
원래는 지금 진행하고 있는 프로젝트와 관련된 내용을 소개하려고 하다가,
python 마지막(?) 실습인 크롤링(Crawling) 또는 스크래핑(Scraping) 실제 활용했었던? 과제에 대해 소개하려고 합니다.
부족한 실력이었지만 크롤링의 의의를 같이 찾아가셨으면 합니다.
1. 프로젝트 소개
1-1. 주제
머신러닝을 이용한 카페 매출액 영향 요인 및 키워드 분석
1-2 목적
행정동 내 카페 매출액 예측을 통해 카페 매출액에 영향을 미치는 요인을 확인하는 것이 목표다. 인구요인, 지역요인, 상권 속성, 접근성 요인을 기반으로 입지적 특성을 분석하고, 리뷰 키워드 데이터를 통해 카페의 특성을 고려하여 매출액과의 관계를 확인하고 자 한다. 나아가 리뷰 데이터를 통해 키워드를 도출하여 성공적인 카페 창업에 필요한 인사이트를 제공
1-3.주요 기능
1) 카페 매출액 회귀분석 및 SHAP(Shapley Additional exPlanations) 영향 요인 분석
인구 특성, 지역 특성, 접근성, 상권, 키워드를 바탕으로 카페 매출액 회귀분석 및 주요 변수와
영향을 주는 요인 분석
2) BERT 기반 카페 리뷰 텍스트 분석
카페 리뷰 텍스트 데이터를 통한 지역별 리뷰 인사이트 분석
2. 프로젝트 필요성
최근 코로나 거리두기 해제에 따라 크게 위축되었던 창업 및 사업에 대한 관심이 증가하고 있고특히 커피전문점 창업에 대한 관심은 꾸준히 증가하고 있다. 실제로 커피전문점 매장 수는 코로나가 창궐한 기간을 포함한 2019년부터 2021년까지 매년 약 1만개씩 증가하였고 지난해 수입액은 1조로 성장하였다. 국내 커피산업의 매출액은 2016년 기준 약 5.9조 원에 서 2018년 약 6.8조원으로 증가하였다. 통계청의 발표에 따르면 커피 가맹점 수가 최근 급증하면서 치킨 가맹점(2만9300개) 수를 넘어섰다.
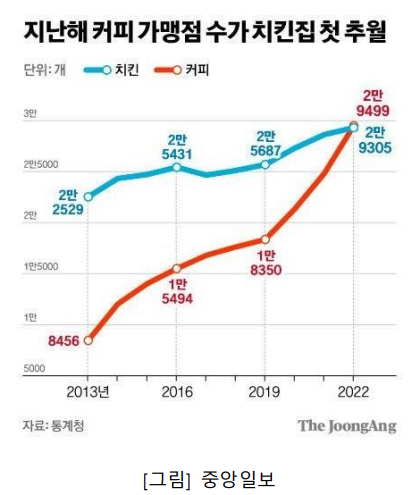
이처럼 꾸준한 커피 소비로부터 커피 전문점은 성장세를 보였고 시장의 규모가 크게 성장했지만, 고급 커피전문점을 내세운 국내외 대기업 커피전문점의 진입과 다양한 개인 커피전문 점의 등장으로 인해 국내 커피전문점 시장의 경쟁이 더욱 치열해지고 있다. 2022년 서울시에서 폐업한 카페는 2187곳으로 전년 1970곳보다 많은 역대 최고치를 기록했다. 이처럼 커 피 전문점 시장에서의 경쟁이 치열해짐에 따라 지역에 대한 정보와 창업하려는 업종의 특징을 통해 유리한 입지 선점에 대한 분석은 필수적이다.
본 프로젝트에서는 행정동 내 카페 매출액 예측을 통해 카페 매출액에 영향을 미치는 요인 확인하는 것이 목표다. 인구요인, 지역요인, 상권 속성, 접근성 요인을 기반으로 입지적 특성을 분석하고, 리뷰 키워드 데이터를 통해 카페의 특성을 고려하여 매출액과의 관계를 확인하고자 한다.
