서비스 API 카테고리 개요
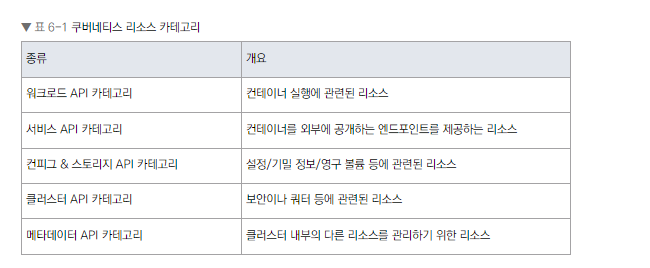
쿠버네티스 리소스는 5가지 카테고리
- 워크로드, 서비스, 컨피그 & 스토리지, 클러스터, 메타데이터 API
- 서비스 API 카테고리는 컨테이너를 외부에 공개하는 엔드포인트를 제공하는 리소스
서비스 API 카테고리의 주요 리소스
- 사용자가 직접 사용하는 것은 L4 로드 밸런싱을 제공하는 서비스 리소스와 L7 로드 밸런싱을 제공하는 인그레스 리소스, 두 종류
- 서비스 (L4 로드 밸런싱)
- 인그레스 (L7 로드 밸런싱)
쿠버네티스에서의 의미
- 쿠버네티스에서 인그레스는 클러스터 외부에서 내부 서비스로 HTTP와 HTTPS 트래픽을 라우팅하는 API 오브젝트입니다.
주요 특징
- L7(응용 계층) 로드 밸런싱을 제공합니다.
- 외부에서 클러스터 내부 서비스로의 진입점 역할을 합니다.
- URL 경로나 호스트 기반의 라우팅 규칙을 정의할 수 있습니다.
인그레스의 역할
- 외부 트래픽을 적절한 내부 서비스로 전달합니다.
- SSL/TLS 종료를 처리할 수 있습니다.
- 이름 기반의 가상 호스팅을 지원합니다.
- 복잡한 트래픽 라우팅 규칙을 구현할 수 있습니다.
인그레스는 쿠버네티스 클러스터에 진입하는 트래픽을 관리하고 제어하는 "관문" 또는 "진입로"의 역할을 한다고 볼 수 있습니다. 이를 통해 외부 사용자나 시스템이 클러스터 내부의 서비스에 안전하고 효율적으로 접근할 수 있게 해줍니
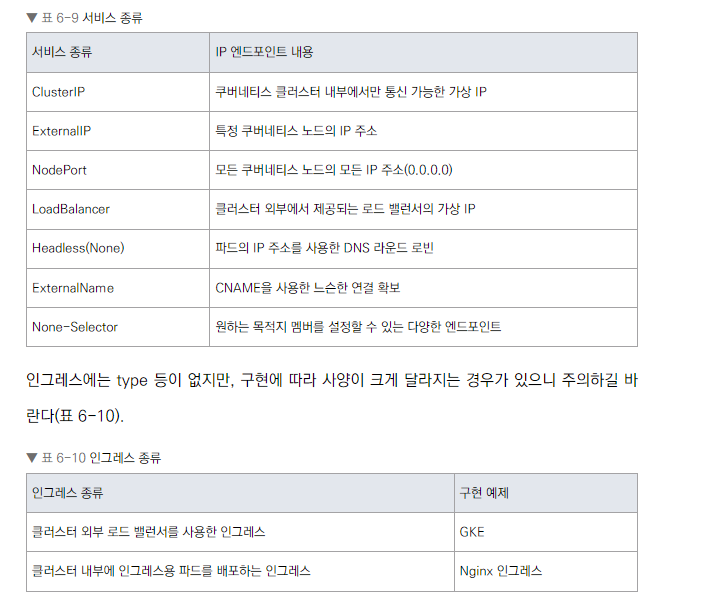
서비스 타입
- ClusterIP: 클러스터 내부 통신용
- ExternalIP: 클러스터 외부에서 접근 가능한 IP 제공
- NodePort: 노드의 특정 포트를 통해 서비스 노출
- LoadBalancer: 클라우드 제공자의 로드 밸런서 사용
- Headless (None): 클러스터 IP 없이 서비스 제공
- ExternalName: 외부 서비스에 대한 별칭
- None-Selector: 수동으로 엔드포인트 지정
추가 설명
- 서비스는 클러스터 내/외부 접근을 위한 가상 IP와 엔드포인트 제공
- 컨테이너 간 통신, 파드 IP 주소, 클러스터 내부 네트워크에 대한 이해가 중요
요약
- 쿠버네티스의 서비스 API 카테고리는 컨테이너를 외부에 노출하고 내/외부 통신을 관리하는 중요한 역할을 합니다. 다양한 서비스 타입을 통해 애플리케이션의 요구사항에 맞는 네트워크 구성이 가능하며, 이를 이해하는 것이 쿠버네티스 네트워킹의 핵심
쿠버네티스 클러스터 네트워크와 서비스
클러스터 (Cluster)
- 쿠버네티스의 가장 큰 단위 구성요소입니다.
- 여러 노드(물리적 또는 가상 머신)의 집합입니다.
- 전체 애플리케이션 인프라를 관리하는 단위입니다.
노드 (Node)
- 클러스터 내의 개별 머신입니다.
- 워커 노드와 마스터 노드로 구분될 수 있습니다.
- 실제 워크로드(파드)를 실행하는 곳입니다.
파드 (Pod)
- 쿠버네티스의 가장 작은 배포 단위입니다.
- 하나 이상의 컨테이너 그룹입니다.
- 노드 위에서 실행됩니다.
관계
- 클러스터 > 노드 > 파드 > 컨테이너
파드 내부 컨테이너 통신
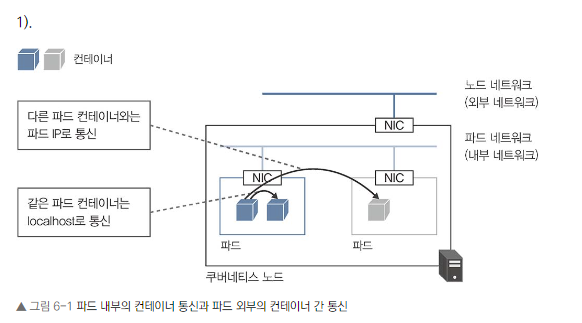
- 같은 파드 내 컨테이너들은 동일한 IP 주소를 공유합니다.
- 같은 파드 내 통신: localhost 사용
- 다른 파드와의 통신: 파드의 IP 주소 사용
쿠버네티스 클러스터 내부 네트워크
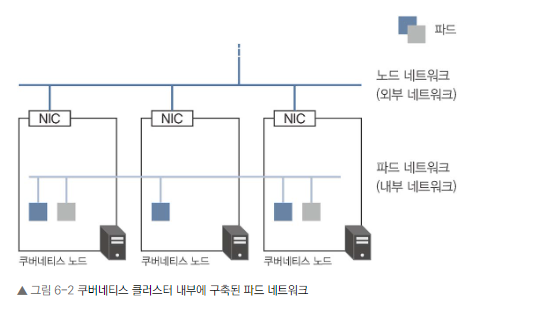
- 클러스터 생성 시 자동으로 내부 네트워크 구성
- 쿠버네티스 클러스터는 클러스터를 생성하면 노드상에 파드를 위한 내부 네트워크가 자동으로 구성된다
- CNI(Container Network Interface) 플러그인으로 구현
- 노드별로 다른 네트워크 세그먼트 사용
- VXLAN, L2 Routing 등으로 노드 간 통신 가능
내부 네트워크의 특징
- 클러스터 전체 네트워크를 자동으로 노드별로 분할
- 사용자의 수동 설정 불필요
- 파드 간 직접 통신 가능
서비스 사용의 장점
- 파드에 대한 트래픽 로드 밸런싱
- 서비스 디스커버리와 클러스터 내부 DNS 제공
요약
- 쿠버네티스의 네트워킹은 복잡해 보이지만, 기본적으로 자동화되어 있어 사용자 친화적
- 파드 간 통신은 기본적으로 가능하지만, 서비스를 사용함으로써 로드 밸런싱과 서비스 디스커버리 같은 중요한 기능을 얻을 수 있음.
- 이러한 네트워크 구조와 서비스의 이점을 이해하는 것이 쿠버네티스를 효과적으로 사용하는 데 중요
파드에 트래픽 로드 밸런싱

서비스의 로드 밸런싱 기능
- 여러 파드에 트래픽을 분산시킵니다.
- 파드의 IP 주소가 동적으로 변하더라도 자동으로 관리합니다.
- 서비스를 사용하면 여러 파드에 대한 로드 밸런싱을 자동으로 구성할 수 있다. 또한, 서비스는 로드 밸런싱의 접속 창구가 되는 엔드포인트도 제공
서비스의 엔드포인트
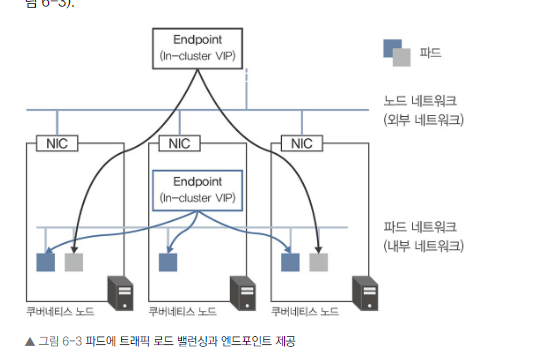
- 로드 밸런싱의 접속 창구 역할을 합니다.
