





다람쥐는 귀엽지만 내용은 결코 귀엽지않다
Preface
HTTP is most famous for two-way conversation between web browsers and web servers.
Part 1. HTTP: The Web’s Foundation
Chapter 1. Overview of HTTP

Web servers speak the HTTP protocol.
Web browsers request HTTP objects from servers and display the objects on your screen.

Web servers host web resources. A web resources is the source of web content.
Resources can also be software programs that generate content on demand.
A file containing your company's takes forecast spreadsheet is a resource. A web gateway to scan your local public library's shelves is a resource. So an Internet search engine is a resource.

Web servers attach a MIME type to all HTTP object data. A MIME type is a textual label, represented as a primary object type and a specific subtype, separated by a slash.

Each web server resource has a name, so clients can point out what resources they are interested in. The server resource name is called a uniform resource Identifier, or URI.
http://www.joes-hardware.com/specials/saw-blade.gifIt shows how the URL specifies the HTTP protocol to access the saw blade GIF resource on Joe's store's server.
The uniform resource locator(URL) is the most common form of resource identifier. URLs describe the specific location of a resource on a particular server.
Most URLs follow a standardized format of three main parts:
1. First part of the URL is called the scheme, and it describes the protocol user to access the resource. This is usually the HTTP protocol(http://)
2. The Second part gives the server Internet address(e.g., www.joes-hardware.com).
3. The rest names a resource on the web server(e.g., /specials/saw-blade.gif).
Today, almosy every URI is a URL

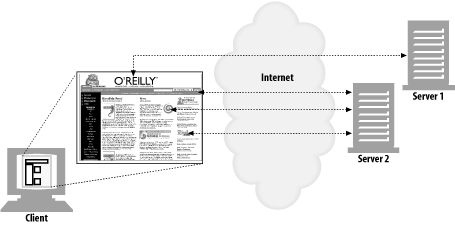

An application often issues multiple HTTP transactions to accomplish a task. Thus a "web page" often is a collection of resources, not a single resource.
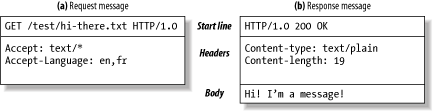
HTTP mseeages consist of three parts: Start Lines Header fields, Body

HTTP is an application layer protocl. HTTP doesn't worry about the nitty-gritty details of network communication; instead, it leaves the details of networking to TCP/IP, the popular reliable Internet transport protocol.
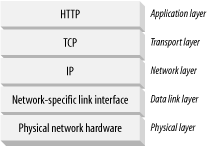
TCP provides three things.
1. Error-free data transportation
2. In-order delivery(data will always arrive in the order in which it was sent)
3. Unsegmented data stream (can dribble out data in any size at any time)
To setting up TCP connection, you need the IP address of the server computer and the TCP port numbers associated with the specific software program running on the server.
Hostnames can easily be converted into IP address through a facility called the Domain Name Service(DNS).
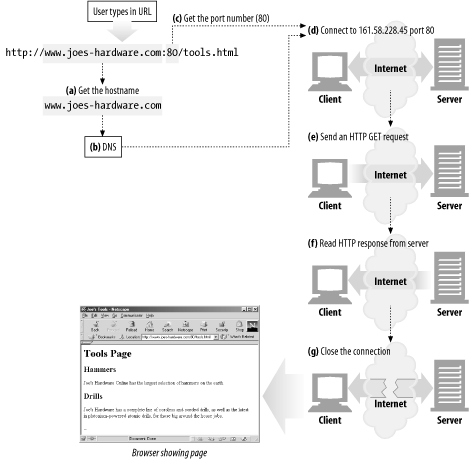
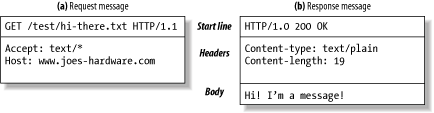
How a browser uses HTTP to display a simple HTML resource that resides on a distant server? Let take a look step by step.
- The browser extracts the server's hostname from the URL.
- The browser converts the server's hostname into the server's IP address.
- The browser extracts the port number (if any) from the URL.
- The browser establishes a TCP connection with the web server.
- The browser sends an HTTP request message to the server.
- The server sends an HTTP response back to the browser.
- The connection is closed and the browser displays the document.
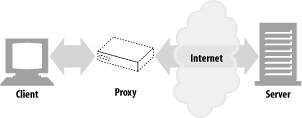
A Proxy sits between a client and a server, receiving all the client's HTTP request and relaying the requests to the server.
So, proxies are often used for security, acting as trusted intermediaries through which all web traffic flows.
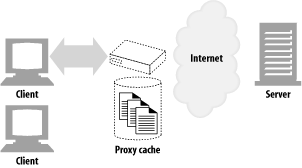
A web cache or caching proxy is a special type of HTTP proxy server that keeps copies of popular documents that pass through the proxy.
A client may be able to download a document much more quickly from a nearby cache than from a distant web server.
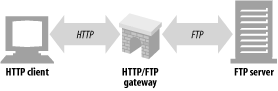
Gateways are special servers that act as intermediaries for other servers. They are often used to convert HTTP taffic to another protocol.
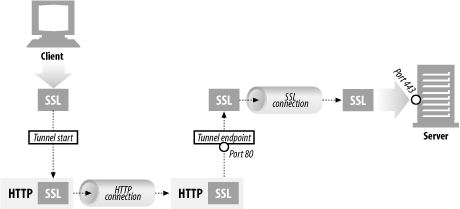
Tunnels are HTTP applications that, after setup, blindly relay raw data between two connections. HTTP tunnels are of often used to transport non-HTTP data over one or more HTTP connections, without looking at the data.