3. 프로젝트 수행 내용
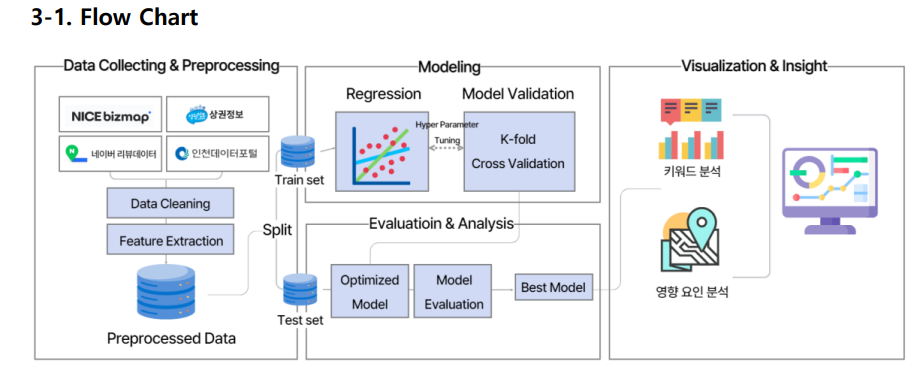
본 프로젝트는 정량데이터와 네이버 지도 크롤링을 통해 추출한 키워드 데이터를 바탕으로 통합 및 전처리를 진행한다. 이후, 데이터셋을 train 과 test 셋으로 나누어 머신러닝 회귀 알고리즘을 통해 학습을 진행한다. 하이퍼파라미터 튜닝과 K-폴드 교차 검증을 사용하여 모델의 일반화 성능을 평가하고, 최적의 모델을 바탕으로 성능을 평가 및 비교하여 가장 효과적인 모델을 선정한다. 선정된 모델을 바탕으로 모델의 결정에 중요한 역할을 하는 특성들을 식별하여 카페 매출액 영향 요인을 분석한다. 나아가 리뷰 텍스트 분석을 통해 카페 창업에 필요한 인사이트를 제공한다.
- 알려드리고자 하는 부분은 크롤링이다 보니 크롤링 위주로 설명하겠습니다.
크롤링 데이터 수집
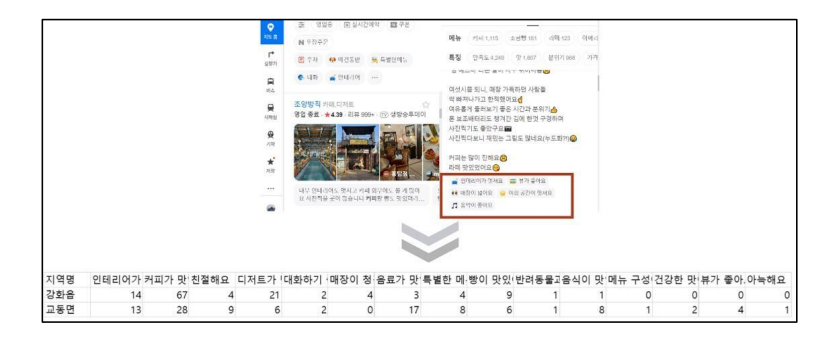
데이터 자료수집은 크롤링을 통해 진행하였다. Nice bizemap과 네이버맵에서 진행한 크롤링으로 분류할 수 있는데 인천 행정동 별 카페를 검색했을 때 나오는 상위 12개 카페들의 각 리뷰에 담겨있는 키워드 100개씩을 수집하였고, Nice bizemap 에서는 행정동 별 지역특성, 근접 점포 개수, 근접 점포 비율, 지역 점포 규모, 지역 매출, 중요 고객층, 지역 영업이익 7개의 변수를 수집하였다.
