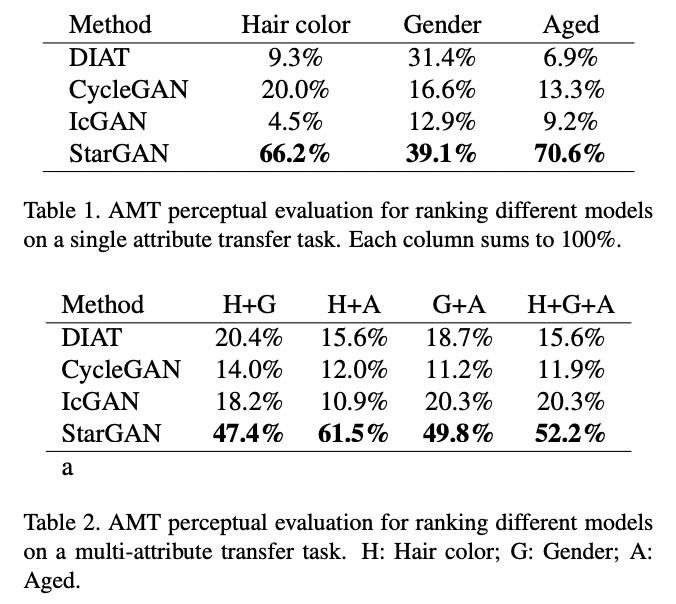
StarGAN
0. Abstract

최근 연구들은 image-to-image translation에서 큰 성공을 보여주었다. Image-to-image translation이란, 어떤 이미지의 양상, 쉽게 말해 특징,을 또 다른 양상으로 바꾸는 task를 말한다. 기존 연구들은 2개이상의 도메인을 다루는데에 scalability와 robustness를 제한해왔는데, 이는 서로 다른 모델들이 각 이미지 도메인 쌍에 대해 독립적으로 만들어졌기 때문이다. 이 한계점을 극복하기 위해 StarGAN이 등장했다.
1. Introduction
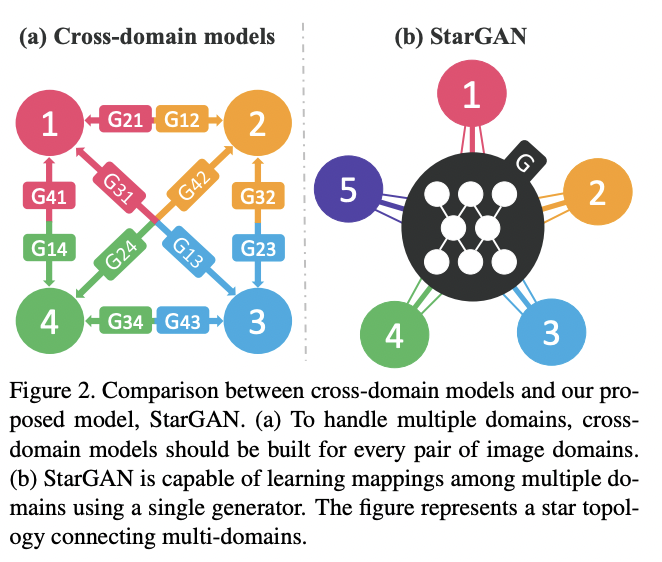
Cross-domain models
Problem
- 4개의 다른 도메인들 사이에서 이미지를 translation 시키기 위해서는 4*(4-1) = 12개의 네트워크가 필요함
- 각 데이터셋이 부분적으로 라벨링되어 있기 때문에, jointly training이 불가능함
StarGAN
Solution
- 모든 가능한 도메인들사이의 매핑을 하나의 generator를 통해 학습함
- Single generator : 이미지와 도메인 정보를 모두 인풋으로 집어넣고 이미지를 알맞은 도메인으로 바꾸는 것을 학습함
- 도메인 정보 표현 시, binary나 one-hot vector와 같은 형식을 사용함
- 학습하는 동안 랜덤하게 타겟 도메인 라벨을 만들어내고 모델이 이미지를 타겟 도메인으로 변환하도록 학습시킴
- 도메인 라벨 제어 가능
- 이미지를 원하는 도메인으로 변환시킬 수 있음
- Mask vector를 도메인 라벨에 추가하여 joint 학습이 가능하도록 함
- 모델이 모르는 라벨을 무시할 수 있음
- 특정 데이터셋의 라벨들에 초점을 맞출 수 있음
2. Star Generative Adversarial Networks
: 다수의 Domain 간의 translation을 한 generator로 학습시키기 다음과 같은 모델 architecture를 가진다.
