BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
1. Introduction
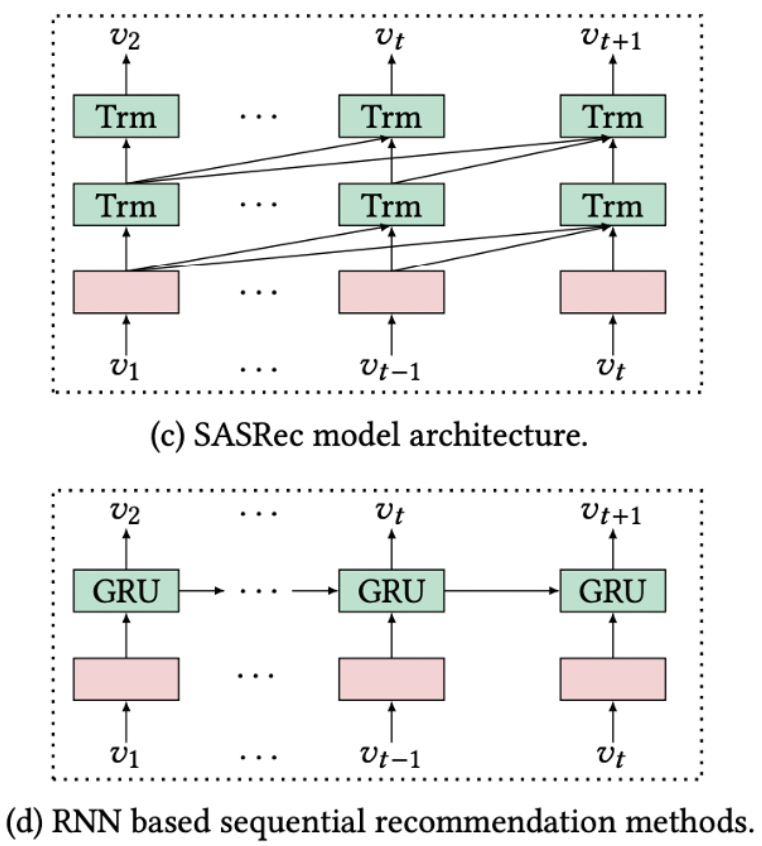
기존에 좋은 성능을 보였던 시퀀셜 추천시스템(GRU4Rec, SASRec)은 아래의 그림과 같이 유저의 이전 행동 패턴만을 고려한 단방향 추천 모델들이 주로 사용되었다. 하지만 이러한 단방향 추천 모델의 경우 유저가 과거에 구매했던 아이템의 정보만으로 모델을 학습하기 때문에 성능에 제한이 있을 수 있으므로 양방향 학습 모델인 BERT4Rec을 제안했다.
2. Related Works
General Recommendation
Interaction matrix
: 어떠한 유저가 어떠한 아이템에 대해 어떤 피드백을 남겼는지를 주시하여 이 정보를 이용해 생성한 저차원 matrix
- 추천 시스템의 근본적인 원리

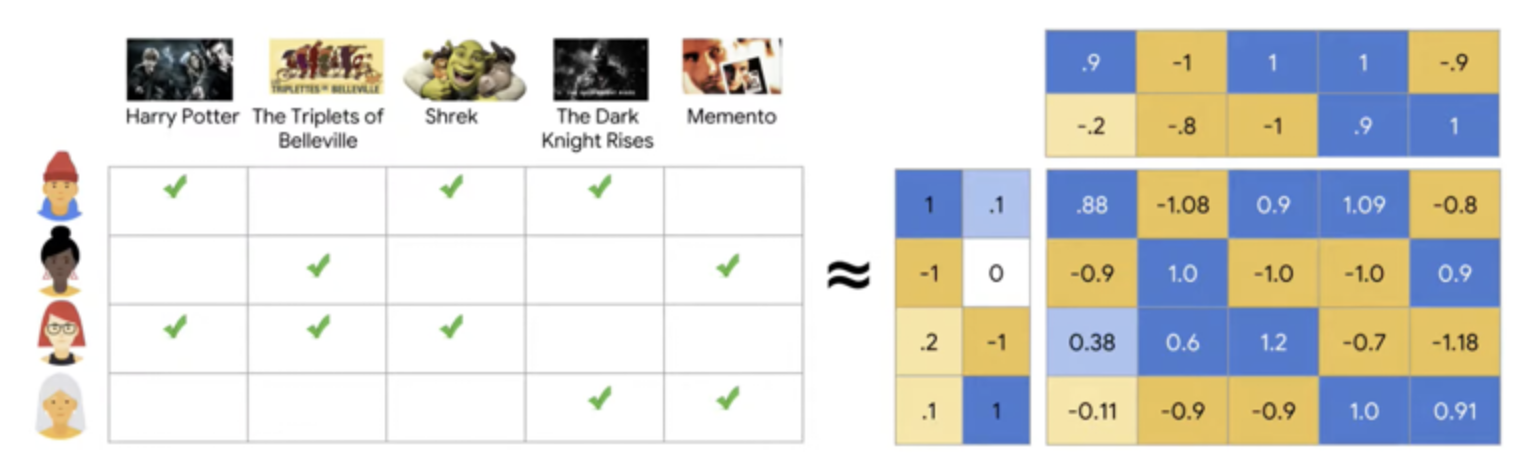
Matrix factorization
: user, item에 대한 수가 너무 크기 때문에 matrix가 매우 복잡해지므로 복잡한 user-item matrix를 저차원의 user-item matrix로 분해하는 방법
- 딥러닝 추천 시스템에 적용되는 원리
NCF(Neural collaborate filtering)