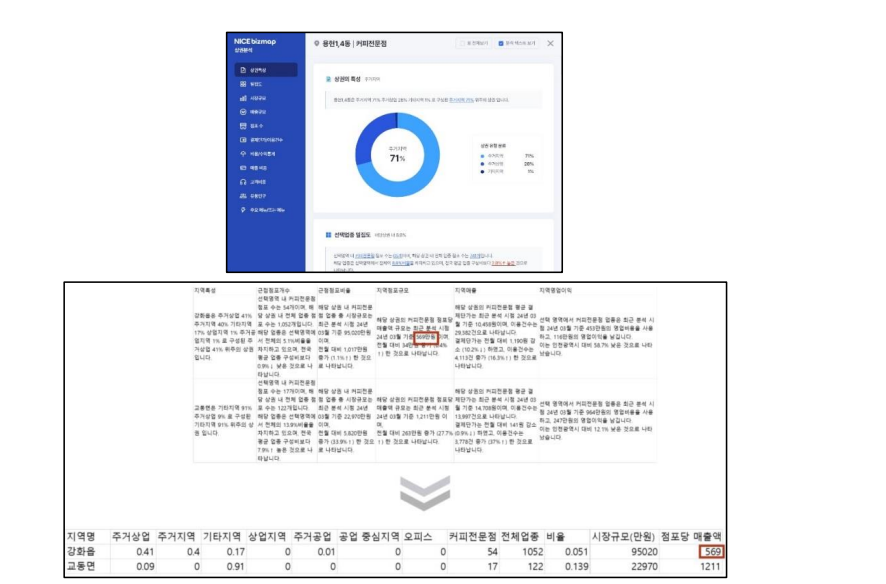
사이트에 줄글로 되어있는 보고서 내용을 크롤링을 통해 수집하고 이를 다시 가공해서 활용할 수 있는 데이터 프레임으로 변형시켰다.
II. 기초 통계량 분석 및 EDA
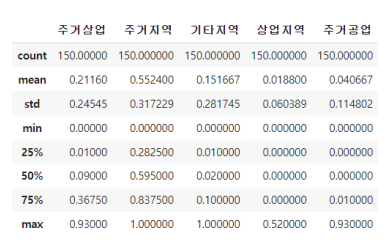
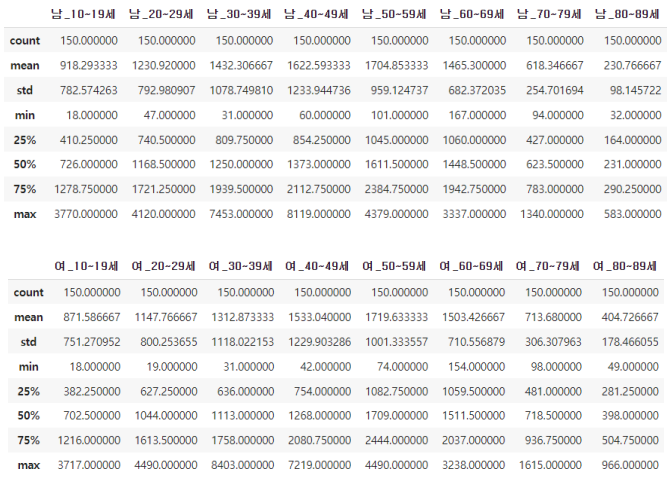
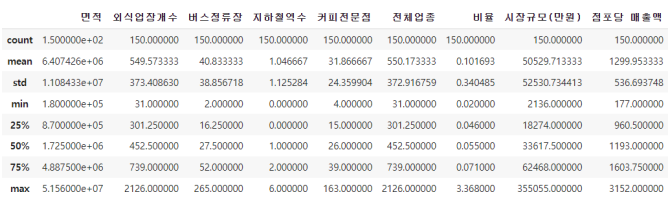
① 정량 데이터 기초 통계량
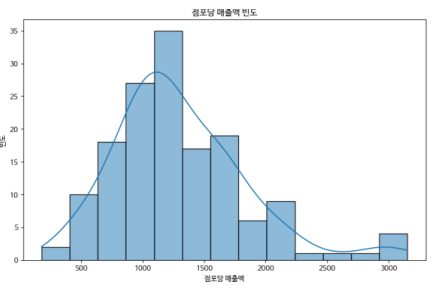
정량 데이터에 대한 기초 통계량은 아래와 같으며, 점포당 매출액은 최소 177 만원, 평균
1300 만원, 최대 3152 만원으로 다음과 같은 분포를 나타낸다.