- 서비스는 로드 밸런싱의 접속 창구가 되는 엔드포인트도 제공한다. 엔드포인트는 외부 로드 밸런서가 할당하는 가상 IP 주소(Virtual IP 주소)나 클러스터 내부에서만 사용할 수 있는 가상 IP 주소(ClusterIP) 등 여러 가지 종류를 제공
- 가상 IP 주소(VIP)를 제공합니다 (예: ClusterIP).
서비스 생성 예제
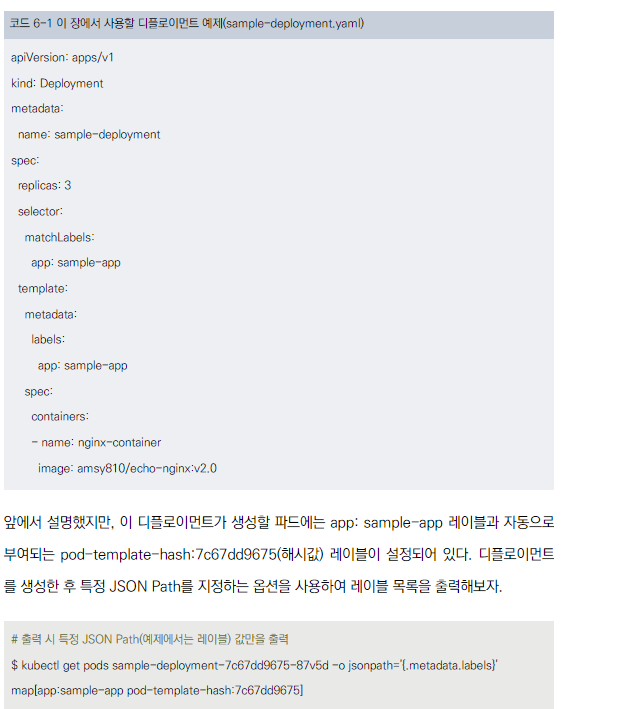
- Deployment를 통해 여러 파드를 생성합니다.
- Service 리소스를 정의하여 이 파드들에 대한 로드 밸런서를 생성합니다.
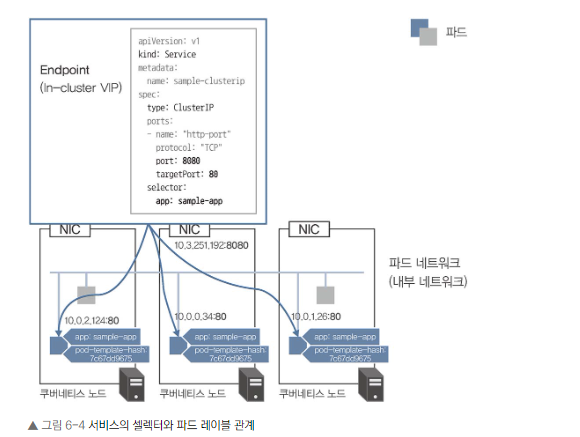
- 엔드포인트의 서비스 종류에 ClusterIP를 사용하는 서비스를 생성
- 서비스 종류는 나중에 자세히 설명하겠지만, ClusterIP는 클러스터 내부에서만 사용 가능한 가상 IP를 가진 엔드포인트를 제공하는 로드 밸런서를 구성.
- 서비스는 spec.selector에 정의할 셀렉터 조건에 따라 트래픽을 전송한다.
- 그림 6-4의 예제에서는 app: sample-app 레이블을 가진 파드에 트래픽을 로드 밸런싱하여 전송
서비스 동작 확인

- 파드의 IP 주소 확인
- 서비스의 엔드포인트 확인 (Endpoints 항목)
- 실제 요청을 보내 로드 밸런싱 확인
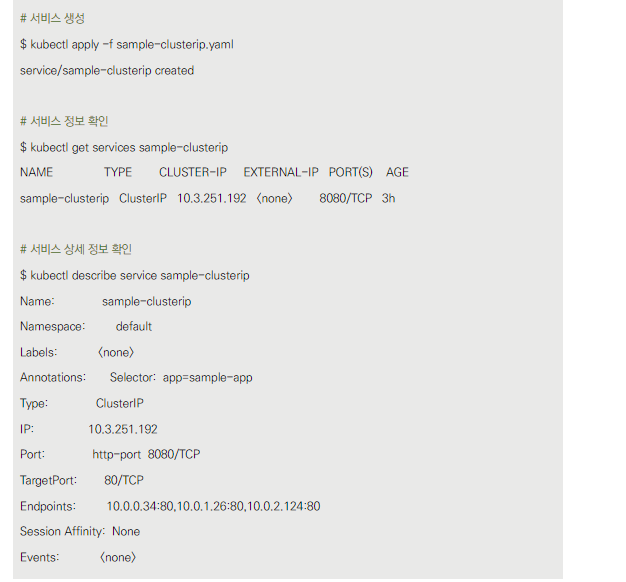
-
다음으로, 생성된 서비스 상세 정보를 출력하면 Endpoints 항목에서 트래픽의 목적지 IP 주소(그리고 포트)를 확인할 수 있다.
-
방금 확인한 app: sample-app 레이블을 가진 파드 IP 주소가 같기 때문에 트래픽 전송이 셀렉터 조건에 따라 선택된 것을 확인할 수 있다.
-
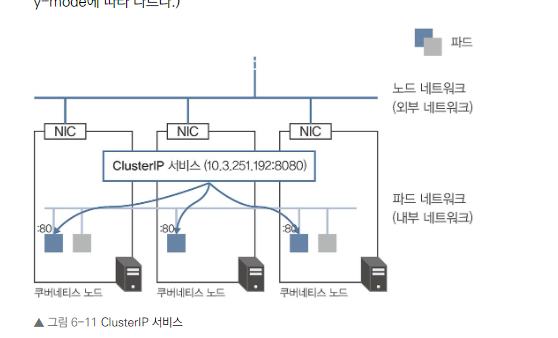
또한, 로드 밸런싱을 위한 엔드포인트의 가상 IP는 CLUSTER-IP 항목이나 IP 항목에서 10.3.251.192가 할당된 것을 확인할 수 있다.
-
클러스터 내부에서만 접근 가능한 가상 IP 제공
-
셀렉터를 통해 트래픽을 전송할 파드 선택
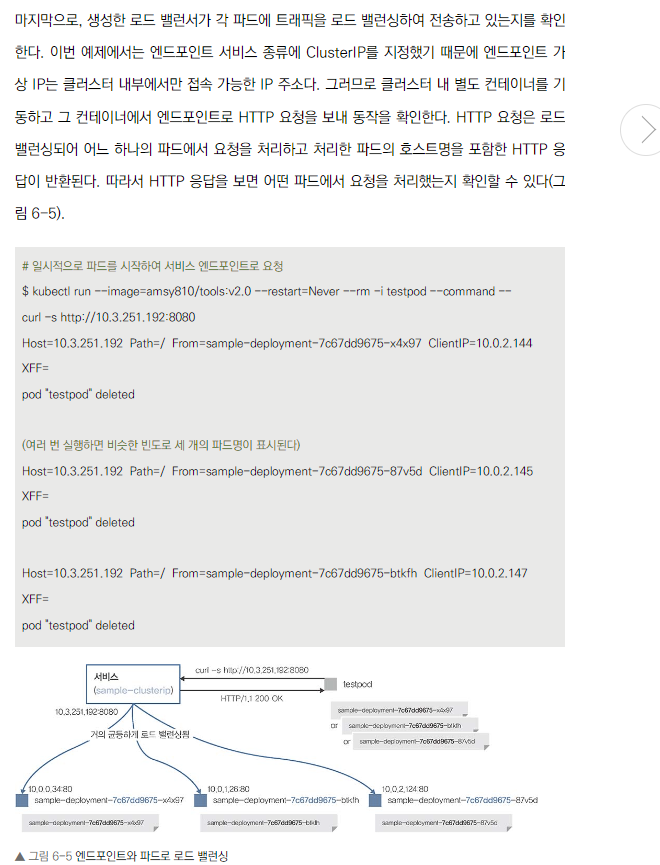
로드 밸런싱 확인 목적
- 생성한 서비스(로드 밸런서)가 각 파드에 트래픽을 적절히 분산하는지 테스트
ClusterIP 서비스의 특징:
- 클러스터 내부에서만 접근 가능한 가상 IP 제공
테스트 방법
- 클러스터 내부에 별도의 임시 컨테이너 생성
- 이 컨테이너에서 서비스의 엔드포인트로 HTTP 요청 전송
로드 밸런싱 동작
- HTTP 요청이 여러 파드 중 하나로 전달됨
- 처리한 파드의 호스트명이 HTTP 응답에 포함되어 반환
확인 포인트
- HTTP 응답을 통해 어떤 파드가 요청을 처리했는지 식별 가능
- 여러 번 요청을 보내 다른 파드들이 균형있게 요청을 처리하는지 확인
여러 포트 할당
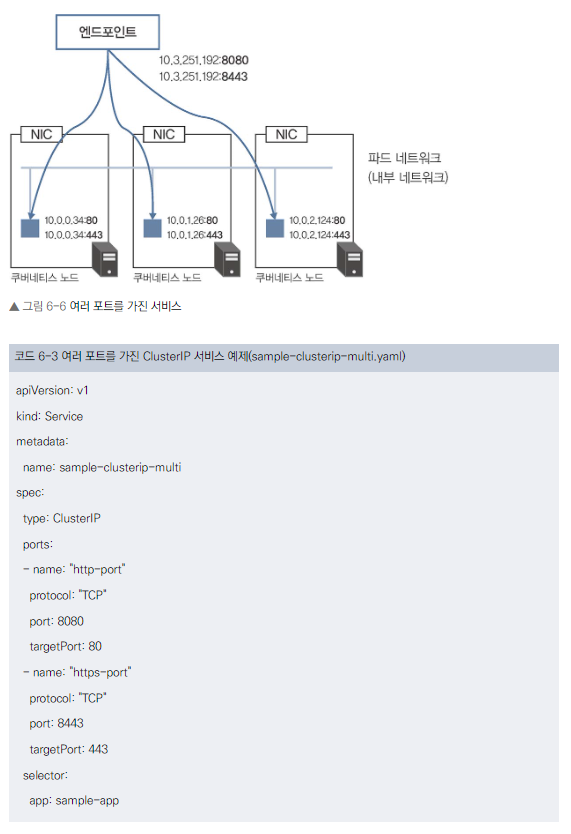
- 하나의 서비스에 여러 포트 할당 가능
- 예: HTTP(8080)와 HTTPS(8443) 동시 지원
여러 포트를 가진 ClusterIP 서비스 예제
- HTTP: 8080 포트(서비스) -> 80 포트(파드)
- HTTPS: 8443 포트(서비스) -> 443 포트(파드)
- 주의: 예제의 파드에서는 443 포트가 실제로 열려있지 않음
이름을 사용한 포트 참조
- 파드의 포트에 이름 지정 가능
- 서비스에서 포트 이름으로 targetPort 참조 가능
- 파드의 포트 정의에 이름을 지정해 놓으면 이름을 사용하여 참조할 수 있다.
