
Grafana Loki 아키텍처와 동작 원리
Grafana Loki는 수평적 확장과 분산 시스템을 염두에 두고 설계된 로그 관리 시스템임. Prometheus와 유사한 방식으로 로그 데이터를 처리하지만, 메타데이터 중심의 간소화된 인덱싱을 통해 저장 공간과 비용을 줄이는 데 초점을 맞춤.
Loki의 주요 특징
- 수평적 확장성: 컴포넌트 분리를 통해 분산 환경에 적합.
- 저장 공간 효율성: 메타데이터 중심 인덱싱으로 저장 공간 최소화.
- 유연한 배포 모드: 단일 바이너리에서 분산 클러스터로 쉽게 전환 가능.
- 멀티 테넌시 지원: 대규모 환경에서 테넌트별 데이터 관리 가능.
테넌트?
- 서로 다른 사용자, 조직, 또는 애플리케이션이 동일한 Loki 인스턴스를 공유하면서도 독립적으로 로그 데이터를 관리할 수 있도록 하는 방법
- 이 Tenant ID를 기반으로 데이터가 분리 저장됨 -> 안전하게 분리 관리
- 클라이언트 요청의 X-Scope-OrgID 헤더를 사용하여 Loki가 어느 테넌트의 데이터 처리 식별
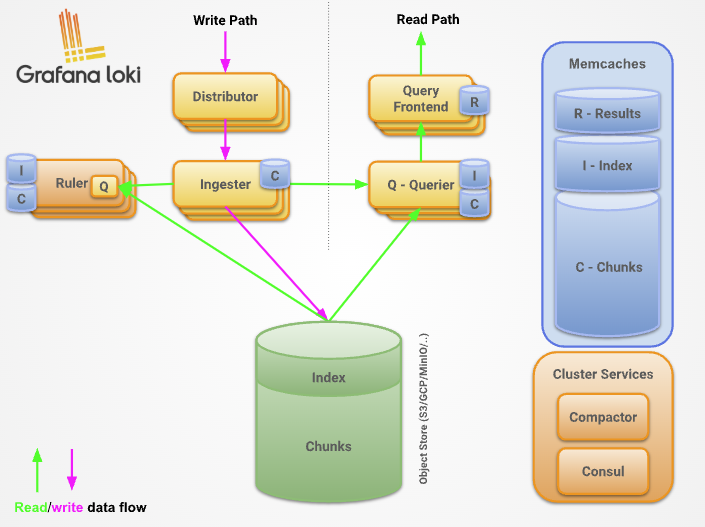
Loki 주요 컴포넌트
(Grafana Youtube) All the Components of Loki Explained | Grafana Labs
1. Distributor
로그 데이터의 쓰기 경로에서 가장 첫 번째 단계로, 클라이언트로부터 데이터를 수신하여 검증하고 적절한 Ingester로 데이터를 분배하는 핵심 역할
Distributor가 필요한 이유
- 데이터 검증: 클라이언트로부터 수신된 로그 데이터가 사양에 맞는지 확인.
- 데이터 분배: 로그 데이터를 여러 Ingester로 효율적으로 분배하여 부하를 분산.
- 여러 Ingester에 데이터를 복제하여 데이터 손실 가능성을 줄임.
Distributor의 주요 기능
1. 데이터 검증 (Validation)
- 로그 데이터의 라벨 형식, 타임스탬프 이상여부, 로그 라인의 길이 등 확인
2. 라벨 정규화 (Preprocessing)
- 라벨의 순서를 정렬하여 동일한 라벨 조합을 일관되게 처리.
- 예:
{foo="bar", bazz="buzz"}를{bazz="buzz", foo="bar"}로 정렬.
=> 데이터 캐싱과 해싱이 결정적으로 작동
- 예:
3. 속도 제한 (Rate Limiting)
- 테넌트별 최대 데이터 수집 속도를 설정하여 데이터 유입량 제어.
- 클러스터의 Distributor 수에 따라 속도를 동적으로 조정.
- 예: 테넌트 A에 대해 10MB/s 제한이 설정된 경우, 10개의 Distributor는 각 1MB/s씩 처리.
