https://arxiv.org/abs/1912.07753
Abstract
- LTV를 예측하는 것이 고객 중심적인 마케팅 전략을 구축하는데 도움을 줌 (CRM)
ex) 예측된 LTV에 따라 고객을 다양한 그룹으로 나누고 각 그룹의 고객에게
맞춤형 마케팅 제공 가능.
-
LTV 예측은 마케팅 예산 할당에 도움을 주고 RTB (real Time Bidding)를 개선함
:
RTB- 마케팅 용어, 실시간 온라인 광고 입찰 시스템을 말함
-
LTV 모델링이 어려운 점은 일부 고객은 돌아오지 않는다는 것과
Heavy-tailed distribution을 가질 수 있다는 것임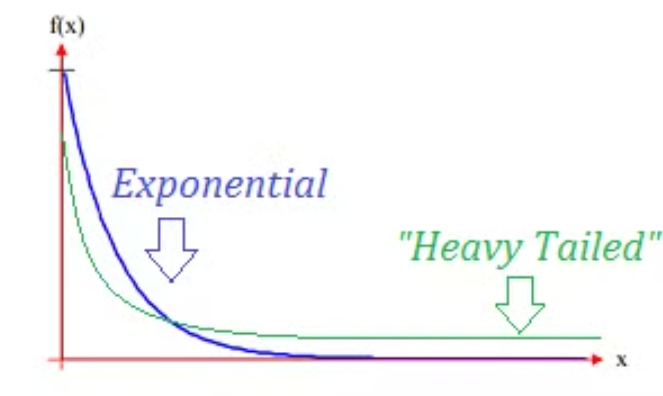
:
Heavy-tailed distribution- 지수함수보다 느리게 감쇠되는 꼬리를 가진 분포
-
그러나 잘 알려진 MSE는 LTV의 대부분을 차지하는 값이 0인 일회성 고객과
민감할 수 있는 충성 고객의 매우 큰 LTV 값을 고려하지 않음
-
따라서 관련된 특징에 대한 LTV 분포를 zero-inflated lognormal (ZILN) distribution 라고 하는 LTV가 0인 경우를 나타내는 제로 집중 부분과 로그 정규 분포의 혼합으로 모델링함
💡 즉, 이 분포는 일회성 고객으로부터의 제로 값 LTV를 고려하면서도 다른 고객들의 LTV 분포를 로그 정규 분포로 모델링하는 것
-
이 접근법은 고객 이탈 확률을 포착하고 LTV의 heavy-tailedness한 특성을 동시에 고려
-
성능 평가를 위해 정규화된 지니 계수를 추천하고 모델 교정을 위해 Decile charts 추천
Introduction
Abstract이랑 비슷한 얘기를 함
-
마케팅 예산 개선, 프로모션 제안, 충성도 보상 프로그램 및 화이트 글러브 서비스 제공 가능
:
화이트 글러브 서비스- 극진한 고객 맞춤 서비스
-
기존 고객의 LTV 예측의 발전은 대부분 RFM 프레임 워크의 확장과 관련되어 있음
:
RFM- Recency (최신성), Frequency (빈도), Monetary (금액)
- 가장 잘 알려진 접근 방법은 BTYD (Buy Till You Die) 모델로 이는 LTV 계산을 위해
과거 거래 데이터에 확률적 모델을 적용한 것임- BTYD
BTYD 모델은 아래와 같은 질문에 답을 해준다- 활성 고객은 몇 명인가
- 지금부터 N년 후에 얼마나 많은 고객이 활동 중일까
- 어떤 고객이 이탈했나
- 고객은 미래에 회사에 얼마나 가치가 있을까
- BTYD
주로 주문 테이블 (영수증 인 듯)과 RFM 지표를 활용함
그러나, BTYD 모델은 새로운 고객에게 적용되지 않음.
