
OSTEP) 26. Concurrency and Threads
이 포스팅은 Operating Systems: Three Easy Pieces, Remzi H. Arpaci-Dusseau & Andrea C. Arpaci-Dusseau을 읽고 개인 학습용으로 정리한 글입니다.
➖ 22-01-18
Concurrency: An Introduction
-
thread: a new abstraction for a single running process.
-
a multi-threaded program has more than one point of execution (i.e., multiple PCs, each of which is being fetched and executed from).
-
each thread is very much like a separate process, except for one difference:
they share the same address space and thus can access the same data.
➕
-
Each thread has a program counter (PC) that tracks where the program is fetching instructions from.
-
Each thread has its own private set of registers it uses for computation
-
thus, if there are two threads that are running on a single processor, when switching from running one (T1) to running the other (T2), a context switch must take place.
-
The context switch between threads is quite similar to the context switch between processes.
-
the register state of T1 must be saved and the register state of T2 restored before running T2.
-
With processes, we saved state to a process control block (PCB); now, we’ll need one or more thread control blocks (TCBs) to store the state of each thread of a process.
-
There is one major difference, in the context switch we perform between threads as compared to processes: the address space remains the same (i.e., there is no need to switch which page table we are using).
➕
-
One other major difference between threads and processes concerns the stack.
-
In a multi-threaded process, each thread runs independently and of course may call into various routines to do whatever work it is doing. Instead of a single stack in the address space, there will be one per thread.
-
Thus, any stack-allocated variables, parameters, return values, and other things that we put on the stack will be placed in what is sometimes called thread-local storage, i.e., the stack of the relevant thread.
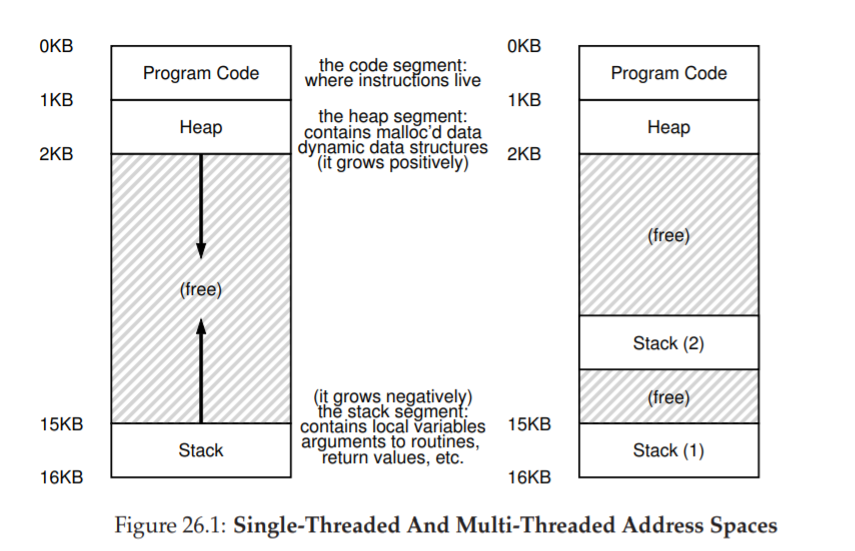
-
(Figure 26.1, left) a single-threaded process (= a classic process): single stack usually residing at the bottom of the address space.
-
(Figure 26.1, right) a multi-threaded process (that has two threads in it): two stacks spread throughout the address space of the process.
-
You might also notice how this ruins our beautiful address space layout. Before, the stack and heap could grow independently and trouble only arose when you ran out of room in the address space. Here, we no longer have such a nice situation. Fortunately, this is usually OK, as stacks do not generally have to be very large (the exception being in programs that make heavy use of recursion).
Why Use Threads?
parallelism
-
If you are executing the program on a system with multiple processors, you have the potential of speeding up this process considerably by using the processors to each perform a portion of the work.
-
The task of transforming your standard single-threaded program into a program that does this sort of work on multiple CPUs is called parallelization, and using a thread per CPU to do this work is a natural and typical way to make programs run faster on modern hardware.
to avoid blocking program progress due to slow I/O
-
Using threads is a natural way to avoid getting stuck; while one thread in your program waits (i.e., is blocked waiting for I/O), the CPU scheduler can switch to other threads, which are ready to run and do something useful.
-
Threading enables overlap of I/O with other activities within a single program, much like multiprogramming did for processes across programs
-
As a result, many modern server-based applications (web servers, database management systems, and the like) make use of threads in their implementations.
An Example: Thread Creation
- Pthread_create(): simply calls pthread_create() and makes sure the return code is 0; if it isn’t, Pthread create() just prints a message and exits.