(1) Mutli-Domain Image-to-Image Translation
Training
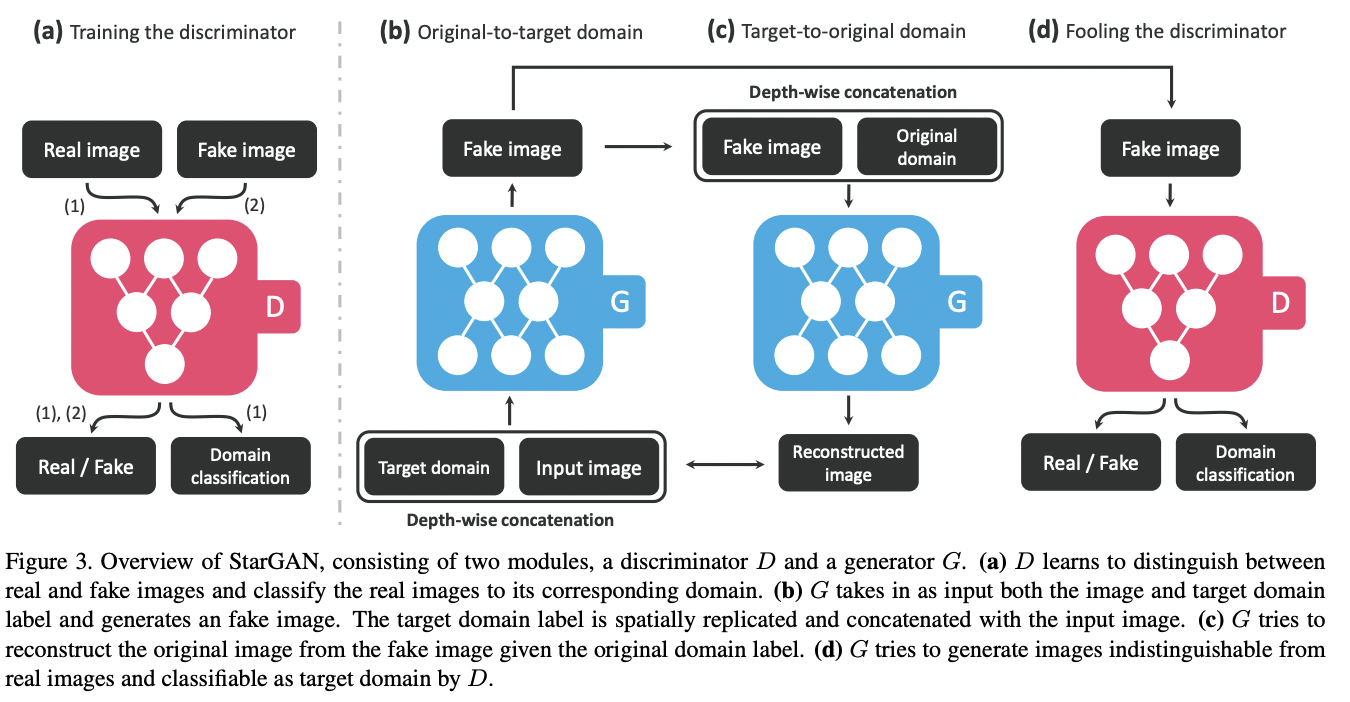
Generator
- Input으로 image와 target domain label을 넣는다.
- Target label은 random하게 생성되어 input image를 flexeble하게 translate하도록 함
- Target domain label에 해당하는 이미지로 변환한 다음에 다시 원래 domain label에 해당하는 이미지로 reconstruction한다.
- 같은 generator를 사용하여 CycleGAN의 형태를 사용함
- 일반 CycleGAN과 다르게 generator를 공통으로 하나만 사용함
- Target label이 분류모델을 통해 나오도록 학습을 한다.
- 만들어진 이미지는 discriminator에 input으로 입력되고 generated image가 real이 됨
Discriminator
- Ground-Truth image와 Generated Image를 input으로 받는다.
- 이전과 같이 real image와 fake image를 구별하고, 실제 이미지의 domain label이 나오도록 분류모델을 학습한다.
Loss Function
Adversarial Loss
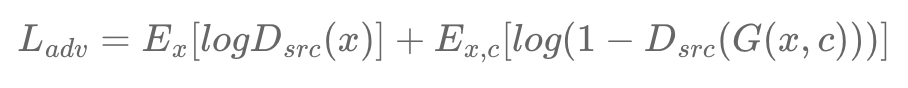
- Generator : 최대한 ground-truth와 비슷한 이미지를 만들어서 Discriminator를 속이도록 학습
- Discriminator : Generator에서 생성된 fake image와 real image를 구별할 수 있도록 학습
Domain Classification Loss
: Input image x가 domain c에 해당하는 이미지로 잘 변환될 수 있도록 하는 Loss term이다.