따라서 새로운 고객의 LTV 예측에는 다른 방법이 필요. 이 논문은 여기에 FOCUS 중임
지도 학습 회귀 (Supervised regression)
그래서 지도 학습 회귀를 사용함
- BTYD 모델과 달리 모든 수준의 고객 특성을 활용
- DNN 아키텍쳐 활용
그러나 개별 고객의 LTV를 정확히 예측하는 것은 어려운 작업임.
두 가지 문제가 있는데
- 많은 고객이 일회성 고객이며 다시 구매하지 않으므로 zero 값 레이블이 있음
- 되돌아오는 고객의 LTV는 변동이 크며 LTV 분포는 매우 치우쳐 있음
이를 해결하기 위해 ZILN loss를 제안
ZILN loss는 제로 값 및 극단적으로 큰 LTV 레이블을 처리함
DNN Model With ZILN Loss
그림은 전형적인 비대칭 LTV 분포로 대부분의 온라인 광고 고객의 LTV 분포를 나타낸다.
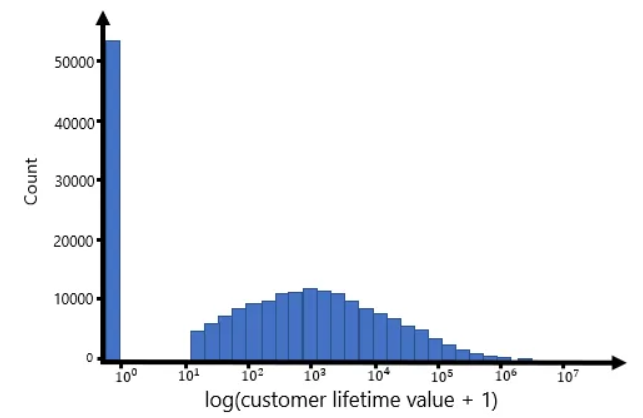
- LTV = 0에서의 큰 수는 일회성 고객의 비율을 보여줌
- 돌아오는 고객을 가시적으로 강조하기 위해 x축을 (LTV + 1)의 로그 값으로 표시함
이는 돌아오는 고객의 주기 범위가 상당히 넓다는 것을 알 수 있음
- 이러한 분포는 일회성 고객의 비율이 크고 일부의 충성 고객으로 구성되어 있어 전통적인 MSE loss 방식에 어려움을 제공함
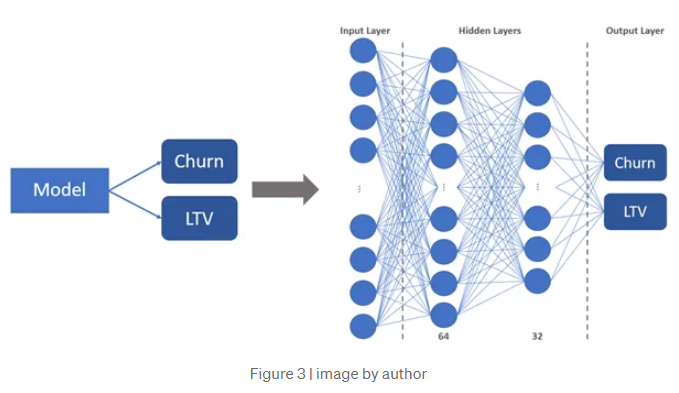
일반적으로 LTV 및 이탈 모델링은 별도로 수행되나 (그림 왼쪽) ,
이 논문은 DNN을 이용하여 동시에 고객 이탈과 LTV 예측을 다루도록 함 (그림 오른쪽)
MSE Loss
MSE는 고액 지출 고객에 대한 예측 오류를 과도한 패널티를 부여할 수 있음
이는 모델을 이상치에 민감하게 만들어 훈련을 불안정하게 함
MSE 손실을 Quantile loss (분위수 손실)로 교체하면 이상치 문제가 완화되지만,
모델은 주로 요구되는 LTV의 평균을 예측하지 못할 수 있음 !