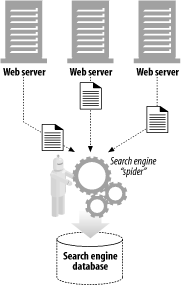
User agents (or just agents) are client programs that make HTTP requests on the user's behalf. Any application that issues web requests is an HTTP agent. So far we've talked about one kind of HTTP agent: web browsers. But there are many other kinds of user agents.
Chapter 2. URLs and Resources
인터넷을 하나의 도시로 생각해보기
모든 것들은 도서번호처럼 고유의 번호가 있고 버스들도 각자 노선번호가 있다.
매일 아침 나는 5호선을 타고 청량리역에서 하차한다.
이러한 번호는 모두가 동의한 규격/규칙이다. -> HTTP protocol
Uniform resources locators(URLs) are the standardized names for the Interent's resources. URLs point to pieces of electronic information, telling you where they are locatied and how to interact with them.
URLs actually are a subset of a more general class of resource identifier called a uniform resource ifentifier, or URI. URIs are a general concept comprised of two main subsets, URLs and URNs. URLs identify resources by describing where resources are located. Wheres URNs identify resources by name, regardless of where they currently reside.
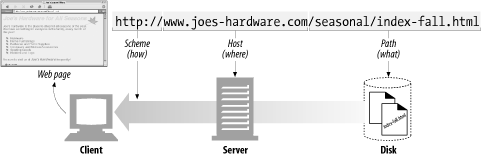
URLs give you and your browser all you need to find a piece of information. They define the particular resourceyou want, where it is located, and how to get it.
http://www.joes-hardware.com:80/seasonal/index-fall.htmlThe path often resembles a hierarchical filesystem path.
http://www.joes-hardware.com/hammers;sale=false/index.html;graphics=trueIn this example there are two path segments,
hammersandindex.html. Thehammerspath segment has the paramsale, and its value isfalse. Theindex.htmlsegment has the paramgraphics, and its value istrue.
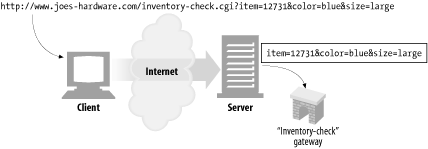
http://www.joes-hardware.com/inventory-check.cgi?item=12731Question mark is called the query component. The qeury component of the URL is passed along to a gateway resource, with the path component of the URL identifying the gatewat resource.
http://www.joes-hardware.com/inventory-check.cgi?item=12731&color=blueBy convention, many gateways expect the query string to be formatted as a series of "name=value" pairs, separated by "&" characters. In this example, there are two name/value pairs in the query component:
item=12731andcolor = blue.
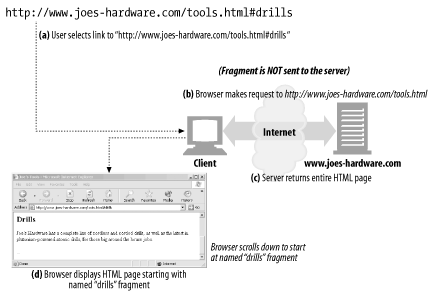
http://www.joes-hardware.com/tools.html#drillsA fragment dangles off the right-hand side of a URL, preceded by a
#character.

URLs come in two flavors: absolute and relative. With an absolute URL, you have all the information you need to access a resource. On the other hnad relative URLs are incomplete. To get all the information needed to access a resource from a relative URL, you must interpret it relative to another URL, called its base.
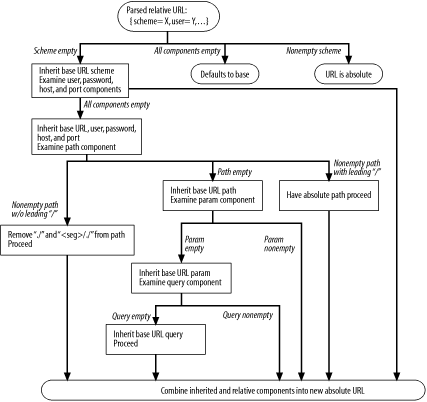
In effect, you are just parsing the URL, but this is often called decomposing the URL, because you are breaking it up into its components.
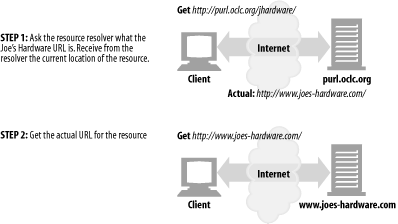
The downfall of this scheme is that if the resource is moved, the URL is no longer valid.
What would be ideal is if you had the real name of an object, which you could use too look up that object regardless of its location.
The IETF has been working on a new standard, uniform resource names (URNs), for some time now, to address just this isuues
URNs provide a stable name for an objec, regardelesso f wher that object moves. Persistent uniform resouce locator (PURLs) are an example of how URN functionality can be achieved using URLs.
Chapter 3. HTTP messages
If HTTP is the internet's courier, HTTP messages are the packages it uses to move this around.
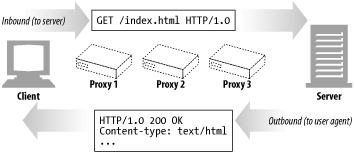
HTTP uses the terms inbound and outbound to describe transactional direction.
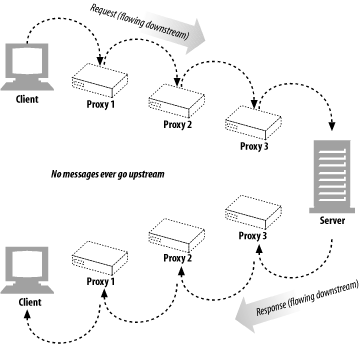
HTTP messages flow like rivers. All messages flow donstream, regardless of whetehr they are request messages or response messages.