4. 데이터 복제 (Replication Factor)
- 데이터를 복제 계수(n)만큼 여러 Ingester로 전송.
- 기본 복제 계수는 3으로 설정되어 있으며, 최소 과반수(Quorum)의 성공적인 쓰기 응답이 필요.
- 예: 복제 계수가 3일 경우, 최소 2개의 성공적인 쓰기 응답 필요.
5. 일관 해싱 (Consistent Hashing)
- 로그 스트림의 라벨과 테넌트 ID를 해싱하여 적절한 Ingester를 선택.
- 해시 링(Hash Ring)을 사용하여 Ingester 간 데이터 분배를 효율화.
Distributor의 동작 방식
- 클라이언트 요청 수신
- 데이터 검증 및 전처리
- 데이터 분배
- Consistent Hashing을 통해 데이터를 복제 계수만큼 Ingester에 분배.
- Ingester로 데이터를 전달하고, 과반수 성공 시 클라이언트에 성공 응답 반환.
2. Ingester
Ingester는 Loki에서 로그 데이터를 처리 및 저장하는 핵심 컴포넌트로, 데이터를 메모리에 저장하고 이를 장기 스토리지로 플러시(Flush)하며, 최근 데이터를 읽기 요청에 제공하는 역할을 함.
Ingester의 역할
- 데이터 수집 및 저장
- Distributor로부터 데이터를 수신하여 메모리 청크에 저장.
- 일정 조건에 따라 데이터를 압축하고 장기 스토리지(S3, GCS 등)로 플러시.
- 데이터 제공
- 읽기 요청 시, 메모리에 저장된 최신 로그 데이터를 반환 OR 장기 스토리지에서 조회
- 데이터 안정성 보장
- Write Ahead Log(WAL)을 활용해 데이터 손실 방지.
Ingester의 주요 기능
1. 상태 관리 (Lifecycle Management)
Ingester는 해시 링(Hash Ring)을 기반으로 동작하며, 다음과 같은 상태를 가짐:
- PENDING: LEAVING 상태의 Ingester로부터 데이터를 전달받기 위해 대기.
- JOINING: 토큰을 해시 링에 추가하고 초기화 중. 자신이 소유한 토큰에 대해 쓰기 요청을 수신.
- ACTIVE: 완전히 초기화된 상태. 읽기 및 쓰기 요청 모두 처리 가능.
- LEAVING: 종료 중. 메모리에 있는 데이터에 대해 읽기 요청만 처리.
- UNHEALTHY: 상태 확인 실패 시 비정상으로 설정.
2. 데이터 청크 관리
- 로그 스트림은 라벨 세트(Label Set)를 기준으로 청크로 나뉘어 메모리에 저장.
- 일정 조건이 충족되면 청크는 읽기 전용(Compressed)으로 설정되고, 새 쓰기 가능한 청크가 생성.
- 청크 플러시 조건:
- 청크가 최대 용량에 도달.
- 일정 시간이 경과하여 업데이트가 없는 경우.
- 플러시 명령이 발생한 경우.
Ingester의 동작 방식
- 데이터 수신: Distributor로부터 데이터를 수신 및 청크에 저장
- 데이터 저장: 메모리에 청크 단위로 데이터를 보관, 일정 조건에서 청크를 장기 스토리지로 플러시
- 데이터 제공: 읽기 요청 시,메모리에서 최근 데이터를 조회, 과거 데이터는 장기 스토리지에서 조회
- 장기 스토리지로 플러시: 청크를 압축하고 읽기 전용으로 설정.
- 테넌트, 라벨, 데이터 내용 기반의 해시를 생성하여 중복 데이터 저장 방지.
- 데이터 손실 방지: WAL을 사용하여 모든 쓰기 작업 기록.
3. Query Frontend
역할
- 쿼리 최적화 및 분산 처리:
- 클라이언트의 쿼리를 소형 하위 쿼리로 나누고 작업을 스케줄링.
- 결과를 병합하여 클라이언트로 반환.
주요 기능
- 큐잉(Queueing):
- 대형 쿼리가 OOM(Out-of-Memory)을 유발하지 않도록 재시도.
