'싱송생송' 프로젝트를 Go언어로 구축을 하기 위해서 Go에 대해서 조금더 자세하게 공부를 해야겠다는 생각을 하게 되었고 여러가지 블로그, 공식문서, Repo등을 참조해 가면서 공부를 하게 되었다. 다음은 Go언어를 공부하면서 정리하게 된 내용이다.
Go언어
"Build simple, secure, scalable systems with Go"
- An open-source programming language supported by Google
- Easy to learn and great for teams
- Built-in concurrency and a robust standard library
- Large ecosystem of partners, communities, and tools
라고 공식홈페이지에 설명이 되어있다.
GO언어의 장점
- 키워드 수가 적고 문법이 단순하여 배우기 쉽다
- 프로그램 안전성
- 고루틴을 통해 동시성 쉽게 관리하여 대규모 서버와 분산 시스템에서 사용하기에 유리하다
- 컴파일 속도 가 빠르고 효율적이다
- 빠른 애플리케이션 시작 시간, 재시작이 필요한 경우 빠르게 복구가 가능하다
- GC(Garbage Collection)가 있어서 높은 성능을 유지하면서 코드 관리가 용이하다
- 멀티코어 CPU를 잘 활용 할 수 있다,
- Goroutine + Channel - 언어 표현이 단순하다
- 애플리케이션 프로파일링, 메트릭 수집 등 표준 라이브러리에 포함되어 있어서 서비스 운영에 필요한 세부 모니털이과 성능 튜닝에 용이하다
GO언어의 아쉬운점
- 에러처리가 번거롭다
- GC는 대규모 힙을 가진 시스템에서는 성능저하를 일으킬 수 있다
- 다른 언어 대비 Generic 사용이 제한적이다
- 표준화된 개발 방법론이 서비스 개발에 강제되지 않았다. 사람에 따라 코드 작성 방식이 다를 수 있다
출처: Golang 도입, 그리고 4년 간의 기록 - 변규현, 당근마켓 | GopherCon Korea 2023
특징
- 클래스가 존재하지 않는다. 대신 메서드를 정의한 인터페이스를 생성하고, 메서드가 해당 타입의 인스턴스에 '속해 있는'것처럼 구현하여 다형성을 적용.
이때 func 키워드와 함수명 사이에 구조체 선언하여 구조체와 메서드를 연결할 수 있는데, 이를 리시버라고 한다(receiver)
type SampleStruct struct {
Name string
Data map[string]string
}
// 리시버로 구조체와 인터페이스의 메서드를 연결하여 다형성을 적용
func (s SampleStruct) SampleMethod() {
fmt.Println("implement sample method")
}
func (s SampleStruct) GetName() string {
return s.Name
}출처: 업무에 손쉽게 Golang 적용하기: 로케이션 코어팀 백엔드 개발자가 일하는 방식
- 개발 방법론이 유연함
- 사람마다 코드 작성 방식이 다르다
- Error처리
- Go에는 Exception이 없다
- Error는 Go의 철학을 보여주는 예시이다.
- Error 는 Go 의 철학을 보여주는 한 예입니다. Go 에서는 Exception 이 없습니다. Exception 은 만들어진 장소에서 처리되지 않는다면 GOTO 문과 같아 코드를 읽기 어렵게 만듭니다. 대신, Go 는 Error 를 값으로 취급해 항상 리턴하도록 하여 코드가 어떤 예외 처리를 하는지 알기 쉽게 만듭니다. 사실 Exception 을 즉시 처리되어야 하는 것으로 본다면, 다른 곳에서 처리되야 할 이유가 없습니다.
- 통일성
Go 는 25개의 키워드로만 구성되어 있습니다. 문법이 간단하므로 idiomatic 한 코드를 작성하기 쉽고, 완성도 높은 gofmt 를 만들 수 있습니다. 우스갯소리로, 어느 누구도 gofmt 의 스타일을 좋아하지 않는다는 이야기도 있지만, 적어도 통일성 있는 스타일링을 사람의 도움 없이 기계적으로 수행할 수 있습니다.
