💚 서론
최근 인덱스를 공부하면서 어떨 때 인덱스를 사용해야 하는가에 대한 나만의 기준을 세우기 위해 노력했다.
간단하게 정리하자면 인덱스가 되는 컬럼의 기준은
1. Where절 또는 join절에서 잦은 사용
2. 낮은 수정 빈도
3. 데이터의 중복(카디널리티 수치)이 적은
정도이다.
어느 정도 기준을 세웠으니 코드에 적용해보자.
🧠 개선 코드 찾기
테이블에 인덱스를 설정한다는 것은 그만큼의 리소스를 활용하기 때문에 200% 잘 활용해야 한다.
당근 마켓 프로젝트에서 사용자들은 특정 게시물을 조회하는 기능을 가장 많이 사용할 것이고, 가장 중요한 API라고 생각하였다. 해당 코드를 가장 생각하며 튜닝해야 한다고 생각하였다.
성능에 비교를 위해 1개의 게시물 내에 100개의 댓글 내에 100개의 대댓글 총 10000개의 데이터를 넣어주었다.
🏃 프로시저를 통해 대량의 데이터 세팅하기
SQL을 생성해주는 사이트들이 많지만 프로시저를 통해서 데이터를 등록하였다.
# reply insert 프로시저 DELIMITER $$ DROP PROCEDURE IF EXISTS insertLoop$$ CREATE PROCEDURE insertLoop() BEGIN DECLARE i INT DEFAULT 1; DECLARE j INT; WHILE i <= 100 DO SET j = 1; WHILE j <=100 DO INSERT INTO devcourse.comments(content, status, member_id, post_id, comment_group, seq, created_at, updated_at) VALUES (concat('Reply',j), 'ALIVE',FLOOR(RAND() * 10) + 1, 1, i, j, CURRENT_TIMESTAMP, CURRENT_TIMESTAMP); SET j = j + 1; END WHILE; SET i = i + 1; END WHILE; END$$ DELIMITER $$ CALL insertLoop; $$
본격적으로 쿼리를 분석해보자
1. 인덱스 컬럼 찾기
SELECT * FROM comments c WHERE c.post_id=1 AND c.seq=0
SELECT * FROM comments c WHERE c.comment_group= 1 AND c.seq > 0 ORDER BY c.seq ASC;프로젝트에서 게시물을 조회할 경우 두 개의 쿼리문이 발생한다.
SELECT
CONCAT(ROUND(COUNT(DISTINCT id) / COUNT(*) * 100, 2), '%') AS id_cardinality,
CONCAT(ROUND(COUNT(DISTINCT content) / COUNT(*) * 100, 2), '%') AS content_cardinality,
CONCAT(ROUND(COUNT(DISTINCT status) / COUNT(*) * 100, 2), '%') AS status_cardinality,
CONCAT(ROUND(COUNT(DISTINCT member_id) / COUNT(*) * 100, 2), '%') AS member_id_cardinality,
CONCAT(ROUND(COUNT(DISTINCT post_id) / COUNT(*) * 100, 2), '%') AS post_id_cardinality,
CONCAT(ROUND(COUNT(DISTINCT comment_group) / COUNT(*) * 100, 2), '%') AS comment_group_cardinality,
CONCAT(ROUND(COUNT(DISTINCT seq) / COUNT(*) * 100, 2), '%') AS seq_cardinality
FROM comments; # 카디널리티 수치 확인하기카디널리티 수치를 확인해보면 comment_group이 더 높다는 것을 알 수 있다.