ZILN Loss
따라서 ZILN 분포에 음의 로그 우도를 취하여 혼합된 loss를 유도함
이러한 loss는 구매 경향성과 특정 기간 동안 고객이 기업에게 제공하는 예상 수익을
동시에 학습시키는 것을 가능하게 함
로그 정규 분포 (lognormal distribution)
long tail의 양수 값만을 갖는 로그 정규분포는 돌아오는 고객의 LTV 분포를 모델링하기 좋음
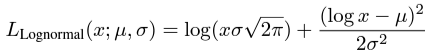
수학적으로 로그 정규분포의 손실인 은
평균 와 표준 편차 를 갖는 로그 정규분포의 음의 로그 우도로 유도됨
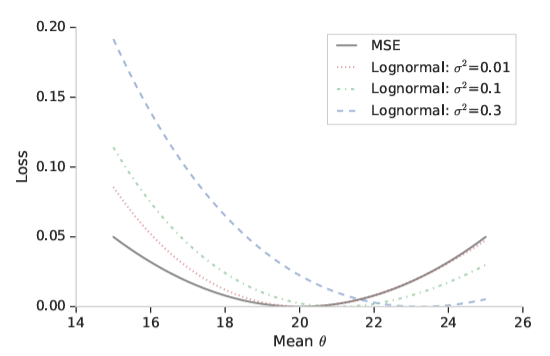
MSE loss와 로그 정규분포 loss를 y축, 평균 를 x축으로 하는 함수로 비교해 보면
특정 관측값 ()에 대해 MSE는 관측값 주변에서 대칭적으로 패널티를 부과하는 반면,
로그 정규분포 loss는 큰 값에 대해 패널티를 덜 부과함. argmin은 가 증가함에 따라 증가함
argmin: y값이 최소가 되는 x값
이는 로그 변환된 에 대한 가중 MSE로 볼 수 있으며 여기서 표준 편차 가 가중 역할을 함
더불어, 표준 편차 는 평균 µ와 마찬가지로 입력 특성에 따라 달라질 수 있고
이는 LTV에 대해 이분산성 로그 정규 분포 (Heteroscedastic lognormal)를 함축한다
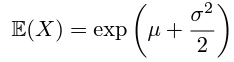
: 의 좋은 추정치를 얻는 것은 평균 예측의 편향에 직접적으로 영향을 미치므로 매우 중요
ZILN loss는 ZILN 분포된 확률 변수의 음의 로그 우도로 유도될 수 있으며
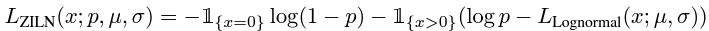
- : 0이 아닌지 여부의 확률
ZILN loss는 두 개의 의미로 해석할 수 있다
- 고객이 재방문 고객인지 여부에 대한 분류 손실
- 반복 고객의 LTV에 대한 회귀 손실
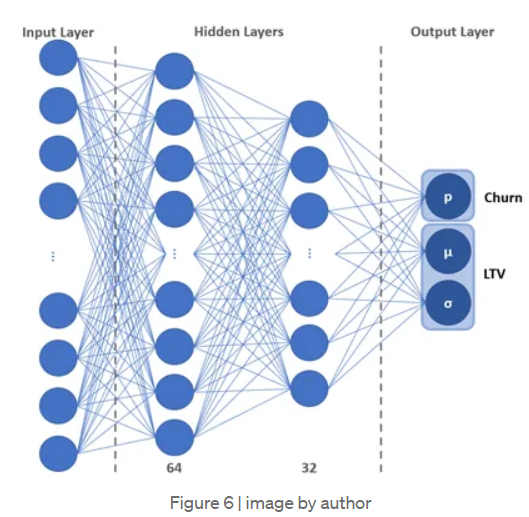
ZILN loss를 가진 DNN 네트워크 구조
- : 돌아온 고객의 확률 (고객 이탈 여부)
- , : 돌아온 고객의 LTV에 대한 로그 정규 분포의 평균과 표준편차
DNN의 마지막 레이어 (블랙)
세 개의 사전 활성화된 로짓 유닛을 가지고 있으며 각각 , , 를 개별적으로 결정한다
세 가지 활성화 함수는 시그모이드, 항등 함수, 그리고 소프트 플러스.