- 쿼리를 FIFO 방식으로 분배하여 공정한 처리 보장.
- 캐싱(Caching):
- 메트릭 쿼리 결과와 로그 쿼리의 부정적 결과(negative cache)를 캐싱하여 성능 최적화.
- 쿼리 분할(Splitting):
- 대규모 쿼리를 병렬로 실행하여 처리 속도 향상.
4. Query Scheduler
역할
- 고급 큐 관리:
- Query Frontend에서 분할된 쿼리를 내부 메모리 큐에 저장.
- 각 테넌트별로 개별 큐를 유지하여 공정성 보장.
특징
- Querier가 작업을 풀 방식으로 가져와 실행.
- 고가용성을 위해 여러 복제본 실행 권장(보통 2개 이상).
5. Querier
역할
- LogQL 쿼리 실행:
- 클라이언트 요청을 직접 처리하거나 Query Frontend/Scheduler로부터 하위 쿼리를 가져와 실행.
- 데이터 제공:
- 메모리에서 최신 데이터 조회.
- 백엔드 스토리지에서 과거 데이터 조회.
주요 기능
- 중복 제거:
- 동일한 타임스탬프, 라벨 세트, 로그 메시지를 가진 중복 데이터를 제거.
6. Index Gateway
역할
- 메타데이터 쿼리 처리:
- 특정 로그의 위치 정보를 반환.
- Querier에 청크 참조를 제공하여 어떤 데이터를 가져와야 할지 알려줌.
모드
- Simple Mode:
- 모든 테넌트의 모든 인덱스를 제공.
- Ring Mode:
- 해시 링을 사용하여 인덱스를 분산 처리.
7. Compactor
역할
- 인덱스 파일 압축 및 최적화:
- Ingester가 생성한 여러 인덱스 파일을 병합하여 효율성을 높임.
- 새로 병합된 인덱스를 저장하고, 기존 파일 삭제.
- 로그 유지/삭제:
- 로그 보존 기간에 따라 데이터를 삭제.
8. Ruler
역할
- 규칙 평가 및 알림 관리:
- 사용자 정의 규칙에 따라 로그 데이터를 분석하고, 조건을 충족하면 알림 생성.
- 원격 규칙 평가(Remote Rule Evaluation):
- Query Frontend와 연동하여 쿼리 분할, 샤딩, 캐싱 이점을 활용.
작동 방식
- 여러 Ruler가 해시 링을 사용하여 규칙 그룹을 분산 처리.
비유:
- 동영상을 보면 실제 공장에서의 작업을 비유하면서 설명을 하였는데 이해하기가 더 쉬웠다
- Distributor (사이트 관리자)가 고객으로부터 받은 주문과 원자재를 검토하고 작업 가능한 생산 라인(Ingester)으로 보냄.
- Ingester (생산 라인)는 데이터를 가공하고, 일정 조건에 따라 창고(장기 저장소)로 옮김.
- 고객이 주문 요청(LogQL 쿼리)을 하면, Query Frontend (주문 처리 데스크)가 이를 접수.
- Query Scheduler (생산 스케줄러)는 작업 요청을 나누어 Querier (작업자)에게 작업을 할당.
- Querier (작업자)는 데이터를 검색, 가공, 정리하여 고객 요청에 맞는 결과를 반환.
- Index Gateway (재고 관리 시스템)는 데이터의 위치 정보를 제공하여 검색을 지원.
- Compactor (압축 기계)는 인덱스를 정리하고 최적화하여 시스템 효율성을 유지.
와 같은 과정을 통하여 로그를 처리한다고 생각을 하면 된다고 한다.