자세하게 공부해봐야할 내용들
Go언어를 공부를 함에 있어서 여러가지 내용들이 있는데 여기서 내가 프로젝트를 진행하면서 궁금했던 점에 대해서 공부를 진행해보기 위해 리스트업을 해보았다.
- concurrency: goroutine, channel
- interface and struct
- defer, panic and recover
- garbage collection
- context package
- memory management
- test
오늘은 한번 고루틴과 채널에 대해서 공부를 해보자
Concurrency: goroutine, channel
goroutine이란 무엇인가?
lightweight thread managed by the Go runtime
출처: A Tour of Go - Concurrency
라고 합니다
실행하는 방법은 간단하게 go라는 명령어를 붙여 실행을 합니다
func say(s string) {
for i := 0; i < 5; i++ {
time.Sleep(100 * time.Millisecond)
fmt.Println(s)
}
}
func main() {
go say("world")
say("hello")
}Goroutine이 왜 좋은지 알아보자!
-
적은 메모리 사용
- 고루틴은 기본적으로 약 2KB의 스택 메모리를 사용하고 필요에 따라 자동으로 증가한다.
(일반 OS 스레드가 1MB 스택을 할당하는 것에 비해 훨씬 적은 메모리로 시작한다.)
- 고루틴은 기본적으로 약 2KB의 스택 메모리를 사용하고 필요에 따라 자동으로 증가한다.
-
낮은 오버헤드
- 고루틴은 가볍고 작은 단위로 스케줄링된다. Go 런타임은 프로그램 실행 시 여러 OS 스레드를 미리 만들어 두고, 필요할 때 고루틴을 할당해 실행한다.
- Go 스케줄러는 고루틴 간 전환을 커널이 아닌 사용자 모드에서 처리해서 컨텍스트 전환 비용을 줄인다.
- 덕분에 수천에서 수만 개의 고루틴을 동시에 효율적으로 관리할 수 있다.
-
Go 런타임 스케줄러의 최적화
- Go 스케줄러는 M:N 모델을 사용해 여러 고루틴을 소수의 OS 스레드에 매핑해서 관리한다. 이렇게 하면 자원을 효율적으로 활용할 수 있다.
Go 스케줄러는 고루틴을 어떻게 관리할까?

- G (Goroutine): 고루틴을 나타낸다. Go 런타임은 각 고루틴의 상태와 스택 포인터 등 필요한 정보를 저장해 스케줄링에 사용한다. 고루틴은 LRQ(Local Run Queue)에서 대기한다.
Go Runtime? 😀
Go 런타임: 고루틴을 포함한 Go 프로그램의 실행을 관리하는 시스템. 메모리 관리, 스케줄링 등 Go의 모든 시스템 레벨 기능을 제공하고 최적화한다.
-
M (Machine): 논리적인 OS 스레드로, POSIX 스레드와 같다. M은 P로부터 고루틴(G)을 받아 실행하며, OS 스레드와 고루틴을 연결하는 역할을 한다.
-
P (Processor): 스케줄링 컨텍스트 정보를 가진 논리적인 프로세서다. 프로그램이 실행될 때
GOMAXPROCS환경 변수로 설정된 개수만큼 생성된다. P는 LRQ에서 고루틴을 가져와 M에 할당한다. 각 P가 하나의 LRQ를 가지기 때문에 레이스 컨디션을 줄이고 고루틴을 더 효율적으로 관리할 수 있다. -
LRQ (Local Run Queue): 각 P에 속한 큐로, 실행 가능한 고루틴들이 대기하는 곳이다. P는 LRQ에서 고루틴을 하나씩 가져와 M에 할당한다.
-
GRQ (Global Run Queue): 모든 P에 속하지 못한 고루틴이 대기하는 큐다. 실행 가능한 고루틴이지만 P의 LRQ에 자리가 없을 때 GRQ로 들어간다.
