인공지능 분야에서 파이썬(Python)의 위상은 누구나 다 아는 사실입니다. 하지만 OpenAI와 Claude 같은 다양한 모델을 동시에 호출하려면 보통 두꺼운 래퍼(Wrapper) 층을 직접 작성해야 합니다. 저 또한 고객이 보낸 엉망진창인 PDF를 파싱하기 위해 직접 정규표현식을 썼던 적이 있습니다. 결과는 뻔했죠. 코드 베이스는 점점 비대해지고 유지보수 비용은 치솟았습니다.
오늘은 데이터 연동부터 모델 평가까지, 전체 파이프라인에서 반복적인 코드를 획기적으로 줄여주는 9가지 파이썬 라이브러리를 소개합니다.
Python 개발 환경 구축하기
라이브러리를 본격적으로 사용하기 전, 안정적이고 관리하기 쉬운 파이썬 환경을 갖추는 것이 기본입니다. 초보 개발자들은 서로 다른 버전, 가상 환경, 의존성 충돌 사이에서 헤매다가 반나절을 허비하곤 합니다.
ServBay를 사용하면 클릭 몇 번으로 파이썬 환경을 한 번에 해결할 수 있습니다. 버전 전환부터 데이터베이스 관리까지 간편하게 처리되죠. 개발자를 번거로운 설정 작업에서 해방시켜준다는 점에서, 제가 다음에 소개할 도구들의 철학과 맞닿아 있습니다.
환경이 준비되었다면, 필요에 따라 아래의 도구들을 선택해 보세요.
LiteLLM: 멀티 플랫폼 모델 호출 통합
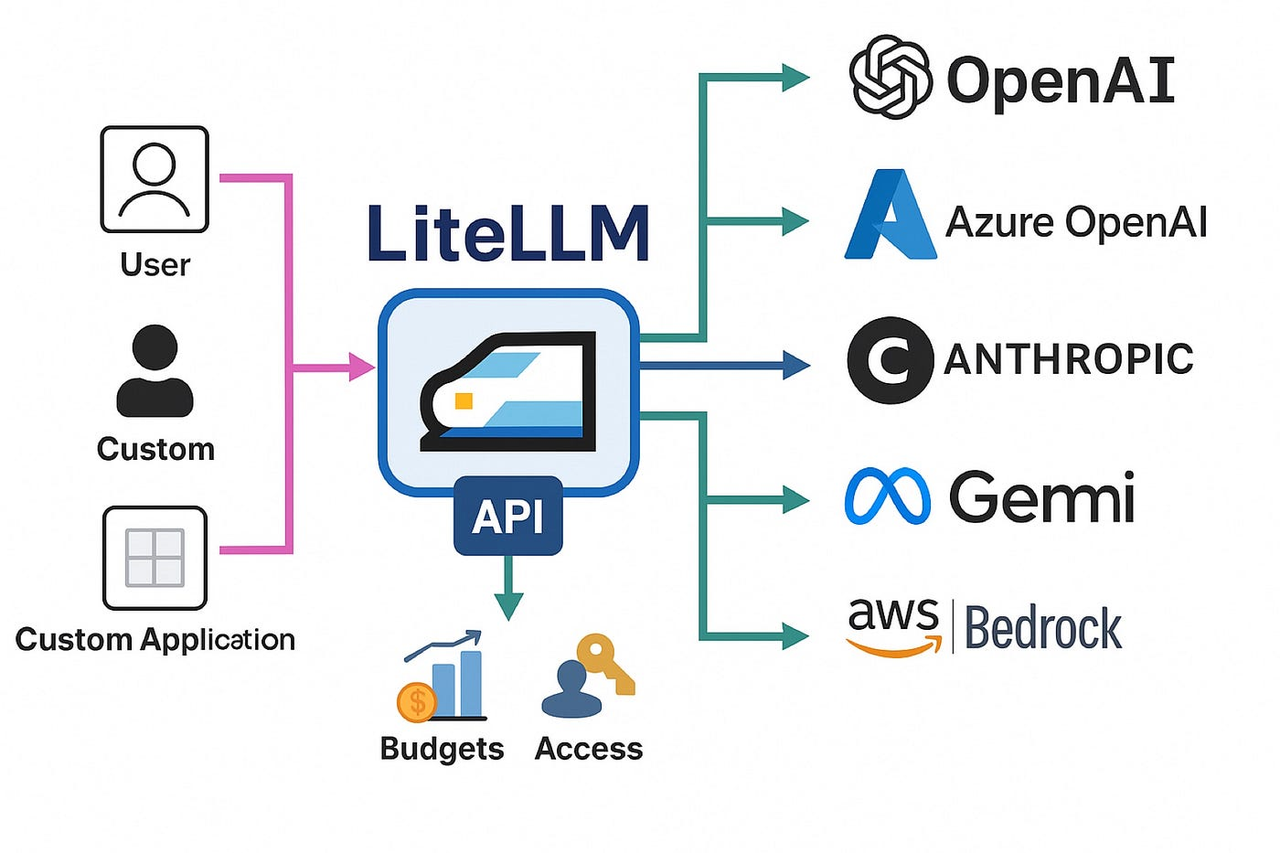
제조사마다 API 표준이 다릅니다. GPT, Claude, Llama의 성능을 비교하기 위해 각각 세 가지 요청 로직과 에러 처리 코드를 짜야 했던 시절이 있었습니다. 하지만 LiteLLM은 이러한 인터페이스를 표준화하여 모델 간의 매끄러운 전환을 가능하게 합니다.
from litellm import completion
