Transformer 논문 리뷰
https://arxiv.org/abs/1706.03762
Abstract
Transformer : 온전히 attention mechanism에만 기반한 구조
- 기존 sequence transduction model들은 인코더와 디코더를 포함한 복잡한 recurrent 나 cnn에 기반함
- 가장 성능이 좋은 모델 또한 attention mechanism으로 인코더와 디코더를 연결한 구조임
- English-to-German , English-to-French translation에서 SOTA 달성함
- 다른 task에서도 일반적으로 잘 동작함
Introduction
이 연구에서는 input과 output간에 global한 dependency를 추출하기위해 recurrence에서 벗어나 전적으로 attention 메커니즘에만 의존하는 transformer 모델을 제안한다. 트랜스포머는 유의미한 병렬화를 가능하게 하고, 8개의 P100 GPU로 12시간 정도만 training하면, 번역의 품질에 있어서 SOTA에 도달할 수 있다.
Transformer
input과 output간 global dependency를 뽑아내기 위해 recurrence를 사용하지 않고, attention mechanism만을 사용한다. 따라서, parallelization이 가능해 적은 시간으로 translation quality에서 SOTA를 달성할 수 있었다.
Model Architecture
(1) Encoder and Decoder Stacks
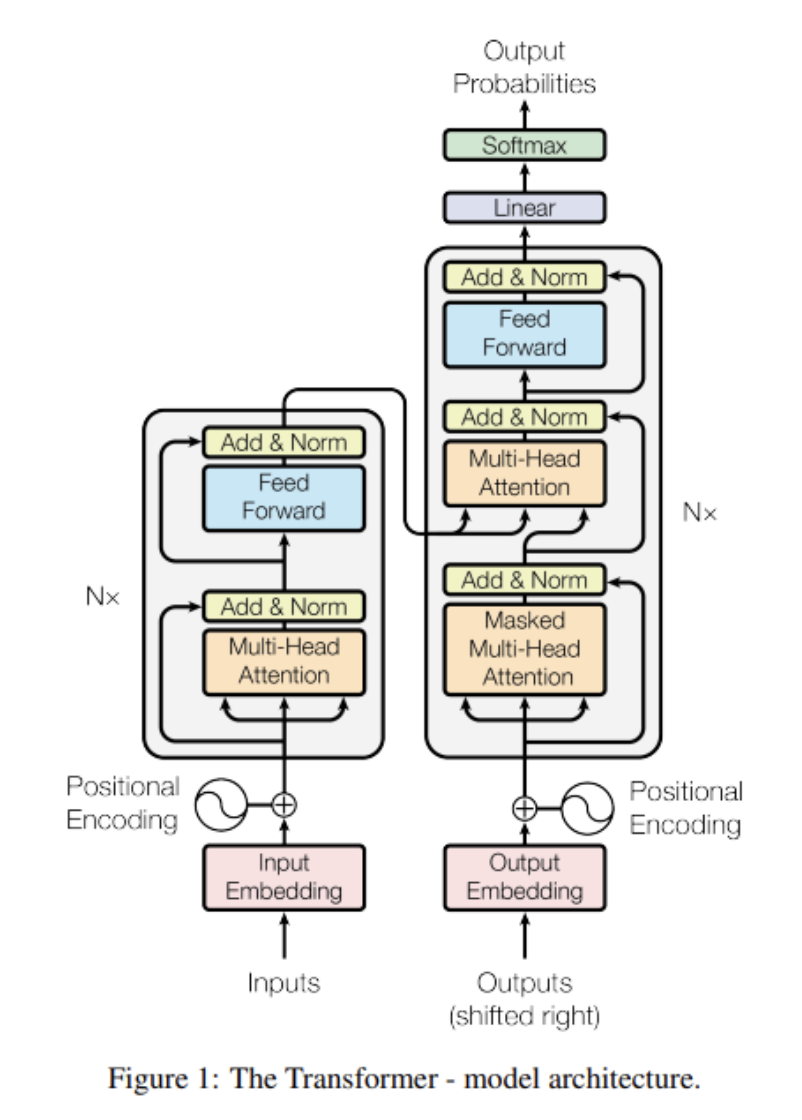
Encoder
- Encoder는 6개의 identical layer로 이루어짐
- 각 layer는 두 개의 sub-layer가 있음
- 첫 번째 sub-layer는 multi-head self-attention mechanism
- 두 번째 sub-layer는 간단한 position-wise fully connected feed-forward network
- 각 two sub-layers 마다 layer normalization 후에 residual connection을 사용함
Decoder
- Decoder도 마찬가지로 6개의 identical layer로 이루어짐
- 각 Encoder layer의 두 sub-layer에, decoder는 세번째 sub-layer를 추가함
- encoder stack의 결과에 해당 layer가 multi-head attention을 수행함
- 마찬가지로 residual connection 적용
(2) Attention
Attention function은 쿼리와 key-value쌍을 output에 매핑함
- output은 value들의 weighted sum으로 계산됨
Scaled Dot-Product Attention
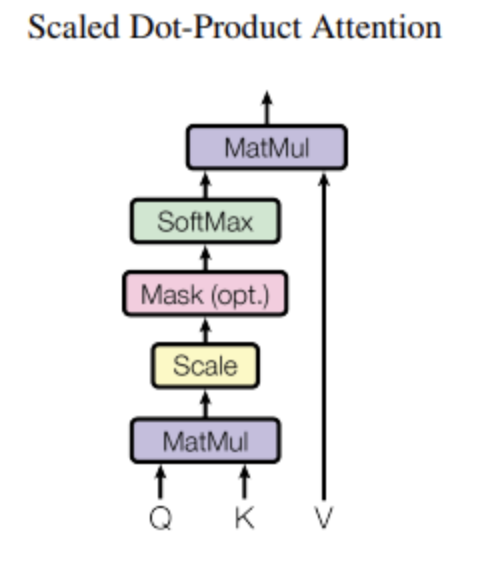
