[LG CNS AM Inspire Camp 1기] MSA (5) - Kafka를 이용하여 MSA 데이터 일관성 문제 해결하기 (1)
LG CNS AM Inspire 1기
INTRO
이전 포스팅에서 마이크로서비스 간 통신 방법에 대해 알아봤다.
특히 여러 서비스 인스턴스를 운영할 때 발생하는 데이터 일관성 문제를 다뤘는데, 이번에는 Kafka를 활용해 이 문제를 어떻게 해결할 수 있는지 알아보려고 한다 👀
1. 데이터 일관성 문제 리마인드
먼저 이전 포스팅에서 살펴본 문제를 다시 생각해보자
여러 인스턴스로 주문 서비스를 운영할 때, 각 인스턴스는 자체 DB를 가지게 된다.
이로 인해 사용자의 주문이 여러 DB에 분산되어 저장되면서 데이터 일관성 문제가 발생한다.
사용자가 총 3개의 주문을 했지만, 서비스를 호출할 때마다 로드 밸런싱에 의해 다른 인스턴스로 요청이 가기 때문에 모든 주문 정보를 한 번에 조회하기 어렵다.
이 문제를 해결하기 위해 메시지 큐를 활용한 이벤트 기반 아키텍처를 도입할 수 있다.
오늘은 그 중에서도 Apache Kafka를 활용한 방법을 알아보자.
2. Apache Kafka란?
Apache Kafka는 LinkedIn에서 개발한 분산 스트리밍 플랫폼이다.
여러 서비스 간에 메시지를 비동기적으로 주고받을 수 있게 해주며 RabbitMQ에 비해 높은 처리량을 보여준다.
💡 Kafka의 주요 개념
Topic: 메시지가 저장되는 카테고리
Producer: 토픽에 메시지를 발행하는 어플리케이션
Consumer: 토픽에서 메시지를 구독하는 어플리케이션
Broker: Kafka 서버
Partition: 토픽을 분할하여 병렬 처리를 가능하게 하는 단위
Kafka는 메시지를 순서대로 저장하고, 소비자가 원하는 시점부터 메시지를 읽을 수 있는 특징이 있다.
이러한 특성 때문에 MSA 환경에서 이벤트 소싱(Event Sourcing) 패턴을 구현하는 데 적합하다.
위 개념을 조금 더 자세히 살펴보면 다음과 같다.
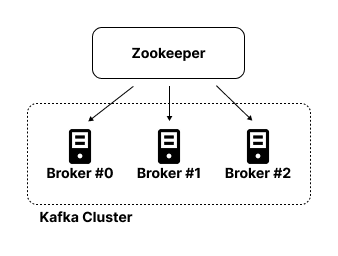
Kafka는 공식 사이트에서 최소 3개 이상의 브로커를 사용하길 권장하고 있다.
왜냐하면 n개의 Broker 중에서 1대는 Controller의 기능을 수행하기 때문이다.
Controller 역할
- 각 Broker에게 담당 파티션 할당
- Broker 정상 동작 모니터링
이제 이렇게 여러개의 Broker로 구성된 Kafka Cluster는 Kafka를 구독하는 Kafka-Client Application과 데이터를 주고받게 된다.
Kafka-Client는 간단하게 Kafka Cluster와 데이터를 주고받는 대상이라고 보면 된다.
(필자가 진행하는 실습에서는 각 서비스가 Kafka-Client가 된다.)
💡 Kafka 설치 (1) - 명령어 다운
필자는 도커를 이용하여 Kafka 컨테이너를 띄워서 사용할 예정이다.
우선 Kafka 컨테이너에 명령을 보내기 위해서는 관련 쉘 스크립트를 다운받아야 한다.
Kafka 명령어 설치 사이트에서 다음 사진과 같이 Binary를 다운로드 받도록 하자
다운로드가 완료되면 여러 쉘 스크립트가 저장된 폴더가 하나 생긴다.