# GPT-4든 Claude든 호출 로직은 완전히 동일합니다
def ask_ai(model_name, prompt):
res = completion(
model=model_name,
messages=[{"role": "user", "content": prompt}]
)
return res.choices[0].message.content
# 모델을 바꿀 때는 문자열만 수정하면 됩니다
print(ask_ai("gpt-4o", "RAG가 무엇인가요?"))
print(ask_ai("claude-3-5-sonnet", "RAG가 무엇인가요?"))이 방식은 코드의 결합도를 낮춰줍니다. 다만, 제조사가 고유 파라미터를 업데이트할 경우 LiteLLM이 이를 반영할 때까지 약간의 대기 시간이 생길 수 있다는 점은 유의해야 합니다.
MarkItDown: 다양한 문서를 Markdown으로 변환
문서 파싱은 정말 골치 아픈 작업입니다. 워드, 엑셀, PDF를 처리하기 위해 네 개의 라이브러리를 설치하고 각기 다른 에러를 처리해야 했습니다. Microsoft의 MarkItDown은 이 모든 문서를 LLM이 가장 선호하는 Markdown 형식으로 통일해 줍니다.
from markitdown import MarkItDown
md_converter = MarkItDown()
# PDF나 Excel 파싱
doc_result = md_converter.convert("annual_report.pdf")
table_result = md_converter.convert("budget.xlsx")
print(doc_result.text_content)제목과 표 구조를 비교적 잘 유지하여 데이터 정제 작업을 줄여줍니다. 단, 주로 텍스트 층을 처리하므로 스캔 문서나 복잡한 이미지 형태의 표에서는 성능이 달라질 수 있습니다.