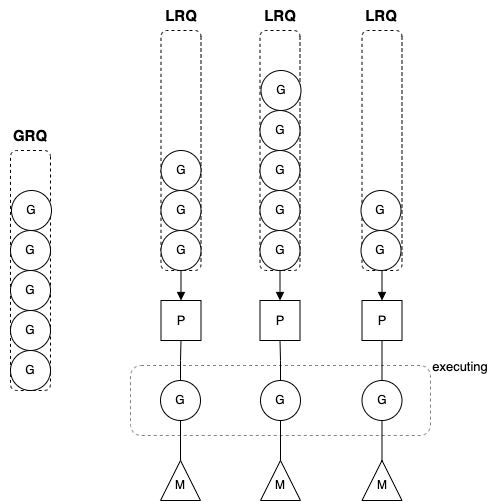
블로킹(Blocking)과 고루틴의 동작 방식
Go에서는 블로킹 작업(예: I/O 작업, 시스템 호출 등)이 발생하면 스케줄러가 고루틴을 다른 OS 스레드로 옮긴다. 이렇게 하면 블로킹 작업이 다른 고루틴에 영향을 주지 않고 프로그램이 계속 실행될 수 있다.
고루틴이 블로킹 작업을 끝내면 다시 P의 큐에 돌아오거나 GRQ로 이동해 대기한다. 이 방식 덕분에 Go 프로그램은 블로킹 작업이 있어도 다른 작업이 멈추지 않고 진행된다.
왜 다른 M(논리적 쓰레드) 가 아니라 다른 OS 스레드로 옮기는 것일까?
- Go 스케줄러가 고루틴의 블로킹 상태를 관리하면서도, 다른 고루틴들이 병렬로 실행될 수 있게 하기 위함
- 병렬성 유지
- 만약 한 고루틴이 M 위에서 블로킹되면 해당 M과 연결된 P가 멈추게 된다. P와 M은 계속 다른 고루틴을 실행할 수 있어 병렬성과 프로그램의 응답성을 유지
- 스케줄링과 블로킹 작업의 독립성:
- Go의 스케줄러는 OS의 스케줄러와 다르게 작동하며, 고루틴의 스위칭과 관리는 주로 Go 런타임에서 사용자 모드에서 이루어진다
- 블로킹 작업은 OS 레벨에서 관리되기 때문에, Go 런타임 스케줄러가 아닌 OS의 스케줄링에 따라 실행되는 독립적인 스레드에서 처리되는 것이 더 효율적
작업의 불균형 해결 - Work Stealing
만약 모든 M과 P가 대기 상태가 된다면, 스케줄러는 GRQ에서 고루틴을 찾아 실행한다. GRQ에도 실행할 고루틴이 없다면 다른 P의 LRQ에서 일부 고루틴을 가져오는 Work Stealing 기법을 사용해 각 P가 작업을 고르게 나누어 처리한다.
고루틴의 컨텍스트 스위칭
고루틴의 컨텍스트 스위칭은 다음과 같은 경우에 발생한다:
unbuffered channel에 접근할 때 (쓰기 또는 읽기)- 시스템 I/O가 발생했을 때
- 메모리 할당 시
time.Sleep()함수가 호출될 때runtime.Gosched()함수가 호출될 때
고루틴은 일반 스레드보다 컨텍스트 스위칭 비용이 낮다. 기존 스레드 전환에서는 여러 레지스터와 상태를 저장/복구해야 하지만, 고루틴은 3개의 레지스터(PC, SP, DX)만 저장 및 복원해서 전환한다.
=> 이것이 가능한 이유는 Go 런타임 자체가 스케줄링을 관리하므로 운영 체제 호출 없이 경량으로 전환 가능하기 때문이다.