우리는 이제 이 폴더에서 쉘 스크립트를 실행하여 명령어를 실행할 예정이다.
💡 Kafka 설치 (2) - 컨테이너 실행
우선 Docker Hub에서 Kafka 이미지를 pull해야 한다.
필자는 latest 버전으로 pull을 받았다.
이후, 명령어를 입력하여 컨테이너를 실행시키자
Kafka 컨테이너 실행 명령어
docker run -d -p 9092:9092 --name broker apache/kafka:latest
Broker라는 이름으로 컨테이너를 실행시켰다.
Kafka는 내부적으로 9092 포트를 사용하기 때문에 localhost의 9092 포트와 바인딩을 시켜줬다.
3. Kafka 사용해보기
우선 지금 작성하는 내용은 Kafka를 실행시켜보고 동작을 확인하기 위함이다.
(프로젝트에 Kafka를 적용하는 부분은 좀있다가 다룰 예정이다.)
이전에 다운로드 받은 Kafka 쉘 스크립트가 위치한 디렉토리의 /bin 으로 이동하자
그리고 다음과 같은 명령어를 입력하면 토픽을 생성할 수 있다.
여기서 필자는 Mac OS를 사용하기 때문에 Window와는 명령어가 다를 수 있다.

사진과 같이 여러 명령어가 있는 모습을 볼 수 있다.
이제 메세지가 저장될 토픽을 다음 커맨드를 입력하여 실행해보자
💡 토픽 생성 및 확인
◉ 명령어 - 토픽 생성
./kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092 --partitions 1
◉ 명령어 - 토픽 리스트 확인
./kafka-topics.sh --bootstrap-server localhost:9092 --list

사진과 같이 quickstart-events 토픽이 생성되었음을 확인할 수 있다.
💡 토픽에 메세지 전송하기
◉ 명령어 - 메세지 발행
