-
Attention 메커니즘을 이해하고 어떤 문제를 해결했는지 알 수 있다.
- Attention 메커니즘이 무엇이며 기계번역(Machine Translation) 성능을 끌어올렸는지 알 수 있다.
- Attention 으로도 해결할 수 없는 RNN 기반 모델의 단점에 대해서 알 수 있다.
-
Transformer의 장점과 주요 프로세스인 Self-Attention에 대해 이해하고 설명할 수 있다.
- 트랜스포머를 발표한 논문 제목은 왜 "Attention is All You Need"인지 설명할 수 있다.
- Positional Encoding을 적용하는 이유에 대해서 설명할 수 있다.
- Masked Self-Attention가 트랜스포머 구조 중 어디에 적용되며 어떤 역할을 하는지 설명할 수 있다.
- 기존 RNN과 비교하여 Transformer가 가지는 장점에 대해서 설명할 수 있다.
-
GPT, BERT 그리고 다른 모델에 대해서 개략적으로 설명할 수 있다.
- GPT(Generative Pre-Training)
사전 학습된 언어 모델(Pre-trained LM)의 Pre-training과 Fine-tuning은 무엇이고 각각 어떤 종류의 데이터셋을 사용하는 지 설명할 수 있다. - GPT는 Transformer를 어떻게 변형하였는지 설명할 수 있다.
- GPT(Generative Pre-Training)
-
BERT(Bidirectional Encoder Representation by Transformer)
- BERT는 Transformer를 어떻게 변형하였으며 GPT와의 차이 무엇인지 알 수 있다.
- MLM(Masked Language Model)은 무엇인지 이해할 수 있다.
- NSP(Next Sentence Prediction)은 무엇인지 이해할 수 있다.
-
최근 언어 모델의 발전은 어떻게 진행되고 있는지 알 수 있다.
❔QnA
-
rnn
단점: 기울기 소실(->LSTM, GRU)
병렬처리 불가
👇
TRANSFORMER -
SOTA(최신 자연어 처리 모델) 모두 트랜스포머 기반56678
모든 토큰을 동시에 입력받아 병렬 연산하기 때문에 GPU 연산에 최적화 되어 있습니다.
트랜스포머에서는 병렬화를 위해 모든 단어 벡터를 동시에 입력받습니다.
컴퓨터가 이해할 수 있도록 단어의 위치 정보를 제공하기 위한 벡터를 따로 제공해주어야 합니다.
Self-Attention (셀프-어텐션)
중요!
쿼리: 분석하고자 하는 단어, 질문의 주체
키: 각각의 단어
밸류: 단어들에 연결된 의미
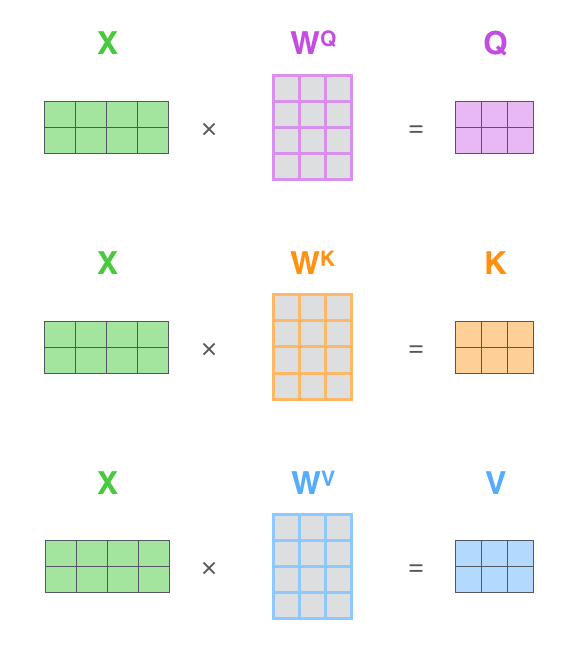
- x는 임베딩, 위치정보를 준 아이들이다.
가중치 매트릭스(행렬)을 임베딩한 결과와 연산해서 쿼리, 키, 밸류 벡터를 만들어낸다.
I am a student
-
I를 알아보려면 I쿼리를 사용해 질문을 던지고 다른 단어는 키 값을 이용.
유사도가 큰 키 밸류와 내적하면 큰 유사도가 도출됨. (코사인머시기)
벡터의 차원에 루트를 씌워준 값을 나눠줌(smoothing)
여기에 softmax를 취하면 다 더하면 1이 되는 값으로 변경됨 -
value와 (키 각각의 의미벡터) 2번에서 구한 유사도를 곱해줌
모두 다 더해서 하나로 만들어줌 -> 첫번째 단어의 의미 벡터 생성
- 실제로는 한번에 처리됨
1. 먼저 쿼리 행렬(Q)과 키 행렬(K)을 내적합니다.
