INTRO
이전 포스팅에서는 서킷 브레이커 패턴을 이용하여 마이크로서비스 아키텍처에서 회복성을 확보하는 방법에 대해 살펴봤다.
이번 포스팅에서는 MSA 환경에서 또 다른 중요한 문제인 '디버깅과 모니터링'을 해결하는 분산 트레이싱 시스템인 Zipkin에 대해 알아보고, 실제로 적용해보자 👀
1. 분산 트레이싱이 필요한 이유
마이크로서비스 아키텍처에서는 하나의 요청이 여러 서비스를 거쳐 처리되기 때문에 문제가 발생했을 때 원인을 찾기가 매우 어렵다.
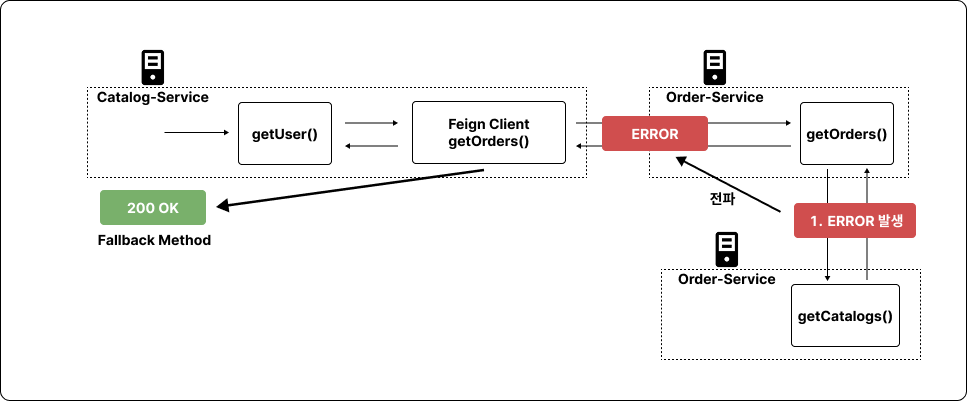
위 사진은 Order-Service에서 getOrders() 메서드를 호출하는 과정에서 에러가 발생하는 구조이다.
서킷 브레이커를 사용하는 이유가 사용자의 경험을 해치지 않기 위함이었다면, 분산 트레이싱을 사용하는 이유는 개발자의 경험을 해치지 않기 위함이라고 볼 수 있다.
실제로, 위 그림과 같이 여러 서비스가 연계되어 있는 환경에서 디버깅을 진행하려면 여러 가지 어려움이 있다.
디버깅 문제
여러 서비스의 로그를 동시에 확인해야 함
- 각기 다른 서비스에서 발생하는 로그를 한 번에 보기 어려움
요청의 흐름 추적이 어려움
- 어떤 서비스에서 어떤 순서로 요청이 처리되었는지 파악하기 힘듦
다양한 기술 스택
- 서로 다른 언어나 프레임워크로 개발된 서비스들을 모두 디버깅하기 어려움
이런 문제들을 해결하기 위해 분산 트레이싱이라는 개념이 등장했고, 이를 구현한 대표적인 도구 중 하나가 바로 Zipkin인 것이다.
💡 Zipkin이란?
그렇다면, Zipkin은 뭘까?
Zipkin은 트위터에서 개발한 오픈소스 분산 트레이싱 시스템으로, 마이크로서비스 아키텍처에서 요청의 흐름을 시각화하고 분석할 수 있게 해준다.
Zipkin의 주요 개념으로는 'Trace'와 'Span'이 있다.
Trace & Span
Trace
- 하나의 요청이 시스템을 통과하는 전체 경로를 나타내는 작업 그룹을 의미한다.
Span
- Trace를 구성하는 개별 작업 단위, 각 서비스에서 처리되는 하나의 작업을 의미한다.