The sender of any message is upstream of the receiver.
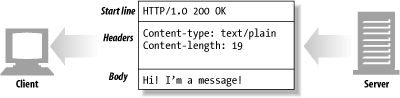
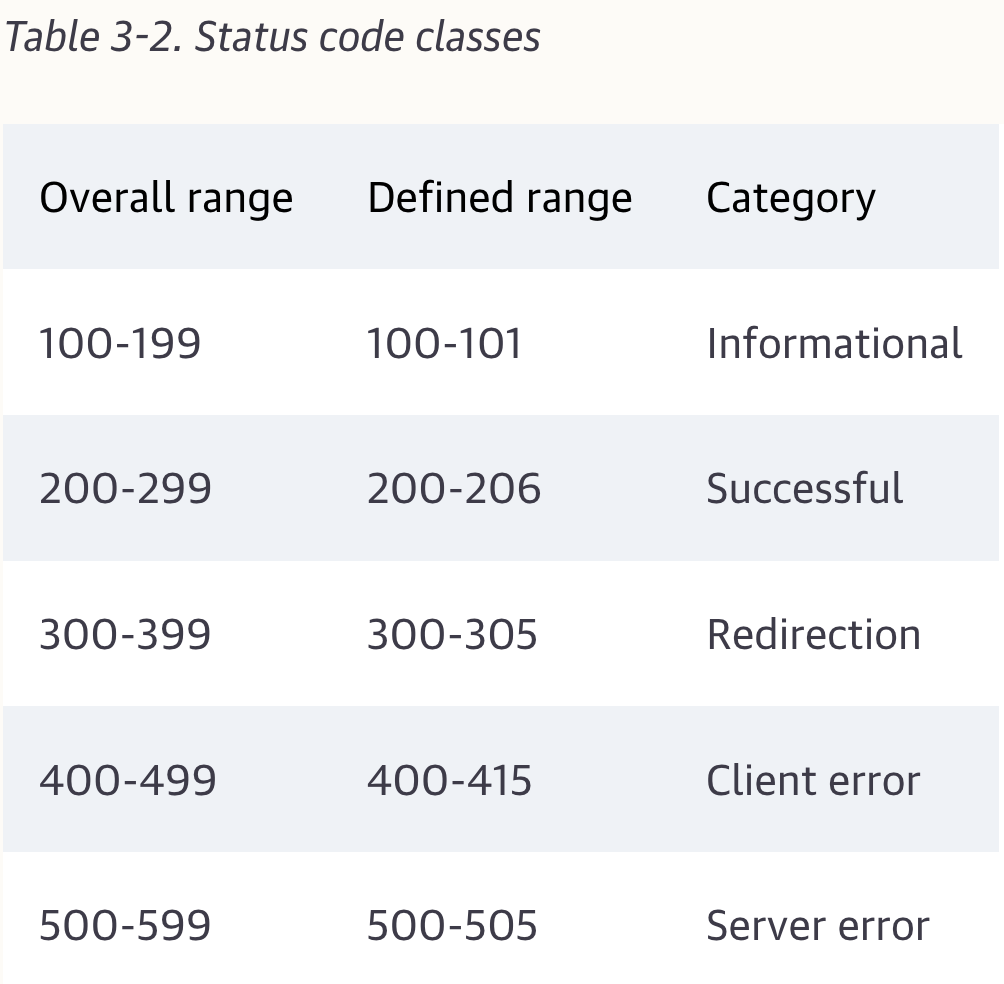
The start line and headers are just ASCII text.
The entity body or message body (or just plain "body") is simply an optional chunk of data. Unluke the start line and headers, the body can contain text or binary data or can be empty.
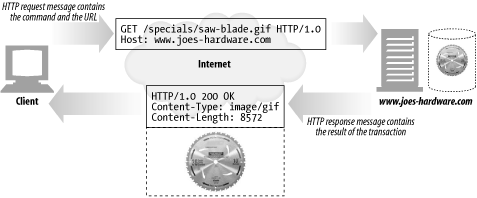
