에 사용해야 하는 경우 해당 프로그램 접두사가 포함된 여러 개의 사본을 생성해야 한다.
또한 각 프로그램은 실제 ray tracing 관련 기능을 구현하는 특정 device 측에 포함되어 호출할 수 있다.
6.3 Module Creation
모듈에는 모든 prgram type의 여러 프로그램을 포함할 수 있다. 두 개의 옵션 구조체가 컴파일 프로세스의 매개변수를 제어한다.
- OptixPipelineCompileOptions
단일 pipeline에 연결된 program group을 만드는 데 사용되는 모든 모듈에 대해 동일하다. - OptixModuleCompileOption
동일한 파이프라인 내의 모듈에 따라 다를 수 있다.
이 옵션은 최적화 수준과 같은 일반적인 컴파일 설정을 제어한다. OptixPipelineCompileOptions는 custom any-hit program, curve primitives, sphere primitives, motion blur, exceptions, ray payload 및 primitive attributes 사용과 같은 API 기능을 제어한다.
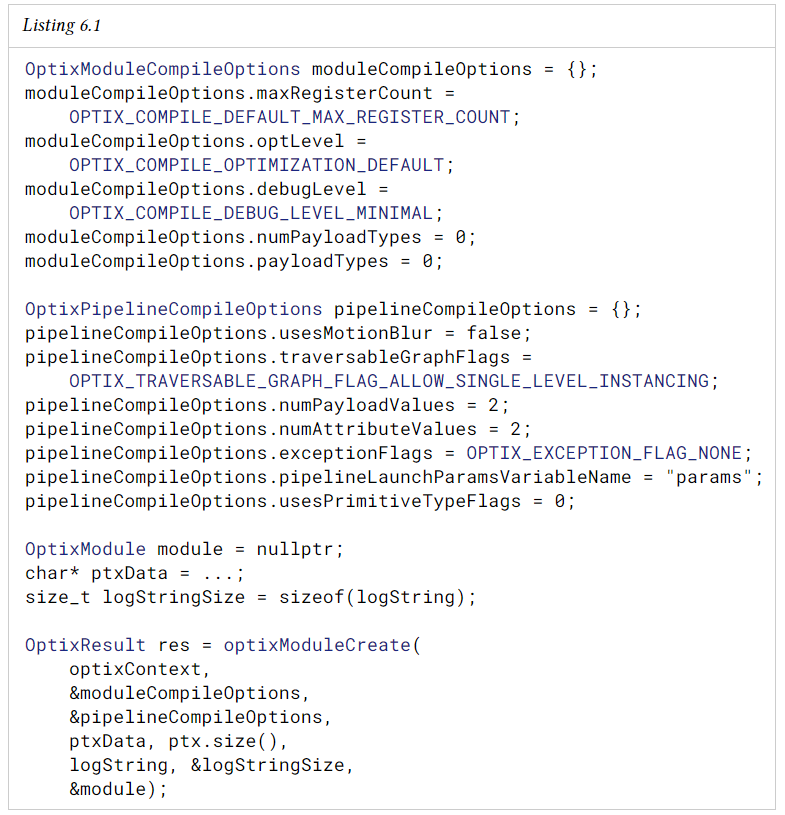
OptixPipelineCompileOptions의 numAttributeValues field는 attribute를 저장하기 위해 예약된 32bit word의 수를 정의한다. 이는 optixReportIntersection의 attribute 정의에 해당한다.
OptixPipelineCompileOptions의 numPayloadValues field는 ray payload를 저장하기 위해 예약된 32bit word의 수를 정의한다. 또는 OptixModuleCompileOptions의 numPayloadTypes 및 payloadTypes 필드를 사용하여 ray payload 사용을 더 자세히 저장할 수 있다.
scene에 기본 삼각형만 포함되어 있을 때 최상의 performance를 얻으려면 OptixPipelineCompileOptions::usesPrimitiveTypeFlags를 OPTIX_PRIMITIVE_TYPE_FLAGS_TRIANGLE로만 설정해야 한다.