./kafka-console-producer.sh --bootstrap-server localhost:9092 --topic quickstart-events
◉ 명령어 - 메세지 확인
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic quickstart-events --from-beginning
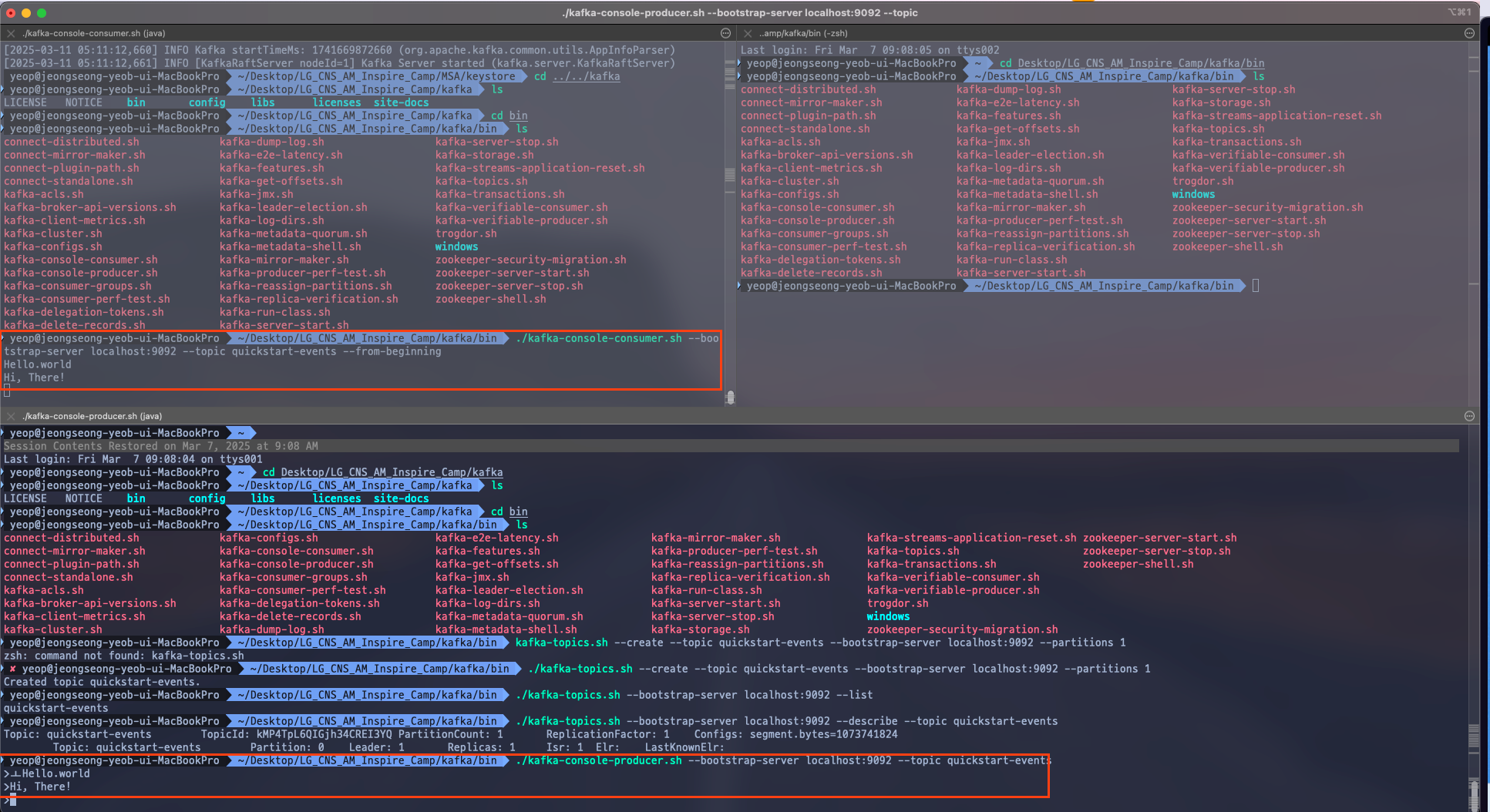
아마 잘 안보일것 같긴한데, 아래는 메세지 발행 커맨드를 입력한 창이고 좌상단 커맨드창은 메세지 확인 창을 띄워놓은 상태이다.
실제로 메세지 발행 커맨드를 입력하여 가상 쉘 스크립트로 접근하고 메세지를 입력하면 위쪽 상단에서도 실시간으로 입력한 데이터가 저장되는 모습을 볼 수 있다.
여기서 메세지 확인 커맨드에서 --from-beginning 옵션은 메세지 브로커에 저장된 내용을 처음부터 읽어오겠다는 것을 의미한다.
만약 특정 범위부터 읽어오고 싶다면 다음과 같이 오프셋을 추가해주면 된다.
◉ 명령어 - 메세지 확인 - 특정 라인부터
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --partition 0 --offset 1 --topic quickstart-events

메세지 브로커에는 Hello, World 와 Hi, There! 메세지가 들어있으나 Hi, There! 만 확인되는 모습을 볼 수 있다.
4. Kafka 적용하기 - Catalog Service
이제부터 Kafka를 기존에 작업하던 프로젝트에 적용해보자
우선 구조를 보면 다음과 같다.
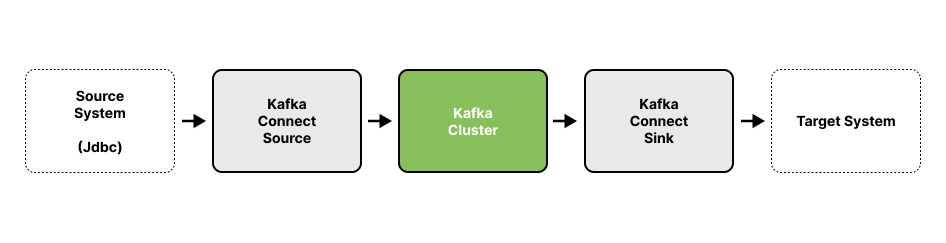
Kafka Cluster에 접근하기 위해서는 Kafka Connect의 Source, Sink가 필요하다.