Thread와 Goroutine의 레지스터 요구사항 비교
| 항목 | 기존 Thread | Goroutine |
|---|---|---|
| PC (Program Counter) | 현재 실행 중인 명령어의 위치를 저장 | 현재 실행 중인 명령어의 위치를 저장 |
| SP (Stack Pointer) | 현재 스택의 위치를 저장 | 고루틴의 독립적인 스택 위치를 저장 |
| DX (Data Register) | 함수 호출 시 데이터를 전달하고, 반환값을 담는 데이터 레지스터를 저장 | 함수 호출 시 데이터를 전달하고, 반환값을 담는 데이터 레지스터를 저장 |
| 일반 레지스터 | EAX, EBX, ECX, EDX 등 다수의 레지스터를 저장 | 필요 없음 (스택에 저장된 데이터로 대체) |
| 플래그 레지스터 | 실행 상태(예: 조건문 상태)를 나타내는 플래그 정보 저장 | 필요 없음 (Go 런타임에서 관리) |
| MMU 상태 | 메모리 관리 유닛(MMU)와 관련된 상태 정보 저장 | 필요 없음 (Go 런타임에서 관리) |
| FPU 레지스터 | 부동소수점 연산에 사용되는 레지스터 저장 | 필요 없음 (필요 시 함수 호출 시 처리) |
요약
- 기존 Thread: PC, SP, 플래그 레지스터, 일반 레지스터, MMU 상태 등 운영 체제가 요구하는 모든 정보를 저장/복구해야 함.
- Goroutine: Go 런타임에서 관리하기 때문에 PC, SP, DX만 필요하며, 나머지 상태는 스택과 런타임에 의해 처리됨.
고루틴의 설계는 최소한의 상태만 저장하여 경량화와 빠른 컨텍스트 스위칭을 가능하게 함. 😊
M:N 모델이란?
고루틴 스케줄링에 사용되는 M:N 모델은 여러 고루틴(M개의 유저 스레드)을 소수의 OS 스레드(N)에 매핑해 실행하는 방식이다.
-
사용자 레벨 스레드: 커널과 독립적으로 운영되며, 일반적으로 사용자 라이브러리를 통해 관리된다. 다만, 하나의 스레드가 중단되면 다른 스레드도 영향을 받는 단점이 있다.
-
커널 레벨 스레드: 커널이 직접 스레드의 스케줄링을 관리한다. 하나의 스레드가 중단되어도 다른 스레드는 계속 실행된다.
-
혼합형 스레드 모델: 여러 유저 레벨 스레드를 가벼운 프로세스(LWP)가 관리하며, 각 LWP는 커널에 의해 스케줄링된다. 사용자 스레드의 장점과 커널 레벨의 병렬성을 모두 활용할 수 있다.
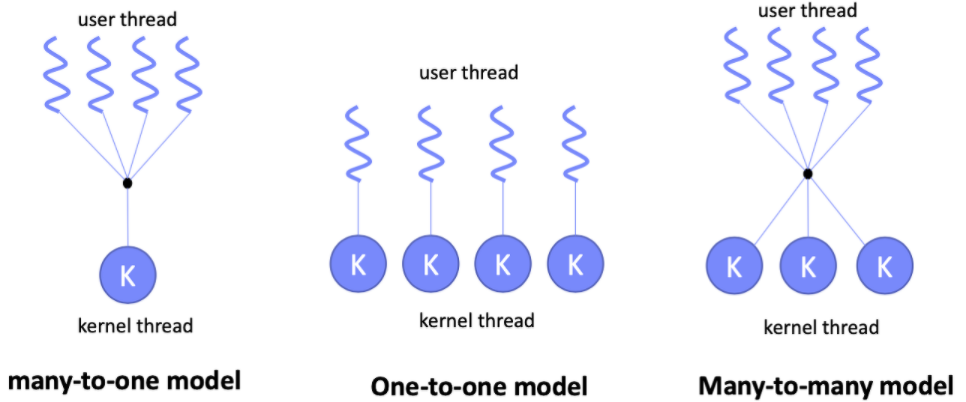
Scheduler Activation
커널이 유저 레벨 스레드를 지원하기 위해 Scheduler Activation 방식을 사용한다. 커널이 사용자 스레드가 필요할 때 정보를 주고받아 스케줄링과 블로킹을 감지한다.
