
[OSTEP] Persistence) 45. Data Integrity and Protection
이 포스팅은 Operating Systems: Three Easy Pieces, Remzi H. Arpaci-Dusseau & Andrea C. Arpaci-Dusseau을 읽고 개인 학습용으로 정리한 글입니다.
CH 45. 데이터 무결성과 보호
1. 디스크 오류 모델
-
초기 RAID 디스크: 실패-시-멈춤 모델
-
현대 디스크: 부분-실패 모델
(1) 숨어있는 섹터 에러(LSE): 디스크 내 섹터(or 섹터 내 블럭) 손상
-> 에러 정정 코드(ECC)로 탐지 가능
(2) 블록 손상: 디스크 내용 손상
-> 조용한 오류
2. 숨어있는 섹터 에러(LSE)
- 에러 리턴 시 중복 저장된 데이터 리턴
3. 손상 검출 ~ 4. 체크섬의 활용
- 데이터와 함께 체크섬 저장 -> 데이터로부터 계산한 체크섬 = 저장된 체크섬?
체크섬 함수 (체크섬 충돌 발생 가능 -> 완벽한 방법은 없음)
(1) XOR
- 각 열에서 2개의 값이 변하면 손상 검출 X
(2) 덧셈
- 각 데이터 청크에 2의 보수 덧셈 (오버플로우 발생 시 무시)
- 많은 부분 변경되었어도 검출 가능, 데이터가 쉬프트된 경우 발견 X
(3) Fletcher 체크섬 (강력함)
- 두 개의 체크 바이트 s1, s2
s1 =s1 + (d_i mod 255)
s2 =s2 + (s1 mod 255) - 모든 한 비트, 두 비트, 동시다발적 에러 검출 가능
(4) Cyclic Redundancy Check (CRC) (강력함)
- 주어진 데이터를 큰 2진수로 여기고 사전에 합의한 값 k로 나눈 계산의 나머지 =CRC
체크섬의 배치 방법
(1) 각 디스크 섹터/블럭에 체크섬 같이 저장
- 디스크 섹터 크기의 청크(or 청크의 배수)로만 쓸 수 있음
-> 섹터 하나 포맷 후 8바이트 체크섬 저장
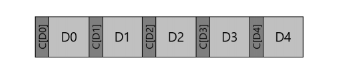
(2) n개의 체크섬 모아서 저장 & 그 뒤에 n개의 블록 배치
-> 상대적으로 덜 효율적
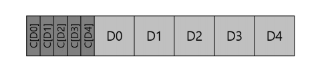
5. 잘못된 위치에 저장
- 체크섬에 디스크 번호 & 섹터 번호를 포함하여 저장
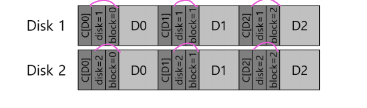
6. 기록 작업의 손실(lost write)
- 상위계층에는 쓰기가 완료되었다고 알리지만, 실제로는 저장되지 않음
- ex. 디스크 블럭이 갱신되지 않고 예전 블럭의 내용이 남겨져 있는 상황
-> 체크섬 O, 물리적 ID (디스크 번호 & 섹터 번호) O
(1) 쓰기 검증(write verify) / 쓰기 후 읽기(read-after-write)
- I/O 두 배
(2) 체크섬을 다른 위치에 기록하기
- Zettabyte FS: 파일 블록의 체크섬을 아이노드와 간접 블록에 저장
-> 데이터 블록에 대한 쓰기는 손실되었더라도 아이노드 내 체크섬은 갱신되었을 것
(아이노드 쓰기와 데이터 쓰기 둘 다 손실되었을 확률은 적음)
7. Scrubbing
- 접근하지 않은 데이터의 무결성 보장 방법
- 디스크 다시 읽기 (dist scrubbing): 주기적으로 모든 블록 읽어 체크섬 검사
8. 체크섬 오버헤드
(1) 공간 (크지 않은 편)
- 디스크 상에 체크섬 저장: 디스크 전체 0.19% 사용
- 시스템 메모리 필요: 메모리에 체크섬과 데이터를 읽어들일 수 있는 공간
(2) 시간
- 데이터 저장할 때 체크섬 연산 & 데이터 접근할 때 체크섬 다시 계산하여 비교
-> 오버헤드를 줄이기 위해 체크섬 연산과 데이터의 복사를 하나의 연속적인 작업으로 처리
(데이터 복사의 예: 커널의 페이지 버퍼에서 사용자 버퍼로 데이터 복사하기) - 체크섬 계산 방법에 따라 추가적인 I/O 발생
-> 체크섬과 데이터가 구분되어 저장된 경우: 설계를 통해 감소 가능
-> 디스크 다시 읽기 수행하는 경우: 수행 시점 적절히 조정

Be able to be vulnerable, in search of truth