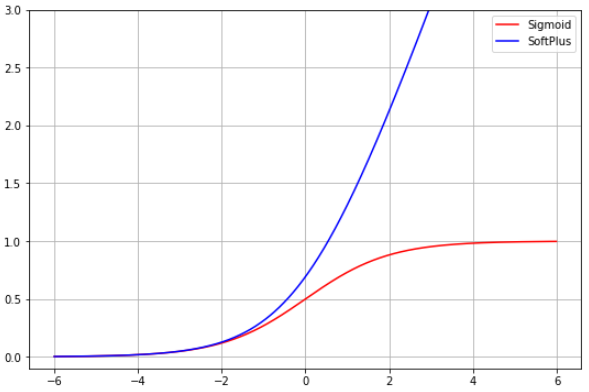
항등 함수는 다 아니까 pass
& 시그모이드
: 시그모이드는 출력 값의 범위가 0에서 1 사이이기 때문에 확률을 예측하기 적합
일반적인 임계값은 0.5로 0.5보다 낮은 값은 돌아온 고객을 의미하며
0.5보다 높은 값은 손실되었다고 예측한다
& 항등 함수
: 유닛은 범위나 부호에 제한이 없으므로 항등 함수를 사용하였음
이는 활성화 함수를 쓰지 않고 단순히 유닛의 예측 값을 출력한다는 의미임
& 소프트 플러스
: 는 양수만 반환 해야함. 지수 함수도 양수 제약 조건을 해결할 수 있지만 기울기가 가파르기
때문에 그래디언트가 쉽게 폭발할 수 있음. 따라서 gradient clipping을 적용한 소프트플러스 사용
- gradient clipping
경사 클리핑 (gradient clipping)은 신경망에서 발생할 수 있는 그래디언트 폭주 문제를 완화하기 위한 기법 중 하나로 일정한 임계값을 설정하고 그래디언트가 임계값을
초과할 경우 그 값을 자르는 방식으로 작동한다
DNN의 중간 레이어 (노랑)
본질적으로 두 가지 작업과 관련되어 있으며 이는
- 돌아온 고객의 분류를 예측
- 돌아온 고객의 지출을 예측
이 아키텍처는 각 작업에 대해 모델이 더 잘 일반화되도록 장려하며 multi-task learning의
핵심 아이디어를 공유함 (Ruder, 2017).
ZILN loss의 또 다른 주요 장점은 , 를 통해 전체 예측 분포를 제공한다는 것임
우리는 돌아온 고객의 확률뿐만 아니라 돌아온 고객의 LTV 값 분포도 얻을 수 있음!
평균 LTV 예측에 추가로 LTV 예측의 불확실성은 일반적인 분위수 회귀
(quantile regression)처럼 로그 정규 분포의 분위수를 사용하여 평가할 수 있음
Evaluation Metrics
AUC
AUC는 ROC curve 아래의 면적을 나타내는 지표로
돌아오는 고객 대 돌아오지 않는 고객의 이진 분류 문제에서 일반적으로 사용됨
- ROC curve 이진 분류기의 성능을 표현하는 곡선으로 가능한 모든 threshold에 대해 FPR과 TPR의 비율을 표현
- 즉, AUC는 평가 중인 분류기가 돌아오는 고객이 돌아오지 않는 고객보다 더 높은 것을 올바르게 예측할 수 있는 확률.