-
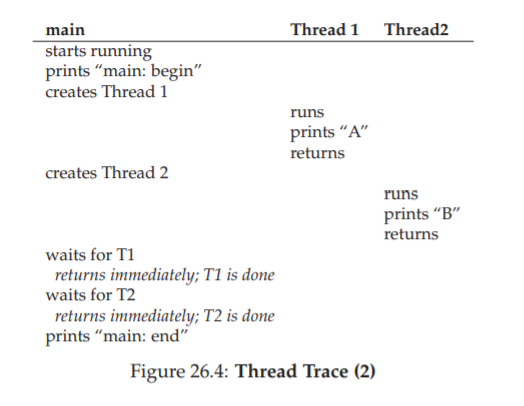
(Figure 26.2) a program code that creates two threads, each of which does some independent work, printing “A” or “B”.
-
The main program creates two threads, each of which will run the
function mythread(), though with different arguments (the string A or B). -
Once a thread is created, it may start running right away, it may be put in a “ready” but not “running” state and thus not run yet, depending on the whims of the scheduler.
-
(On a multiprocessor, the threads could even be running at the same time.)
-
After creating the two threads (T1 and T2), the main thread calls pthread join(), which waits for a particular thread to complete, ensuring T1 and T2 will run and complete before finally allowing the main thread to run again.
-
when it does, it will print “main: end” and exit.
-
Overall, three threads were employed during this run: the main thread, T1, and T2.
➕


-
thread creation is a bit like making a function call.
-
however, instead of first executing the function and then returning to the caller, the system instead creates a new thread of execution for the routine that is being called, and it runs independently of the caller, perhaps before returning from the create, but perhaps much later.
-
What runs next is determined by the OS scheduler, and although the scheduler likely implements some sensible algorithm, it is hard to know what will run at any given moment in time.
Why It Gets Worse: Shared Data

- (Figure 26.6) a simple example where two threads wish to update a global shared variable.
➕



The Heart Of The Problem: Uncontrolled Scheduling

-
the code sequence for adding a number(1) to counter might look something like this (in x86).
-
This example assumes that the variable counter is located at address 0x8049a1c.
-
- the x86 mov instruction is used first to get the memory value at the address and put it into register eax.
-
- Then, the add is performed, adding 1 (0x1) to the contents of the eax register.
-
- Finally, the contents of eax are stored back into memory at the same address.
➕
-
Let us imagine one of our two threads (Thread 1) enters this region of code, and is about to increment counter by one.
-
It loads the value of counter (let’s say it’s 50 to begin with) into its register eax.
-> Thus, eax=50 for Thread 1. -
Then it adds one to the register
-> thus, eax=51 for Thread 1. -
Now, something unfortunate happens: a timer interrupt goes off.
-> thus, the OS saves the state of the currently running thread (its PC, its registers including eax, etc.) to the thread’s TCB. -
Now something worse happens: Thread 2 is chosen to run, and it enters this same piece of code.
-
It also executes the first instruction, getting the value of counter and putting it into its eax (remember: each thread when running has its own private registers; the registers are virtualized by the context-switch code that saves and restores them).
-> thus, eax=50 for Thread 2. (The value of counter is still 50 at this point). -
then assume that Thread 2 executes the next two instructions, incrementing eax by 1
-> thus, eax=51 for Thread 2. -
then, saving the contents of eax into counter (address 0x8049a1c).
-> Thus, the global variable counter now has the value 51. -
Finally, another context switch occurs, and Thread 1 resumes running. Recall that it had just executed the mov and add, and is now about to perform the final mov instruction. Recall also that eax=51.
-> Thus, the final mov instruction executes, and saves the value to memory;
-> the counter is set to 51 again.

