
1장 소개
23p
커뮤니케이션을 위한 코드를 작성하기 위한 첫단계는 본능에 의해 코딩하는 것을 멈추고 내가 어떤 생각을 하고 있는지 살펴볼 수 있는 여유를 갖는 것이다
24p
다음 단계는 다른 사람들의 중요성을 인정하는 것이다. 프로그래밍을 통해 만족감을 얻는 자기중심적인 태도보다 동료의 중요성을 인지하고 커뮤니케이션 가능한 코드 작성에 공을 들여야한다
2장 패턴
29p
프로그램을 읽는 사람은 개념과 더불어 세부 사항까지도 이해해야 한다. 세부사항을 이해해야 전체 개념에 대한 그림을 그릴 수 있고, 한편 전체 개념을 이해해야 세부적인 구현 내용을 이해할 수 있기 때문이다.
3장 프로그래밍 이론
33p
프로그램을 잘 짜는 사람은 타인과의 커뮤니케이션을 중시하고, 코드의 과도한 복잡성을 피하면서도 유연성 있는 코드를 작성한다. 커뮤니케이션, 단순성, 유연성의 가치는 프로그래밍을 할 때 내리는 모든 의사 결정에 영향을 미친다
35p
내가 프로그래밍을 시작한 것은 무엇보다 외부의 세계와 커뮤니케이셔나기 위해서였다. 하지만 고집세고, 이해하기 어렵고, 짜증나는 사람들과 상대하고 싶지 않았다
35p
"다른 사람이 이걸보면 어떤 생각을 할까?" 라는 생각을 하면 내 자신과 컴퓨터만 생각하며 코드를 짤 때와는 다른 신경세포가 내 머릿속에서 동작한다. 결국 우리는 사회적 존재이므로 실제 사회적 문제들을 무시하기보다는 고려하는 편이 더 현실적이다.
36p
쓸모없는 점을 지운 그래프는 원본에 비해 참신하고 이해하기도 훨씬 쉽다. 복잡도를 낮추면 프로그램을 읽고 사용하고 수정하는 사람들이 프로그램을 훨씬 빨리 이해할 수 있다.
36p
좋은 프로그램을 작성하기 위해서는 독자층을 고려해야하는 것처럼 좋은 프로그램을 작성하기 위해서는 독자 수준을 고려해야 한다. 프로그램이 독자 수준에서 약간 어려운 정도라면 괜찮을 수도 있지만 복잡도가 ㅓ무 올라가면 다른 사람들이 여러분의 프로그램을 이해할 수 없다
37p
프로그램을 최대한 단순화하라. 의미없는 코드는 모두 제거하라. 설계시에도 과도한 요소는 모두 빼고, 요구사항을 분석해서 꼭 필요한 사항만을 뽑아내라. 과도한 복잡도를 제거하면 코드를 새로운 관점에서 바라볼 수 있다.
37p
때로는 산순화로 인해 프로그램을 이해하기 어려워지는 경우도 있다. 나라면 이러한 경우 단순성보다는 커뮤니케이션을 선택할 것이다. 드물게는 과도한 단순화가 커뮤니케이션을 저해하는 경우도 있다.
38p
유연성이 있으면서도 당장 이득을 얻을 수 있는 패턴을 사용하라. 당장 비용이 들어가지만 앞으로 이득을 얻을 수 있을지 불확실한 패턴의 경우에는 일단 사용을 자제하는 편이 좋다. 이러한 패턴은 일단 사용을 보류했다가, 정말 필요한 때가 오면 그 때 적용하라.
38p
유연성을 높이면 복잡도가 증가한다. 따라서 유연성을 높이기위해서는 최대한 단순성을 추구해야한다.
39p
코드를 수정할 때 함께 바꿔야하는 부분을 최소화해야한다. 지역적 변화만을 일으키는 코드는 커뮤니케이션이 쉽다. 프로그램 전체를 알 필요 없이 그 부분만 보고 이해가 가능하기 때문이다. 지역적 변화 원칙은 여러 패턴의 근간이다.