- AUC는 0.5 - 1 사이에 위치하며 값이 높을수록 모델이 돌아올 고객을 올바르게 판단하는데 더 뛰어나다고 해석
LTV 모델의 성능 평가
-
과거에는 실제 LTV와 예측된 LTV 간의 피어슨 상관관계를 사용하여 성능을 평가
- 그러나 이 측정치는 데이터의 이상치에 민감할 수 있음
-
따라서 요즘은 스피어만 순위 상관관계를 사용합
-
LTV 모델의 성능을 평가할 때 두 가지 측면에서 접근함
- 모델의 구별력 : 충성 고객을 나머지 고객과 구별하는 모델의 능력
- 모델의 보정도 : 실제와 예측된 LTV 간의 일치를 의미
- 모델의 구별력 : 충성 고객을 나머지 고객과 구별하는 모델의 능력
Model Discrimination (모델 구별력)
Donkers 등은 hit-rate 지표를 제안한다.
Hit-rate measure
이는 예측된 LTV가 실제 LTV와 동일한 범주에 속하는 고객의 백분율로
예를 들어, 상위 25% 가치의 고객의 LTV가 200 이상이라면 Hit-rate는 이러한 고객 중 몇 명의
LTV를 200 이상으로 예측했는지를 count
순서 기반의 Hit-rate measure
실제 LTV를 기준으로 예측된 LTV의 상위 25%에 속하는 고객의 수를 count 하는 방식
우리는 Hit-rate level을 구체적으로 지정하지 않고 Hit-rate를 일반화하는 지표를
사용할 건데 그게 지니계수
Gini coefficient (지니 계수)
지니 계수는 주로 경제학에서 소득의 불평등을 측정하는데 사용됨
- 지니 계수와 로렌츠 곡선
로렌츠 곡선
인구의 누적 비율을 x축에 소득의 누적 점유율을 y축에 놓고 이들의 관계를 그린 곡선
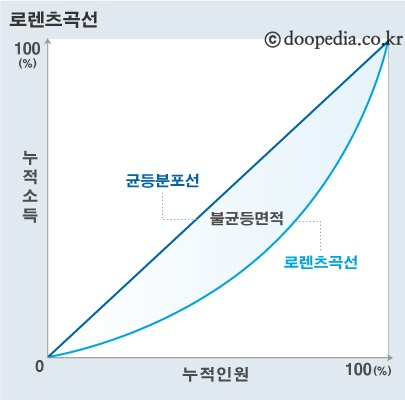
지니 계수
지니 계수란 불평등 면적을 로렌츠 곡선 상의 전체 직각삼각형 (ABC)로 나눈 값을 의미
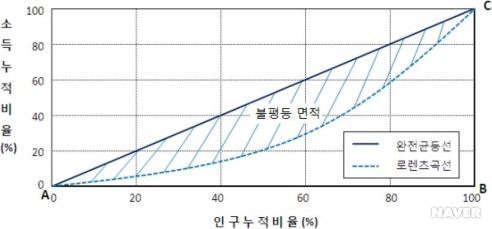

: 불평등면적이 0이면 완전히 평등한 경제를, 1이면 완전히 불평등한 경제를 의미
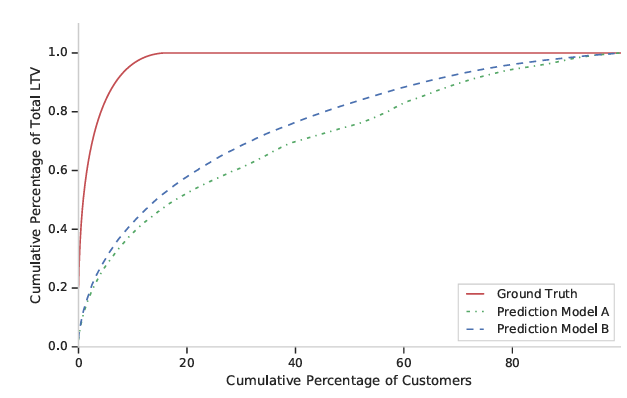 이는 이익 곡선으로 두 가지 예측 모델 A와 B를 비교.