- 예제에서는 디플로이먼트의 포트 정의에서 80번 포트를 http라고 명명하고,
- 서비스에서 참조할 때는 targetPort에서 http로 참조한다. 이 기능을 사용하면 다른 목적지의 포트 번호를 처리하는 것도 할 수 있다.
이름이 붙여진 포트를 가진 파드 예제
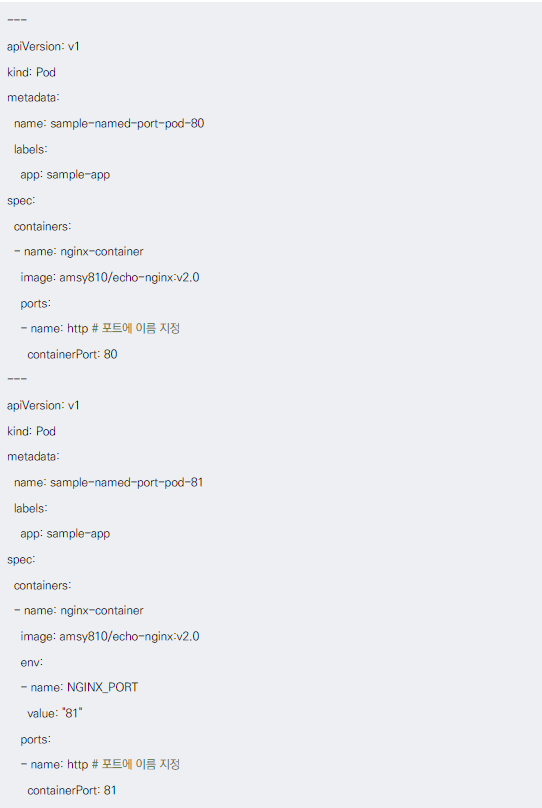
- 두 개의 파드 정의 (80번 포트와 81번 포트)
- 둘 다 'http'라는 이름으로 포트 지정
이름이 붙여진 포트를 참조하는 서비스 예제
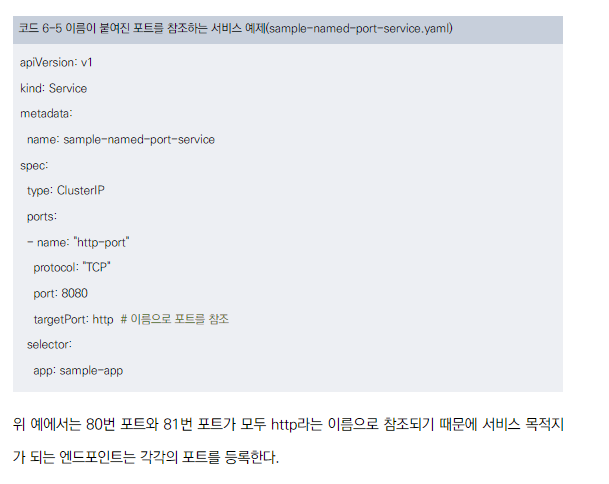
- targetPort를 'http'로 지정하여 이름으로 포트 참조
동작 확인
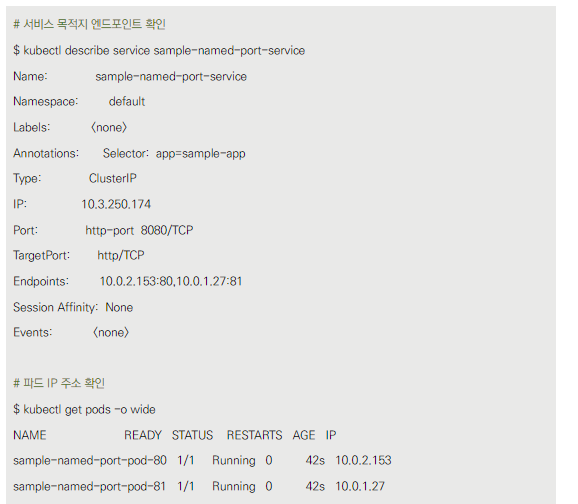
- 서비스의 엔드포인트에 80번과 81번 포트 모두 등록됨
- kubectl describe 명령으로 엔드포인트 확인
- kubectl get pods 명령으로 파드 IP 주소 확인
장점
- 포트 번호 변경 시 서비스 정의를 수정할 필요 없음
- 다른 포트 번호를 사용하는 파드들도 동일한 서비스로 묶을 수 있음
요약
- 쿠버네티스 서비스의 유연성을 보여주는 중요한 기능입니다.
- 여러 포트를 지원하고, 포트에 이름을 붙여 참조할 수 있는 기능은 복잡한 애플리케이션 구조에서 네트워크 설정을 간편하게 만듭니다.
- 이를 통해 서비스 구성의 유지보수성과 확장성이 크게 향상됩니다.
파드 설정
- 두 개의 파드가 생성되었습니다: sample-named-port-pod-80와 sample-named-port-pod-81
- 두 파드 모두 app: sample-app 레이블을 가지고 있습니다.
- 첫 번째 파드는 80번 포트를, 두 번째 파드는 81번 포트를 사용합니다.
- 두 파드 모두 포트 이름을 "http"로 지정했습니다.
서비스 설정
- sample-named-port-service라는 이름의 서비스가 생성되었습니다.
- 이 서비스는 app: sample-app 레이블을 가진 파드들을 선택합니다.
- 서비스는 8080 포트로 들어오는 트래픽을 "http"라는 이름의 타겟 포트로 전달합니다.
결과 해석
kubectl describe service 명령의 결과를 보면
- 서비스의 포트는 8080/TCP입니다.
- TargetPort는 "http/TCP"로 표시되어 있습니다. 이는 "http"라는 이름의 포트를 참조한다는 의미입니다.
- Endpoints에 두 개의 IP:Port 조합이 나열되어 있습니다: 10.0.2.153:80/ 10.0.1.27:81
-
kubectl get pods -o wide 명령의 결과를 보면:
-
sample-named-port-pod-80의 IP는 10.0.2.153입니다.
-
sample-named-port-pod-81의 IP는 10.0.1.27입니다.
중요한 점
- 두 파드 모두 포트 이름을 "http"로 지정했지만, 실제 포트 번호는 다릅니다(80과 81).
- 서비스는 "http"라는 이름의 포트를 타겟으로 지정했습니다.
- 이로 인해 서비스는 80번 포트를 사용하는 파드와 81번 포트를 사용하는 파드 모두를 엔드포인트로 인식합니다.
클러스터 내부 DNS와 서비스 디스커버리
서비스 디스커버리 개요
- 정의: 특정 조건의 대상이 되는 멤버를 보여주거나 이름에서 엔드포인트를 판별하는 기능
- 쿠버네티스에서의 의미: 서비스에 속한 파드를 보여주거나 서비스명에서 엔드포인트 정보를 반환하는 것
서비스 디스커버리 방법
- a) 환경 변수 사용
- b) DNS A 레코드 사용
- c) DNS SRV 레코드 사용
환경 변수를 사용한 서비스 디스커버리


- 장점: 같은 네임스페이스의 서비스 정보를 파드 내부에서 확인 가능
- 주의점: 파드 생성 후 서비스 변경 사항이 자동으로 반영되지 않음
- 그러나 파드가 생성된 후 서비스 생성이나 삭제에 따라 변경된 환경 변수가 먼저 기동한 파드 환경에는 자동으로 다시 등록되지 않기 때문에 예기치 못한 장애로 이어질 수 있다.
- 옵션: spec.enableServiceLinks: false로 설정하여 비활성화 가능
DNS A 레코드를 사용한 서비스 디스커버리


-
다른 파드에서 서비스로 할당되는 엔드포인트에 접속하려면 당연히 목적지가 필요하지만, 할당된 IP 주소를 사용하는 방법 외에도 자동 등록된 DNS 레코드를 사용할 수 있다.