6.4 Pipeline launch parameter
모든 모듈에서 access해야 하는 실행 가변 매개변수 또는 값을 OptixPipelineCompileOptions에 명명된 사용자 정의 변수를 통해 지정할 수 있다. 액세스가 필요한 각 모듈에서 extern 또는 exturn "C" 링크와 constant memory 지정자를 사용하여 이 변수ㅡㄹ 선언한다. 변수의 크기는 pipeline의 모든 module에서 일치해야 한다. 크기는 같지만 유형이 다른 변수는 정의되지 않은 동작을 유발할 수 있다.
예를들면, 헤더파일은 Params 구조체의 instance로서 공유되는 변수 Params라는 이름으로 정의한다.

아래는 params.h를 포함함으로써 program이 공유 매개변수 구조체 instance의 값에 액세스하고 설정할 수 있음을 보인다.

6.4.1 Parameter specialization
경우에 따라 pipeline에서 모듈을 전문화하여 특정 기능을 켜고 끄는 것이 유용할 수 있다. 예를 들어 사용자는 shader에서 shdow ray 계산을 위한 지원을 컴파일하고 싶지만, scene parameter에 필요하지 않은 경우 이 지원을 비활성화하고 싶을 수 있다. 사용자는 여러 버전의 PTX program을 사용하거나 파이프라인 시작 파라미터에서 shadow 지원 여부를 나타내는 값을 읽어서 이 기능을 지원하고 싶을 수 있다. 여러 버전의 PTX program을 사용하면 최상의 성능을 얻을 수 있지만 모든 program version을 유지 관리하고 저쟁해야 하는 비용이 발생한다. optix는 pipeline 실행 파라미터의 값을 특수화하는 메커니즘을 제공한다.
모듈을 컴파일하는 동안 optix는 OptixPipelineCompileOptions::pipelineLaunchParamsVariableName으로 지정된 pipeline launch pipeline 구조체에 대한 로드를 주어진 범위 내에서 찾으려고 시도한다. 이렇게 지정된 로드는 각각 미리 정의된 값으로 대체된다. 컴파일러 최적화 pass는 이러한 상수 값을 사용한다.
OptixModuleCompileBoundValueEntry 구조체는 파이프라인 파라미터의 일부를 대체할 바이트 배열을 지정한다.
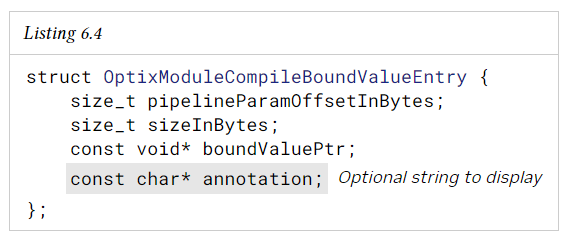
아래는 모듈 컴파일 중에 OptixModuleCompileBoundValueEntry 구조체 배열을 OptixModuleCompileOptions에 지정하는 방법을 보여준다.
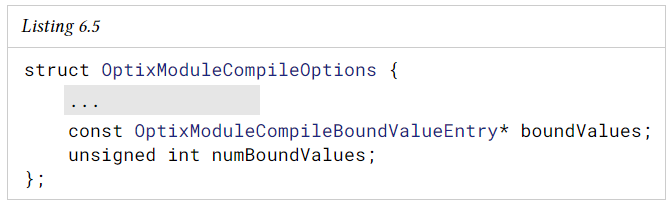
아래는 shadow ray를 비활성화하도록 모듈을 특수화하는 예이다.

host측에서 아래에서 실행 매개변수의 구현이 나와있다.

이 파이프라인 실행 매개변수 전문화를 통해 아래 코드가 가능해진다.

이후 최적화를 통해 도달할 수 없는 코드가 제거되도록 아래와 같이 한다.