OS 쓰레드와 고루틴의 메모리 비용 차이
- OS 쓰레드는 생성 및 삭제 시 많은 리소스를 소모한다. 스레드가 종료되면 리소스를 OS에 반환해야 하므로, 스레드를 직접 생성/삭제하는 대신 스레드 풀을 사용해 문제를 해결한다.
- 고루틴은 필요한 레지스터와 최소한의 상태 정보만 저장하므로 스택 메모리 사용량이 적고 컨텍스트 스위칭 비용도 낮다. 기존의 스레드 전환은 다양한 레지스터와 메모리 상태를 저장/복구해야 하지만, 고루틴은 최소한의 레지스터 정보(PC, SP, DX)만 사용해 전환한다.
정리를 해보자면..
Go의 고루틴은 Go 런타임이 제공하는 경량 스레드로, OS 스레드보다 메모리와 전환 비용이 적어 수천~수만 개의 동시 작업을 효율적으로 관리할 수 있다. G-M-P 모델을 기반으로 스케줄링을 최적화하며, Work Stealing과 Blocking 관리 등을 통해 성능을 극대화한다.
Go에서 고루틴을 사용하면 요청 1건당 1개 고루틴을 생성하여 많은 요청을 동시에 처리할 수 있다. 이는 많은 리소스를 사용하는 스레드 방식의 한계를 넘어서 Go만의 고유한 장점이 된다.
하지만 OS 쓰레드가 필요한 경우가 있습니다
- 블로킹 작업 처리
- 고루틴이 파일 I/O, 네트워크 I/O, 또는 시스템 호출(Syscall) 같은 블로킹 작업을 수행하면, Go 런타임은 해당 고루틴을 별도의 OS 쓰레드로 이동
- 이렇게 하면 고루틴을 실행하는 다른 OS 쓰레드들은 블로킹 없이 계속 작업할 수 있습니다.
- 병렬 처리
- 고루틴이 병렬로 실행되기 위해서는 실제로 CPU 코어에서 실행되어야 하며, 이를 위해 OS 쓰레드가 필요합니다.
- Go 런타임은 GOMAXPROCS 환경 변수에 설정된 CPU 코어 수만큼 OS 쓰레드를 생성하여 병렬 실행을 지원합니다.
- 런타임 관리 작업
- Go 런타임의 가비지 컬렉션(GC)과 같은 내부 작업은 OS 쓰레드를 통해 처리됩니다.
출처: goroutine고루틴-파헤치기
출처: Go - Goroutine 정리
출처: A Tour of Go
Go 채널(Channel)로 고루틴 간 데이터 통신하기
Go의 고루틴은 서로 채널(Channel)을 통해 데이터를 주고받으며 통신할 수 있다. 여러 고루틴이 서로 데이터를 주고받아야 하는 상황이 많기 때문에, Go는 안전하고 효율적인 통신을 위해 채널을 제공한다. Go의 런타임은 모든 고루틴이 접근할 수 있는 공용 힙 메모리를 관리하며, 채널은 이 공용 힙에서 저장되기 때문에 고루틴이 어느 프로세서(P)나 스레드(M)에서 실행되더라도 채널을 통해 자유롭게 통신할 수 있다.
Go 채널의 특징
1. FIFO (First-In-First-Out)
채널은 FIFO 방식으로 동작한다. 즉, 먼저 들어간 데이터가 먼저 나오기 때문에, 여러 데이터를 전송해도 보낸 순서대로 수신된다. 이 점에서 큐(Queue)와 유사하게 동작한다.
2. Goroutine-Safe
채널은 goroutine-safe하다. 이는 여러 고루틴이 동시에 같은 채널에 접근해 데이터를 주고받아도 안전하다는 뜻이다. 여러 고루틴이 하나의 채널에 동시에 데이터를 보내거나 받아도, 데이터가 손상되거나 예기치 않은 문제가 발생하지 않는다. 쉽게 말해, 채널은 고루틴이 동시에 접근해도 문제없는 구조다.