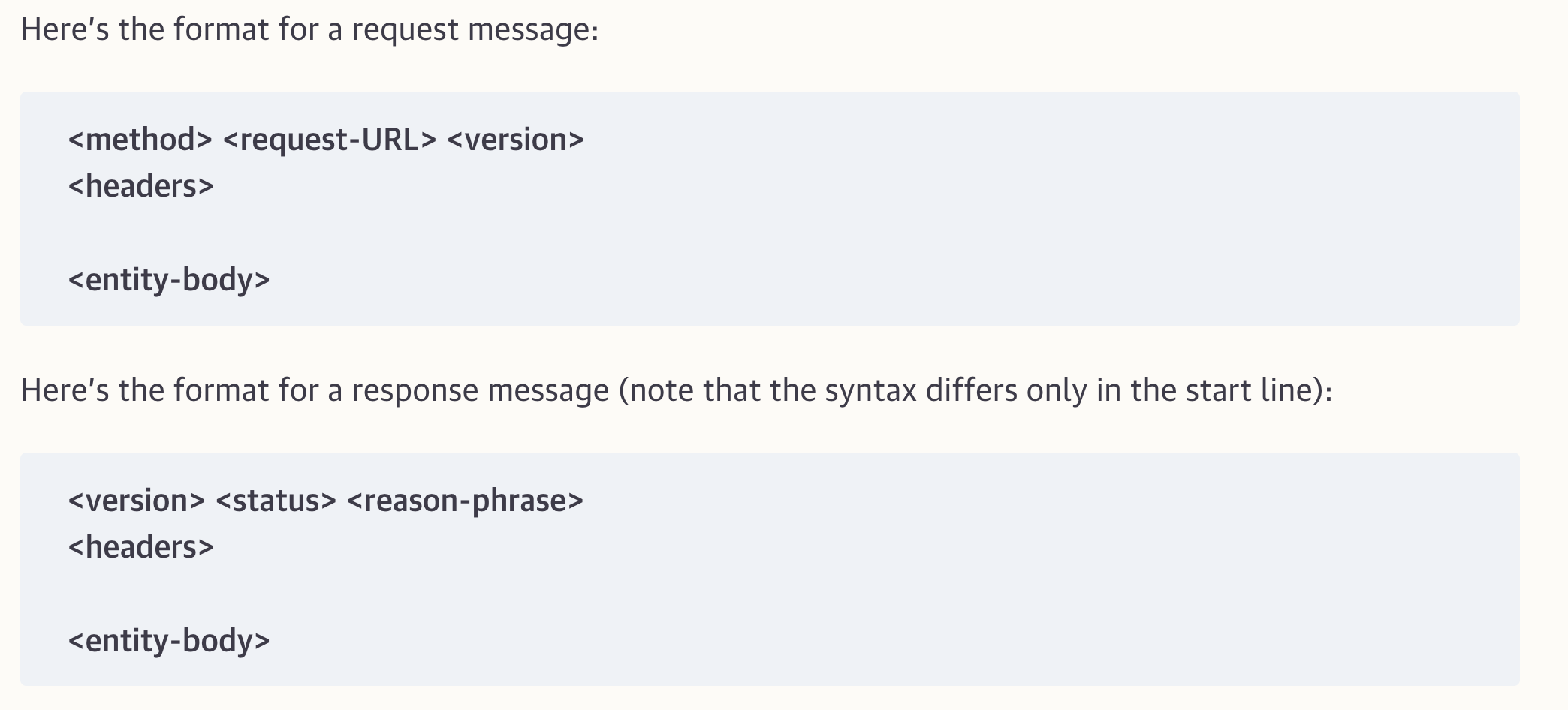
All HTTP messages fall into two types: request messages and response messages. request messages request an action from a web server, Response messages carry results of a request back to a client.
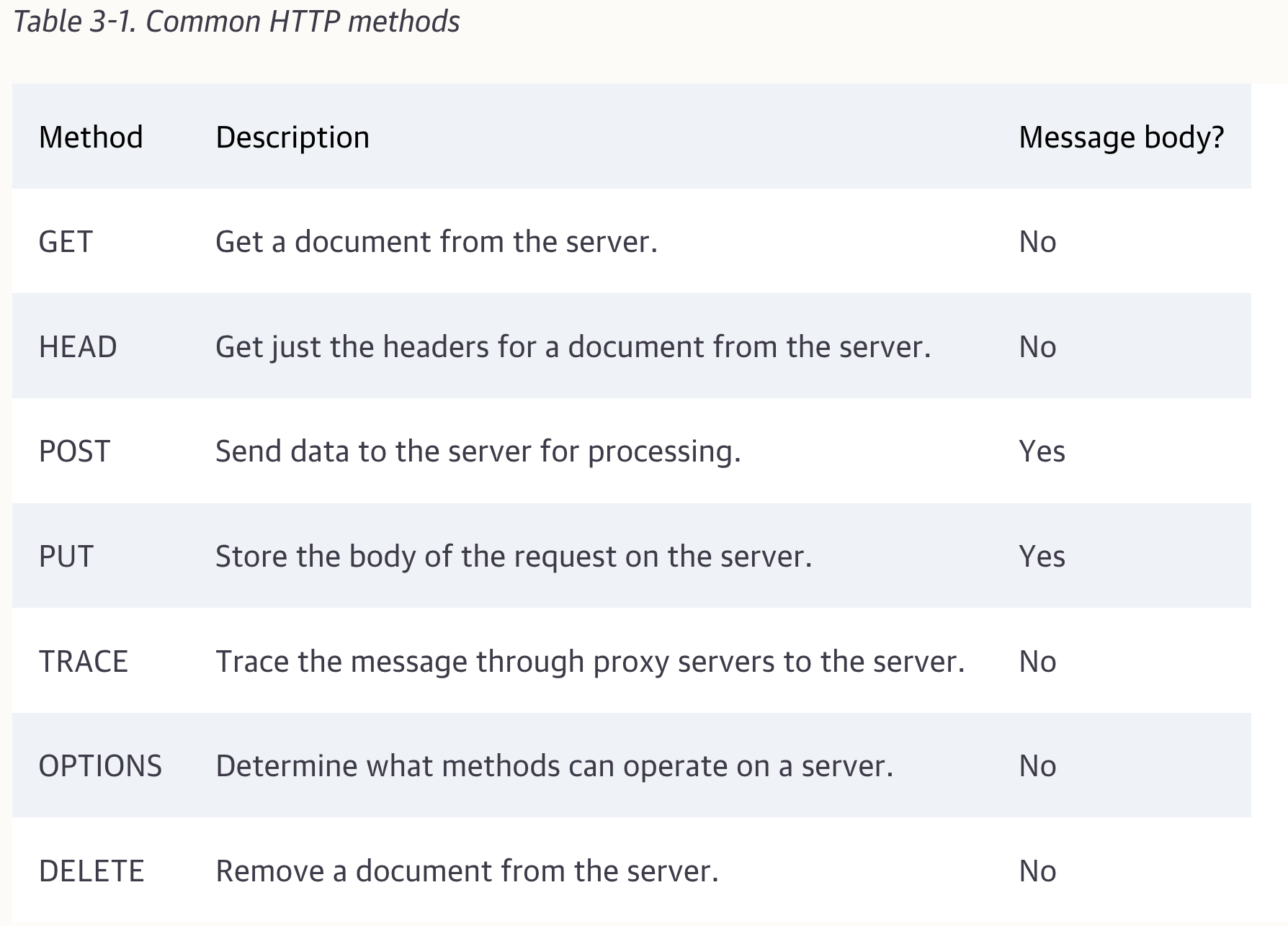
Method is the action that the client wants the server to perform on the resource. It is a single word, like "GET", "HEAD", or "POST".