bound value은 파이프라인 파라미터 상수 값을 나타내기 위한 것이다. optiX는 pipelineParams에서 모든 부하를 찾아 적절한 바운드 값과 연관시키려고 한다. 그러나 이러한 로드와 bound 값을 안전하고 안정적으로 상호 연관시킬 수 없는 경우가 있다. 예를들어 inline 함수가 아닌 함수에 대한 인수로 pipelineParams에 대한 포인터가 전달되거나 loop에서의 액세스로 인해 pipelineParams에 대한 부하의 offset을 정적으로 결정할 수 없는 경우 상관 관계가 불가능하다. 어떤 모듈도 올바르게 작동하기 위해 특수화되는 값에 의존해서는 안된다. optixLaunch에 지정된 pipelineParams의 어떤 값은 바운드 값과 일치해야 한다. 컨텍스트 유효성 검사 모드가 활성화된 경우 optix는 지정된 바인딩된 값이 optixLaunch에 지정된 pipelineParams의 값과 일치하는지 확인한다.
캐싱이 활성화된 경우 값을 변경하면 모듈이 새로 컴파일된다.
pipelineParamOffsetByes 및 sizeInBytes는 pipelineParams 변수의 bound 내에 있어야 하며, 그렇지 않으면 optionModuleCreate에서 OPTIX_ERROR_INVALID_VALUE가 반환된다.
바인딩된 값이 둘 이상 겹치거나 바인딩된 값의 크기가 0과 같으면 optixModuleCreate에서 OPTIX_ERROR_INVALID_VALUE가 반환된다.
파이프라인의 모든 모듈에 동일한 바운드 값 집합을 사용할 필요는 없지만 모듈 간에 겹치는 값은 동일한 값을 가져야 한다. 그렇지 않으면 optixPipeCreate에서 OPTIX_ERROR_INVALID_VALUE가 반환된다.
6.5 Program group creation
OptixProgramGroup object는 하나에서 세 개의 OptixModule Object로 생성되며 SBT record의 헤더를 채우는 데 사용한다. 프로그램 그룹에는 다섯 가지의 유형이 있다.
- OPTIX_PROGRAM_GROUP_KIND_RAYGEN
- OPTIX_PROGRAM_GROUP_KIND_MISS
- OPTIX_PROGRAM_GROUP_KIND_EXCEPTION
- OPTIX_PROGRAM_GROUP_KIND_HITGROUP
- OPTIX_PROGRAM_GROUP_KIND_CALLABLES
모듈은 하나 이상의 프로그램을 포함할 수 있다. 모듈의 프로그램은 optixProgramGroupCreate 함수에 전달된 optixProgramGroupSec라는 구조체의 일부인 entry 함수의 이름으로 지정된다. 4개의 program group에는 하나의 프로그램만 (entry function을?)포함할 수 있으며, OPTIX_PROGRAM_GROUP_KIND_HITGROUP만 closest-hit, any-hit, intersection program에 대해 최대 3개의 program을 지정할 수 있다.
Module의 program은 여러 개의 OptixProgramGroup 객체에서 사용할 수 있다. 결과 program group은 SBT record를 원하는 수만큼 채우는 데 사용할 수 있다. 컴파일 옵션이 일치하는 한 파이프라인 전반에서 프로그램 그룹을 사용할 수 있다.
모듈의 lifetime은 해당 모듈을 참조하는 optixProgramGroup까지 연장되어야 한다.
hit-group은 ray가 primitive와 교차하는지 여부를 테스트하는 데 사용되는 intersection program과 ray가 primitive와 교차할 때 실행될 hit shader를 지정한다. built-in primitive의 유형의 겨우 optixBuiltinSModuleGet()에서 built-in intersection program을 가져와 hitGroup에서 사용해야 한다. 특별한 경우로, 삼각형 및 DMM triangle primitive의 경우 intersection program이 필요하지 않으며 무시된다.
