Index란?
데이터베이스 분야에 있어서 테이블에 대한 검색의 속도를 높여주는 자료 구조이다. Index는 색인이고 메모리 영역의 일종의 목차를 생성하는 개념이다. 책에서 원하는 항목을 찾기 위해서는 첫 페이지에서부터 찾는 것보다 색인(목차)를 통해 검색 범위를 줄이는 것이 훨씬 효과적이다. DB 인덱싱은 데이터의 양이 많고 컬럼의 값이 다양할 경우 더 큰 효과를 볼 수 있다.
DB 인덱스의 종류
인덱스의 종류에는 여러가지가 있다.
- B(Balanced)-tree Index
- Bitmap Index
- IOT Index
- Clustered Index
여기서 흔히 사용하는 인덱스는 B-tree 인덱스라고 한다.
장점 & 프로세스
일반 DB와 Indexed DB의 차이점은 레코드를 조회(select)할때 발생한다.
먼저 일반 DB에서 특정 조건에 해당되는 데이터를 검색하는 방식은 full scan 방식이다. Full scan 방식이란 말 그대로, DB 테이블에 포함된 데이터를 id 순으로 처음부터 끝까지 체크하여 원하는 데이터를 추출하는 것을 의미한다. 이런 방식은 데이터의 수가 방대할 경우 비효율적인 방식이라고 할 수 있다.
이 때 데이터베이스에 인덱싱을 통해 조금 더 최적화된 스캔 방식을 적용할 수 있다. 먼저 인덱스 테이블을 생성한다. 인덱싱할 컬럼을 key값으로, 그리고 접근할 데이터의 primary key id를 value로 지정해준다. 이때 추가된 인덱스 테이블은 인덱스 컬럼 기준으로 정렬(sorting)이 되어 저장된다. 따라서 특정 조건의 데이터들을 검색을 할때 시작점을 지정해, 그 지점부터 데이터에 대한 조회가 가능해 좀 더 빠른 스캔이 가능하다.
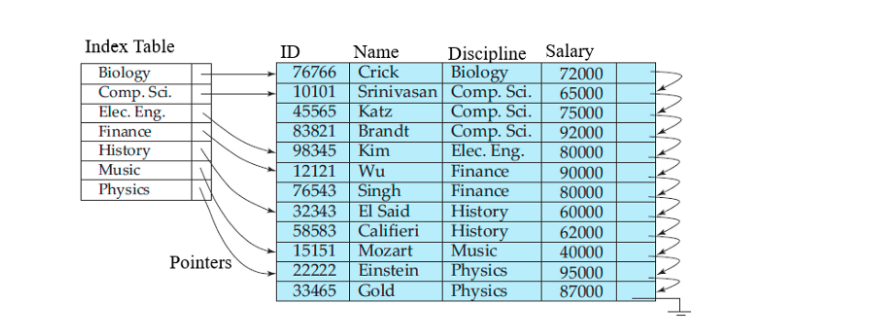
위와 같은 그림식으로 인덱스 테이블은 본 테이블과 매핑이되어 있기 때문에 먼저 인덱스에서 조건에 맞는 데이터를 찾은 다음에 본 테이블에서 나머지 데이터를 가지고 오는 방식을 사용한다. 보통 인덱스에 사용되는 컬럼은 조건검색(where)에 자주 등장하는 컬럼이다.
인덱스 테이블을 생성하는 방법은 다음과 같다 (MySQL)
1. 기존 테이블에 인덱스 추가
ALTER TABLE table_name ADD INDEX(keyword(20))2. 테이블 생성과 동시에 인덱스 추가
CREATE TABLE table_name (
keyword varchar(20),
INDEX(keyword(20))
)
ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;단점
하지만 DB 인덱싱은 새로운 테이블을 생성하기 때문에 별도의 저장공간이 발생하고, 인덱스 테이블은 기본적으로 sorting이 된 상태기 때문에 새로운 데이터를 삽입하거나 수정할때 오히려 더 성능이 안좋아진다.
DB 인덱스 손익 분기점이 있다. 인덱스를 생성하려는 컬럼의 분포도가 10~15% 이하이면 인덱스를 타는게 효율적이라고 한다.