2. 결과로 나오는 행렬의 요소를 루트dk(smoothing) 로 나누어 줍니다.
3. 행렬의 각 요소에 Softmax를 취해줍니다.
4. 마지막으로 밸류 행렬(V)과 내적하면 최종 결과 행렬(Z)이 반환됩니다Multi-Head Attention
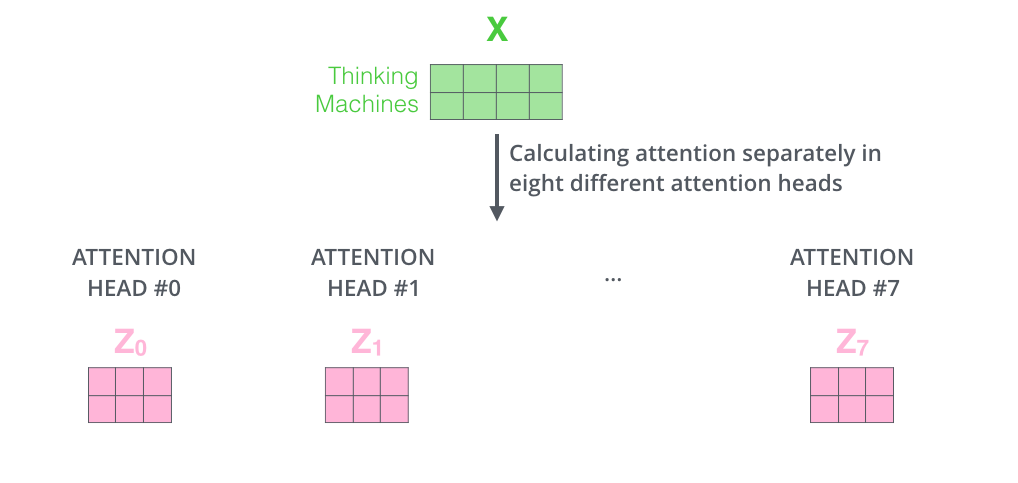
Self-Attention 을 동시에 여러 개로 실행
논문에서는 8개의 Head를 사용하였습니다.
8번의 Self-Attention을 실행하여 각각의 출력 행렬 을 만들어냅니다.