이는 이익 곡선으로 두 가지 예측 모델 A와 B를 비교.
- 각 점 은 예측된 상위 %의 고객이 전체 수익의 %를 기여한다는 것을 나타냄
- 모델 A는 모델 B보다 고객을 구별하는 데 더 우수함 : 모델 곡선이 로렌츠 곡선에 가까울수록 모델이 고객을 구별하는 데 더 우수
- 실제 값은 고객의 실제 LTV에 따라 정렬하여 구성된 로렌츠 곡선을 나타낸다
지니 계수는 세 단계로 계산된다
-
실제 LTV를 내림차순으로 정렬
: 기존 정의는 오름차순이지만 충성 고객에 대한 직관적인 해석을 위해 변경
-
로렌츠 곡선을 그림
: 누적된 전체 LTV(세로축)에 대한 누적된 고객 백분율(가로축)을 의미
곡선 상의 한 점 (x, y)은 상위 x %의 고객이 전체 고객 가치의 y %를 차지함을 의미
-
지니 계수
: 로렌츠 곡선과 45도 대각선 선 사이의 면적의 두 배로 이는 고객의 임의 정렬을 의미
- 지니 계수는 이진 분류기의 경우, 2 * AUC - 1을 한 것임
- 지니 계수는 예측의 순위에만 기초하며 모델 보정도에 민감하지 않은데 이는 특히 예측된 LTV를 기반으로 고객을 분류하는 경우에 유용함
- 정규화된 지니 계수는 특정 Hit-rate level을 지정할 필요가 없음
기준 지니 계수 (baseline Gini coefficient)
: 단계 1에서 실제 LTV 대신 첫 번째 구매 값으로 대체하여 세 번째 유형의 지니 계수를 계산한 것
- 첫 번째 구매 값과 LTV 간의 높은 상관 관계로 인해 기준 지니 계수는 합리적이고 실용적인 하한선으로 간주됨
- 이후에는 고객 속성, 첫 번째 구매의 메타 데이터, 그리고 비구매 행동과 같은 다른 예측 신호를 추가함으로써 기준 지니 계수를 개선할 수 있음
Model Calibration (모델 보정도)
이진 분류 문제에서는 연속 확률 예측을 출력하는 소프트 분류기를 평가하기 위해
보정 그래프가 널리 사용됨
- 보정 그래프
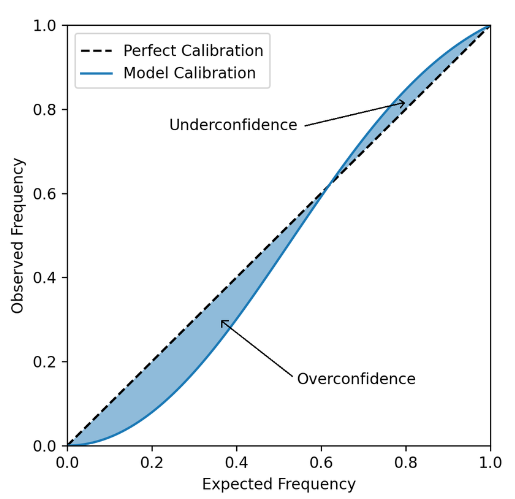
x축에 예측된 확률을, y축에는 positive 레이블의 비율을 나타내는 적합성 판단 그래프
예를 들어, 충성 고객일 확률이 20%로 예측된다면 해당 예측을 받은 100명 중 약 20명이
충성 고객이어야 하고 완벽한 예측은 위에 있어야 함.