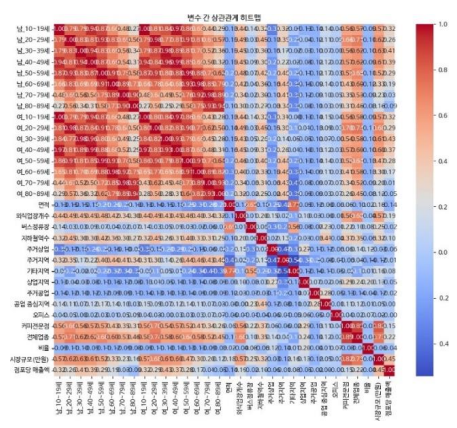
② 정량 데이터 상관분석
정량 데이터에 대한 상관관계 분석을 진행한 결과 시장규모(0.451962), 30대 여성(0.431944),
30대 남성(0.414114), 40대 남성(0.393940), 40대 여성(0.372121) 순서로 높게 나타났다.
그러나 이외 변수들에 대해서는 매출액과의 관계가 없는 것으로 나타났다.
III. Feature Extraction
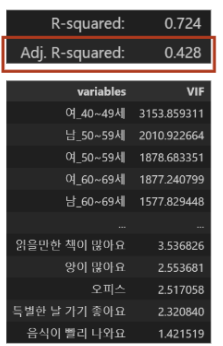
독립변수 77개를 가지고 OLS 선형 회귀 분석 결과 조정된 R-squared 값이 낮아 모델에
불필요한 변수가 포함되었을 가능성이 높다는 것을 확인했다. 또한, VIF 분석 결과 높은
다중공선성을 보이는 변수들이 존재했다.
① 인구 요인
인구 요인 분석 결과, 변수들의 P-value 값이 높고 같은 나이대의 남녀 변수들 간 상관계수가 높은 것을 확인했다.
이 때 선형 회귀분석 진행하는데 있어 python 툴을 다루는 것이 미숙하여 팀원들의 도움을 많이 받았다..;;
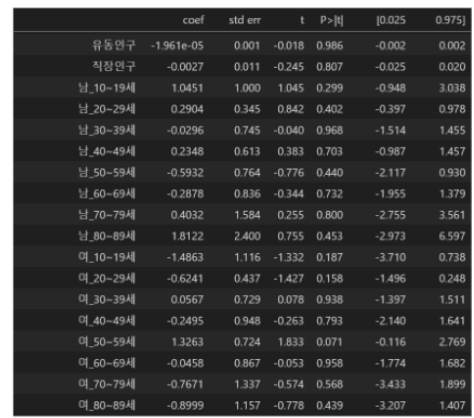
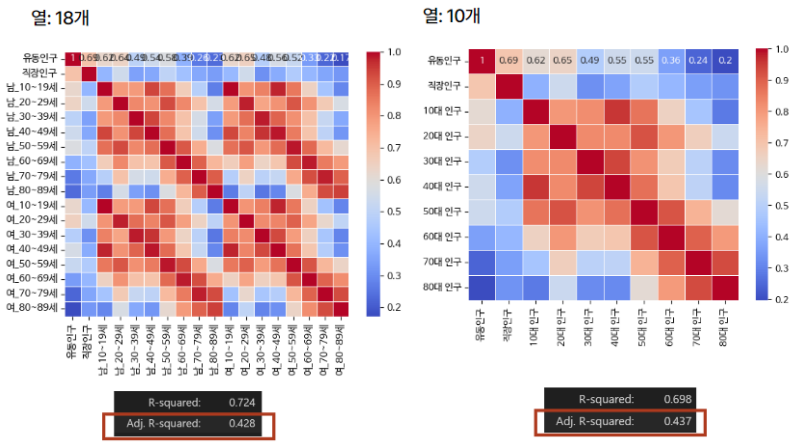
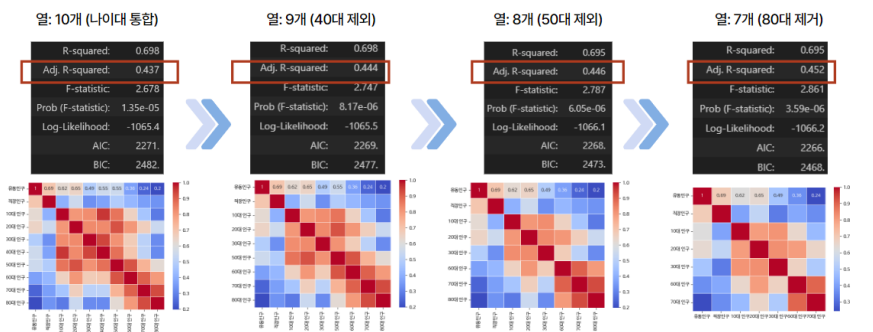
그 이후, 40대, 50대, 80대 변수를 차례대로 제외하면서 조정된 R-squared 값을 0.437, 0.444, 0.446, 0.452 순서대로 높이고, 변수 간 상관계수를 줄였다. 최종적으로 추출된 인구 요인 변수는 유동인구, 직장인구, 10대인구, 20대인구, 30대인구, 60대인구, 70대인구였다.