-
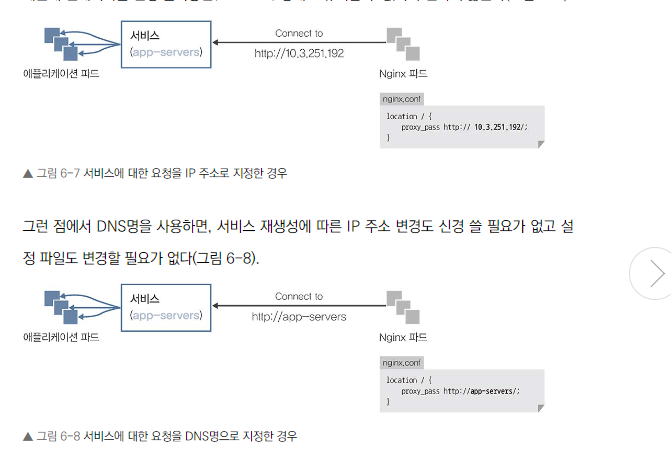
쿠버네티스에서 IP 주소를 편하게 관리하려면 기본적으로 자동 할당된 IP 주소에 연결된 DNS명을 사용하는 것이 바람직하다. 할당되는 IP 주소는 서비스를 생성할 때마다 변경된다
-
그래서 IP 주소를 송신 측 컨테이너 설정 파일 등에서 명시적으로 설정하면 변경될 때마다 설정 파일 등을 변경해야 하기 때문에 컨테이너를 변경 불가능한(immutable) 상태로 유지할 수 없어 추천하지 않는다
-
장점: IP 주소 대신 DNS 이름을 사용하여 서비스에 접근 가능
-
형식: 서비스명.네임스페이스명.svc.cluster.local
-
편의성: 같은 네임스페이스 내에서는 서비스명만으로도 접근 가능
DNS 설정
- /etc/resolv.conf에 네임스페이스 관련 설정이 포함되어 있어 간단한 이름으로 접근 가능
역방향 질의도 지원됨
DNS SRV 레코드를 사용한 서비스 디스커버리
- SRV 레코드: 포트명과 프로토콜을 사용하여 서비스의 포트 번호를 포함한 엔드포인트를 DNS로 해석


- 형식: 서비스의 포트명.프로토콜.서비스명.네임스페이스명.svc.cluster.local
- 예: _http-port._tcp.sample-clusterip.default.svc.cluster.local
- 장점: 포트 번호를 포함한 완전한 엔드포인트 정보를 제공
클러스터 내부 DNS와 외부 DNS
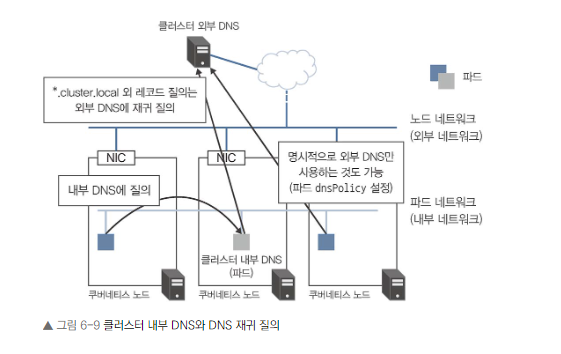
- 클러스터 내부 DNS
- dnsPolicy를 사용하여 파드의 DNS 서버 설정을 명시적으로 하지 않는 이상 기동하는 모든 파드는 이 클러스터 내부 DNS를 사용하여 이름 해석
- 모든 파드가 기본적으로 사용
- 서비스 엔드포인트에 대한 레코드(*.cluster.local) 저장
- 서비스 디스커버리에 사용
외부 DNS
- 내부 DNS에 없는 레코드에 대해 재귀 질의
노드 로컬 DNS 캐시
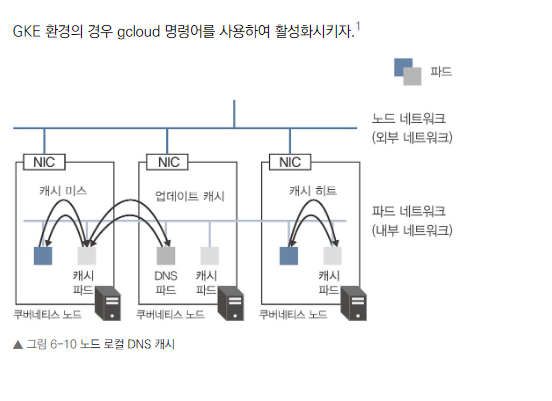
- 목적: 대규모 클러스터에서의 성능 향상
- 작동 방식: 각 노드의 로컬에 DNS 캐시 서버 배치
- 장점: 파드의 DNS 질의를 같은 노드의 로컬 DNS 캐시 서버로 처리
정리
- 쿠버네티스는 다양한 DNS 기반 서비스 디스커버리 방법을 제공하여 유연하고 효율적인 서비스 접근을 가능하게 함
- SRV 레코드를 통해 포트 정보를 포함한 상세한 서비스 엔드포인트 정보를 얻을 수 있다.
- 클러스터 내부 DNS와 외부 DNS의 구분은 효율적인 이름 해석과 보안을 위해 중요
- 노드 로컬 DNS 캐시는 대규모 클러스터에서 DNS 쿼리 성능을 향상시키는 중요한 최적화 기법
ClusterIP 서비스
ClusterIP 서비스 개요:
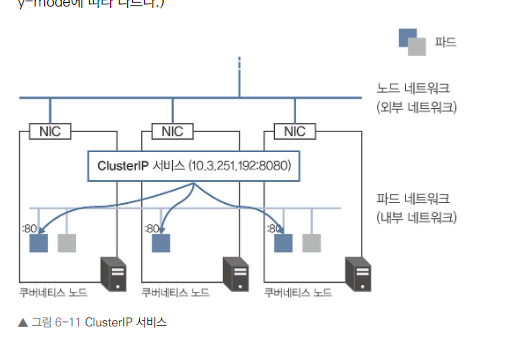
- 가장 기본적인 쿠버네티스 서비스 타입
- 클러스터 내부 네트워크에 가상 IP 할당
- kube-proxy가 ClusterIP와 파드 간 통신 관리
ClusterIP 서비스의 특징

- 클러스터 내부에서만 접근 가능
- ClusterIP는 쿠버네티스 클러스터 외부에서 트래픽을 수신할 필요가 없는 환경에서 클러스터 내부 로드 밸런서로 사용
- 쿠버네티스 API 서버도 ClusterIP 서비스로 제공됨
ClusterIP 서비스 생성
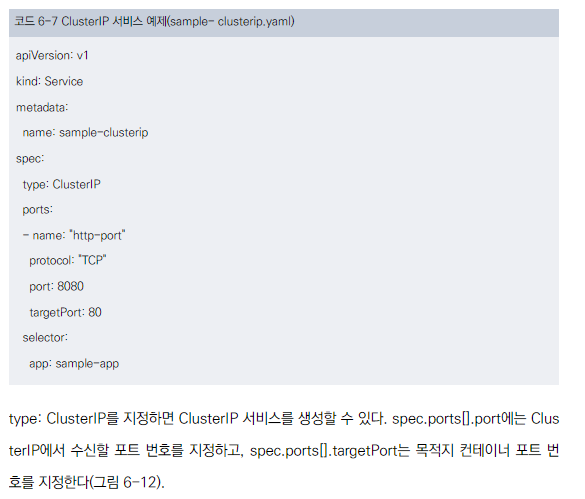
-
YAML 매니페스트로 정의
-
주요 설정:
-
type: ClusterIP
-
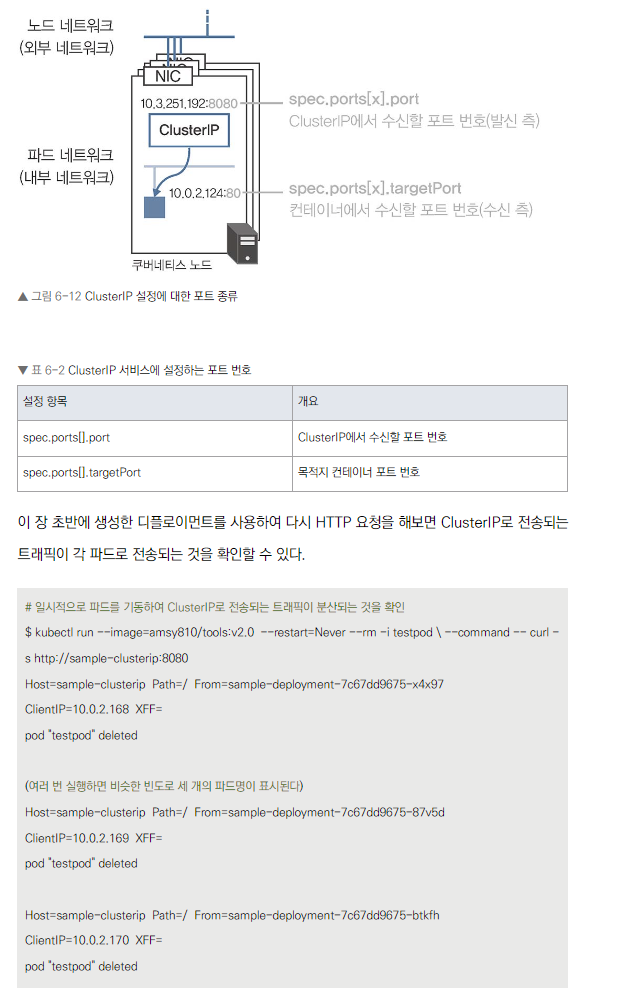
port: ClusterIP에서 수신할 포트
-
targetPort: 목적지 컨테이너 포트
- 셀렉터를 통해 서비스와 파드 연결
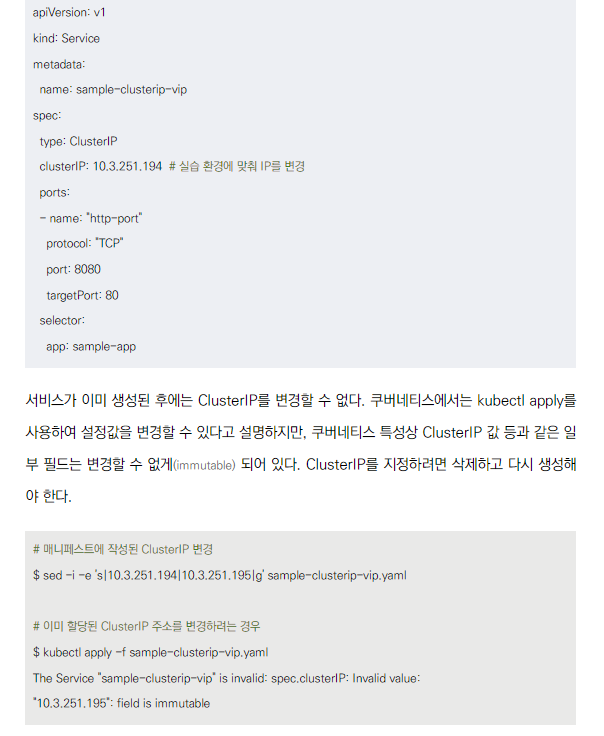
ClusterIP 정적 지정
-
애플리케이션에서 데이터베이스 서버를 지정하는 경우에는 기본적으로 쿠버네티스 서비스에 등록된 클러스터 내부 DNS 레코드를 사용하여 호스트를 지정하는 것이 바람직함
-
그러나 IP 주소로 지정해야 하는 경우 ClusterIP를 정적으로 지정할 수도 있음
-
spec.clusterIP 필드로 IP 수동 지정 가능
-
한번 지정된 ClusterIP는 변경 불가 (immutable)
-
변경 필요 시 서비스 삭제 후 재생성 필요
핵심 메시지
- ClusterIP 서비스는 쿠버네티스 내부 서비스 디스커버리와 로드 밸런싱의 기본이 되는 중요한 리소스입니다.
