💚 서론
공부하는 과정에서 한 글을 읽고 웹 성능을 개선해야겠다는 생각을 하게 되었다.
요약하자면, 사용자가 늘어나 서버에 부하가 발생했을 때, 서버에 문제가 없는지 확인하고, 해결해 사용자에게 쾌적한 서비스 환경을 제공할 수 있어야 한다.
💚 개선 코드 찾기
문제 상황 : 5명의 사용자가 게시물 1개에 각각 댓글을 작성한 경우 게시글의 댓글을 조회하는 경우 n + 1의 문제가 발생한다.
- findAllByPostIdToSeqIsZero()
- getMember()
- getPost()
- getMember()
- getMember()
- getMember()
- getMember()
"content": [
{
"commentId": 1,
"memberId": 1,
"username": "11",
"postId": 1
..(생략)
},
{
"commentId": 2,
"memberId": 2,
"username": "22",
"postId": 1,
},
{
"commentId": 3,
"memberId": 3,
"username": "33",
"postId": 1,
},
{
"commentId": 4,
"memberId": 5,
"username": "44",
"postId": 1,
},
{
"commentId": 5,
"memberId": 6,
"username": "55",
"postId": 1,
}
],
위와 같은 경우에 만약에 1000명의 사용자가 하나의 게시글에 댓글을 작성한 경우
쿼리문은 1000 + 1000 + 1로 총 2001번의 쿼리문이 발생할 것이다.
이는 성능에 큰 영향을 주기 때문에 리팩토링 해보자.
🪄 N + 1 문제란?
연관 관계가 설정된 엔티티를 조회할 경우에 조회된 데이터의 갯수(N)만큼 연관관계의 조회 쿼리가 추가로 발생하는 형상을 말한다.
즉, 게시글 댓글을 작성한 사용자의 수만큼 조회 쿼리가 추가로 발생한다.
Q : JPA Fetch Lazy전략을 통해서 해결 가능하지 않을까?
A : 놉! 지연로딩과 즉시 로딩에서 모두 발생할 수 있다.
[ EAGER(즉시 로딩)의 경우 ]
- JPQL에서 만든 SQL을 통해 데이터를 조회한다.
- 이후 JPA에서 Fetch전략을 가지고 해당 데이터의 연관 관계인 하위 엔티티들을 추가 조회한다.
- 2번 과정으로 N + 1문제가 발생한다.
[ LAZY(지연 로딩)의 경우 ]
- JPQL에서 만든 SQL을 통해 데이터를 조회한다.
- 이후 JPA에서 Fetch전략이 LAZY이기 때문에 추가 조회를 하지 않음
- 하지만, 하위 엔티티를 가지고 작업을 하게되면 추가 조회가 발생하기 때문에 결국 N + 1문제가 발생한다.
🪄 해결 방안
N + 1 문제를 해결하는 방식에는 Fetch Join, EntityGraph 어노테이션, Batch Size 등의 방법이 있다.
나는 Fetch Join방식으로 해결하였기 때문에 나머지 방식은 간단하게만 알고 넘어가자
1. Fetch Join
N + 1문제가 발생하는 이유가 한쪽 테이블만 조회하고 연결된 다른 테이블은 따로 조회하기 때문에 발생하는 문제이기 때문에
JPQL을 사용하여 DB에서 데이터를 가져올 때 처음부터 연관된 데이터까지 같이 가져오는 방법이다.
Join을 통해 한 번에 값을 가져오면 N + 1문제는 발생하지 않는다.
@Query("SELECT c FROM Comment c JOIN fetch c.member WHERE c.post.id=:postId AND c.seq=0")
List<Comment> findAllByPostIdToSeqIsZero(@Param("postId") Long postId);Fetch Join은 SQL의 Join문과 거의 동일하지만 Fetch Join은 JPQL의 성능 처리를 위해 JPQL에만 있는 쿼리이다.
연관관계를 조회할 때 Fetch Join을 사용하게 된다면 지연로딩이 걸려있는 연관관계도 즉시로딩처럼 한번에 조회하기 때문에 연관관계가 프록시 객체가 아닌 실제 엔티티를 참조한다.
이 말은 즉, 우리가 연관관계에서 설정해놓은 FetchType.LAZY를 사용할 수 없다는 단점이 존재한다.
[ 단점 ]
- 쿼리 한번에 모든 데이터를 가져오기 때문에 JPA가 제공하는 Paging API 사용 불가능(Pageable 사용 불가)
- 1:N 관계가 두 개 이상인 경우 사용 불가
- 패치 조인 대상에게 별칭(as) 부여 불가능
- 번거롭게 쿼리문을 작성해야 함
[ Fetch Join & EntityGraph 주의점 ]
Fetch Join과 EntityGraph는 JPQL을 사용하여 Join문을 호출한다는 공통점이 있다.
또한 공통적으로 카테시안의 곱이 발생하여 댓글의 수만큼 사용자의 중복 데이터가 존재할 수 있다.(지금은 해당 X)
그러므로 중복된 데이터가 컬렉션에 존재하지 않도록 주의해야 한다.
