educative - kotlin - 11
External vs. Internal Iterators
External Iterator (외부 반복자)
외부 반복자는 배열에서 요소를 for나 while 등의 루프로 하나씩 꺼내서 직접 조작하는 방식이다
val numbers = listOf(10, 12, 15, 17, 18, 19)
for (i in numbers) {
if (i % 2 == 0) {
print("$i, ") //10, 12, 18,
}
}추가적으로 break나 continue문을 활용해 직접 루프를 쉽게 제어할 수 있다.
Internal Iterator (내부 반복자)
내부 반복자는 반복당 수행할 액션만을 정의하고 그 액션을 컬렉션이 받아 내부적으로 자동 처리하는 방식이다.
numbers.filter { e -> e % 2 == 0 }
.forEach { e -> print("$e, ") } //10, 12, 18,여기서 filter() 함수는 리스트를 돌면서 인자로 들어온 람다 표현식의 조건에 대한 return 값이 true인 요소들만 필터링 한다.
필터링된 요소는forEach() 함수를 통해 컬렉션 타입의 개수만큼 람다식으로 들어온 구문을 반복 실행한다.
Which is Better?
예시를 확인해보자. 짝수로된 숫자의 제곱을 담는 리스트를 가져오려고 한다. 외부 반복자를 이용하면 다음과 같이 코드를 작성할 수 있다.
val doubled = mutableListOf<Int>()
for (i in numbers) {
if (i % 2 == 0) {
doubled.add(i * 2)
}
}
println(doubled) //[20, 24, 36]흔히 보는 익숙한 방식이다. 나쁘지 않다. 하지만 빈 리스트를 코드 시작부분에서 생성해야 하는 부분이 살짝 거슬린다. 내부 반복자를 활용해보자.
val doubledEven = numbers.filter { e -> e % 2 == 0 }
.map { e -> e * 2 }
println(doubledEven) //[20, 24, 36]낯설지만 확실히 간결하다. 어떤 iteration 방식을 사용할지는 본인 취향이다. 외부 반복자를 사용하고 내부 반복자도 사용해보고 둘 중 하나가 더 좋으면 리팩토링하면 된다.
Internal Iterators
대표적인 internal iterator를 정리해보자.
- filter() : 람다의 조건식이 True가 되는 요소들을 리스트로 만들어준다.
- map(): 람다를 통해 리스트 내부 요소들의 형태를 바꾼다.
- reduce(): 전체 리스트를 누적 연산을 통해 하나의 데이터로 모아준다.
간단하게 Person 클래스로 이루어진 People 컬렉션을 가지고 예시를 들어보자
data class Person(val firstName: String, val age: Int)
val people = listOf(
Person("Sara", 12),
Person("Jill", 51),
Person("Paula", 23),
Person("Paul", 25),
Person("Mani", 12),
Person("Jack", 70),
Person("Sue", 10))앞서 정리했던 3개의 internal iterator를 사용해 20세 이상의 대문자 이름을 구하는 코드를 작성해보자
val result = people.filter { person -> person.age > 20 }
.map { person -> person.firstName }
.map { name -> name.toUpperCase() }
.reduce { names, name -> "$names, $name" }
println(result) //JILL, PAULA, PAUL, JACK위 코드의 연산 과정은 다음 그림과 같다