3. 채널의 블로킹(Blocking)과 언블로킹(Unblocking)
채널을 사용하다 보면 블로킹(Blocking)과 언블로킹(Unblocking) 상황이 자주 발생한다. 채널은 데이터를 주고받는 과정에서 상태에 따라 고루틴을 멈추거나 재개시키는 역할을 한다.
블로킹(Blocking)
고루틴이 채널에 데이터를 보내려 할 때, 채널이 꽉 차 있으면 고루틴은 블로킹 상태가 된다. 반대로, 데이터를 받으려 할 때 채널이 비어 있으면 역시 블로킹 상태가 된다.
ch := make(chan int, 3) // 버퍼 크기가 3인 채널
go func() {
ch <- 1
ch <- 2
ch <- 3
ch <- 4 // 블로킹 발생
// do something
}()위 예제에서 ch 채널의 버퍼 크기는 3이므로, ch <- 4 부분에서 채널이 꽉 차 블로킹된다. 따라서, 이후 do something은 실행되지 않는다. 이처럼 채널이 꽉 차거나 비어 있을 때 데이터를 보내거나 받으려 하면 고루틴이 멈추는 상태가 된다.
언블로킹(Unblocking)
고루틴이 블로킹 상태에 있다가 채널에 공간이 생기거나 데이터가 들어오면 언블로킹된다. 아래 예제를 보자.
ch := make(chan int, 3)
go func() {
ch <- 1
ch <- 2
ch <- 3
ch <- 4 // 2) 언블로킹
// 3) do something
}()
go func() {
<-ch // 1) 데이터 수신
}()- 첫 번째 고루틴에서 ch <- 4를 실행할 때 채널이 꽉 차 블로킹된다.
- 두 번째 고루틴이 <-ch를 실행해 ch에서 데이터를 하나 수신하면 채널에 공간이 생긴다.
- 채널에 자리가 생기면서 첫 번째 고루틴의 블로킹이 풀리고(unblock), ch <- 4와 do something이 이어서 실행된다.
이처럼, 채널의 블로킹과 언블로킹은 고루틴 간의 자연스러운 협업과 동기화를 가능하게 한다.
Go 채널의 메모리 모델
Go에서 채널은 공용 힙에 저장되기 때문에, 여러 고루틴이 어떤 P(프로세서)나 M(스레드)에서 실행되더라도 채널을 통해 데이터를 안전하게 주고받을 수 있다. 모든 고루틴은 공용 힙 메모리를 통해 채널을 공유하기 때문에 다른 프로세서(P)에 있는 고루틴끼리도 채널을 통해 데이터를 전송할 수 있다.
Go의 채널은 단순한 데이터 전송뿐만 아니라 고루틴 간의 동기화와 통신을 동시에 관리하는 중요한 도구다. 이러한 특성 덕분에 고루틴들은 동시성을 유지하며 효율적으로 통신할 수 있다.
Go의 채널을 통해 동시성 프로그램을 더욱 안전하고 효율적으로 구현할 수 있다. FIFO 방식의 데이터 전송과 고루틴 간의 안전한 통신 방식, 그리고 블로킹과 언블로킹 메커니즘을 통해 여러 작업을 손쉽게 연결해 실행할 수 있다.
간단한 사용법
1. 채널에 데이터 전송하기
채널에 데이터를 전송하려면 <- 연산자를 사용한다. 아래 코드처럼 <- 연산자를 채널명 뒤에 붙이고, 보낼 데이터를 추가해 전송한다.
// 채널 생성
c := make(chan int)
// 데이터 전송
c <- 3 // int형 데이터를 채널에 전달- 채널에서 데이터 수신하기
채널에서 데이터를 수신할 때는 <- 연산자를 채널명 앞에 사용한다. 이렇게 하면 채널에서 데이터를 읽어올 수 있다.