- Put simply, what has happened is this: the code to increment counter
has been run twice, but counter, which started at 50, is now only equal
to 51. A “correct” version of this program should have resulted in the
variable counter equal to 52.
➕
-
a race condition: the results depend on the timing execution of the code.
-> we call this result indeterminate, where it is not known what the output will be and it is indeed likely to be different across runs. -
Because multiple threads executing this code can result in a race condition, we call this code a critical section.
-> A critical section is a piece of code that accesses a shared variable (or more generally, a shared resource) and must not be concurrently executed by more than one thread. -
mutual exclusion: guarantees that if one thread is executing within the critical section, the others will be prevented from doing so.
TIP: USE ATOMIC OPERATIONS
-
The idea behind making a series of actions atomic is simply expressed
with the phrase “all or nothing”. -
it should either appear as if all of the actions you wish to group together occurred, or that none of them occurred, with no in-between state visible.
-
Sometimes, the grouping of many actions into a single atomic action is called a transaction.
26.5 The Wish For Atomicity
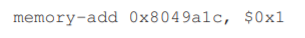
-
Assume this instruction adds a value to a memory location, and the hardware guarantees that it executes atomically.
-> when the instruction executed, it would perform the update as desired.
-> It could not be interrupted mid-instruction, because that is precisely the guarantee we receive from the hardware: when an interrupt occurs, either the instruction has not run at all, or it has run to completion; there is no in-between state. -
Atomically, in this context, means “as a unit”.
➕
-
What we’d like is to execute the three instruction sequence atomically:

-
If we had a single instruction to do this, we could just issue that instruction and be done. But in the general case, we won’t have such an instruction.
-
What we will instead do is ask the hardware for a few useful instructions upon which we can build a general set of what we call synchronization primitives.
26.6 One More Problem: Waiting For Another
-
This chapter has set up the problem of concurrency as if only one type of interaction occurs between threads, that of accessing shared variables and the need to support atomicity for critical sections.
-
there is another common interaction that arises, where one thread must wait for another to complete some action before it continues.
-
for example, when a process performs a disk I/O and is put to sleep; when the I/O completes, the process needs to be roused from its slumber so it can continue (sleeping/waking interaction).
ASIDE: KEY CONCURRENCY TERMS (CRITICAL SECTION, RACE CONDITION,INDETERMINATE, MUTUAL EXCLUSION)
-
A critical section is a piece of code that accesses a shared resource, usually a variable or data structure.
-
A race condition (or data race) arises if multiple threads of execution enter the critical section at roughly the same time.
-> both attempt to update the shared data structure, leading to a surprising (and perhaps undesirable) outcome. -
An indeterminate program consists of one or more race conditions.
-> the output of the program varies from run to run, depending on which threads ran when.
-> The outcome is thus not deterministic, something we usually expect from computer systems. -
To avoid these problems, threads should use some kind of mutual exclusion primitives; doing so guarantees that only a single thread ever enters a critical section, thus avoiding races, and resulting in
deterministic program outputs.
26.7 Summary: Why in OS Class?
-
the OS was the first concurrent program, and many techniques were created for use within the OS. Later, with multi-threaded processes, application programmers also had to consider such things.
-
OS designers, from the very beginning of the introduction of the interrupt, had to worry about how the OS updates internal structures.
📌참고자료