- Input : query, key의 dimension
- Additive attention, Dot-product attention이 있음
Multi-Head Attention
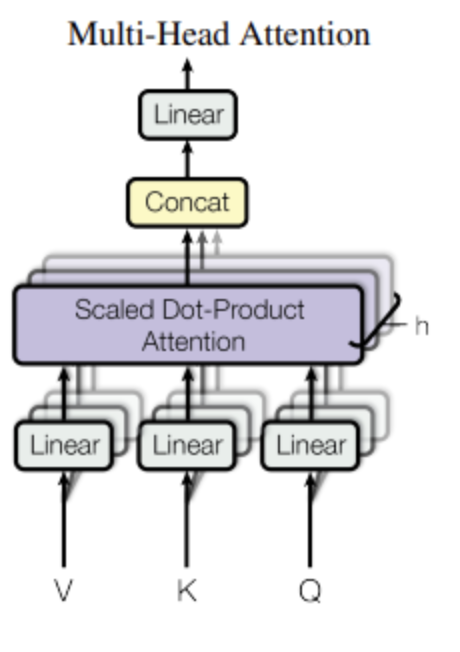
- 각 head마다 차원을 줄이기 때문에, 전체 계산 비용은 전체 차원에 대한 single-head attention과 비슷함
(3) Position-wise Feed-Forward Networks
인코더 디코더의 각 layer는 fully connected feed-forward network를 가짐
- 각 position에 따로따로, 동일하게 적용됨
- ReLu 활성화 함수를 포함한 두 개의 선형 변환이 포함됨
- linear transformation은 다른 position에 대해 동일하지만 layer간 parameter는 다름
(4) Embeddings and Softmax
다른 sequence transduction models 처럼, 학습된 임베딩을 사용함
- decoder output을 예측된 다음 토큰의 확률로 변환하기 위해 선형 변환과 softmax를 사용함
- tranformer에서는, 두 개의 임베딩 layer와 pre-softmax 선형 변환 간, 같은 weight의 matrix를 공유함
(5) Positional Encoding
Transformer는 어떤 recurrene, convolution도 사용하지 않기 때문에, sequence의 순서를 사용하기 위해 sequence의 상대적, 절대적 position에 대한 정보를 주입해줘야 함
- 인코더와 디코더 stack 아래의 input 임베딩에 "Positional Encoding"을 추가함
- 다양한 positional encoding 방법 중에, transformer는 다른 주기의 sine, cosine function을 사용함
Training
(1) Training Data and Batching
- English-German
- English-French
(2) Hardware and Schedule
- 8개의 NVIDIA P100 GPU로 학습
- base model은 12시간 동안 (100,000 step) 학습시킴
- big model 은 3.5일 동안 (300,000 step) 학습시킴
(3) Optimizer
- Adam optimizer 사용
(4) Regularization
- 세 가지 regularization을 사용함
Results
(1) Machine translation
- WMT 2014 English-to-German translation, English-to-French translation에서 SOTA 달성
(2) Model Variation
(3) English Constituency Parsing
- English Constituency Parsing에서도 잘 일반화해서 사용할 수 있는지 실험함
- 구체적인 tuning 없이도 놀라운 성능을 보임