// 채널 생성
c := make(chan int)
// 데이터 수신
<-c // 채널로부터 데이터 수신데이터 전송과 수신의 차이
- 데이터 전송: c <- 3 - <- 연산자를 채널명 뒤에 사용하여 데이터를 채널로 보낸다.
- 데이터 수신: <- c - <- 연산자를 채널명 앞에 사용하여 데이터를 채널에서 받아온다.
- 채널의 대기 상태
채널에 데이터를 전송하면 수신될 때까지 대기하는 상태가 된다. 아래 코드에서 익명 함수가 채널에 3을 전송하지만, 데이터를 받을 수신자가 없으므로 코드 실행이 멈춘다.
package main
import "fmt"
func main() {
c := make(chan int)
go func() {
c <- 3
fmt.Println("test")
}()
}
/*
실행 결과: 아무것도 출력되지 않음
*/위 코드에서 test가 출력되지 않는 이유는 c <- 3에서 수신자를 기다리며 대기 상태가 되었기 때문이다. 이 문제를 해결하려면 채널 데이터를 받을 수신 부분을 추가해야 한다.
- 채널 데이터 송수신 예제
아래 코드는 고루틴이 c 채널에 데이터를 전송하고, 메인 함수에서 그 데이터를 수신해 출력하는 예제다.
package main
import "fmt"
func main() {
c := make(chan int) // 채널 생성
go func() {
c <- 3 // 데이터 전송
}()
fmt.Println(<-c) // 데이터 수신 후 값 출력
fmt.Println(c) // 채널의 주소 출력
}
/*
실행 결과:
3
0xc000080060
*/여기서 3은 c 채널을 통해 수신된 값이고, 그 뒤에 출력되는 것은 c 채널의 메모리 주소다. 이 메모리 주소는 실행할 때마다 달라진다.
- 채널과 큐의 관계
채널은 데이터를 하나만 저장하는 게 아니라 여러 데이터를 FIFO(First-In-First-Out) 방식으로 쌓아두고, 수신할 때는 가장 먼저 전송된 데이터를 먼저 출력한다. 이는 큐(Queue)와 같은 동작 방식이다.
package main
import "fmt"
func main() {
c := make(chan int)
go func() {
c <- 3
c <- 5
}()
fmt.Println(<-c)
fmt.Println(<-c)
}
/*
실행 결과:
3
5
*/여기서 c 채널에 3과 5를 전송하면, 수신 시에는 먼저 전송된 3이 먼저 출력되고, 그다음 5가 출력된다.
- 버퍼 채널
채널 생성 시 두 번째 인자로 버퍼 크기를 설정해 주면, 채널이 특정 크기만큼 데이터를 버퍼링할 수 있다. 이를 버퍼 채널이라고 하며, 버퍼가 꽉 찼을 때는 데이터 수신을 기다리지 않고 자동으로 대기 상태에 들어간다.
버퍼 채널 생성
아래와 같이 두 번째 인자로 버퍼 크기를 설정해 버퍼 채널을 생성할 수 있다.
// 버퍼 채널 생성
c := make(chan int, 5) // 버퍼 크기 5버퍼 채널에 데이터 추가하기
버퍼 크기가 5인 채널은 최대 5개의 데이터를 저장할 수 있다. 만약 채널이 가득 찬 상태에서 데이터를 추가하려 하면 에러가 발생한다.
package main
import "fmt"
func main() {
c := make(chan int, 5)
c <- 1
c <- 2
c <- 3
c <- 4
c <- 5
// c <- 6 // 추가하면 에러 발생
}위 코드에서 c <- 6을 실행하려 하면 “fatal error: all goroutines are asleep - deadlock!” 에러가 발생한다. 이는 버퍼 크기(5)를 초과하여 데이터를 추가하려 했기 때문에 생긴 에러다.
결론
- 고루틴과 채널 어렵다.. 조금더 딥다이브 해보는 시간을 가져보자..