(Generator와 Discriminator학습에 따라 2가지로 나누어짐)
- Discriminator를 학습하는 경우, real image가 real domain으로 잘 분류될 수 있도록 함
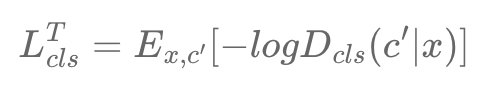
- Generator를 학습하는 경우, Generated image가 target label c로 분류되도록 학습함
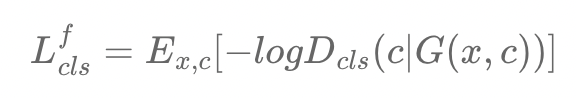
Reconstruction Loss
: Cycle loss를 사용하고, metric으로는 L1 norm을 사용한다.
- Adversarial loss와 classification loss를 최소화하기 위해, G는 진짜같은, 올바른 타겟 도메인에 분류되는 이미지들을 만들어내도록 학습됨
- 하지만, loss를 최소화하는 것은 변환된 이미지가 인풋 이미지들의 내용을 보존한다는 것을 보장하지 않음
- 이러한 문제를 완화하기 위해서, generator에 Cycle consistency loss를 적용함
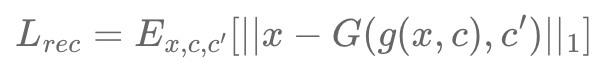
Final Loss Function
최종적인 Loss Function은 다음과 같다.
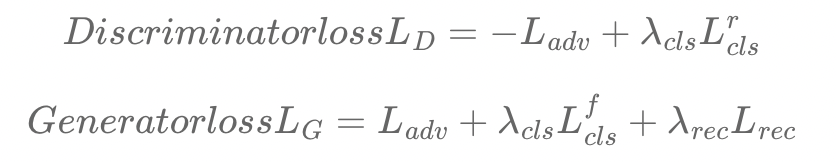
(2) Training with Multiple Datasets
: StarGAN은 다른 label type을 가지는 여러 데이터셋들을 동시에 사용할 수 있다.
- 하지만, 데이터셋마다 가지고 있는 attribute의 정보가 다르므로 문제가 생길 수 있음
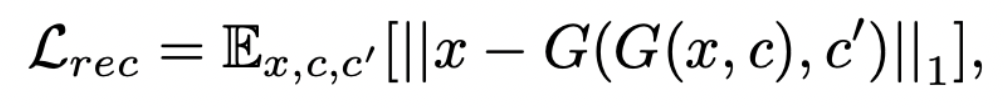
Mask Vector
: StarGAN이 특정화되지 않은 라벨들을 무시하고 특정 데이터 셋에서 존재하는 확실히 알려진 라벨에 초점을 맞추도록 한다.
- StarGAN에서는 mask vector m을 표현하기 위해 n차원의 one-hot vector를 사용하는데 n은 데이터셋의 수를 뜻함
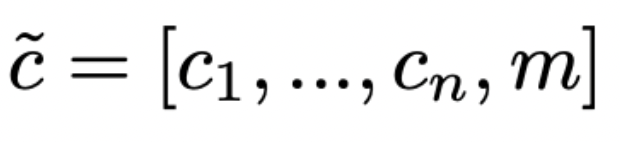
- c_i : i번째 데이터셋의 라벨에 대한 벡터
- binary attributes = binary vector
- 카테고리 attributes = one-hot bector
Training Strategy
: Training과정에서는, domain label를 generator의 인풋으로 사용하여 generator가 알려지지 않은 라벨에 대해서는 무시를 하게 만든다.
- Generator의 구조는 input label의 차원을 제외하고는 하나의 데이터셋에 대해 학습할 때와 같은 구조임
- Discriminator는 classification error만을 최소화함
- 다양한 데이터셋을 번갈아가며 학습하며 discriminator는 모든 데이터셋에 관한 discriminative 특징들을 학습하고 generator는 모든 라벨들을 제어하는 것에 대해 학습하게됨

3. Implementation
: 학습 과정을 안정화시키고 더 좋은 퀄리티의 이미지들을 만들어내기 위해 gradient penalty와 함께 Wasserstein GAN으로 대체하였다.
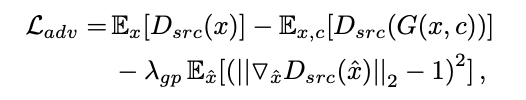
Network Architecture
: StarGAN은 두 개의 convolutional layers로 구성된 generator network를 가진다.
- generator에 instance normalization을 사용하고 discriminator에는 사용하지 않음
4. Experiment