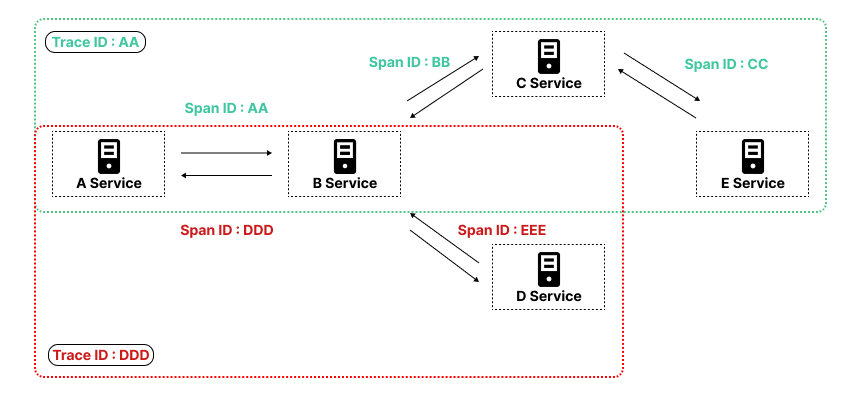
위 그림에서 볼 수 있듯이, 하나의 Trace ID에 여러 개의 Span ID가 포함된다.
각 Span은 요청이 특정 서비스에서 어떻게 처리되었는지에 대한 정보를 담고 있으며, 개발자는 이를 추적하여 로그를 트레이싱할 수 있다.
2. Zipkin 설정하기
Spring 기반의 마이크로서비스에서는 Zipkin 의존성을 추가하여 분산 트레이싱을 구현할 수 있다.
우선 Zipkin을 설치하기 위해 공식 홈페이지로 접근하면 다음과 같은 화면을 볼 수 있다.
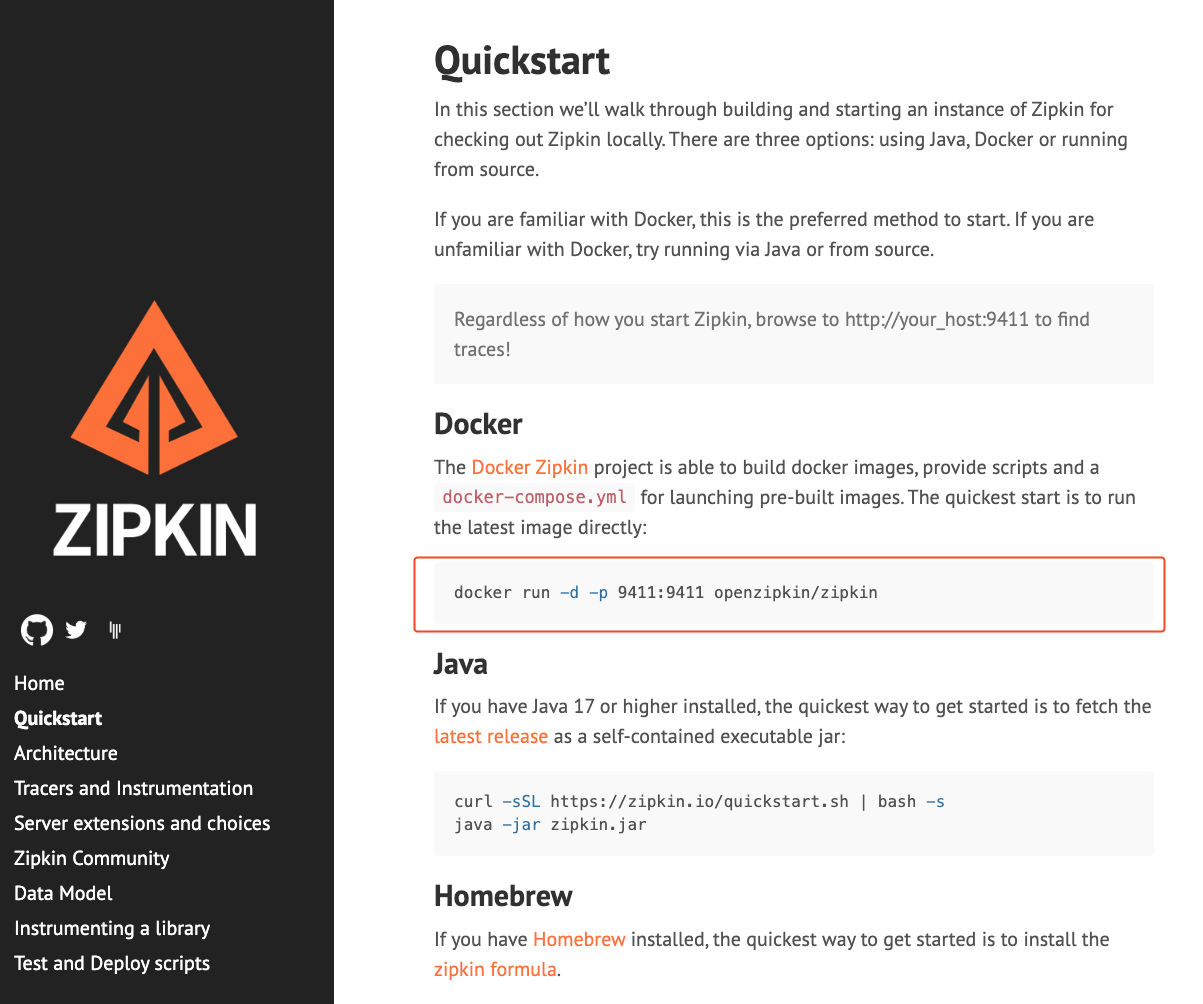
공식 홈페이지에서 알려주는 것과 같이 Docker에서 zipkin 컨테이너를 띄워서 사용할 수 있다.
하지만, 최근 Zipkin은 영구 저장소로 MySQL과 같은 데이터베이스를 사용하도록 변경되었다.
따라서 필자는 MySQL과 함께 Zipkin을 실행하기 위한 docker-compose 파일을 만들어서 사용해볼 예정이다.
💡 Zipkin 대쉬보드 접근
Zipkin 홈페이지에서 제공하는 명령어를 입력하여 도커 컨테이너를 띄운 상태라면, 사진과 같이 대쉬보드에 바로 접근해볼 수 있다.
포트바인딩에 사용된 9411 포트로 접근하면 Zipkin에서 제공하는 UI를 이용하여 요청을 추적할 수 있다.
💡 Docker Compose 파일 작성하기
우선 Docker Compose 파일을 살펴보자
Sample Code
version: '3' services: zipkin: image: openzipkin/zipkin ports: - "9411:9411" environment: - STORAGE_TYPE=mysql - MYSQL_DB=zipkin - MYSQL_USER=zipkin - MYSQL_PASS=zipkin - MYSQL_HOST=mysql mysql: image: mysql:5.7 platform: linux/amd64 volumes: - ./initdb.d:/docker-entrypoint-initdb.d environment: MYSQL_DATABASE: zipkin MYSQL_USER: zipkin MYSQL_PASSWORD: zipkin MYSQL_ROOT_PASSWORD: root ports: - "3308:3306"
이 docker-compose 파일에서는 Zipkin 서버와 MySQL 데이터베이스를 함께 실행한다.
MySQL 컨테이너가 시작될 때 필요한 스키마를 자동으로 생성하기 위해 초기화 스크립트를 볼륨으로 마운트하고 있다.
초기화 스크립트(initdb.d 디렉토리에 저장)는 Zipkin이 필요로 하는 테이블 구조를 생성하는 쿼리가 작성되어있으며, zipkin 스키마에서 제공하는 쿼리를 포함한다.