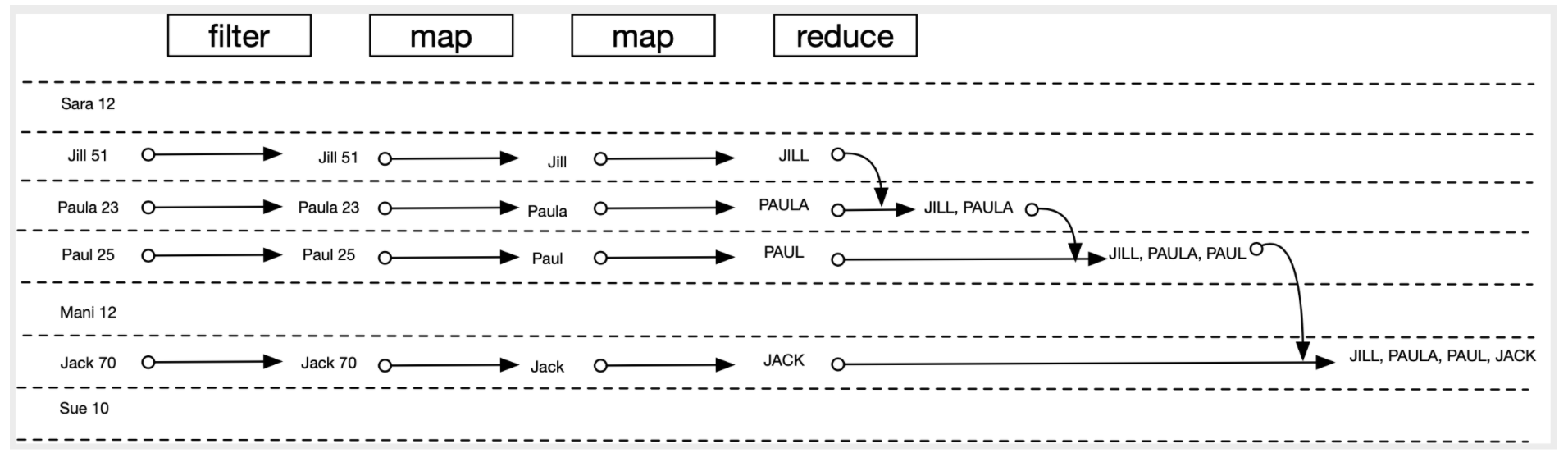
reduce() 대신 joinToString(",") 으로 대체 가능하다. 더 직관적이고 error prone하다.
Getting the first and the last
장고의 ORM과 비슷하게 first() 와 last()를 활용하면 리스트의 첫번째, 마지막 요소를 가져올 수 있다.
val nameOfFirstAdult = people.filter { person -> person.age > 17 }
.map { person -> person.firstName }
.first()
println(nameOfFirstAdult) //Jillflatten and flatMap
flatten()은 해당 리스트를 하나의 list로 펼치는 기능을 하고 flatMap()은 주어진 람다로 Map을 만들고 이를 다시 flat한 리스트로 만들어주는 함수이다.
val families = listOf(
listOf(Person("Jack", 40), Person("Jill", 40)),
listOf(Person("Eve", 18), Person("Adam", 18)))
println(families.size) //2
println(families.flatten().size) //4
val namesAndReversed3 = people.map { person -> person.firstName }
.map(String::toLowerCase)
.flatMap { name -> listOf(name, name.reversed())}
println(namesAndReversed3.size) //14size 프로퍼티는 리스트의 길이를 반환한다. flatten(), flatMap() 함수를 사용하기 전후의 값 차이를 확인해보자.
Sorting
sortedBy(), sortedByDescending()를 사용하면 원본 리스트를 바꾸지 않고 주어진 람다를 기준으로 정렬된 리스트를 반환한다.
val namesSortedByAge = people.filter { person -> person.age > 17 }
.sortedBy { person -> person.age }
.map { person -> person.firstName }
// .sortedByDescending { person -> person.age }
//[Jack, Jill, Paul, Paula]
println(namesSortedByAge) //[[Paula, Paul, Jill, Jack]Grouping objects
groupBy() 함수를 사용해 group by 연산을 할 수 있다.
val groupBy1stLetter = people.groupBy { person -> person.firstName.first() }
println(groupBy1stLetter)
//{S=[Person(firstName=Sara, age=12), Person(firstName=Sue, age=10)], J=[...
val namesBy1stLetter =
people.groupBy({ person -> person.firstName.first() }) {
person -> person.firstName
}
println(namesBy1stLetter)
//{S=[Sara, Sue], J=[Jill, Jack], P=[Paula, Paul], M=[Mani]}Sequences for Lazy Evaluation
Kotlin standard library는 컬렉션과 함께 또 다른 컨테이너 타입인 sequence (Sequence<T>) 를 가지고 있다. Sequence는 컬렉션을 감싸고 있는 일종의 Wrapper이다. Collection과 비교해서 lazy하다는 특성을 가지고 있다.