An HTTP messages begin with a start line. The start line for a request message says what to do. The start line for a response messages says what happened.
Content-length: 19HTTP header fields add additional information to request and response messages. They are basically just lists of name/value pairs. For example, the following header line assigns the value 19 to the Content-Length header field.
The third part of an HTTP message is the optional entity body. Entity bodies are the payload of HTTP messages.
HTTP messages can carry many kinds of digitial data: images , video, HTML, software application, credit card transactions, and so on.
HTTP defines a set of methods that are called safe methods. The GET and HEAD methods are said to be safe, meaning that no action should occur as a result of an HTTP request that uses either the GET or HEAD method.
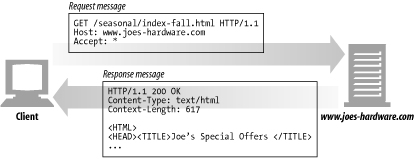
Get is the most common method. It usually is used to ask a server to send a resource.

The HEAD method behaves exactly like the GET method, but the server returns only the headers in the response.
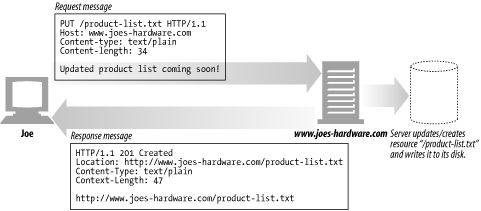
The PUT method writes documents to a server, in the inverse of the way that GET reads documents from a server.
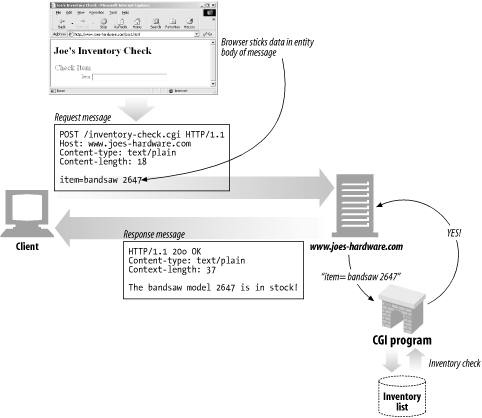
The POST method was designed to send input data to the server.
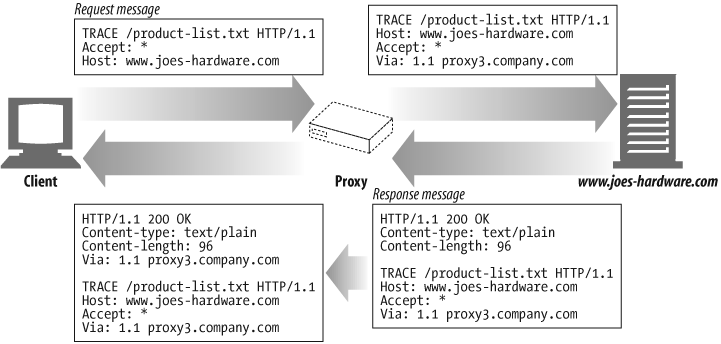
When a client makes a request, that request may have to travel through firewalls, proxies, gateways, or other applications. Each of these has the opportunity to modify the original HTTP request. The TRACE method allows clients to see how its request looks when it finally makes it to the server.
No entity body can be sent with a TRACE request. The entity body of the TRACE response contains, verbatim, the request that the responding server received.
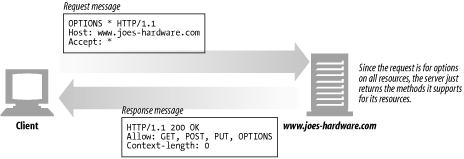
The OPTIONS method asks the server to tell us about the various supported capabilities of the web server.
This provides a means for client applications to determine how best to access various resources without actually having to access them.
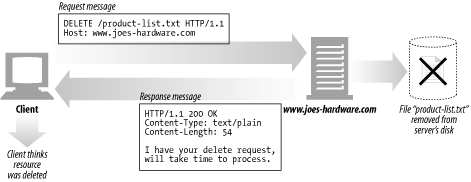
However, the client application is not guaranteed that the delete is carried out. This is because the HTTP specification allows the server to override the request without telling the client.

If a client is sending an entity to a server and is willing to wait for a 100 Continue response before it sends the entity, the client needs to send an Expect request header (see Appendix C) with the value 100-continue.
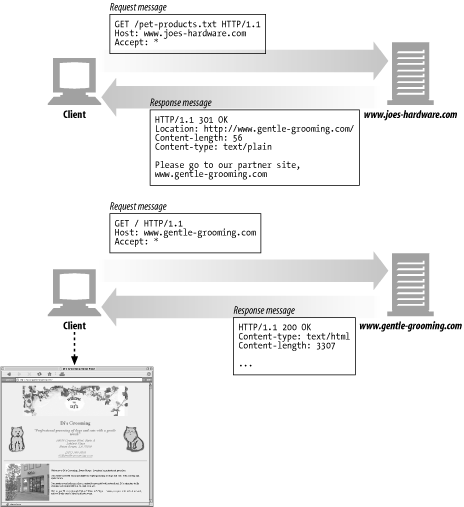
The redirection statis codes either tell clients to use alternate locations for the resources they're interested in or provide an alternate response instead of the content.