40p
지역적 변화를 돕는 다른 원칙은 최소 중복의 원칙이다. 같은 코드가 여러 곳에서 반복되면 하나를 바꿀 때 중복된 코드를 모두 바꿔야한다
40p
병렬 클래스 계층(parallel class hierarchy)도 중복의 일종이다. 프로그램상의 어떤 개념을 수정했을 때 2개 이상의 클래스 계층을 수정해야한다면 지역적 변화 원칙 위반이다.
40p
중복을 없애는 한 가지 방법은 프로그램을 여러 작은 부분-짧은 구문, 짧은 메소드, 작은 객체, 작은 패키지 - 으로 나누는 것이다.
41p
지역적 변화의 원칙에 근거한 다른 원칙은 로직과 데이터를 함께 유지하는 것이다. 데이터와 그 데이터를 처리하는 로직을 밀접하게-가급적 같은 메서드 혹은 같은 객체 내에, 최소한 같은 패키지 내부에 배치하라.
41p
프로그램에서 대칭성은 여러곳에 존재한다. add() 메서드가 있는 곳에는 remove() 메서드가 있다. 프로그램에서 대칭성을 찾아내서 명확히 표현해주면, 코드를 읽기가 수월해진다. 프로그램의 절반만 이해하면 나머지 절반은 자연스럽게 이해되기 때문이다
41p
코드의 대칭성은 하나의 아이디어를 프로그램 전체에서 일관된 방식으로 표현하는 통일성이다
42p
때로 대칭성을 찾아서 표현하면 코드의 중복을 제거할 수 있다. 코드 곳곳에서 비슷한 아이디어가 사용되었다면 대칭성에 따라 아이디어를 일관된 방식으로 표현해야한다. 이렇게 되면 하나의 구현으로 통합될 수 있어서 중복되는 구현을 제거하기 쉬워진다.
43p
수행순서가 중요한 구문이나 조건부 구문이 없는 일반 구문의 경우, 선언적 표현을 통해 코드를 작성하는 것이 이해하기 쉽다.
44p
마지막 원칙은 함께 변하는 로직과 데이터를 함께 관리하고, 변화율이 다른 로직과 데이터는 분리하는 것이다. 이때 변화율은 시간적 대칭성으로 볼 수 있다.
44p
변화율은 데이터에도 적용된다. 하나의 객체에 있는 모든 필드는 가급적 함께 변해야한다. 예를 들어 특정 메서드가 수행될 때만 사용되는 필드는 그 메소드의 지역변수로 선언되어야 한다.
45p
변화율은 대칭성의 일종으로 시간적 대칭성이다. 대칭적인 필드를 별도의 객체에 묶어서 대칭성을 표현하면, 코드를 읽는 다른 사람에게 프로그래머의 의도를 잘 전달할 수 있고 중복을 줄일 수 있으며 코드 수정에 대한 영향을 제어하기 쉬워진다.
4장 동기유발
47p
소프트웨어 설계의 원동력은 경제성이다. 소프트웨어는 전체 비용을 줄이는 방향으로 설계되어야한다.
48p
유지비용 = 이해비용 + 수정비용 + 테스트 비용 + 설치 비용
전체비용을 줄이는 한 가지 전략은 유지 비용을 줄일 수 있을 거라 기대하고 초기 개발 비용에 좀더 많은 투자를 하는 것이다. 하지만 이러한 전략은 보통 전체 비용을 절감하지 못한다. 아무리 고민을 많이 하더라도 나중에 수정할 사항까지를 대비해 완벽한 코드를 짜는 것은 불가능하다.
5장 클래스
51p
객체 지향 프로그래밍은 후기 서양 철학의 아이디어를 받아들여 프로그램을 클래스와 객체로 구성한 것이다. 여기서 클래스는 비슷한 성질을 가진 것을 총칭하며, 객체는 클래스가 구체화된 것이다.