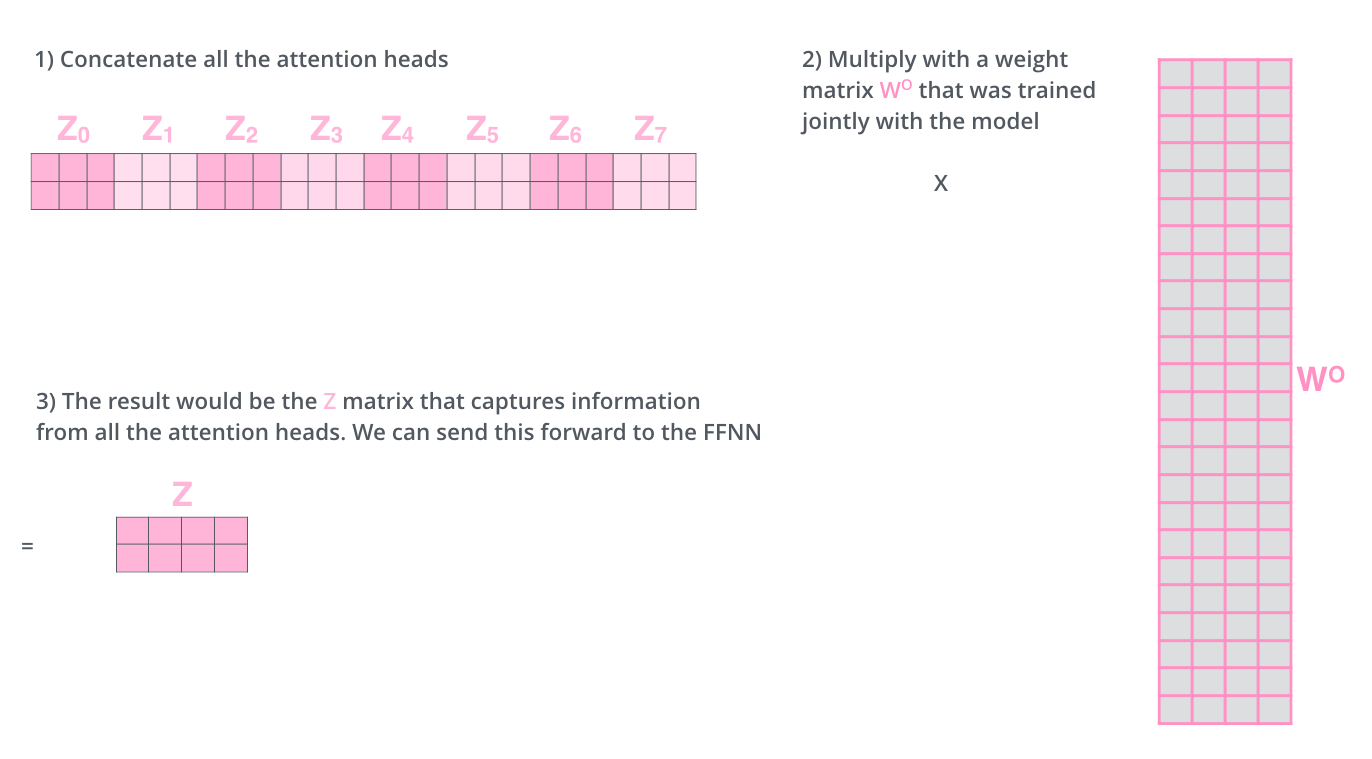
출력된 행렬 은 이어붙여집니다(Concatenate).
처음 Z 벡터의 크기로 맞춰주기 위해 Z의 열과 같은 가중치를 곱해줍니다.
그러면 Z 크기의 벡터 나옴!
Layer normalization과 Skip connection
정보 잘 나오라고 연산작업
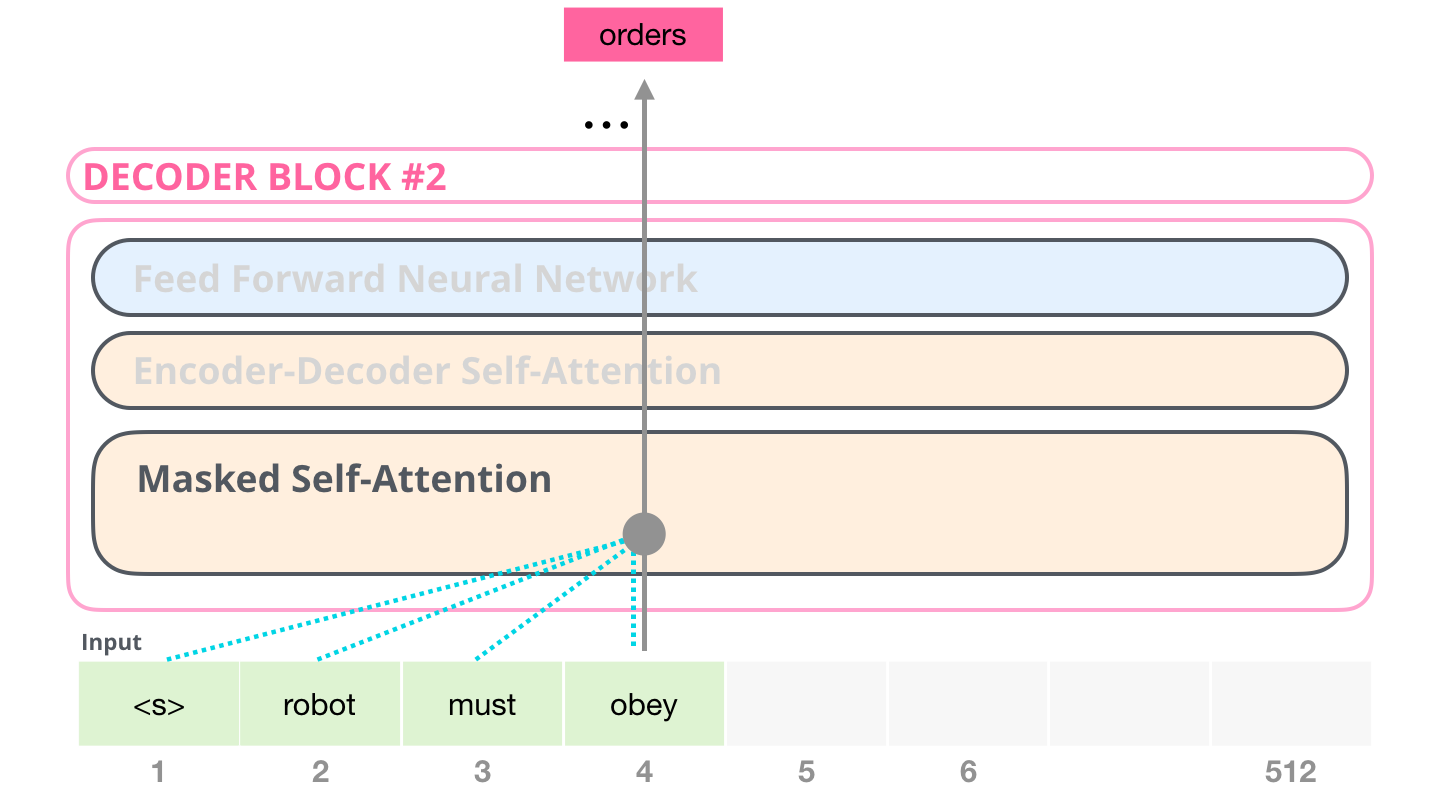
Masked Self-Attention!