💡 마이크로서비스에 Zipkin 클라이언트 설정하기
Zipkin을 이용해서 트레이싱을 하고싶은 서비스 설정 파일에서 다음과 같은 설정 정보를 추가하자
Sample Code
management: tracing: sampling: probability: 1.0 # 모든 요청에 대해 트레이싱 활성화 propagation: consume: B3 produce: B3 zipkin: tracing: endpoint: http://localhost:9411/api/v2/spans # Zipkin 서버 주소 endpoints: web: exposure: include: health, httptrace, info, metrics, prometheus # 모니터링 엔드포인트 노출
여기서 눈여겨볼만한 설정은 다음과 같다.
sampling.probability
- 트레이싱할 요청의 비율 (1.0은 모든 요청을 트레이싱)
propagation
- 트레이싱 정보를 전달하는 형식 (B3는 Zipkin의 기본 형식)
zipkin.tracing.endpoint
- Zipkin 서버의 주소
- 여기서는 도커로 띄워놓은 주소를 제공하면 된다.
이렇게 설정이 끝나면 실제로 서비스마다 Slf4j 를 사용하여 log를 찍어놓은 내용이 Zipkin에 등록된다.
별도로 코드를 추가하는 등의 작업은 필요없다.
💡 Micrometer 의존성 추가하기
Spring Boot 3.x부터는 기존에 사용되던 Spring Cloud Sleuth가 Micrometer Tracing으로 통합되었다.
따라서 분산 트레이싱을 구현하기 위해서는 Sleuth가 아닌 Micrometer 관련 의존성을 추가해야 한다.
Gradle을 사용한다면 다음과 같이 의존성을 추가하면 된다
Gradle 의존성 추가
implementation 'org.springframework.boot:spring-boot-starter-actuator' implementation 'io.micrometer:micrometer-tracing-bridge-brave' implementation 'io.zipkin.reporter2:zipkin-reporter-brave'
의존성을 추가한 후에는 로깅 패턴을 적용하여 로그에 Trace ID와 Span ID가 표시되도록 해야 한다.
이를 위해 application.yml 파일에 다음과 같은 설정을 추가한다
Sample Code
logging: pattern: level: '%5p [${spring.application.name:},%X{traceId:-},%X{spanId:-}]'
이 설정은 로그 메시지의 레벨 부분에 애플리케이션 이름, Trace ID, Span ID를 함께 표시해준다.
이렇게 하면 여러 서비스의 로그를 모아서 볼 때도 어떤 요청에 속하는 로그인지 쉽게 파악할 수 있다!
여기서 중요한 것은, 위의 의존성과 로깅 패턴을 모두 적용해야 Trace ID와 Span ID가 정상적으로 생성되고, 이 정보가 Zipkin 대시보드에 올바르게 등록된다는 것이다.
단순히 Zipkin 서버만 실행했다고 해서 데이터가 자동으로 수집되는 것이 아니라, 각 마이크로서비스에서 이러한 설정이 제대로 이루어져야 한다.
또한, 이렇게 로깅 패턴을 등록한다면 Zipkin에서 확인한 ID를 가지고와서 CLI 환경에서도 로그를 직접 찾아볼 수도 있을 것이다.
3. Zipkin으로 분산 트레이싱 확인하기
모든 설정을 마친 후 서비스들을 실행하면, Zipkin UI를 통해 트레이싱 정보를 확인할 수 있다.
