YOLO 논문 리뷰
https://arxiv.org/pdf/1506.02640.pdf
Abstract
YOLO는 object detection에 대한 새로운 접근 방식이다. 단일 신경망은 evaluation 한 번으로 이미지의 bounding box와 클래스 확률을 즉시 예측한다. 전체 detection 파이프라인이 단일 네트워크이므로 end-to-end detection 가능하다. 또한 초당 45프레임으로 실시간 이미지 처리하며 localization 오류가 더 많지만 배경에 대해 false positive를 예측할 가능성은 낮다.
Introduction
복잡한 파이프라인으로 구성된 기존 모델들과 달리, 이미지에서 bounding box 좌표와 클래스 확률을 즉시 예측함으로써 object detection을 단일 회귀 문제로 재구성한다. 이미지를 한 번만 보고 객체의 위치와 종류를 파악 가능하다.
- YOLO의 장점
- YOLO is extremely fast.
- YOLO reasons globally about the image when making predictions
- YOLO learns generalizable representations of objects.
- YOLO의 단점 : 속도는 빠르지만, 일부 object, 특히 크기가 작은 object에 대한 detection이 어렵다.
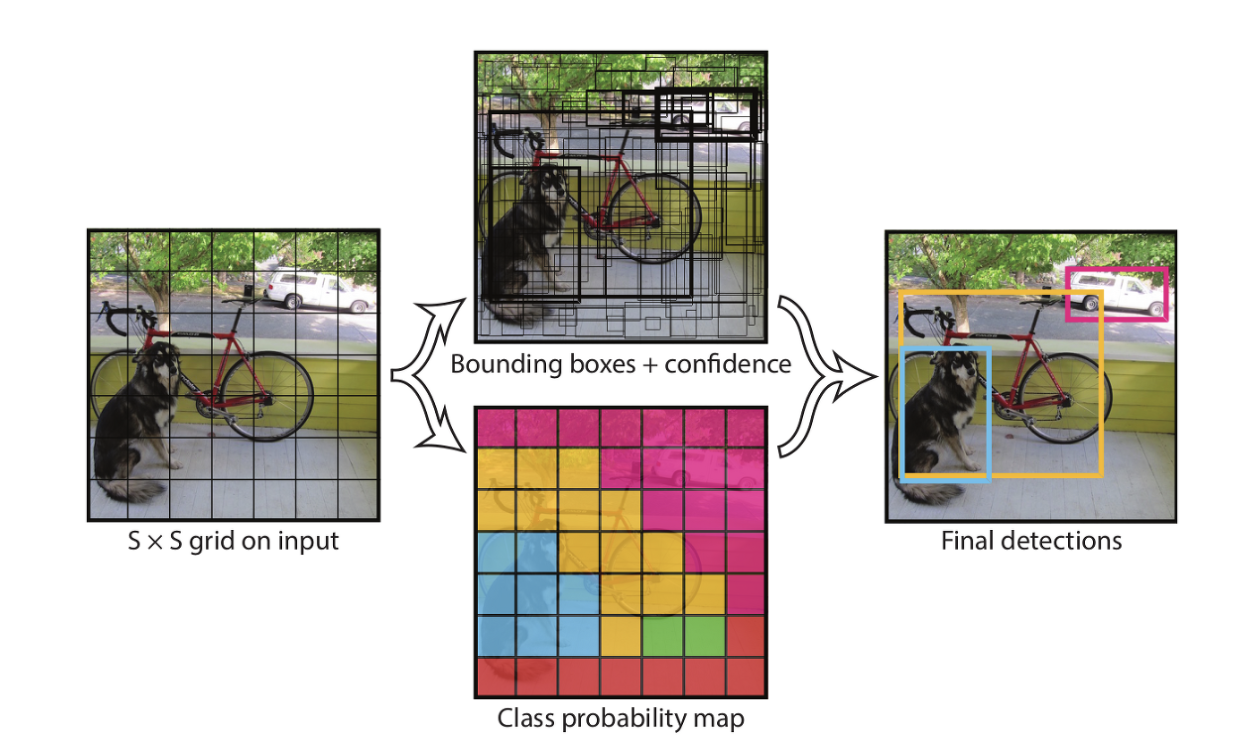
Unified Detection
YOLO는 구조가 하나로 통합되어 Single Neural Network 구조 형성한다.
단 하나의 네트워크로 전체 이미지의 feature를 사용해 모든 클래스와 그에 대한 bounding box를 동시에 예측하므로즉 전체 이미지와 이미지 내 모든 object에 대해 추론 가능하다.