Decile chart (십분위 차트)
: 각 예측 십분위에 대해 평균 예측과 평균 레이블을 비교하는 차트
회귀 문제에서 보정 그래프는 예측된 값과 실제 값 간의 산점도로 나타낼 수 있음
그러나, LTV 문제와 같이 레이블이 매우 치우친 분포를 가질 때 산점도는 작은 예측 영역의
보정을 설명하기 어려울 수 있음.
따라서, 예측의 십분위로 레이블을 plot하는 십분위 차트를 사용
이때 잘 보정된 모델은 각 예측 십분위에 대해 예측 평균이 레이블 평균과 유사
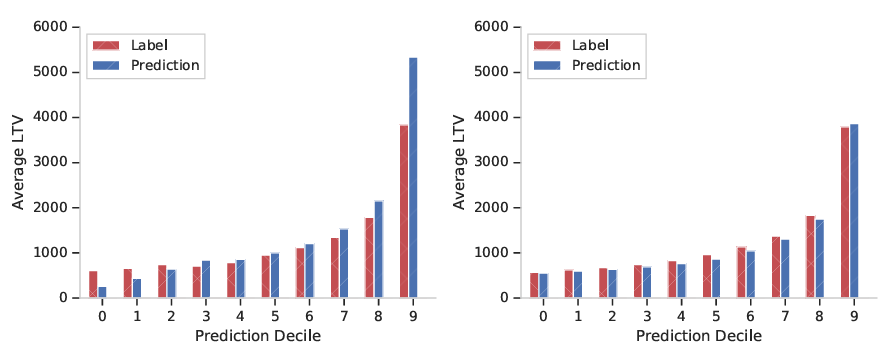
Decile chart (십분위 차트)의 예시.
- 왼쪽은 높은 10분위에서 과대예측되고 낮은 10분위에서 과소예측되는 나쁜 보정의 예
- 오른쪽은 각 10분위별로 예측된 LTV가 실제 LTV와 유사하게 일치하는 좋은 모델 보정
- 또한, Decile chart는 모델의 구분력을 질적으로 평가함
: 좋은 구분력을 가진 모델은 십분위 간의 차이가 크다
MAPE (평균 절대 백분율 오차)
MAPE는 Mean Absolute Percentage Error의 약자로 예측 오차의 크기를 상대적으로
측정하는 지표로 회귀 모델 성능 평가 지표이다
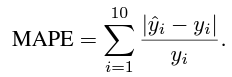
- : i 번째 예측 십분위에 있는 고객들의 레이블 평균
- : i 번째 예측 십분위에 있는 고객들의 예측
- : 샘플 수
MAPE가 낮을수록 모델의 예측이 실제 값과 가깝다고 해석할 수 있음
Data Experiments
Kaggle acquire valued shoppers challenge
-
데이터셋은 33,000개 회사의 311,000명 고객에 대한 쇼핑 이력을 포함
-
초기 구매 이후 다음 12개월 간 각 고객의 총 구매 가치를 예측하는 작업 진행
-
모델의 특징은 초기 구매 금액, 구매된 항목 수, 그리고 각 개별 구매된 항목의 가게 체인,
- 제품 카테고리, 제품 브랜드 및 제품 크기 측정치를 포함
-
고객 수에 기반하여 상위 20개 회사로 실험을 제한하고 각 회사에 대해, 모델 훈련을 위해 고객의 80%를 임의로 선택하고 나머지 20%를 모델 평가에 사용
-
모델 아키텍처와 손실 함수를 기준으로 실험 진행
- 선형 및 DNN 모델
- ZILN 손실을 MSE 손실과 비교
- 추가로, 돌아온 고객 예측의 이진 분류 결과를 보고
Spearman’s Correlation
- ZILN loss는 Linear의 경우 평균적으로 약 23.9% 높고
DNN의 경우 약 48% 높은 스피어만 상관 관계를 보여줌
- ZILN loss의 경우 Linear 모델에 비해 DNN이 평균적으로 2.2% 정도 높음
Model Discrimination
4가지 모델과 기준 모델에 대한 정규화된 지니 계수를 요약