컬렉션에서 map()이나 filter()를 사용하는 경우 퍼포먼스 측면해서 생각해야 할 점이 있다. 위 함수를 거칠 때 마다 매번 list가 연산되어 return 되므로 컬렉션의 길이가 길면 프로세스에 부하가 걸리게 된다. 하지만 Sequence의 경우 최종 메소드가 실행될때 연산 전체가 수행되므로 부하가 상대적으로 덜 하다.
따라서 컬렉션에 길이에 따라 internal iterator 혹은 sequence를 사용할지 정해야 한다. 당연히 컬렉션의 길이가 크면 lazy한 sequence를 사용하는게 좋다.
fun isAdult(person: Person): Boolean {
println("isAdult called for ${person.firstName}")
return person.age > 17
}
fun fetchFirstName(person: Person): String {
println("fetchFirstName called for ${person.firstName}")
return person.firstName
}
val nameOfFirstAdult = people
.filter(::isAdult)
.map(::fetchFirstName)
.first()
println(nameOfFirstAdult)위 코드에서도 마찬가지로 filter(), map() 을 사용하는 두 함수는 iteration을 돌면서 내부적으로 새로운 리스트를 계속 생성한다. 결국 얻고자 하는건 리스트의 첫번째 요소이므로 실행결과는 확인해보면 리소스 낭비가 심하다는 것을 알 수 있다.
실행결과
isAdult called for Sara
isAdult called for Jill
isAdult called for Paula
isAdult called for Paul
isAdult called for Mani
isAdult called for Jack
isAdult called for Sue
fetchFirstName called for Jill
fetchFirstName called for Paula
fetchFirstName called for Paul
fetchFirstName called for Jack
Jill이런 부하는 컬렉션의 사이즈가 클수록 더 커진다. sequence를 사용해 연산의 부담을 줄여줄 수 있다.
val nameOfFirstAdult = people.asSequence()
.filter(::isAdult)
.map(::fetchFirstName)
.first()
println(nameOfFirstAdult)실행결과
isAdult called for Sara
isAdult called for Jill
fetchFirstName called for Jill
JillInfinite Sequences
generateSequence(seed: T>, nextFunction: () -> T?)를 사용해 무한 Sequence를 생성할 수 있다. 첫번째 인자인 seed에 받아진 값을 첫 요소로 생성하고, 두 번째 인자인 nextFunction을 통해 함수를 통과한 요소를 무한히 생성할 수 있다.
tailrec fun nextPrime(n: Long): Long =
if (isPrime(n + 1)) n + 1 else nextPrime(n + 1)
val primes = generateSequence(5, ::nextPrime)tailrec은 tail recursive라는 의미로 추가적인 연산이 없이 자신 스스로 재귀적으로 호출하다가 어떤 값을 리턴하는 함수를 의미한다. StackOverflowError를 방지해준다.
위 예제를 보면 벌써 무한대의 컬렉션이 이미 생성된거 같지만 사실 직접적인 값을 호출하기 전까지는 아무 컬렉션도 생성되지 않는다. 이제 직접 호출해보자
System.out.println(primes.take(6).toList()) //[5, 7, 11, 13, 17, 19]take() 메소드를 사용하면 인자로 주어진 길이의 리스트만 생성해준다. 이 때 실제로 generateSequence의 연산이 실행되는 것이다.
다음과 같이도 사용할 수 있다.
val primes = sequence {
var i: Long = 0
while (true) {
i++
if (isPrime(i)) {
yield(i)
}
}
}
//drop()을 사용해 처음 두번째까지의 요소를 삭제
println(primes.drop(2).take(6).toList()) //[5, 7, 11, 13, 17, 19]