다음 예는 단일 hit program group을 구성하는 방법을 보여준다.
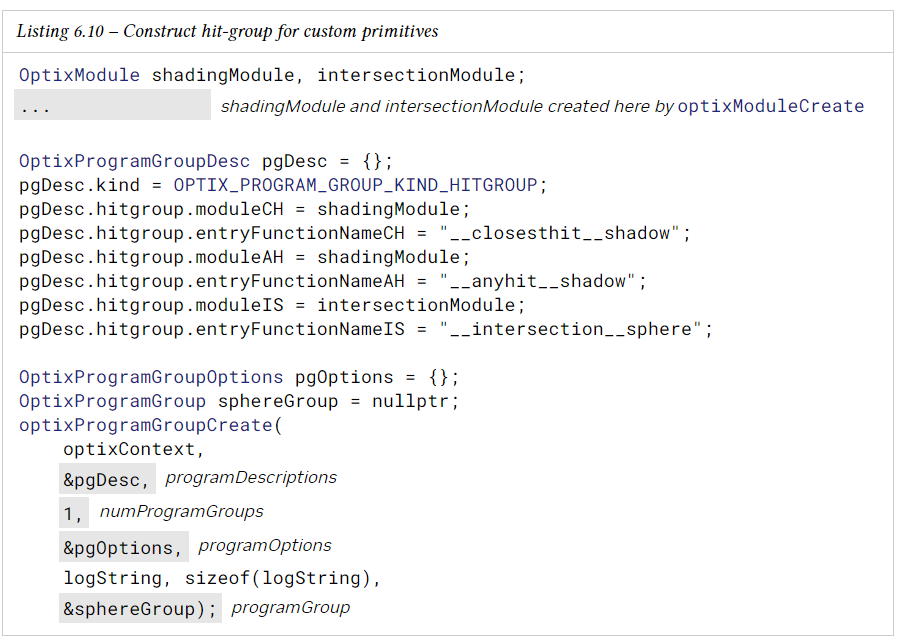
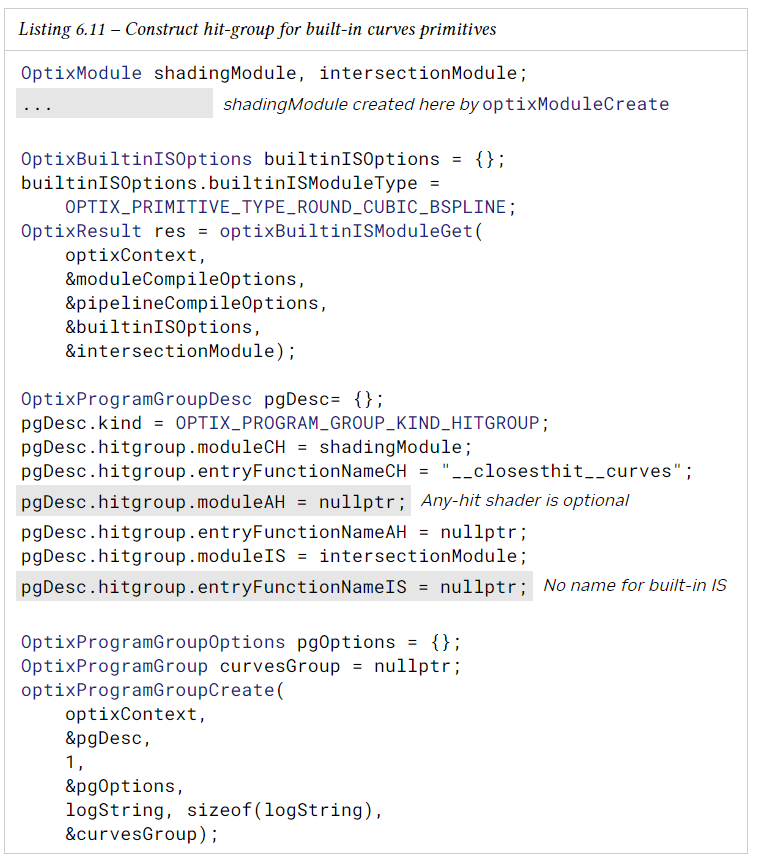
sphere primitive에 대한 hit group 구성은 curve example과 유사하며, 모듈 유형 OPTIX_PRIMITIVE_TYPE_ROUND_CUBIC_BSPLINE을 OPTIX_PRIMITIVE_TYPE_SPHERE로 대체하면 된다.