간단하게 Source는 데이터를 Kafka Cluster에 집어넣을 때 사용되고, Sink는 Kafka Cluster에서 가져올 때 사용된다.
필자가 진행하는 프로젝트에서는 다음과 같이 동작해야 한다.
동작 순서
1. User가 상품을 주문한다.
2. 주문 내역이 Order-Service를 통해 Kafka Cluster에 메세지로 저장된다.
3. 주문 내역에 맞춰서 Catalog-Service에서 재고 수량을 차감한다.
4. Kafka Cluster에 저장된 주문 내역이 하나의 DB에 자동으로 저장된다.
즉, 위에서 설명한 내용을 참고했을 때, Kafka Cluster를 기준으로 Catalog-Service는 Consumer, Order-Service는 Producer가 될 것이다.
왜냐하면, Order-Service에서 주문 정보를 생성해서 Kafka Cluster에 메세지를 발행할 것이기 때문에 Producer로 볼 수 있다.
마찬가지로 Kafka Cluster에서 메세지를 가져와서 재고 수량을 차감시킬 것이기 때문에 Catalog-Service는 Consumer로 볼 수 있다.
우선, 이 개념을 이해하고 나머지 실습을 진행하는 것이 중요하다!
위와 같이 Kafka 의존성을 추가해서 프로젝트를 설정하자
💡 Kafka 설정 추가 - Catalog Service
다음으로 Kafka를 사용하기 위해 필요한 설정 정보를 추가해주자
우선 코드를 살펴보면 다음과 같다.
Sample Code
@EnableKafka @Configuration public class KafkaConsumerConfig { @Bean public ConsumerFactory<String, String> consumerFactory() { Map<String, Object> properties = new HashMap<>(); properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); properties.put(ConsumerConfig.GROUP_ID_CONFIG, "consumerGroupId"); properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); return new DefaultKafkaConsumerFactory<>(properties); } @Bean public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() { ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory = new ConcurrentKafkaListenerContainerFactory<>(); kafkaListenerContainerFactory.setConsumerFactory(consumerFactory()); return kafkaListenerContainerFactory; } }
해당 코드는 Catalog-Service에서 Kafka Consumer 설정을 진행하는 코드이다.
중요한 부분을 정리하면 다음과 같다.
@EnableKafka
- 이 어노테이션은 Spring Kafka 기능을 활성화하는 어노테이션이다.
- 이후에 살펴볼
@KafkaListener어노테이션을 사용할 수 있게 해준다.
@Configuration
- 스프링 설정 클래스임을 의미한다.
BOOTSTRAP_SERVERS_CONFIG
- Kafka 브로커의 주소를 설정한다.
- 필자는 도커 컨테이너로 Kafka를 띄워놨는데 9092로 포트바인딩을 진행했다.
- 따라서,
localhost:9092로 설정한다.
GROUP_ID_CONFIG
- Consumer 그룹 ID를 설정한다.
- 여기서 같은 그룹에 속한 Consumer들은 메시지를 분산해서 처리한다.
AUTO_OFFSET_RESET_CONFIG
- Consumer가 처음 시작할 때 또는 오프셋이 없을 때 어디서부터 메시지를 읽을지 설정한다.
earliest는 토픽의 시작부터 읽는다는 의미이다.
KEY_DESERIALIZER_CLASS_CONFIG,VALUE_DESERIALIZER_CLASS_CONFIG
- Kafka 메시지의 키와 값을 역직렬화하는 방법을 설정한다.
- Kafka는 JVM 기반의 Scala라는 언어로 만들어져있기 때문에 Java와 호환성이 좋다.