- 클러스터 내부 통신에 최적화되어 있으며, 외부 접근이 필요 없는 서비스에 적합합니다.
- IP 주소 관리에 주의가 필요하며, 가능한 한 DNS 이름을 사용하는 것이 권장됩니다.
ExternalIP 서비스
ExternalIP 서비스 개요
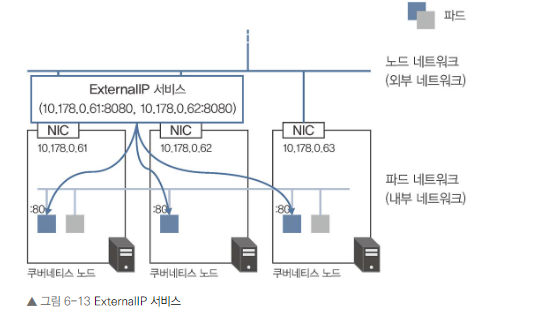
- 특정 쿠버네티스 노드 IP 주소:포트에서 수신한 트래픽을 컨테이너로 전송
- 외부와의 통신을 가능하게 함
- NodePort 서비스가 더 일반적으로 권장됨
ExternalIP 서비스 생성-
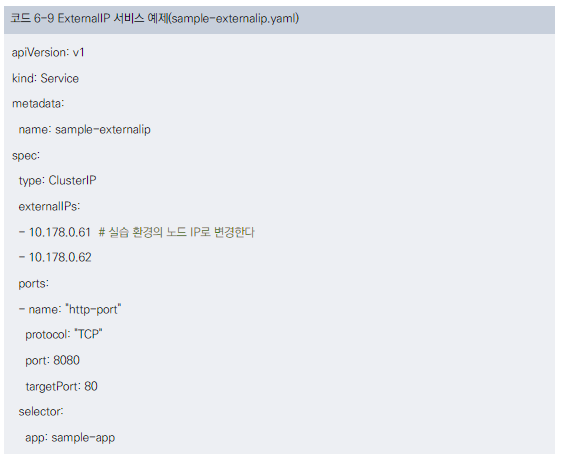
- YAML 매니페스트로 정의
주요 설정
- type: ClusterIP (ExternalIP는 별도 타입이 아님)
- externalIPs: 쿠버네티스 노드 IP 목록
- port: 노드 IP와 ClusterIP에서 수신할 포트
- targetPort: 목적지 컨테이너 포트
ExternalIP 특징
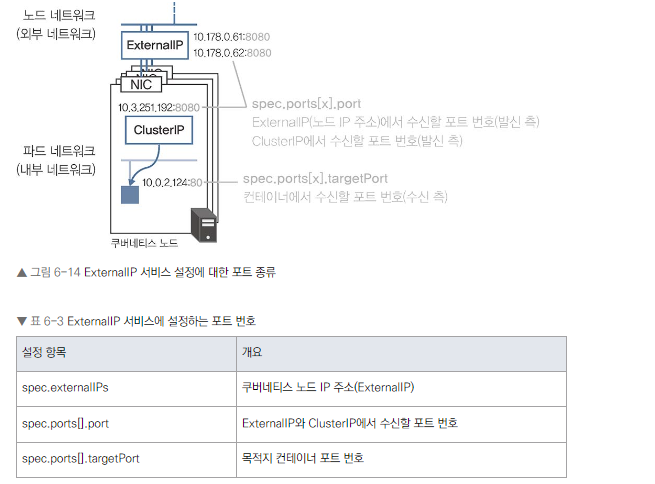
- ExternalIP에 사용 가능한 IP 주소는 노드 정보에서 확인할 수 있다
- 모든 노드 IP를 지정할 필요 없음
- 내부적으로 ClusterIP도 자동 할당됨
- 클러스터 내부 DNS는 ClusterIP를 반환
주의사항


- 노드의 OS에서 인식 가능한 IP만 사용 가능
- GCE 인스턴스의 글로벌 IP는 사용 불가능
동작 확인
- 지정된 노드에서만 포트가 Listen 상태
- 외부에서 지정된 IP:포트로 접근 가능
- 트래픽은 여러 파드로 분산됨
핵심 메시지
- ExternalIP 서비스는 특정 노드 IP를 통해 외부 접근을 가능하게 하는 유연한 방법입니다.
- 그러나 NodePort 서비스가 더 일반적이고 권장되는 방식입니다.
- IP 주소 관리와 네트워크 구성에 주의가 필요합니다.
NodePort 서비스
NodePort 서비스 개요
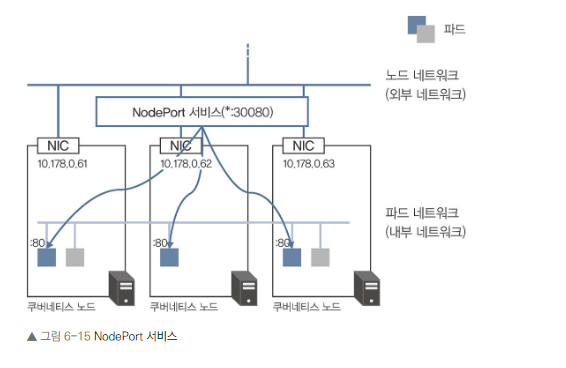
- NodePort는 쿠버네티스의 서비스 타입 중 하나입니다.
- ExternalIP 서비스와 유사하지만, 모든 노드에서 동작한다는 점이 다릅니다.
- 모든 쿠버네티스 노드의 IP 주소:포트에서 수신한 트래픽을 컨테이너로 전송합니다.
- 0.0.0.0:포트로 바인딩하여 모든 IP 주소에서의 트래픽을 수신합니다.
- 도커 스웜의 'Expose' 기능과 유사한 동작을 합니다.
NodePort 서비스 생성 방법
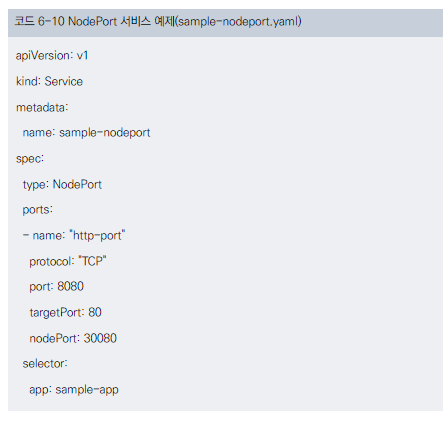
- YAML 매니페스트 파일을 사용하여 생성합니다.
주요 설정 항목

- spec.type: NodePort로 지정
- spec.ports[].port: ClusterIP에서 수신할 포트 번호
- spec.ports[].targetPort: 목적지 컨테이너 포트 번호
- spec.ports[].nodePort: 모든 쿠버네티스 노드에서 수신할 포트 번호
- nodePort를 지정하지 않으면 30000-32767 범위에서 자동 할당됩니다.
NodePort 서비스의 특징


- ClusterIP도 자동으로 할당되어 클러스터 내부 통신에 사용됩니다.
- 클러스터 내부 DNS에서는 ClusterIP를 반환합니다.
- 모든 쿠버네티스 노드에서 지정된 nodePort로 리스닝합니다.
- 외부에서 모든 노드의 IP:nodePort로 접근 가능합니다.
- 요청은 여러 파드로 분산됩니다.