optixProgramGroupCreate을 한 번 호출하면 다양한 종류의 여러 program group을 구성할 수 있다. 다음 코드는 ray generation 및 miss program group을 구성하는 방법을 보여준다.
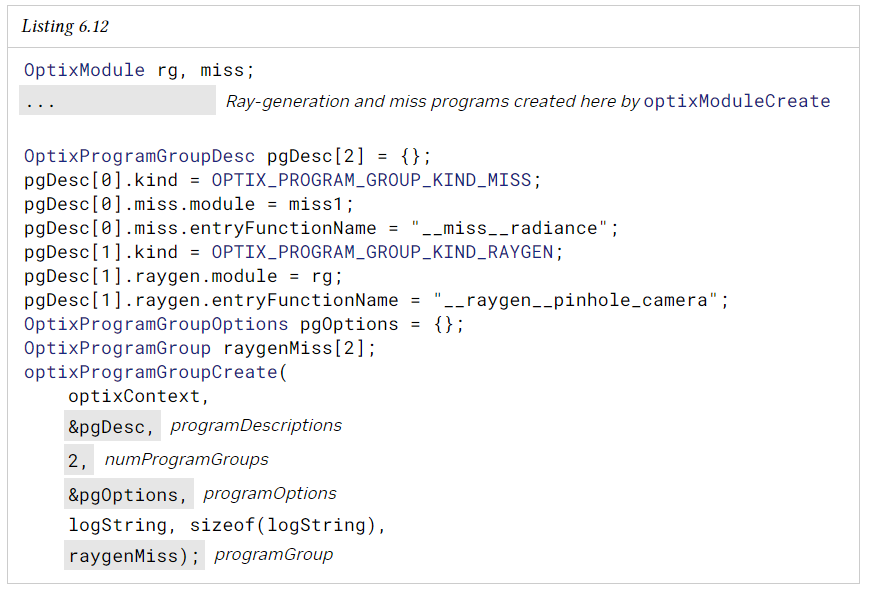
OptixProgramGroupOptions에 정의된 옵션은 단일 파이프라인에 연결된 프로그램 그룹에 따라 달라질 수 있으며, 이는 OptixModuleCompileOptions와 유사하다.
6.6 Pipeline linking
pipeline의 모든 program group을 정의한 후에는 이를 OptixPipeline에 연결해야 합니다. 그런 다음 결과 OptixPipeline 객체를 사용하여 ray generation 실행을 호출한다.
OptixPipeline이 링크될 때 OptixpipelineLinkOption 및 OptionPipelineCompileOptions에 따라 일부 fixed function component를 선택할 수 있다. 이러한 option은 이전에 pipeline에서 모듈을 컴파일 하는데 사용되었다. link option은 재귀적 레이트레이싱을 위한 최대 재귀 깊이 설정과 디버깅을 위한 파이프라인 레벨 설정으로 구성된다. 그러나 최대 재귀 깊이 값에는 링크 옵션으로 설정된 제한을 재정의하는 상환이 있다.
OptixPipeline을 생성하고 링크하는 예제이다.