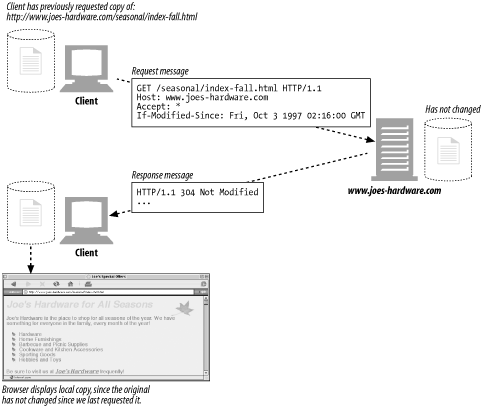
We've all seen the infamous 404 Not Found error code while browsing-this is just the server telloing us that we have requested a resource about which it knows nothing.
Proxies often run into problems when trying to talk to servers on a client's behalf. Proxies issue 5xx server error status codes to describe the problem.
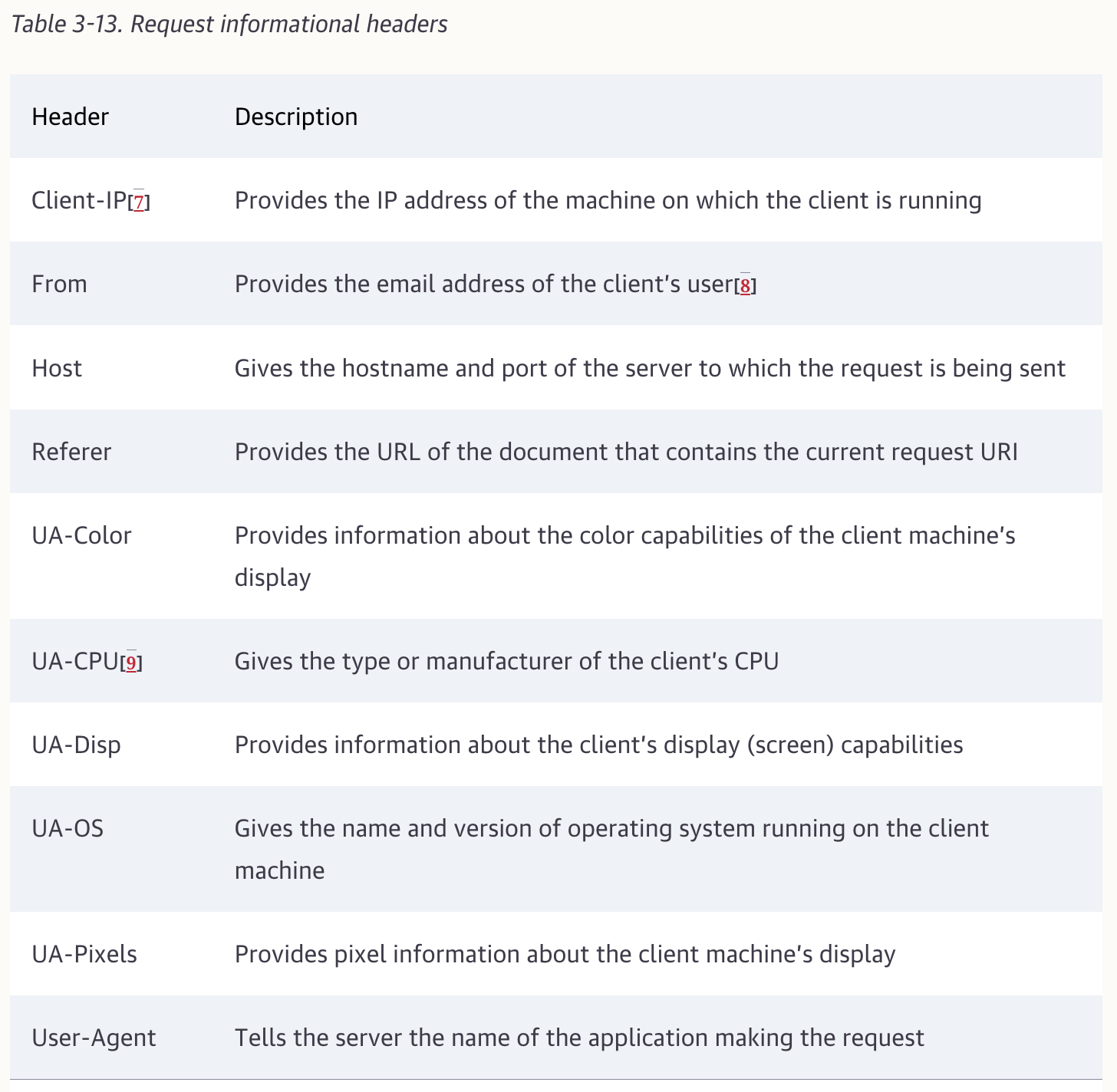
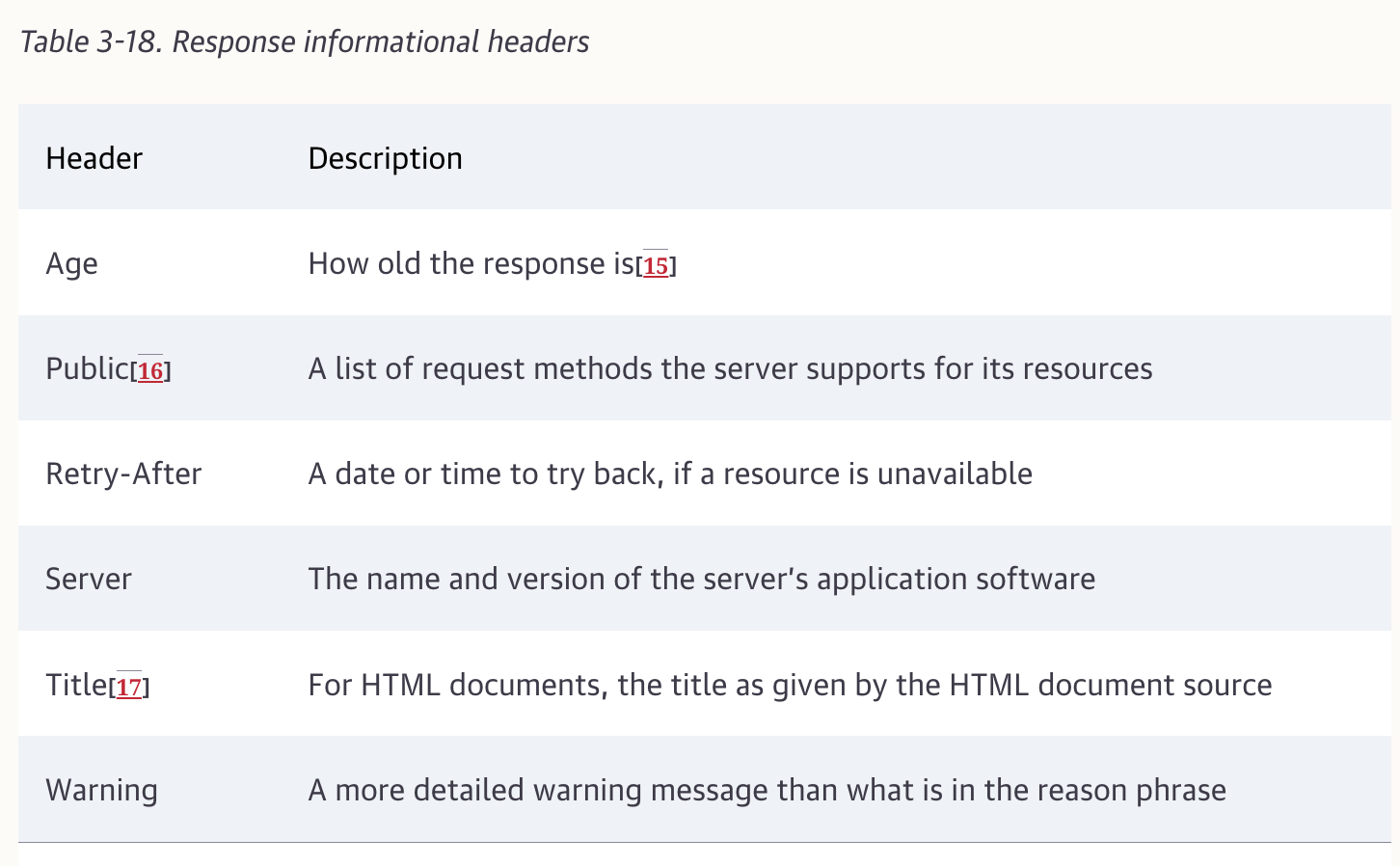
Headers fall into five main classes: General Headers, RequestHeaders, Response Headers, Entity Headers, Extension Headers.

Date: Tue, 3 Oct 1974 02:16:00 GMTGeneral headers serve general purposes that are useful for clinets, servers, and other applications to supply to one another.
Accept: */*Reqeust Headers provide extra information to servers, such as what type of data the client is willing to receive.
Servers can use the information the request headers give them about the client to try to give the client a better response.