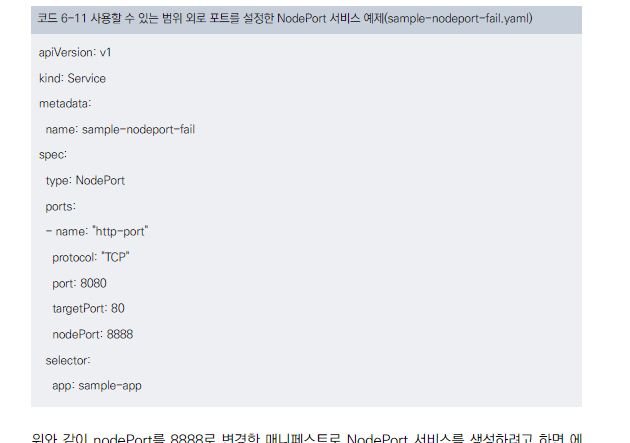
포트 범위 및 제한사항
- 사용 가능한 포트 범위는 일반적으로 30000-32767입니다 (쿠버네티스 기본값).
- 이 범위 외의 포트를 지정하면 에러가 발생합니다.
- 쿠버네티스 마스터 설정을 직접 수정할 수 있는 경우 이 범위를 변경할 수 있습니다.
주의사항 및 제한사항
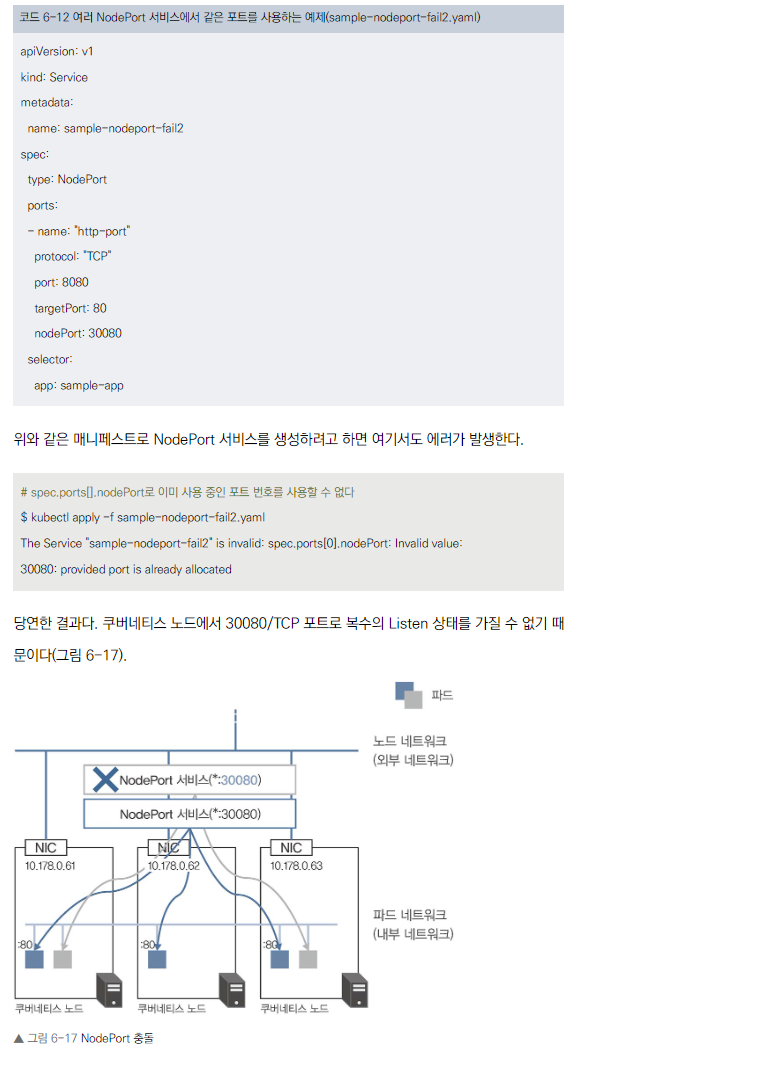
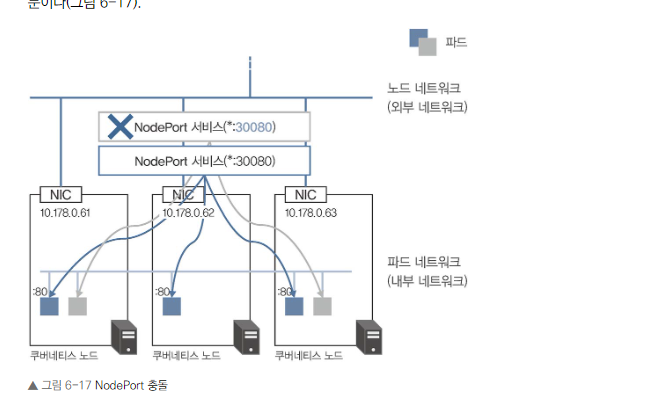
- 여러 NodePort 서비스에서 같은 포트를 사용할 수 없습니다.
- 포트 충돌에 주의해야 합니다.
- 보안 그룹이나 방화벽 설정에 주의가 필요합니다 (예: GCP의 경우).
NodePort 서비스 확인 및 테스트
- kubectl get services 명령으로 생성된 서비스를 확인할 수 있습니다.
- dig 명령어로 서비스의 DNS 확인이 가능합니다.
- ss 또는 netstat 명령어로 노드에서 포트 상태를 확인할 수 있습니다.
- curl 명령어로 외부에서 서비스에 접근 테스트가 가능합니다.
NodePort의 사용 사례
- 개발 환경이나 데모용으로 적합합니다.
- 클러스터 외부에서 직접 접근이 필요한 서비스에 사용됩니다.
- 로드 밸런서가 없는 환경에서 외부 접근을 위해 사용할 수 있습니다.
NodePort vs LoadBalancer vs Ingress
- NodePort는 직접적인 노드 포트 노출 방식입니다.
- LoadBalancer는 클라우드 제공자의 로드 밸런서를 사용합니다.
- Ingress는 HTTP 및 HTTPS 트래픽을 처리하는 더 복잡한 라우팅을 제공합니다.
정리
NodePort 서비스의 핵심 개념 이해
-
NodePort는 쿠버네티스에서 외부 트래픽을 클러스터 내부 서비스로 라우팅하는 간단하고 직접적인 방법입니다. 모든 노드의 특정 포트를 열어 서비스에 접근할 수 있게 해줍니다.
구성의 용이성과 유연성
-
YAML 파일을 통해 쉽게 구성할 수 있으며, 포트 설정을 통해 유연하게 커스터마이즈할 수 있습니다.
클러스터 내외부 통신의 이중성
-
외부 접근을 위한 NodePort와 내부 통신을 위한 ClusterIP를 동시에 제공하여, 다양한 네트워크 요구사항을 충족시킵니다.
사용 시 주의사항 강조
- 포트 범위 제한, 중복 사용 불가 등의 제한사항을 이해하고 적절히 대응해야 합니다.
실제 환경에서의 적용 및 테스트
- 다양한 커맨드라인 도구를 통해 서비스의 작동을 확인하고 테스트할 수 있습니다.
서비스 선택의 중요성
- NodePort, LoadBalancer, Ingress 등 다양한 옵션 중에서 적절한 서비스 타입을 선택하는 것이 중요합니다.
그 외 서비스 기능
세션 어피니티
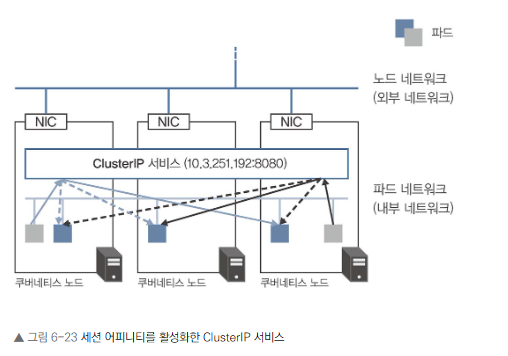
- 세션 어피니티(Session Affinity)는 쿠버네티스 서비스에서 활성화할 수 있는 기능
- ClusterIP 서비스에서 세션 어피니티를 활성화하면, 같은 클라이언트의 트래픽이 계속 같은 파드로 전송

-
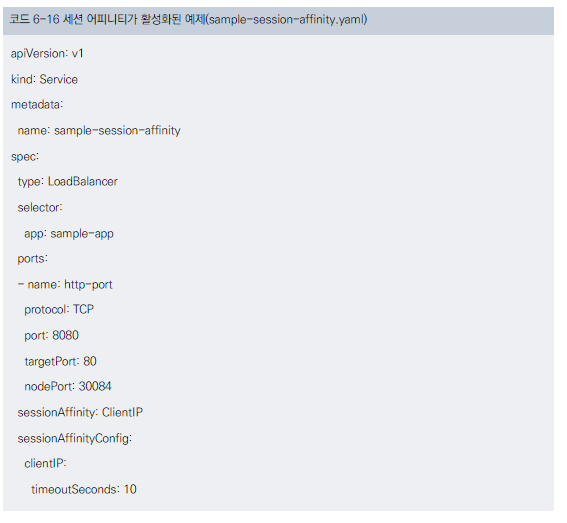
설정은 spec.sessionAffinity와 spec.sessionAffinityConfig를 사용합니다.
-
ClusterIP에서는 클라이언트 IP 주소를 기반으로 목적지를 결정
-
세션 어피니티는 각 쿠버네티스 노드의 iptables에 구현되어 있습니다.