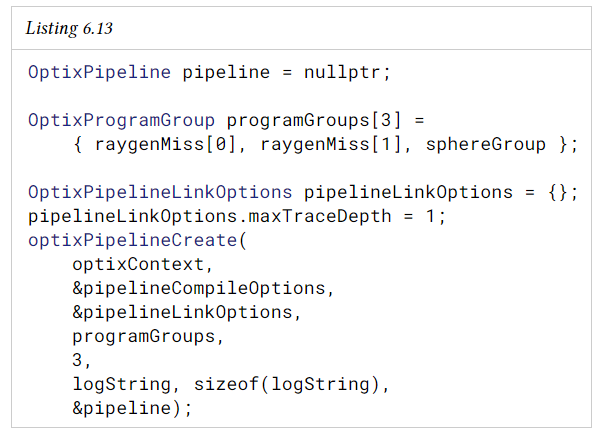
optixPipelineCreate를 호출하면 완전히 연결된 모듈이 드라이버에 로드된다.
After calling optixPipelineCreate, the fully linked module is loaded into the driver.
optiX는 pipeline 당 소량의 GPU 메모리를 사용한다. 이 메모리는 pipeline 또는 device context가 파괴되면 해제된다.
6.7 Pipeline stack size
모듈의 프로그램은 direct stack와 continuation stack이라는 두 가지 유형의 스택 구조를 사용할 수 있다. pipeline을 실행하는데 필요한 결과 stack은 결과 호출 그래프에 따라 달라지므로 pipeline을 적절한 스택 크기로 구성해야 한다. 이러한 크기는 각 프로그램 그룹에 대해 컴파일러가 결정할 수 있다. program set이 동일하다면 파이프라인을 다른 호출 그래프에 재사용할 수 있다. 이러한 이유로 파이프라인 스택 크기는 pipeline compile option과 별도로 구성된다.
ray-generation, miss, exception, closest git, any-hit 및 intersection program에서 발생하는 direct stack 요구 사항과 exception program에서 발생하는 continuation stack 요구 사항은 내부적으로 계산되므로 구성할 필요가 없다. direct call이 가능한 program에서 발생하는 direct stack 요구 사항은 구성해야 한다. 이러한 요구 사항이 명시적으로 구성되지 않은 경우 내부 기본 구현이 사용된다. cotinuation-callable 및 direct-callable program은 최대 깊이가 2개 이하인 경우 기본 구현이 정확하다(반드시 최적은 아님). 기본 구현이 정확하더라도 사용자는 특정 호출 그래프 구조에 대한 지식을 바탕으로 언제든지 더 정확한 스택 요구사항을 제공할 수 있다.
개별 program group에 대한 스택 요구 사항을 query하려면 optixProgramGroupGetStackSize를 사용한다. 이 정보를 사용하여 optix program의 특정 호출 그래프에 필요한 총 스택 크기를 계산할 수 있다. 특정 pipeline에 대한 stack 크기를 설정하려면 optixPipelineSetStackSize를 사용한다. 다른 매개변수의 경우 이러한 계산을 구현하기 위해 도움을 주는 함수를 사용할 수 있다. 다음은 매우 보수적인 접근 방식에서 시작하여 단계별로 추정치를 세분화하여 optixPipelineSetStackSize에 대한 스택 크기를 계산하는 방법에 대한 설명이다.
cssRG는 모든 ray generation program의 최대 연속 스택 크기를 나타내며, miss, closest hit, any-hit, intersection 및 continuation callable program도 유사하게 나타낸다. dssDC는 직접 호출 가능한 모든 프로그램의 최대 스택 크기를 직접 나타낸다. 최ㅐ 추적 깊이는 최대 추적 깊이를 나타내고(OptixPipelineLinkOptions::maxTraceDepth에서와 같이), 최대 CCDepth와 최대 DCDepth는 각각 continuation callable program과 direct callable program의 호출 트리의 최대 깊이를 나타낸다. 그런 다음 optixPipelineSetStackSize의 세 파라미터를 계산하는 간단하고 보수적인 접근 방식이 있다.