51p
클래스: "이 데이터들은 함께 사용되는데, 그에 관련된 로직이 이것이다"라는 이야기를 하고 싶을 때 클래스를 사용한다.
단순한 상위클래스 이름: 클래스 계층의 최상위에 위치하는 클래스 이름은 단순하게 짓는다.
한정적 하위클래스 이름: 상위클래스와의 유사점과 차이점을 분명히 드러내는 이름을 사용한다.
53p
클래스 계층을 사용하면 코드를 읽기 어려워진다. 하위클래스를 이해하기 위해서는 상위클래스도 이해해야 하기 때문이다. 클래스는 객체 지향 프로그램의 설계 요소 중 비교적 값이 비싼 편이므로, 뭔가 의미 있는 작업에만 클래스를 사용해야한다. 다른 클래스의 크기를 너무 비대하게 하지 않으면서 클래스의 수를 줄이는 것은 프로그램을 개선한 것이라 할 수 있다.
54p
클래스 이름을 지을 때는 간결성과 표현성 사이에서 고민하게 된다. ... 이런 딜레마를 벗어나는 방법은 메타포(은유)를 사용하는 것이다. 객체의 기능을 사람들에게 설명하다보면 그 객체를 표현할 풍부한 연상 이미지들과 함께 새로운 이름이 떠오른다.
56p
클래스 이름은 코드의 내용을 반영해야한다.
56p
구현이 아니라 인터페이스에 맞춰 코딩하라. 다시말해 설계상의 결정을 필요이상으로 노출하지 말라.
56p
인터페이스 추가에는 비용이 발생한다. 인터페이스를 통해 유연성을 얻을 수 있는 경우에만 인터페이스에 비용을 지불해야한다.
57p
인터페이스를 사용하게 된 경제적 이유는 소프트웨어는 예측하기 어렵다는 점을 들 수 있다.
60p
인터페이스 계층과 클래스 계층은 서로 배타적인 것이 아니다. 인터페이스를 통해 "이 기능은 이렇게 사용하세요"라고 전달하고, 상위클래스를 통해 "이 기능을 이렇게 구현해봤습니다"라고 전달하는 것도 가능하다.
62p
함수형 스타일 연산은 상태를 변화시키지 않으며 새로운 값을 생성한다. 일시적이더라도 고정적인 상황을 표현하고 싶다면 함수형 스타일이 적절하고, 상황이 변하는 경우라면 상태(state)를 사용하는 편이 낫다.
63p
변하지 않는 객체를 참조하고 있는 변화하는 상태를 갖고 있는 객체는 위와 같다.
64p
값 스타일 객체를 사용할 때의 문제점은 성능이다. 모든 객체를 매번 새로 생성하면 메모리 관리 시스템에 부담을 줄 수 있다. 프로그램을 가장 효과적으로 표현하는 방법은 변화하는 상태를 가진 객체와 값 스타일의 객체를 적절히 섞어서 사용하는 것이다.
68p
하위 클래스를 올바르게 사용하기 위한 키 포인트는 상위클래스의 로직을 여러 개의 메소드로 잘게 쪼개는 것이다.
71p
수행경로가 다양한 프로그램이 그렇지 않은 프로그램에 비해 결함을 갖고 있을 확률이 높은 것은 사실이다. 따라서 조건문의 수가 많으면 많을수록 프로그램의 안정성이 떨어지는 경향이 있다.