Loki Deployment Modes
1. Monolithic Mode (모놀리식 모드)
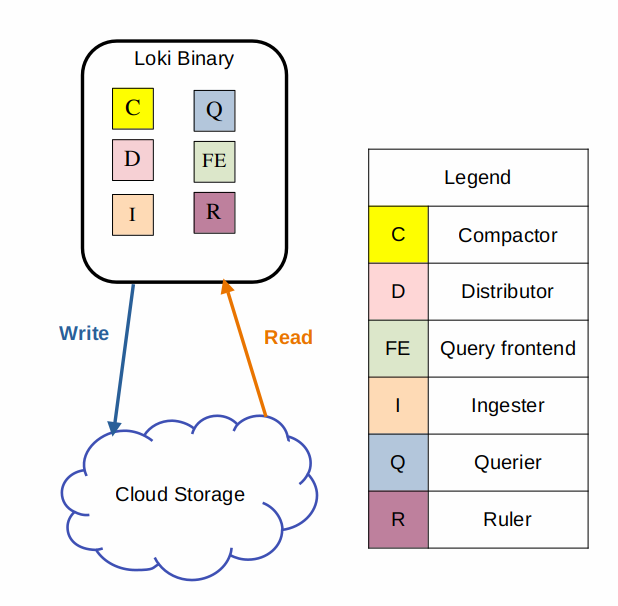
특징
- Loki의 모든 컴포넌트를 단일 프로세스로 실행.
-target=all플래그를 설정하여 모놀리식 모드 활성화.- 간단한 설정으로 빠르게 시작 가능하며, 작은 데이터 볼륨(하루 약 20GB 이하)에 적합.
장점
- 간편성: 하나의 바이너리 또는 Docker 이미지로 모든 컴포넌트 실행.
- 빠른 시작: Loki 실험 및 소규모 환경에서 적합.
확장
- 수평적 확장:
- 공유 오브젝트 스토어 사용.
loki.yaml파일에서ring섹션을 설정하여 인스턴스 간 상태 공유.
- 고가용성(HA):
- 두 개 이상의 Loki 인스턴스를 실행.
memberlist_config와replication_factor=3설정을 사용.- 라운드 로빈 방식으로 트래픽 분배.
2. Simple Scalable Mode (간단 확장 모드)
특징
- 기본 배포 모드로, Loki Helm Chart에서 기본적으로 설치됨.
- 데이터 처리 경로를 읽기(Read), 쓰기(Write), 백엔드(Backend)로 분리하여 확장 가능.
- 하루 몇 TB의 로그 데이터를 처리할 수 있음.
구성 요소
-
Write Target (
-target=write):- 상태 유지(Stateful).
- 주요 컴포넌트:
- Distributor
- Ingester
- Kubernetes StatefulSet으로 관리됨.
-
Read Target (
-target=read):- 상태 비유지(Stateless).
- 주요 컴포넌트:
- Query Frontend
- Querier
- Kubernetes Deployment로 관리 가능 (Helm Chart에서는 StatefulSet으로 배포).
-
Backend Target (
-target=backend):- 상태 유지(Stateful).
- 주요 컴포넌트:
- Compactor
- Index Gateway
- Query Scheduler
- Ruler
- Kubernetes StatefulSet으로 관리됨.
확장
- 독립적인 경로 확장:
- 읽기(Read), 쓰기(Write), 백엔드(Backend) 경로를 개별적으로 확장하여 비용과 성능 최적화.
- 리버스 프록시:
- 클라이언트 API 요청을 읽기 노드와 쓰기 노드로 분배.
- 기본적으로 Nginx 설정 포함.
3. Microservices Mode (마이크로서비스 모드)
특징
- Loki의 각 컴포넌트를 개별 마이크로서비스로 실행.
- 특정 컴포넌트 실행 시
-target플래그 사용. - 대규모 Loki 클러스터 또는 정밀한 제어가 필요한 운영 환경에 적합.
구성 요소
-
주요 컴포넌트:
- Cache Generation Loader
- Compactor
- Distributor
- Index-gateway
- Ingester
- Ingester-Querier
- Overrides Exporter
- Querier
- Query-frontend
- Query-scheduler
- Ruler
-
Loki 버전에 따라 실행 가능한 전체 타겟 목록은 다음 명령어로 확인 가능:
docker run docker.io/grafana/loki:<버전> -config.file=/etc/loki/local-config.yaml -list-targets
장점
- 세부 제어:
- 컴포넌트별로 독립적인 확장 및 최적화 가능. - 고효율 배포:
- 특정 요구 사항에 맞게 리소스를 조정 가능.
단점
- 높은 복잡성:
- 설정 및 유지 관리가 복잡.