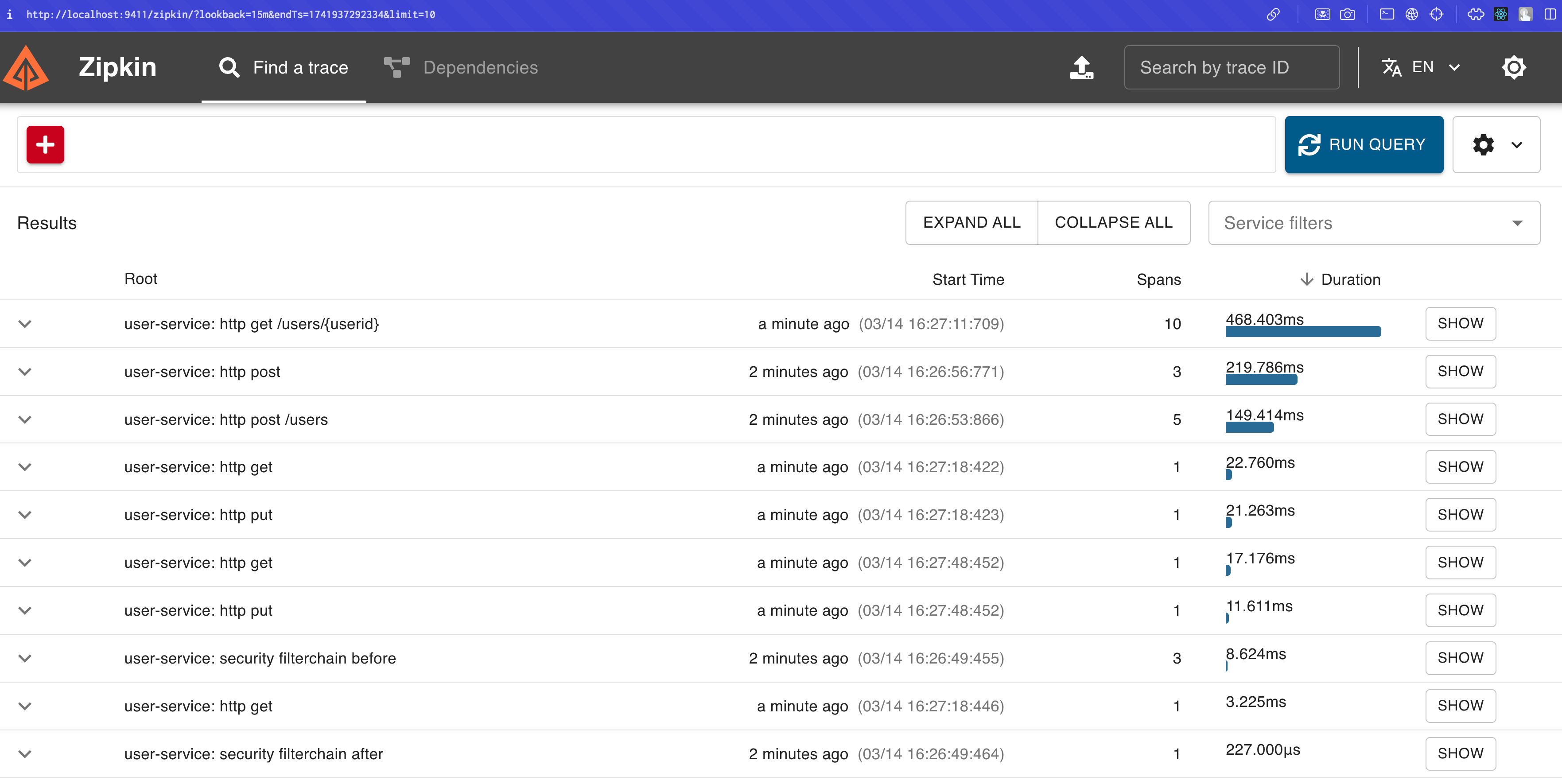
여기서 각 요청을 상세히 확인하고 싶다면, SHOW 버튼을 클릭하면 된다.