- 기준 모델은 초기 구매 가치에 따라 고객이 순위가 매겨진 것임
- 기준 모델 대비 평균적으로 DNN-MSE는 10.6%, DNN-ZILN은 23.1%,
선형-ZILN은 21.3% 향상 - 선형-MSE 모델은 이상치 존재로 인한 미니 배치 수렴 문제로 인해
일부는 성능이 더 떨어짐 - ZILN loss는 선형 (28.6%) 및 DNN (11.4%) 모두에서 MSE loss를 능가
Model Calibration
네 가지 모델에 대한 Decile-level MAPE를 보여줌
- ZILN 손실은 MSE 손실보다 낮은 Decile-level MAPE를 보임
- 선형 모델에서는 60.0% 감소하고 DNN에서는 68.9% 감소함
- ZILN 손실을 사용시 DNN이 선형 모델보다 Decile-level MAPE를 추가로 5.3% 감소
Returning Customer Prediction
이진 분류 작업인 돌아온 고객 예측의 AUC_PR을 보여줌
- ZILN은 표준 Binary Cross Entropy (BCE) 손실과 유사한 성능을 보임
- AUC_PR : 돌아온 고객 예측에 대한 Precision-Recall Curve의 면적
KDD Cup 1998
-
지난 12개월 동안 기부를 중단한 사람들을 대상으로 함
-
데이터셋에는 1997년 메일링을 받았지만 직전 12개월 동안 기부를 하지 않은
약 20만 명의 이전 기부자가 포함되어 있음
-
1997년 메일링 캠페인에 대한 기부 달러 값을 예측 !
-
레이블에는 zero와 positive 기부값이 혼합되어 있음
-
약 95%의 중단된 기부자가 1997년 메일링 캠페인에 응답하지 않아 zero lable 값을 부여
-
나머지 5%의 중단된 기부자 중에서는 positive 기부값의 분포가 로그 스케일로 나타남
log scale from the 5% lapsed donors
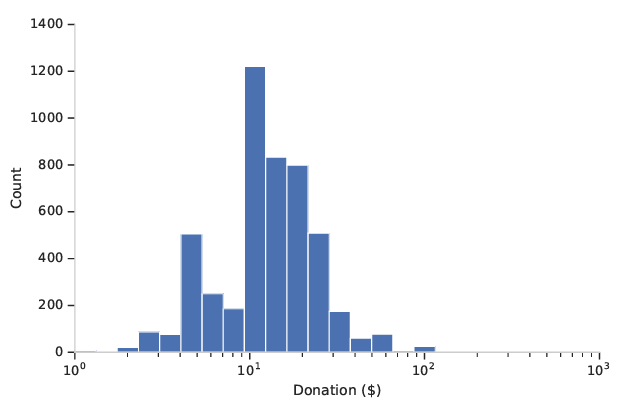
5% 중단된 기부자들의 positive 기부값의 분포를 로그 스케일로 나타낸 그래프
- MSE 손실과 비교하여 ZILN 손실은 스피어만 순위 상관 관계가 더 높다 (0.027 vs 0.020)
- 모델 구분력 측면에서 ZILN 손실은 정규화된 지니 계수가 더 높다 (0.190 vs 0.184)
- ZILN 손실은 모델 보정에서도 MSE보다 MAPE가 더 작다 (0.176 대 0.210)
우수한 성능을 보여줌
Conclusion
-
LTV 예측이 다양한 마케팅 결정에 어떻게 영향을 미칠 수 있는지 확인
-
DNN을 사용하여 고객 속성 및 구매 메타데이터를 기반으로 새로운 고객의 LTV를 예측
-
ZILN loss는 zero values와 heavy-tailed values를 혼합한 것임
-
모델 구분력을 위해 정규화된 지니 계수를,
모델 보정도를 평가하기 위해 십분위 차트를 추천