comment_group을 인덱스로 잡아서 성능을 개선해보자
2. 쿼리 실행계획으로 쿼리 정보 확인하기
CREATE INDEX idx_comment_commentGroup ON comments ( comment_group );
EXPLAIN
SELECT * FROM comments c WHERE c.comment_group= 1 AND c.seq > 0 ORDER BY c.seq ASC;
- id: 각 쿼리 블록 또는 서브쿼리에 대해 부여된 고유한 식별자. 여러 서브쿼리가 있는 경우 계층적으로 표현된다.
- select_type: 쿼리의 유형을 의미한다. "SIMPLE"은 단순한 SELECT 쿼리를 나타낸다.
- table: 쿼리가 참조하는 테이블의 이름.
- type: 테이블에서 레코드를 읽는 방법을 나타낸다.
- ref: 조인 할 때 JOIN 순서에 상관없이 사용, 데이터 접근 범위가 2개 이상 또는 WHERE 절의 비교 연산자가 있을 경우
- range: 테이블 내 연속적인 범위 내에서 인덱스를 사용하여 원하는 데이터를 추출하는 경우
- const: SELECT에서 PK 혹은 Unique Key를 조회하는 경우로 한 건의 데이터 조회한 경우
- possible_keys: 쿼리에서 사용될 수 있는 인덱스 목록.
- key: 실제로 선택된 인덱스.
- key_len: 실제로 사용할 인덱스의 길이
- ref: 엑세스 조건에 사용된 컬럼
- rows: 쿼리 실행시 조사하는 행
- Extra: 추가 정보
3. 쿼리 성능 확인하기
MySQL의 Profiling을 통해서 쿼리의 수행시간을 확인할 수 있다.
사전 설정
show index from comments; # 인덱스 확인 show variables like '%profiling%'; #프로파일링 기능 확인 set profiling = 1; # 기능 확성화 set profiling_history_size = 100; # 기록 사이즈 100 SELECT * FROM comments c WHERE c.comment_group= 1 AND c.seq > 0 ORDER BY c.seq ASC; show profiles; # 프로파일링 분석 show profile for query 39; # 쿼리문의 수행 시간을 상세하게 확인 show profile cpu for query 39; # 쿼리문의 CPU 사용량 분석
프로파일링 설정을 하고, 쿼리를 실행한 후 프로파일링을 확인해보면 아래와 같이 39번에서 쿼리문이 발생했다.

그리고 쿼리문의 수행 시간을 분석해보면
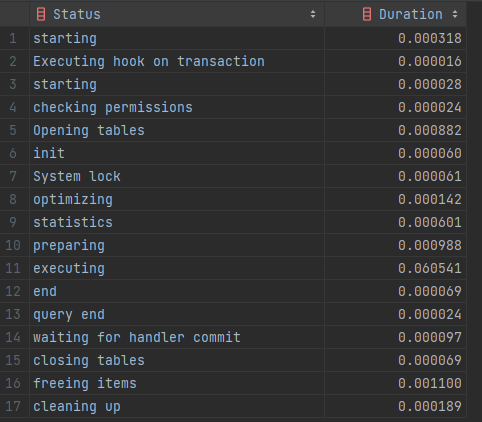
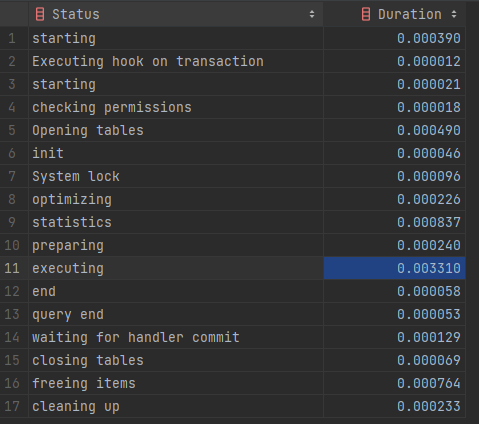
[ 속도 비교 ]
인덱스 설정 전 수행 시간의 총합 : 0.065209
인덱스 설정 후 수행 시간의 총합 : 0.006992
테이블을 Full Scan하던 부분을 Index Range Scan을 통해
약 89.31% 성능이 향상 되었다는 것을 알 수 있다.

잘 보고 갑니다. 선배님...