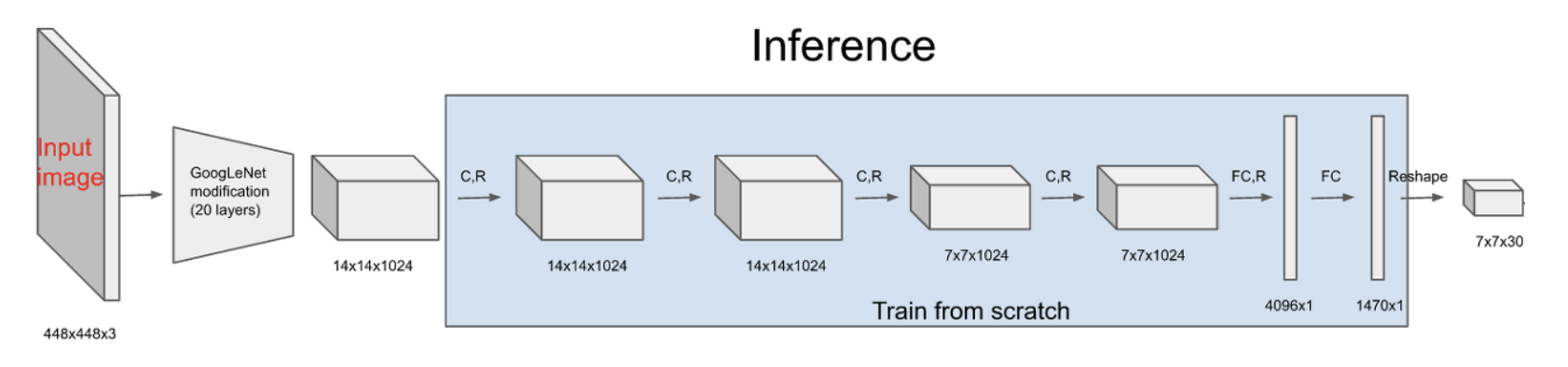
Network Design
- 전체 구조 : convolutional layers 24 (feature 추출) + fully connected layer 2
- 1000 class의 ImageNet 데이터셋으로 20개의 conv layer를 pre-train 1 × 1 컨볼루션 레이어를 번갈아 사용해 선행 레이어의 feature space를 축소 - 활성함수 : leaky ReLU (마지막 layer만 linear 함수)
- 최종 output : 7 × 7 × 30 tensor (S=7, B=2, C=20)
Training
YOLO 네트워크는 손실함수로 SSE를 사용하지만, SSE는 최적화가 용이하지만 몇가지 문제점이 있다.
(1) localization error와 classification error의 가중치를 동일하게 취급한다.
- localization loss : bounding box의 위치를 얼마나 잘 예측했는지
- classification loss : 클래스를 얼마나 잘 예측했는지
(2) 모델의 불균형을 초래한다.
- 일반적으로 이미지 내 객체가 존재하는 부분보다 없는 배경 부분이 더 많기 때문에, grid cell 대부분의 confidence score = 0이다.
(3) 모든 크기 bounding box의 가중치를 동일하게 취급한다.
- 위치 변화에 민감한 작은 box와 그렇지 않은 큰 box의 가중치를 동일하게 취급한다.
이러한 문제를 개선하기 위해 사용한 두 가지 방법이 있다.
(1) 가중치 조정
- 객체가 있는 BB 가중치 ↑, 객체 없는 BB 가중치 ↓ (BB : Bounding Box)
λcoord = 5 / λnoobj = 0.5 (coord : coordinate prediction 좌표예측, noobj : no object)
(2) square root 적용한다.
- Bounding box의 크기 차이를 감소시키기 위해 높이와 넓이에 제곱근을 적용한다.
Limitations of YOLO
(1) 작은 객체 탐지가 어렵다.
- Spatial constraint (공간적 제약) : 그리드 셀 하나당 객체를 하나만 검출할 수 있어서, 한 셀에 작은 객체가 여러 러 개 모여있는 경우, 여러 객체를 검출하는 것이 아니라 하나로만 봐야하기 때문에 제대로 검출하지 못하는 문제
(2) 새로운 aspect ratio에 대한 탐지가 어렵다.
- aspect ratio : bounding box의 가로세로 비율
(예를 들어, 1:1, 1:2, 2:1 비율의 bounding box만 학습했는데, 3:1 비율의 box를 테스트하면 탐지하지 못함)
(3) 손실함수 SSE가 BB 크기와 관계 없이 가중치를 동일하게 취급한 문제를 해결하지 못한다.
- BB의 높이와 넓이에 루트를 취해서 크기 차이를 감소해 문제를 개선했지만, 가중치는 동일하게 주기 때문에 완전히 해결하지 못함
Conclusion
YOLO는 간단한 single network 구조이고 전체 이미지를 한 번에 train 및 detection 가능하며 여러 구역으로 나뉜 이미지를 보는 게 아니라 전체 이미지를 봄으로써 새로운 도메인에 대한 일반화 능력 우수하다는 장점이 있다.