-
최대 세션 고정 시간을 설정할 수 있으며, 기본값은 None입니다.
-
예제 코드를 통해 세션 어피니티가 활성화된 서비스 설정을 보여줍니다.
-
실제 요청을 보내 세션 어피니티의 동작을 확인하는 예시를 제공합니다.
-
NodePort와 LoadBalancer 서비스에서도 세션 어피니티를 사용할 수 있지만, 제한적
-
세션 어피니티는 같은 클라이언트의 요청을 일정 시간 동안 같은 파드로 보내는 기능으로, 특정 상황에서 유용할 수 있습니다. 하지만 서비스 유형에 따라 그 효과가 제한적일 수 있음
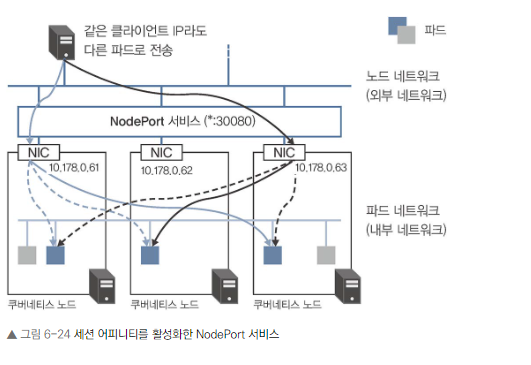
노드 간 통신 제외와 발신 측 IP 주소 유지
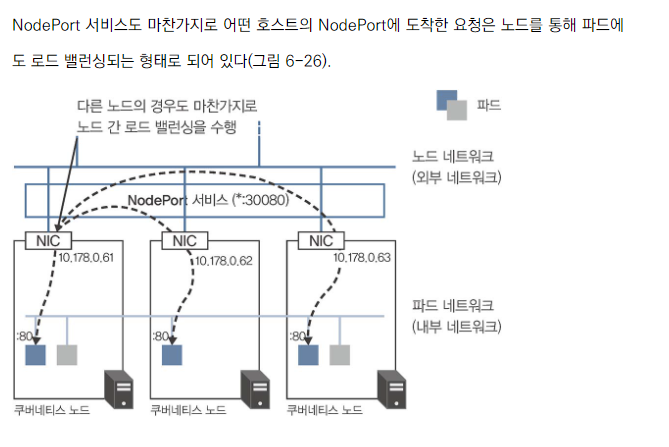
- NodePort와 LoadBalancer 서비스에서는 불필요한 2단계 로드 밸런싱이 발생합니다.
- 첫 번째: 외부 로드 밸런서 또는 NodePort를 통해 노드로
- 두 번째: 노드 내에서 파드로
2단계 로드 밸런싱의 특징

- 균일한 요청 분산
- 불필요한 레이턴시 오버헤드 발생
- 밸런싱을 수행할 때 네트워크 주소 변환(Network Address Translation, NAT)이 이루어져 발신 측 IP 주소가 유실되는 특징
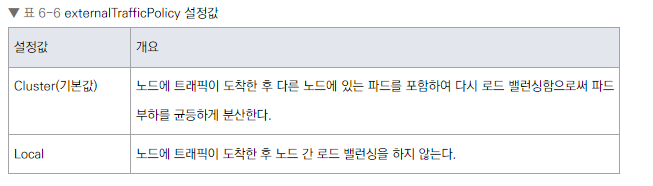
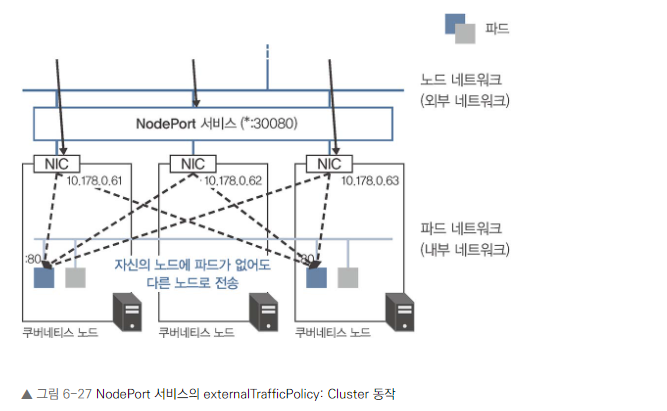
externalTrafficPolicy 설정을 통해 로드 밸런싱 방식 조정 가능
-
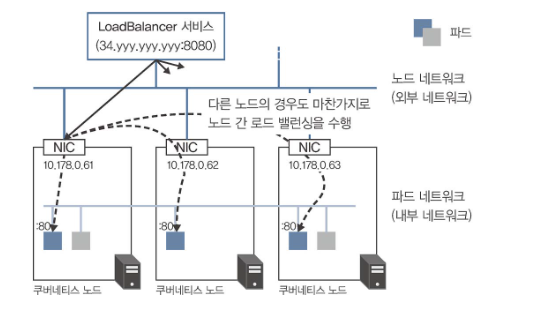
Cluster (기본값): 노드 간 로드 밸런싱 수행
-
Local: 노드 간 로드 밸런싱 하지 않음
-
spec.externalTrafficPolicy가 Cluster인 경우 LoadBalancer 서비스와 NodePort 서비스 둘 다 외부로부터 해당 노드에 도착한 요청은 세 개의 파드에 거의 균등하게 전송
externalTrafficPolicy: Local 설정의 효과
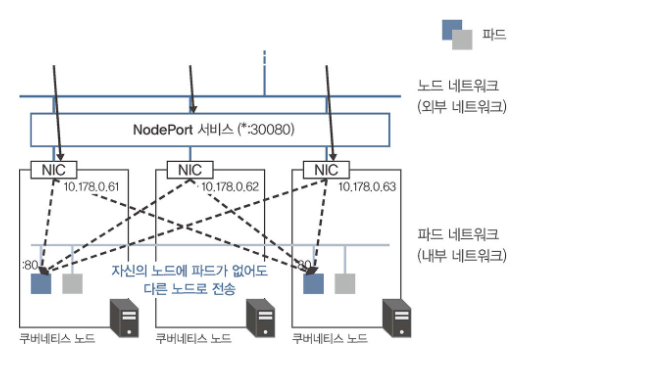
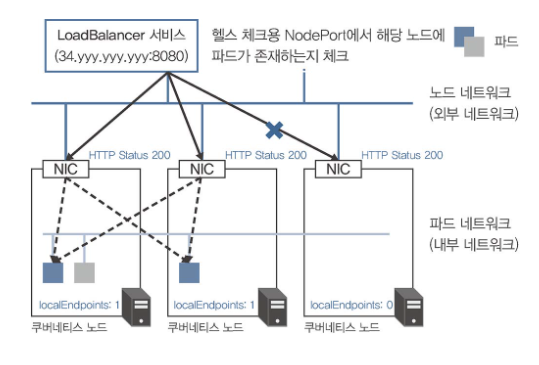
- 요청이 도착한 노드의 파드로만 트래픽 전달
- 클라이언트 IP 주소 보존
- NodePort 서비스에서는 파드가 없는 노드에서 응답 불가
- LoadBalancer 서비스에서는 헬스 체크로 파드 없는 노드 제외
- NodePort 서비스의 경우 해당 노드에 파드가 없다면 요청에 응답할 수 없으므로 가능하면 사용하지 않는 것이 좋다.
LoadBalancer 서비스의 헬스 체크

- 별도의 NodePort 할당
- spec.healthCheckNodePort로 포트 지정 가능
- 노드의 엔드포인트 개수 확인 가능
- 쿠버네티스의 NodePort와 LoadBalancer 서비스에서 발생하는 2단계 로드 밸런싱의 특성과 그에 따른 문제점,
- 그리고 이를 해결하기 위한 externalTrafficPolicy 설정에 대해 설명
- 특히 externalTrafficPolicy를 Local로 설정함으로써 불필요한 네트워크 홉을 줄이고 클라이언트 IP를 보존할 수 있음을 강조
토폴로지를 고려한 서비스 전송
존 서비스 전송의 문제점
- 앞에서 설명했듯이, 일반적으로 서비스 전송 대상은 토폴로지(리전, 가용성 영역 등)를 고려하지 않음
- 원거리 노드 간 통신 시 성능 저하
- 노드 수가 많을 때 East-West 트래픽 증가로 인한 성능 저하
Topology-aware Service Routing의 도입
- externalTrafficPolicy의 한계 극복
- ClusterIP에서도 사용 가능
- 노드 이외의 토폴로지 범위 지정 가능
- 파드가 없는 경우에도 타임아웃 없이 다른 옵션으로 전환
Topology-aware Service Routing의 특징
- 우선순위 기반의 토폴로지 범위 지정
- 발신 측 IP 주소 보존 불가
- externalTrafficPolicy: Local과 동시 사용 불가
구현 방법
- spec.topologyKeys를 사용하여 우선순위 지정
- 예: kubernetes.io/hostname, topology.kubernetes.io/zone, topology.kubernetes.io/region
- '*'를 사용하여 임의의 파드 지정 (마지막에 사용)
동작 예시
- 같은 노드에 파드가 있으면 해당 파드로만 전송
- 같은 노드에 파드가 없으면 다음 우선순위 또는 임의의 파드로 전송
opology-aware Service Routing은 쿠버네티스 서비스의 네트워크 토폴로지를 고려한 트래픽 라우팅을 가능하게 합니다. 이를 통해 네트워크 레이턴시를 줄이고, 불필요한 cross-zone 트래픽을 감소시켜 전체적인 시스템 성능을 향상시킬 수 있습니다. 또한, 기존 externalTrafficPolicy의 한계를 극복하여 더 유연한 트래픽 관리가 가능해집니다.