LlamaIndex: 데이터와 LLM을 잇는 프레임워크
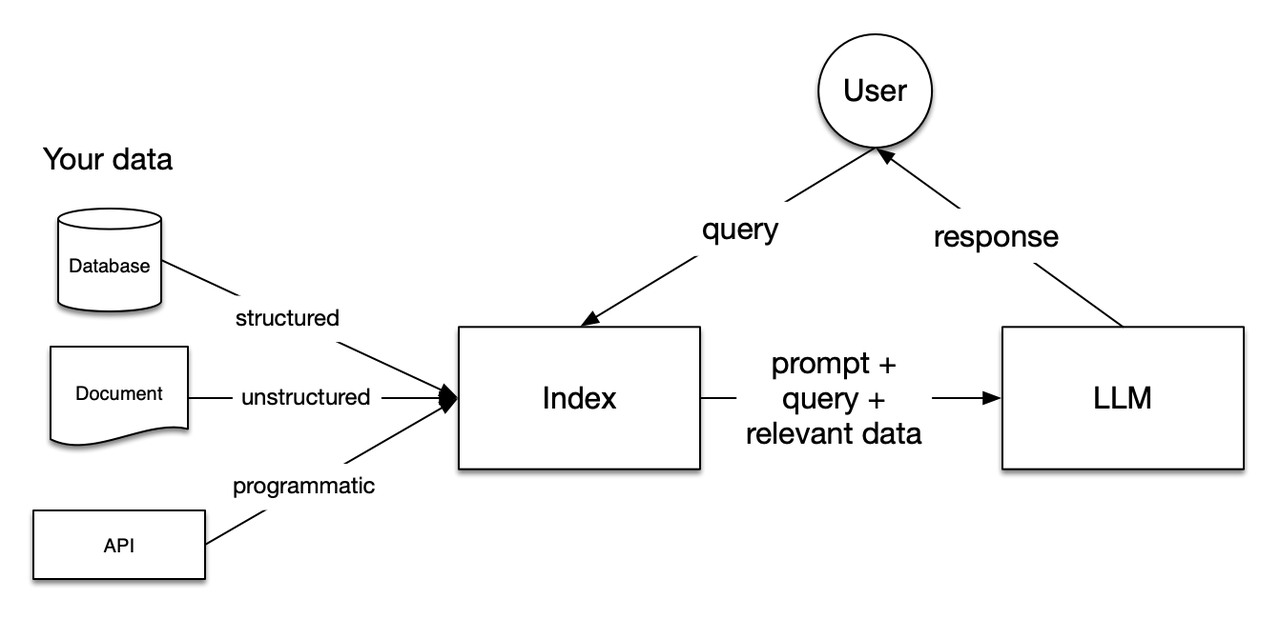
LlamaIndex(구 GPT Index)는 프라이빗 데이터를 LLM에 연결하는 문제를 해결하는 데 특화되어 있습니다. 문서 읽기부터 인덱스 구축, 쿼리 인터페이스까지 전체 프로세스를 제공합니다.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
# 디렉토리 내 모든 문서를 자동으로 읽어 인덱스 구축
data_docs = SimpleDirectoryReader("./docs").load_data()
data_index = VectorStoreIndex.from_documents(data_docs)
# 쿼리 엔진 생성
engine = data_index.as_query_engine()
print(engine.query("문서의 핵심 관점을 요약해 줘"))복잡한 문서 구조를 처리하고 RAG(검색 증강 생성) 시스템을 구축할 때 매우 견고한 성능을 보여주는 주류 데이터 프레임워크입니다.
PydanticAI: 타입 안전성 기반의 에이전트 개발
예전에는 AI가 JSON 형식으로만 응답해주길 간절히 바랐지만, AI는 꼭 서두에 "네, 요청하신 JSON입니다" 같은 말을 덧붙여 파싱 에러를 유도하곤 했습니다. PydanticAI는 데이터의 경계를 직접 정의하여 이 문제를 해결합니다.
from pydantic import BaseModel
from pydantic_ai import Agent
class AnalysisResult(BaseModel):
summary: str
score: float
analysis_agent = Agent(
"openai:gpt-4o",
result_type=AnalysisResult,
system_prompt="사용자 피드백을 분석하고 점수를 매기세요"
)
output = analysis_agent.run_sync("이 기능 정말 편해요, 업무 효율이 확 올라갔습니다")
print(output.data.summary)AI 호출을 타입 안전한(Type-safe) 함수 호출로 바꿔줍니다.