- 여기서는 String 타입으로 역직렬화하도록 설정한다.
- 이 설정이 필요한 주된 이유는 Kafka가 바이트 배열로 메시지를 전송하기 때문이다.
- 따라서 송신자가 직렬화한 데이터를 수신자가 올바르게 해석하려면 역직렬화 방식을 지정해야 하며, 우리는 String으로 소비하겠다는 의미이다.
kafkaListenerContainerFactory() 메서드
@KafkaListener어노테이션이 붙은 메서드가 Kafka 메시지를 처리할 때 사용할 컨테이너 팩토리를 설정한다.- 앞서 만든 consumerFactory를 사용하여 Consumer 속성을 설정한다.
- 마지막으로 ConcurrentKafkaListenerContainerFactory는 여러 개의 Consumer 인스턴스를 동시에 실행할 수 있게 해준다.
이제 설정이 마무리 되었으니 실제로 토픽을 리스닝하는 클래스를 만들어보자
💡 Kafka 토픽 리스닝 - Catalog Service
우선 코드를 살펴보면 다음과 같다.
Sample Code
@Service @Slf4j public class KafkaConsumer { CatalogRepository repository; @Autowired public KafkaConsumer(CatalogRepository repository) { this.repository = repository; } @KafkaListener(topics = "example-catalog-topic") public void updateQty(String kafkaMessage) { Map<Object, Object> map = new HashMap<>(); ObjectMapper mapper = new ObjectMapper(); try { map = mapper.readValue(kafkaMessage, new TypeReference<Map<Object, Object>>() {}); } catch (JsonProcessingException ex) { ex.printStackTrace(); } CatalogEntity entity = repository.findByProductId((String)map.get("productId")); if (entity != null) { entity.setStock(entity.getStock() - (Integer)map.get("qty")); repository.save(entity); } } }
이 부분은 실제로 Kafka 토픽을 리스닝하고 변화가 감지되면 작동시킬 메서드를 정의한다.
위에서 @EnableKafka 어노테이션을 사용하여 Kafka 기능을 활성화했기 때문에 @KafkaListener 어노테이션을 사용하여 리스닝할 토픽을 지정한다.
여기서 우리는 토픽 이름을 example-catalog-topic 으로 지정할 예정이다.
다음으로 updateQty 메서드를 살펴보면 kafkaMessage라는 매개변수가 String으로 넘어오는 모습을 볼 수 있다.
그 이유는 우리가 이전에 KafkaConfig에서 역직렬화 방법을 String으로 선언했기 때문이다.
이제 해당 데이터를 가지고 Catalog DB에서 상품을 찾아보고 구매 수량에 맞춰 재고를 차감하는 로직이 작성되어 있다.
💡 주의사항
이전에 잠깐 설명했던 Kafka Connect는 실행되고 있지 않다.
즉, 위 로직은 CatalogRepository라는 JPA를 사용해서 동작하고 있는 것이다.
메세지 브로커에서 데이터 변경이 감지되면 자동으로 DB에 데이터를 저장하게끔하길 원한다면 다음 포스팅에서 다룰 Kafka Sink를 사용해야 한다.
OUTRO
분량 조절에 실패해서 아마 2개의 포스팅으로 Kafka 관련 내용을 정리해야할 것 같다.
물론, 코드를 계속 봐야겠지만 이번에 정리한 내용만으로는 아직 Kafka가 무엇인지 감이 잡히지 않을 수도 있다
그래서 다음 포스팅에서 Order Service에 적용되는 Kafka를 다시한번 살펴볼 예정이다.
이번 포스팅을 통해서 무엇을 위해 Kafka를 사용하고, Kafka는 어떻게 사용하고, 스프링 프로젝트에는 Kafka를 어떻게 적용하는지를 유념해서 다시 읽어보면 좋을 것 같다 👊