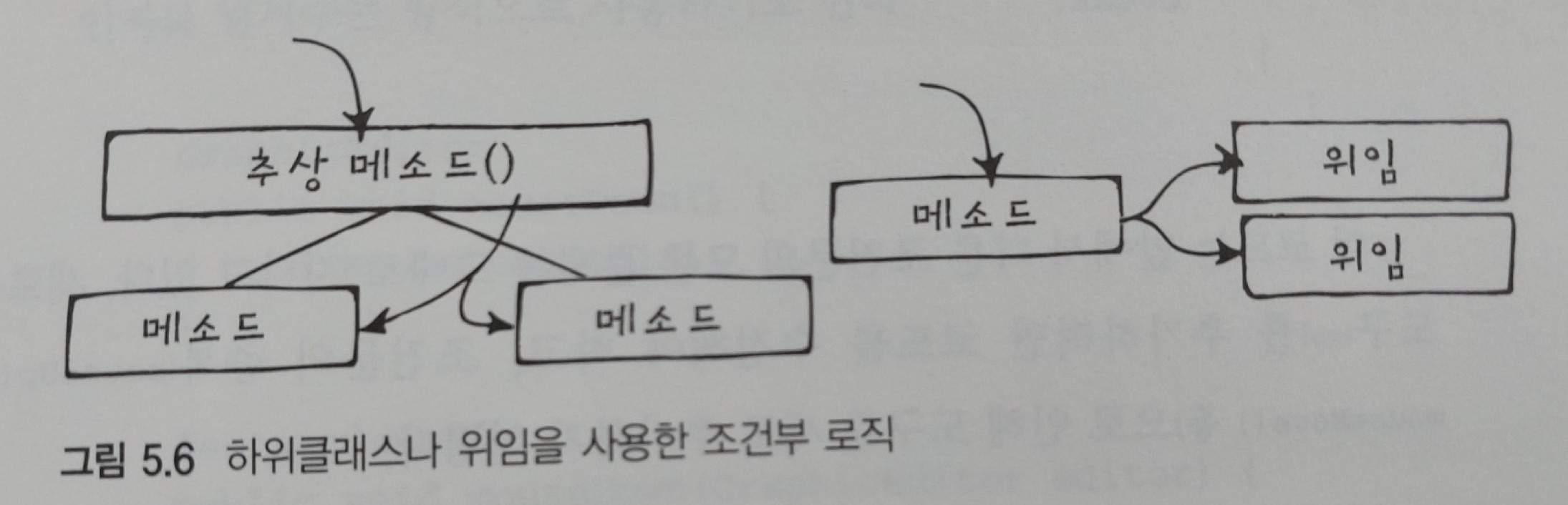
73p
하위클래스나 위임 중 더 적합한 방법을 사용해서 조건문을 메시지로 바꾸면 해결할 수 있다. 중복되는 로직이나 분기문의 결과에 따라 로직이 달라지는 경우, 보통 명시적인 로직 대신 메시지를 사용하는 것이 더 좋다. 요컨데 조건문은 단순성과 지역성(하나의 클래스만 수정)에서 장점이 있지만, 광범위하게 사용되는 경우 이러한 장점이 문제가 될 수도 있다.
78p
어떤 객체에도 적합하지 않은 기능은 어디에 구현해야 할까? 한 가지 방안은 빈 클래스를 하나 만들어서 정적 메서드로 구현하는 것이다. 라이브러리 클래스는 인스턴스화가 불가능한, 라이브러리 메서드만을 갖고 있는 클래스다.
6장 상태
83p
컴퓨터 분야의 선구자들이 프로그래밍에 사용할 메타포를 정할 때, 그들은 시간에 따라 변하는 상태를 생각해냈다. 인간의 두뇌는 선천적, 후천적으로 상태를 다루는 데 익숙하다.
83p
함수형 프로그래밍 언어에는 변화하는 상태의 개념이 없다. 단일 할당이나 변수를 사용하지 않는 프로그래밍에서는 수많은 효과적인 사고 기법들을 포기해야한다.
83p
효과적으로 상태를 관리하기 위한 키포인트는 유사한 상태를 묶어서 관리하고 각 상태를 별도로 관리하는 것이다. 두 가지 상태가 유사한지 알 수 있는 두 개의 단서로는 1) 두 개의 상태가 동일한 연산 안에서 사용되고, 2) 동일한 시점에 생성되고 소멸되는지 보면 된다. 함께 사용되고 생성 소멸 시점이 동일한 두 가지 상태를 밀접하게 관리하는 것은 좋은 아이디어일 가능성이 높다.