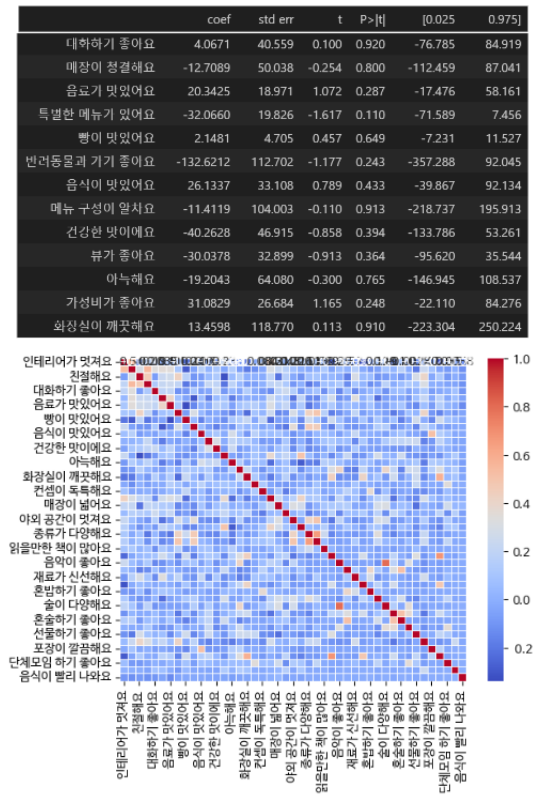
② 키워드 요인
키워드 요인 분석 결과, 변수들의 P-value가 높고, 키워드가 너무 구체적이고 다양하다는 피드백을 반영하여 카페 특성을 나타낼 수 있는 포괄적인 키워드 6개(서비스, 외구 공간, 내부 공간, 가격, 메뉴, 맛)로 통합 및 분류했다.
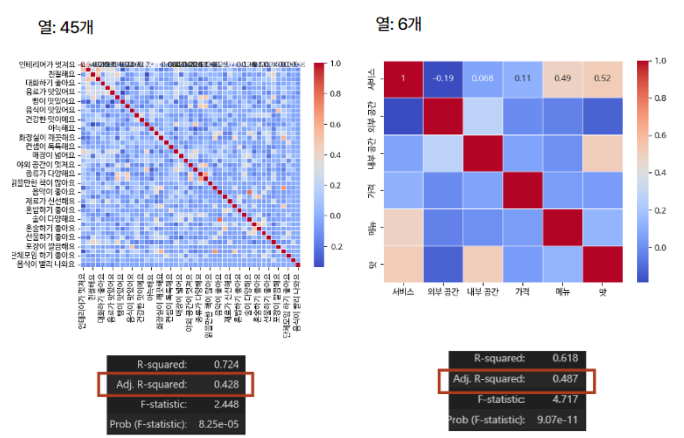
크롤링이 이런 데이터 분석에 활용된다는 것을 간접적으로나마 전달해보고 싶어 이번 글을 작성하였습니다. 많은 도움이 되었으면 좋겠습니다.