Server: Tiki-Hut/1.0Response headers have their own set of headers that provide information to the client.
Content-Type: text/html; charset=iso-latin-1Entity headers refer to headers that deal with the entity body. For Instance, entity headers can tell the type of the data in the entity body.
Chapter 4. Connection Management
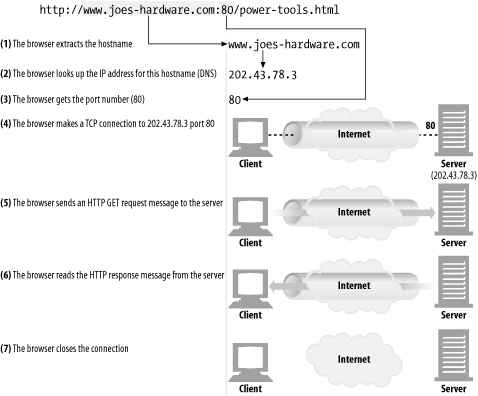
(1) The browser extracts the hosname
(2) The browser looks up the IP address for this hostname(DNS)
(3) The browser gets the port number(80)
(4) The browser makes a TCP connection to 202.43.78.3 port 80.
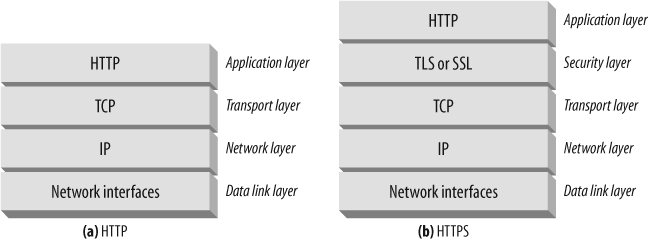
TCP sends its data in little chunks called IP packets (or IP datagrams). In this way, HTTP is the top layer in a "protocol stack” of “HTTP over TCP over IP,” as depicted in Figure 4-3a. A secure variant, HTTPS, inserts a cryptographic encryption layer (called TLS or SSL) between HTTP and TCP (Figure 4-3b).