: 특정 유저, 아이템에 대한 K차원의 dense한 feature를 뽑는 방법

Sequential Recommendation
: RNN을 이용하여 sequential한 history를 학습하는 방법 등이 있음
Attention Mechanism
: Attention과 Recommendation를 합친 방법 등이 있음
- SASRec : next item을 masking한 다음 추천 아이템을 예측하는 방식
- transformer의 decoder 구조를 가지고 있음
- 단방향(unidirection) 모델
3. BERT4REC
Model Architecture
Embedding Layer, Transformer Layer, Output Layer로 구성되어 있음
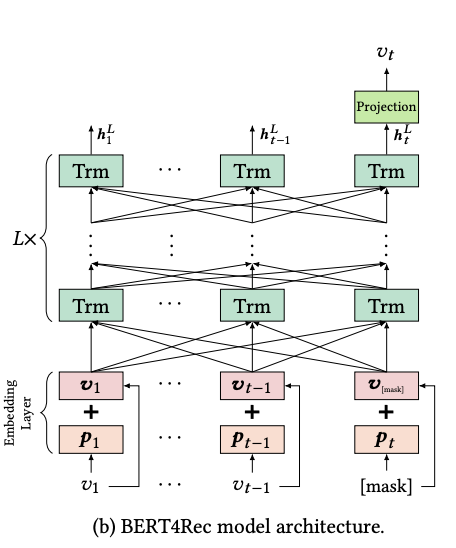
Embedding Layer
- 아이템의 정보를 더해 Mask와 함께 Transformer 모델의 입력으로 들어간다.
- 유저의 시퀀스 길이가 전체 시퀀스 길이인 하이퍼 파라미터 N보다 크면 잘라내고(truncate), N보다 작으면 제로 패딩 한다.
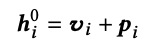
Transformer Layer
- 기존 Transformer와 동일하게 Multihead Attention, Point-Wise Feed Forward를 사용하며 레이어의 수 L만큼 반복 연산을 수행한다.