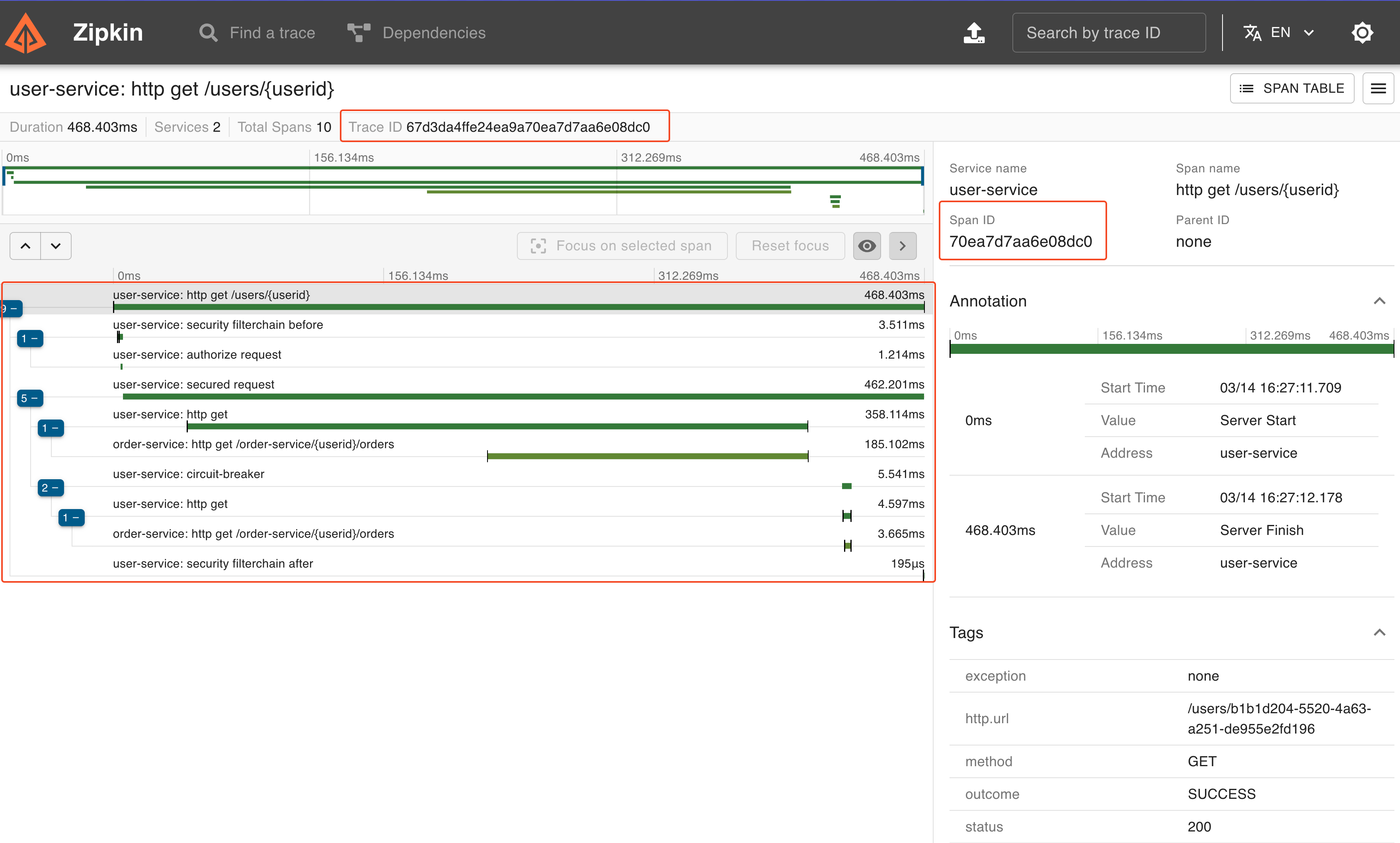
그러면 사진과 같이 Trace ID, Span ID를 모두 확인할 수 있으며, 요청이 어떤 흐름으로 진행되고 있는지도 확인할 수 있다.
OUTRO
이번 포스팅에서는 마이크로서비스 환경에서 분산 트레이싱을 구현하기 위한 Zipkin 사용법에 대해 알아보았다.
분산 트레이싱은 시스템의 동작을 이해하고 최적화하는 데 필수적인 인사이트를 제공한다.
당연히, 호출 시간이 오래 걸리는 API를 발견한다면 해당 API를 리팩토링하여 성능을 개선시켜야한다는 근거로 사용할 수 있을 것이다.
MSA 환경에서는 서비스 간 통신이 많아질수록 이러한 추적 도구의 중요성이 더욱 커진다는 점을 기억하자 👊