- Kubernetes에 최적화된 환경에서 주로 사용.
저장소 구성
1. 오브젝트 스토리지
- Loki는 모든 데이터를 Amazon S3, Google Cloud Storage, Azure Blob Storage와 같은 오브젝트 스토리지에 저장.
- 인덱스 시퍼(Index Shipper):
- 청크 파일과 동일한 객체 스토리지에 인덱스 파일을 저장하는 어댑터로, Loki가 외부 데이터베이스 없이 인덱스를 관리할 수 있도록 지원
- TSDB(Time Series Database) 또는 BoltDB 형식으로 인덱스 파일을 저장.
2. 데이터 포맷

- 인덱스(Index):
- 로그 데이터를 빠르게 찾기 위한 "목차".
- 라벨 기반으로 로그의 위치를 저장.
- 청크(Chunk):
- 라벨과 특정 시간 범위에 속하는 로그 데이터를 포함.
- 구성:
- MagicNumber, 버전, 압축 방식 등의 메타데이터.
- 라벨 정보와 로그 엔트리를 포함.
- 청크 데이터는 압축되어 저장됨.
----------------------------------------------------------------------------
| | | |
| MagicNumber(4b) | version(1b) | encoding (1b) |
| | | |
----------------------------------------------------------------------------
| #structuredMetadata (uvarint) |
----------------------------------------------------------------------------
| len(label-1) (uvarint) | label-1 (bytes) |
----------------------------------------------------------------------------
| len(label-2) (uvarint) | label-2 (bytes) |
----------------------------------------------------------------------------
| len(label-n) (uvarint) | label-n (bytes) |
----------------------------------------------------------------------------
| checksum(from #structuredMetadata) |
----------------------------------------------------------------------------
| block-1 bytes | checksum (4b) |
----------------------------------------------------------------------------
| block-2 bytes | checksum (4b) |
----------------------------------------------------------------------------
| block-n bytes | checksum (4b) |
----------------------------------------------------------------------------
| #blocks (uvarint) |
----------------------------------------------------------------------------
| #entries(uvarint) | mint, maxt (varint) | offset, len (uvarint) |
----------------------------------------------------------------------------
| #entries(uvarint) | mint, maxt (varint) | offset, len (uvarint) |
----------------------------------------------------------------------------
| #entries(uvarint) | mint, maxt (varint) | offset, len (uvarint) |
----------------------------------------------------------------------------
| #entries(uvarint) | mint, maxt (varint) | offset, len (uvarint) |
----------------------------------------------------------------------------
| checksum(from #blocks) |
----------------------------------------------------------------------------
| #structuredMetadata len (uvarint) | #structuredMetadata offset (uvarint) |
----------------------------------------------------------------------------
| #blocks len (uvarint) | #blocks offset (uvarint) |
----------------------------------------------------------------------------- block부분은 individual log line을 의미한다. 이 블럭은 압축되어 저장이 된다.
- ts: timestamp, len: length of log entry
데이터 처리 흐름
1. 쓰기 경로 (Write Path)
- Distributor가 HTTP POST 요청으로 로그 스트림과 라인을 수신.
- Consistent Hashing을 통해 스트림을 적절한 Ingester로 전달.
- Ingester는 로그를 청크로 저장하거나 기존 청크에 추가.
- Ingester는 복제를 위해 다른 인스턴스와 동기화.
- 과반수(Quorum) 응답을 확인한 후, 성공 또는 실패를 반환.
2. 읽기 경로 (Read Path)
- Query Frontend가 LogQL 쿼리를 수신.
- 쿼리를 하위 쿼리로 나누어 Querier로 전달.
- Querier는 메모리 및 저장소 데이터를 검색하고, 중복 제거.
- Query Frontend는 하위 쿼리 결과를 병합하여 최종 결과를 반환.
멀티 테넌시
- 테넌트 ID: 요청 헤더의
X-Scope-OrgID필드에서 가져옴. - 메모리와 장기 저장소의 모든 데이터는 테넌트 ID에 따라 분리 관리됨.
- 멀티 테넌시가 비활성화된 경우, 기본 테넌트 ID는
fake로 설정됨.