Marvin: AI 능력을 함수로 캡슐화
단순한 분류나 추출 기능이 필요한데 복잡한 프롬프트를 짜고 싶지 않을 때가 있습니다. Marvin을 사용하면 일반 함수를 작성하듯 AI 로직을 짤 수 있으며, 분류, 추출, 생성 작업에 매우 적합합니다.
import marvin
@marvin.fn
def generate_tags(description: str) -> list[str]:
"""
제품 설명을 바탕으로 3개의 태그를 생성합니다
"""
tags = generate_tags("고성능 알루미늄 노트북, 고속 충전 지원")
print(tags) # 출력 예: ['IT/가전', '사무용', '휴대성']기존 시스템에 AI 기능을 최소한의 코드 변경으로 통합할 수 있는 훌륭한 방법입니다.
Haystack: 엔드 투 엔드 검색 파이프라인
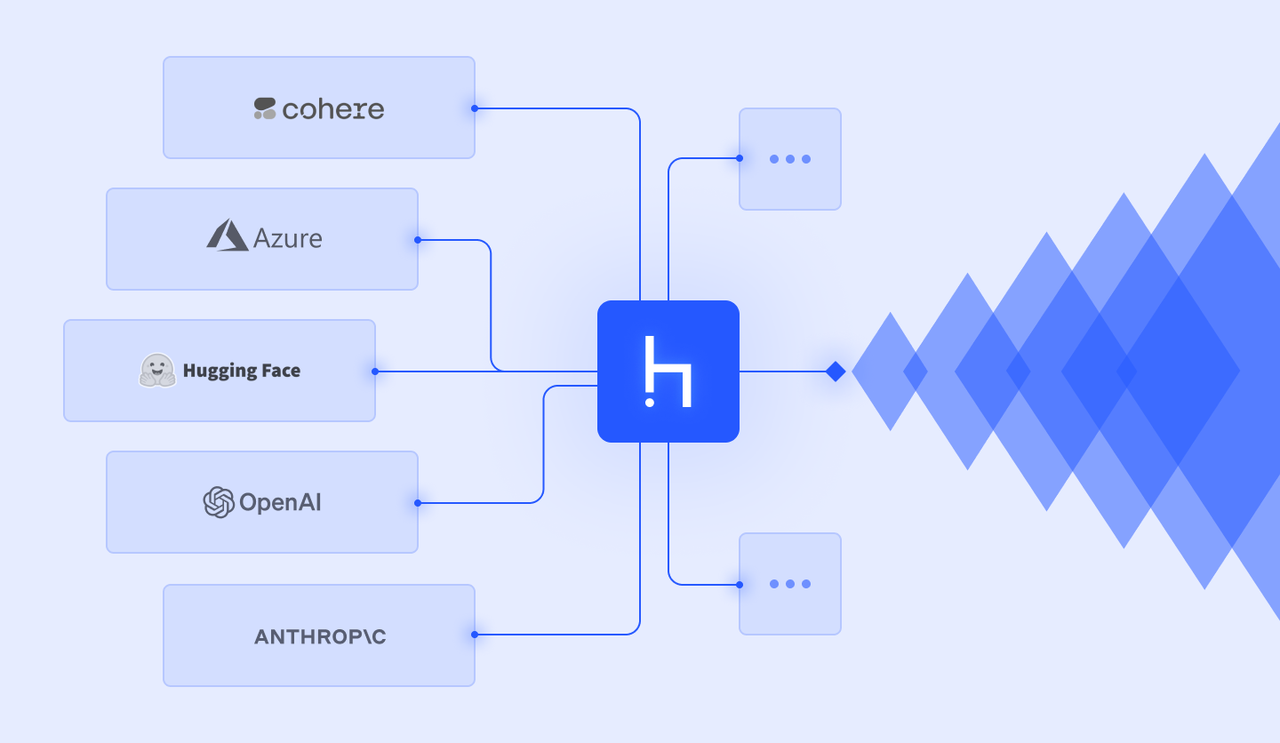
Haystack은 대규모 검색 시스템 구축에 적합합니다. Qdrant, Elasticsearch 등 다양한 벡터 데이터베이스를 지원하며, 검색, 정렬, 필터링을 레고 블록처럼 조합할 수 있습니다.