When HTTP wants to transmit a message, it streams the contents of the message data, in order, through an open TCP connection. TCP takes the stream of data, chops up the data stream into chunks called segments, and transports the segments across the Internet inside envelopes called IP packets (see Figure 4-4). This is all handled by the TCP/IP software; the HTTP programmer sees none of it.
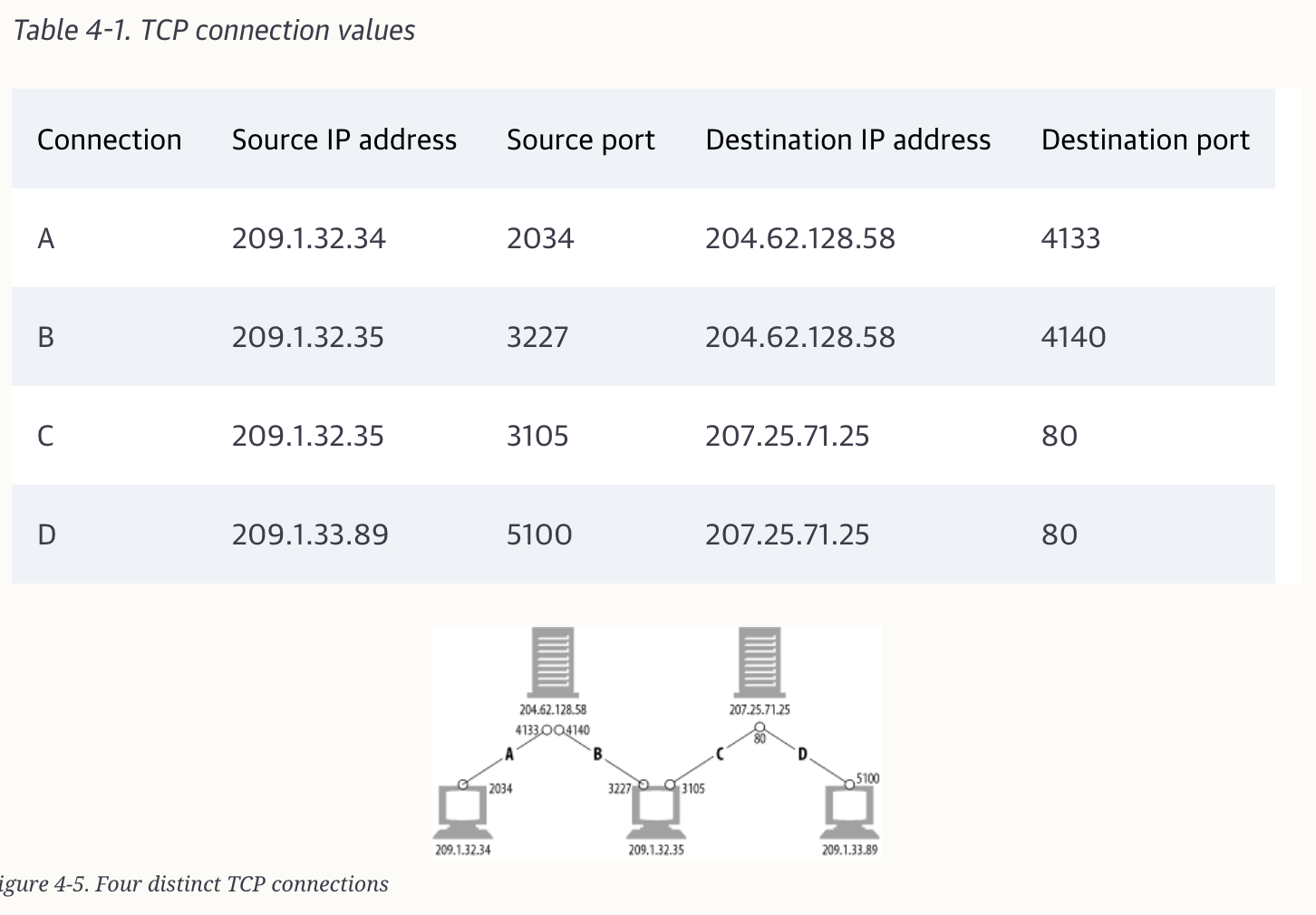
Port numbers are like employees’ phone extensions. Just as a company’s main phone number gets you to the front desk and the extension gets you to the right employee, the IP address gets you to the right computer and the port number gets you to the right application.
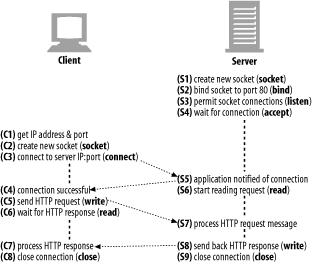
The TCP API hides all the details of the underlying network protocol handshaking and the segmentation and reassembly of the TCP data stream to and from IP packets.
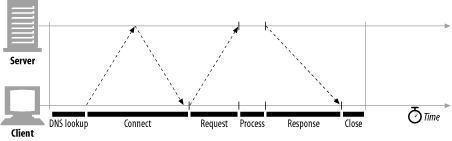
Because HTTP is layered directly on TCP, the performance of HTTP transactions depends critically on the performance of the underlying TCP plumbing.
Part 2. HTTP Architecture
Part 3. Identificatino, Authorization, And Security
Part 4. Entities, Encodings, And Internationalization
Part 5. Content Publishing And Distribution