이 계산은 여러 가지 방법으로 계산할 수 있다. continuation stack size 계산을 위해 스택 크기는 cssIS 및 cssAH를 다른 합집합 위에 사용하지 않고 한 수준의 cssCHOrMSPlusCCTree에 대해 상쇄할 수 있다. 이렇게 하면 더 복잡하지만 더 나은 추정치를 얻을 수 있다.

앞의 공식은 도움을 주는 함수인 optixUtilComputeStackSizes에 의해 구현된다.
direct callable program의 call tree를 call site의 의미 유형에 따라 개별적으로 분석하면 처음 두 항의 계산을 개선할 수 있다. 이러한 맥락에서 any-hit 및 intersection program의 call cite는 순회로 계산되는 반면, ray generation, miss, closest hit program의 call cite는 계산된다.

이 개선 사항은 도움 함수 optixUtilComputeStackSizeDCSplit에 의해 구현된다.
시나리오에 따라 이러한 추정치는 더 개선될 수 있으며 때로는 크게 개선될 수 있다. 예를 들면 continuation callable program의 호출 트리가 두 개 있다고 가정해보자. 하나의 호출 트리는 깊지만 관련된 continuation callable program에는 작은 continuation stack이 필요하다. 다른 호출 트리는 얕지만 관련된 continuation callable program에는 상당히 큰 continuation stack이 필요하다. cssCCTree의 추정치는 다음과 같이 개선할 수 있다.

이 개선사항은 도움을 주는 함수 optixUtilComputeStackSizesCssCCTree에 의해 구현된다.
camera ray와 shadow ray 등 광선 유형을 개별적으로 고려하는 경우 maxTraceDepth와 관련된 모든 표현식에 대해 유사하다.
direct stack은 direct callable program이 실행될 때 사용하는 stack이다. direct callable program은 다른 program에서 직접 호출할 수 있는 program으로 호출 스택에 추가된다.
Continuation stack은 continuation callable program이 실행될 때 사용하는 stack이다. Continuation callable program은 다른 program에서 호출할 수 있지만, 호출 스택에 추가되지 않는 대신 continuation stack에 추가된다.6.7.1 Constructing a path tracer
간단한 path tracer는 camera ray와 shadow ray의 두 가지 ray type으로 구성할 수 있다. path tracer는 ray generation, miss, closest hit program으로만 구성되며, any-hit, intersection, continuation callable 또는 direct callable program은 사용하지 않는다. camera ray는 각각 miss 및 closest hit program인 MS1과 CH1만 호출한다. CH1은 그림자 광선을 추적할 수 있으며, 이 경우 각각 miss 및 closest hit program MS2와 CH2만 호출한다. 즉, 최대 trace 깊이는 2이며 초기 공식은 다음과 같이 단순화 한다.

그러나 호출 그래프 구조를 보면 MS2 또는 CH2는 CH1에서만 호출할 수 있다는 것을 알 수 있다. 이 제한으로 인해 다음과 같은 추정이 가능하다.

이 추정치는 이전 추정치보다 나쁘지 않지만, 예를 들어 가장 closest hit program의 stack size가 다르고 miss program이 식을 지배하지 않는 경우 더 나은 경우가 많다.
도움을 주는 함수 optixUtilComputeStackSizesSimplePathTracer는 두 개의 단일 program 대신 closest hit program의 두 배열을 허용하여 이 공식을 구현한다.
6.8 Compliation cache
컴파일 작업은 optixModuleCreate 또는 optixProgramGroupCreate을 호출할 때 자동으로 트리거되며, optixPipelineCreate 중에도 트리거될 수 있다. optixDeviceContext에서 활성화된 경우 이 작업은 디스크에 자동으로 캐시된다. 캐싱은 반복되는 program 및 program group에 대한 컴파일 작업을 줄여준다. 캐싱은 기본적으로 활성화되어 있지만 optixDeviceContextSetCacheEnabled를 통해 비활성화 할 수 있다.
일반적으로 캐시 항목은 동일한 드라이버 버전 및 GPU 유형과만 호환이 된다.