뒷내용으로 앞 단어를 추측하지 못하게 가려줌
{kind=link}
뒷 단어에 엄청나게 큰 값을 더해줘서 먹통되게 함

softmax해주면 0이 나와서 연산이 안됨

Encoder-Decoder Attention
번역할 문장과 번역되는 문장의 정보 관계를 엮어주는 부분이 바로 이 부분입니다.
❗ 학습과 사용은 별개다
인코더 마지막 레이어에서 나온 키, 밸류 값
Q는 내가
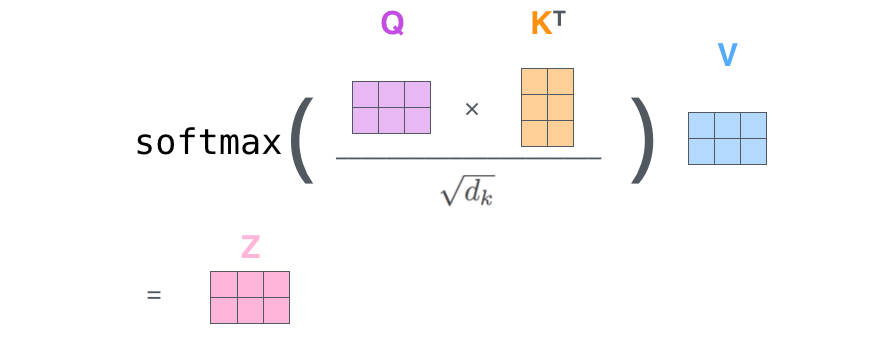
학습구조!
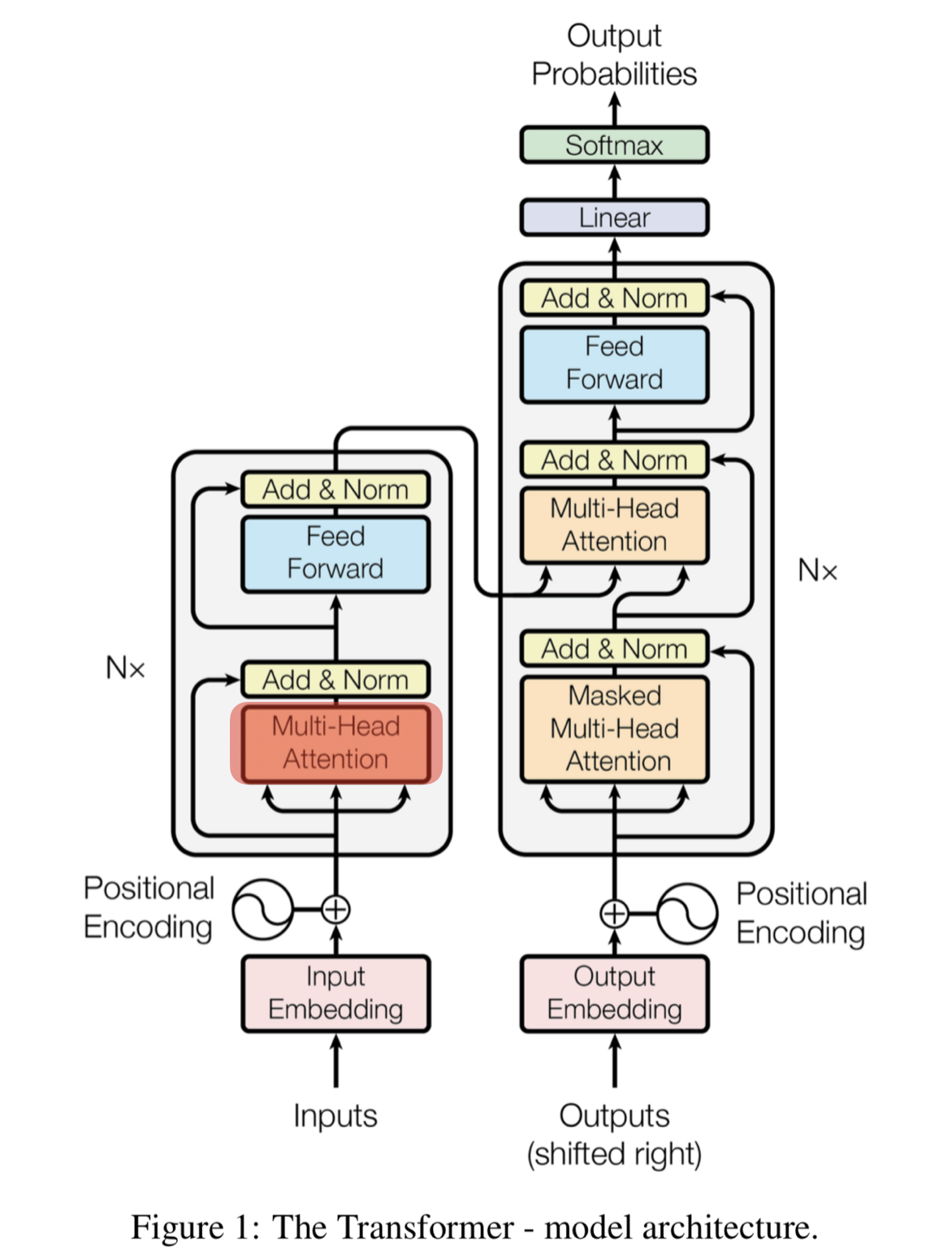
input embedding : 나는 학생이다.
output embedding : I am a student.
학습하는 과정이기 때문에 해석본도 넣어줘야 얘네가 아 이게 이런 구조구나 하고 학습을 함.
오후 QnA
-
RNN
-
Transformer
a. 인코더 / 디코더
b. 나는 학생입니다 / i am a student -
인코더
a. multi-head attention
b. ffnn(feed forward) -
디코더
a. multihead attention
b. encoder-decoder attention
c. ffnn -
transformer는 어떻게 rnn의 단점을 해결했을까?
a. 병렬처리 불가능
b. rnn을 없앰, 행렬 연산 -> 한 번에 연산 -
단어를 한 번에 입력(위치정보 x)
a. 위치 -> positional encoding 필요 -
self attention (multi-head attention)
a. query: 분석하고자 하는 단어
b. key:각각의 단어