84p
하나의 프로그래밍 언어는 저장된 값에 대한 접근 (accessing stored value)과 계싼(invoking computation)으로 나눌 수 있다. 메모리 접근은 현재 저장된 값을 반환하는 일종의 계산이다. 한편 계산은 아직 저장되지 않은 메모리 값을 읽는 일종의 값 접근이다.
84p
객체의 목표 중 하나는 저장소를 관리하는 것이다. 각 객체는 조그마한 메모리를 갖고 있는 별도의 작은 컴퓨터라고 볼 수 있다.
85p
직접 접근이 많은 코드는 원활한 커뮤니케이션을 방해하는 요소이다.
86p
내가 사용하는 기본 정책은 클래스 내부(내부 클래스 포함)에서는 직접 접근을 허락하지만 클래스 외부에서는 간접 접근을 사용하는 것이다.
88p
가변 상태는 공용 상태에 비해 훨씬 유연하지만, 코드 커뮤니케이션이 쉽지 않다. 객체가 제대로 동작하기 위해 꼭 필요한 데이터 요소는 어떤 것인가? 이 질문에 답하기 위해서는 코드를 주의 깊게 읽고, 때로는 수행 과정을 지켜봐야만 한다.
90p
가능하다면 공용 상태를 사용하라. 경우에 따라 어떤 필드가 필요할지 확실치 않은 경우에만 가변 상태를 사용하라.
91p
변수의 생명기간은 가급적이면 변수의 범위에 가까워지도록 노력하라. 또한 같은 범위에서 정의되는 변수들은 모두 같은 생명기간을 갖게하라.
95p
파라미터 사용으로 인해 발생하는 의존성은 영구적인 참조를 통해 발생하는 의존성보다 약하다. 하나의 객체에서 다른 객체에 대한 여러 메세지같은 파라미터를 필요로 한다면, 그 파라미터를 호출되는 객체에 포함시키는 것이 나을 수도 있다. 파라미터는 객체를 연결하는 얇은 실과 같지만, 소인국의 걸리버 이야기처럼 가는 실이라도 그 수가 너무 많아지면 나중에는 문제가 될 수 있다.
99p
파라미터 객체를 사용하면 코드가 짧아지고, 의도를 좀더 명확히 전달할 수 있으며, 알고리즘을 쉽게 표현할 수도 있다. 파라미터 객체를 사용하지 않고 확대 축소를 구현하려면 필요한 곳마다 파라미터를 반복해서 사용해야 하고, 구현상 실수를 범하기도 쉽다. 코드는 좀 더 읽기 쉽고, 잘 나뉘어 있고, 테스트하기 ㅎ쉬워야 한다. 파라미터 객체는 이 모든 측면에서 코드를 향상시킨다.
101p
상수를 사용하는 것이 중요한 이유는 실수를 줄일 수 있기 때문이다.
103p
요컨데 나는 변수 이름을 통해 변수의 역할을 전달한다. 변수에 관한 다른 중요한 정보 - 생명기간, 범위, 타입 - 는 일반적으로 문맥을 통해 전달할 수 있다.
104p
변수 초기화에는 몇 가지 생각해볼 점이 있다. 먼저 초기화는 가급적 선언과 함께 하는 것이 좋다. 초기화와 선언을 함께 하면, 한 곳에서 변수에 대한 여러 정보를 얻을 수 있다. 다른 문제는 성능이다. 초기화에 드는 비용이 비싼 변수의 경우, 생성과 초기화를 분리하는 것이 나을 수 있다.
7장 행위
116p
코드를 읽고 이해하기 가장 쉬운 경우느 프로그램의 각 문장이 순서대로 하나씩 수행될 때다. 독자는 일반 산문을 읽듯이 코드를 읽으며 프로그래머의 의도를 파악할 수 있다. 주요 흐름을 최대한 명료하게 표현하라. 다른 경로는 예외를 사용해서 표현하면 된다.