from haystack import Pipeline
from haystack.components.builders import PromptBuilder
from haystack.components.generators import OpenAIGenerator
# 파이프라인 노드 구성
query_pipeline = Pipeline()
query_pipeline.add_component("prompt_builder", PromptBuilder(template="질문: {{query}}"))
query_pipeline.add_component("llm", OpenAIGenerator(model="gpt-4o"))
query_pipeline.connect("prompt_builder", "llm")
res = query_pipeline.run({"prompt_builder": {"query": "Python을 어떻게 배우나요?"}})방대한 문서를 처리하고 시맨틱 검색을 구현해야 하는 애플리케이션에 뛰어난 확장성을 제공합니다.
tiktoken: 정확한 토큰 소모량 계산
재귀 로직으로 생성된 너무 긴 프롬프트 때문에 한 번의 호출에 1.5달러를 날린 적이 있습니다. 그 이후로는 요청 전 반드시 비용을 확인합니다. tiktoken은 매우 빠른 속도의 토크나이저로, OpenAI 모델의 비용 예측에 필수적입니다.
import tiktoken
tokenizer = tiktoken.encoding_for_model("gpt-4")
content = "테스트 텍스트의 토큰 수 확인"
token_list = tokenizer.encode(content)
print(f"토큰 수: {len(token_list)}")비용을 실시간으로 관리할 수 있게 해주어, 월말 청구서를 보고 놀랄 일이 없어집니다.
FAISS: 효율적인 벡터 유사도 검색
수십만 개의 데이터를 검색할 때 일반적인 선형 검색은 시스템을 멈추게 합니다. Meta가 오픈소스로 공개한 FAISS는 수억 개의 벡터 중에서도 쿼리와 가장 관련 있는 조각을 밀리초 단위로 찾아냅니다.
import faiss
import numpy as np
# 인덱스 초기화
vector_dim = 64
search_index = faiss.IndexFlatL2(vector_dim)
# 시뮬레이션 데이터 추가
mock_data = np.random.random((1000, vector_dim)).astype('float32')
search_index.add(mock_data)
# 검색 실행
distances, results = search_index.search(mock_data[:1], 3)현재 벡터 검색 분야의 표준 도구이며, 특히 로컬 환경 배포 시 뛰어난 성능을 보입니다.
Pydantic Evals: 프롬프트 회귀 테스트

예전에는 프롬프트를 수정할 때 '감'에 의존했습니다. 예시 한두 개 돌려보고 괜찮다 싶으면 배포했죠. 결과는 버그 하나 고치면 세 개가 더 생기는 식이었습니다. Pydantic Evals는 미리 설정된 케이스를 통해 자동화된 회귀 테스트를 실행할 수 있게 해줍니다.
from pydantic_evals import Case, Dataset
# 테스트 데이터셋 정의
eval_dataset = Dataset(
cases=[
Case(inputs="회사명 추출: 마이크로소프트가 새 시스템을 발표했다", expected_output="마이크로소프트"),
]
)
# 평가 실행 및 보고서 확인
results = eval_dataset.evaluate(your_extract_function)
results.print()이러한 확신은 상용 수준의 애플리케이션을 개발하기 위한 필수 전제 조건입니다.
요약
LiteLLM은 인터페이스를 통일했고, MarkItDown은 문서 처리를 간소화했으며, PydanticAI는 출력 품질을 보장합니다.
이 라이브러리들은 개발 효율을 미친 듯이 끌어올려 줍니다. 덕분에 개발 주기가 짧아지니 워라밸(Work-Life Balance)까지 챙길 수 있게 되었네요. 여러분도 지금 바로 적용해 보세요.