c. value: 각각의 단어의 의미
d. 목적: 문장 단어 사이의 관계
e. 일종의 앙상블 효과 (여러 관점에서 context파악) -
디코더 masked multi-head attention
a. 타깃 단어 뒤에 나오는 단어 가려줌
b. -10억 더해줌
c. softmax하면 0이됨
d. 목적
i. query, key, value
ii. 번역할 언어 문장 단어 관계 파악 -
encoder-decorder attention
a. 목적
i. query: maskedmulti-head 디코더
ii. key, value:인코더
iii. 목적: 번역할 언어, 번역될 언어 뜻 매칭
iv. 나는 학생입니다 -> i am a student -
GPT > 디코더 위주 학습
a. 트랜스포머의 디코더 12개
b. 사전학습 방법
i. 레이블링 되지 않은 데이터를 학습
디코더는 마스킹이 되어있으니까 순서 없는 거 부터 학습
ii. 다음에 나올 단어 확률 높아지도록 학습 -
bert > 인코더 위주
a. 트랜스포머의 인코더 12개
b. 사전학습 방법: MLM, NSP
c. MLM : 빈칸 채우기(단어 랜덤으로 마스킹해서 그 단어 유추)
인코더는 마스킹을 안하니까! 랜덤 마스킹해도 유추 가능
d. NSP: ?? 못들음 ㅠ
12: 사전 학습 왜 함?
a. 미리 많이 학습 시켜놓고, 가져다 쓰는 것 (성능👍)
b. fine tuning, 내가 해결하고자 하는 학습에 맞게 미세하게 조정
- transformer에서 ffnn의 역할이 정확히 뭔지 알수 있을까요?
a. 활성함수: relu - 큰 흐름을 따라 공부합세~!