🌟 카테시안 곱
두 테이블 사이에 유효 join 조건을 적지 않았을 때 해당 테이블에 대한 모든 데이터를 전부 결합하여 테이블에 존재하는 행 갯수를 곱한만큼의 결과 값이 반환되는 것
→ N개의 행을 가진 테이블과 M개의 행을 가진 테이블이 Join된 경우, N*M개의 결과 값이 산출
중복 발생 문제 해결 방법
- JPQL을 사용하기 때문에 distinct를 사용하여 중복된 데이터를 조회하지 않을 수 있다.
- 컬렉션을 Set을 사용하게 되면 중복을 허용하지 않는 자료구조이기 때문에 중복된 데이터를 제거할 수 있다.
2. EntitiyGraph
EntityGraph는 @EntityGraph어노테이션을 이용해서 attributePaths에 fetch join을 사용해줄 연관관계 멤버 변수를 설정하고 type을 EntityGraph.EntityGraphType.FETCH를 설정해주면 직접 작성한 Fetch Join과 동일하게 작동되어 N+1을 해결한다.
EntityGraph를 사용시 outer join을 사용한다.
3. Batch Size
batch Size는 IN 쿼리를 통해서 한번에 가져와 해결하는 방식이다.
application.yml 파일에 IN절에 한번에 들어가는 크기(batch size)를 설정한다.
spring:
jpa:
properties:
hibernate:
default_batch_fetch_size: 1000Q : BatchSize로 모든 문제를 해결이 가능하니까 Fetch Join은 사용하지 않아도 되는가?
A :
BatchSize는 N+1문제를 최대한 IN쿼리로 기본적인 성능을 보장해주는 것이다.
즉, 최소한의 성능을 보장해주는 것이므로 최선이 아닌 것이다.
@OneToOne, @ManyToOne과 같은 ToOne관계의 연관관계에 대해서는 모두 Fetch Join을 걸어 한방 쿼리를 수행한다
@OneToMany, @ManyToMany와 같이 ToMany관계의 연관관계에 대해서는 데이터가 가장 많은 쪽에 Fetch Join을 사용한다.
💚 성능 테스트 해보기
- 상품 1번의 댓글들 조회
- GET api/v1/posts/1/comments
- Fetch Join 적용 전
- Vuser(가상 사용자) : 10
- Duration : 1분
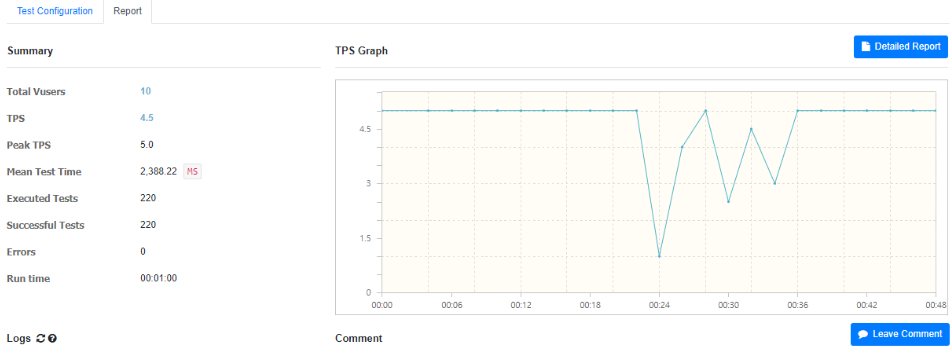
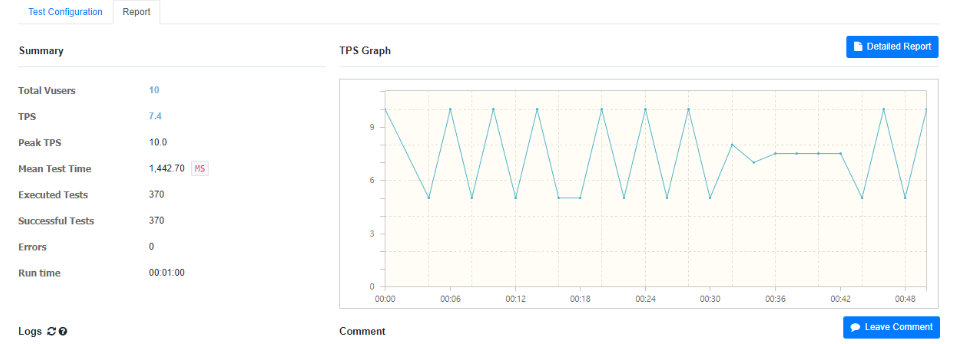
- Fetch Join 적용 후
- Vuser(가상 사용자) : 10
- Duration : 1분
- 수치 변화
- 평균 TPS : { 4.5 } → { 7.4 } (약 65% 개선)
- Peek TPS : { 5 } → { 10 }
- Mean Test Time : { 2,388 } ms → { 1,442 }ms
- Exected Tests : { 220 } → { 370 }