116p
프로그램에는 주요 흐름이 있지만 때로는 주요 흐름에서 벗어나야 할 때가 있다. 보호절을 사용하면 간단한 지역적 예외 상황을 지역적인 변화만을 수반하며 표현할 수 있다.
118p
보호절은 여러 개의 조건이 있을 경우 특히 유용하다. 보호절의 포인트는 보통 경우와 예외 경우 처리의 차이점을 부각시키는 것이다.
120p
하위 수준의 예외는 문제를 진단하는 데 유용한 정보를 제공해주는 경우가 많다. 하위 수준 예외를 상위 수준 예외로 포장하라.
8장 메서드
126p
추상화 수준이 비슷한 메서드 호출로 하나의 메서드를 구성하라. 잘못 구성된 메서드는 상이한 추상화 수준의 메서드를 호출한다.
127p
메서드를 구성할 때는 추측이 아닌 사실에 근거하라. 일단 동작하는 코드를 만들고 구성방식을 결정하라. 코드 구성에 미리 시간을 들이게 되면, 구현 도중 새로 알게 되는 사실 때문에 했던 일들을 번복하는 경우가 많다.
129p
메서드 이름을 지을 때는 그 메서드를 호출하는 입장에서 생각해보라. 왜 이 메서드를 사용해야 하는가? 메서드 이름에서 이 질문에 대한 답을 얻을 수 있어야 한다. 메서드 이름은 그 메서드를 호출하는 코드가 표현하려 하는 바에 도움을 줄 수 있도록 지어야한다.
130p
가시성을 선택할 때는 두 가지 비용을 고려해야 한다. 하나는 미래의 유연성이다. 외부에 드러나는 인터페이스가 많지 않은 경우 미래에 인터페이스를 수정하는 것은 어렵지 않다. 다른 고려할 사항은 객체를 사용하는데 들어가는 비용이다. 노출된 인터페이스가 많지 않은 객체를 사용할 경우, 사용하는 측에서는 필요 이상으로 많은 작업을 해야한다. 적절한 가시성을 선택하기 위해서는 위의 두 가지 비용을 균형있게 맞추는 것이 중요하다.
131p
먼저 가장 제한적인 가시성을 선택한 후, 필요에 따라 조금씩 가시성을 높여라. 반면 만약 어떤 메서드의 가시성이 불필요하게 높다면 가시성을 낮춰라.
132p
메서드 이름을 따럿 클래스 이름을 정한다. 예를 들어complexCalculation()은ComplexCalculator가 된다.
135p
메서드 오버로드는 파라미터 타입만 다를 뿐, 같은 연산을 수행해야 한다. 만약 메서드마다 다른 반환 타입을 사용한다면 코드 읽기가 너무 어려워진다. 의도가 다르다면 새로운 이름을 갖는 메서드를 사용하는 것이 좋다. 별도의 연산에 대해서는 각각 다른 이름을 사용하라.
136p
프로그래머는 코드의 이름과 구조를 통해 최대한 많은 정보를 전달하는 것이 좋다.
137p
도우미 메서드의 목적은 당장 관련도가 떨어지는 세부구현을 숨기고 메서드 이름을 통해 프로그래미의 의도를 나타냄으로써 보가잡하고 거대한 연산 코드를 좀 더 읽기 좋게 하기 위함이다.
140p
변환을 사용하는 이유는 다른 프로토콜을 사용하는 객체를 얻기 위함이다
struct Money {
var amount: Double
var currency: String
// 변환 생성자: 문자열을 받아 Money 객체를 만듭니다.
init?(fromString string: String) {
let components = string.split(separator: ' ')
guard components.count == 2,
let amount = Double(components[0]),
let currency = components.last else {
return nil
}
self.amount = amount
self.currency = String(currency)
}
}
// 예시 사용
let moneyString = "100 USD"
if let myMoney = Money(fromString: moneyString) {
print("금액: \(myMoney.amount), 통화: \(myMoney.currency)")
} else {
print("변환 실패: 올바른 형식의 문자열을 입력하세요.")
}