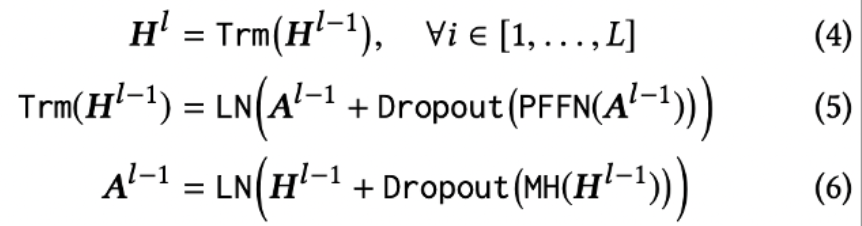
Output Layer
- Transformer 모델로부터 받은 final output으로부터 softmax를 통해 Mask 토큰의 확률값을 구한다.
- 아이템에 대한 임베딩 매트릭스는 공유된(Shared) 임베딩 매트릭스를 사용하여 모델의 오버피팅과 사이즈를 줄일 수 있도록 한다.
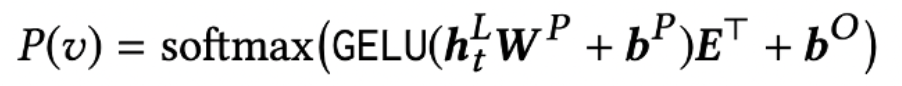
Model Learning
- 모델의 입력에는 유저의 시퀀스 중 p의 확률 만큼 mask를 수행하여 들어가게 되며 출력으로 Mask된 아이템의 확률값이 나온다.
- Mask의 비율 p의 경우 데이터셋마다 다르지만, 너무 큰 값으로 설정할 경우 오히려 성능은 악화됨
- 모델의 Loss로 Negative log-likelihood를 사용한다.
- Mask가 반영된 유저의 행동 시퀀스가 주어졌을 때 Mask 아이템과 실제 Mask의 아이템을 비교하여 낮은 확률을 가질록 weight를 더 많이 업데이트하는 방식으로 학습한다.
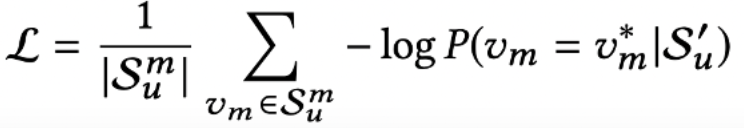
4. Experiments
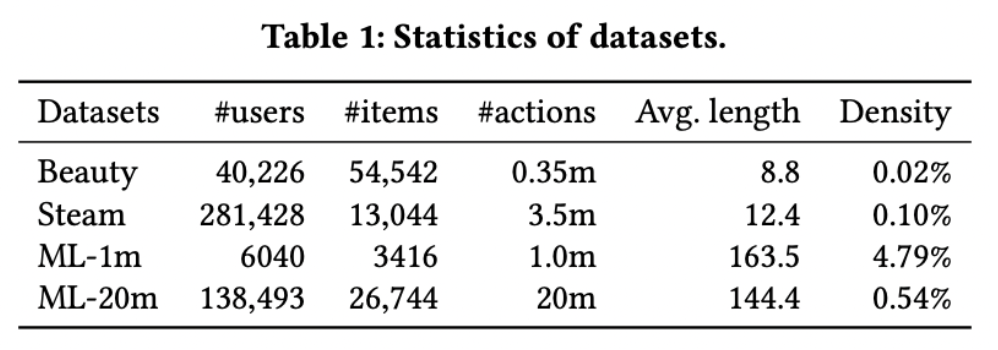
Datasets
: 총 4가지 데이터 셋을 통해 실험을 진행함
Evaluation
: 전체 데이터 중에서 일부만 사용하여 학습하고 나머지 데이터는 얼마나 유사하게 예측했는지 평가하기위해 사용함
- 검색 시스템에서 많이 쓰는 다음 2가지를 이용해서 평가함
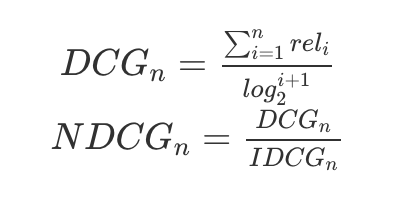
5. Results
: 단순히 BERT만 사용했음에도 불구하고 다른 모델보다 좋은 성능을 보여주었음

MLOps