헤드리스 서비스(None)
헤드리스 서비스 개요

- 헤드리스 서비스는 개별 파드의 IP 주소를 직접 반환하는 서비스입니다.
- 다른 서비스 유형들(ClusterIP, ExternalIP, NodePort, LoadBalancer)과 달리 가상 IP를 통한 로드 밸런싱을 하지 않습니다.
- 대신 DNS 라운드 로빈(DNS RR)을 사용하여 엔드포인트를 제공합니다.
- 클라이언트에서 DNS 캐시 주의해야 함
헤드리스 서비스의 특징
- 로드 밸런싱을 위한 IP 주소를 제공하지 않습니다.
- DNS 쿼리 결과로 파드의 실제 IP 주소들이 반환됩니다.
- 클라이언트 측에서 DNS 캐시 관리에 주의해야 합니다.
헤드리스 서비스 생성 조건
- 서비스의 spec.type이 ClusterIP여야 합니다.
- 서비스의 spec.clusterIP가 None이어야 합니다.
- 스테이트풀셋과 함께 사용할 때는 서비스의 metadata.name이 스테이트풀셋의 spec.serviceName과 일치해야 합니다.
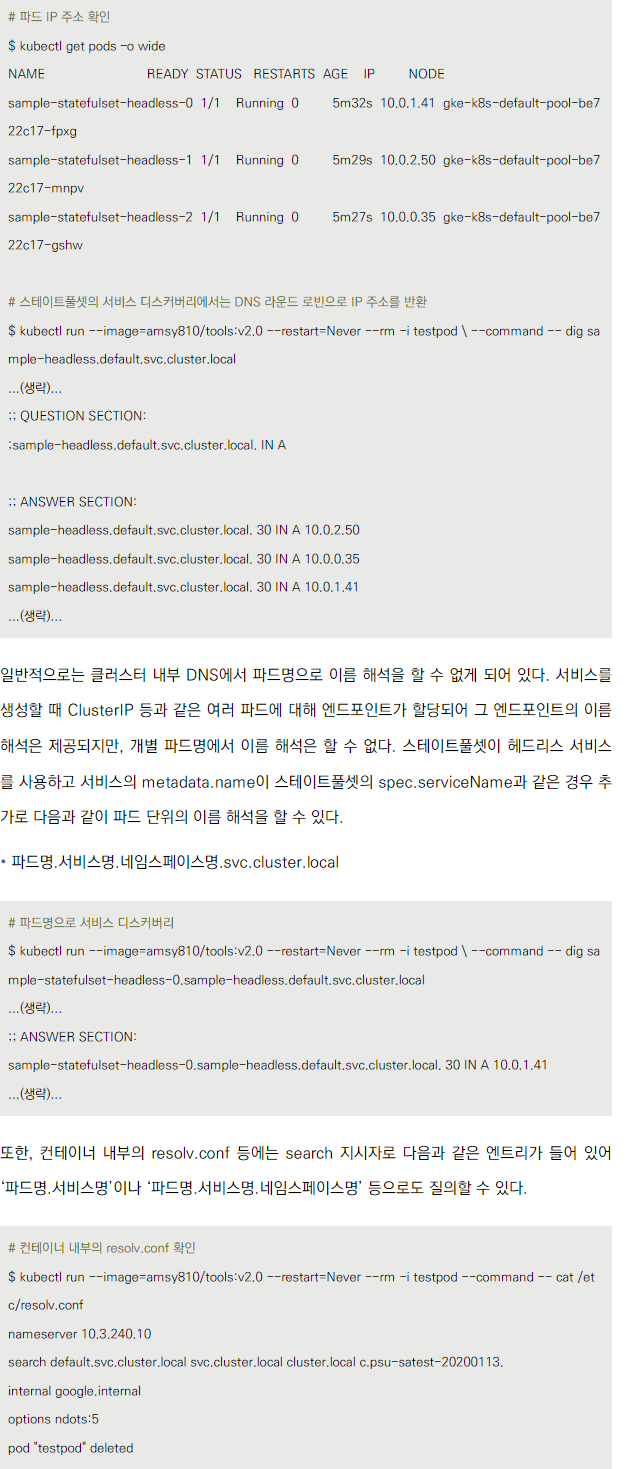
헤드리스 서비스의 DNS 해석
- 일반적인 서비스 이름 해석: '서비스명.네임스페이스명.svc.cluster.local'
- 스테이트풀셋과 함께 사용 시 파드 단위 이름 해석: '파드명.서비스명.네임스페이스명.svc.cluster.local'
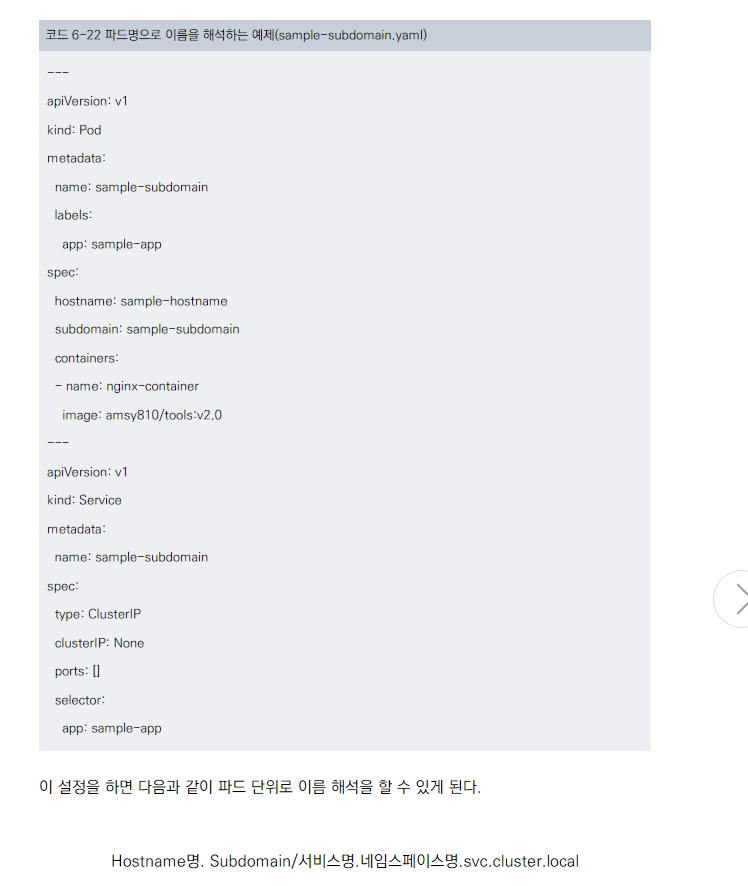
스테이트풀셋 외의 파드에서 이름 해석
- 파드에 spec.hostname과 spec.subdomain 설정을 추가하여 가능합니다.
- 형식: 'Hostname명.Subdomain/서비스명.네임스페이스명.svc.cluster.local'
주의사항
- 디플로이먼트 등에서는 여러 레플리카에 같은 hostname만 설정 가능하여 개별 파드 이름 해석이 제한적입니다.
- 파드명으로 이름 해석 사용 시 신중한 검토가 필요합니다.
ExtenalName 서비스

ExternalName 서비스 개요
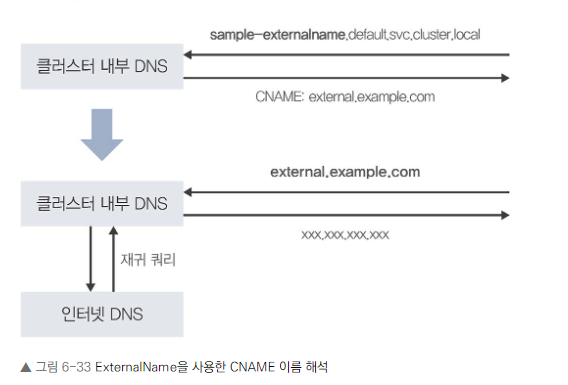
- 일반 서비스와 달리 서비스명의 이름 해석 시 외부 도메인으로 CNAME을 반환합니다.
- 주요 용도: 다른 이름 설정, 클러스터 내부 엔드포인트 쉽게 변경
ExternalName 서비스 생성
- 매니페스트에서 spec.type: ExternalName과 spec.externalName 필드를 사용합니다.
- 서비스 조회 시 External-IP에 CNAME용 FQDN이 표시됩니다.
이름 해석
- 컨테이너 내부에서 서비스명 또는 FQDN으로 질의 시 CNAME이 반환됩니다.
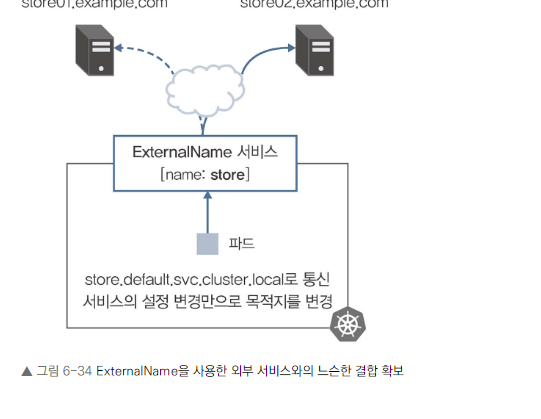
외부 서비스와의 느슨한 결합
- ExternalName을 사용하면 외부 서비스 변경 시 쿠버네티스 내부에서만 설정을 변경하면 됩니다.
- 애플리케이션 코드 변경 없이 외부 서비스 변경 가능
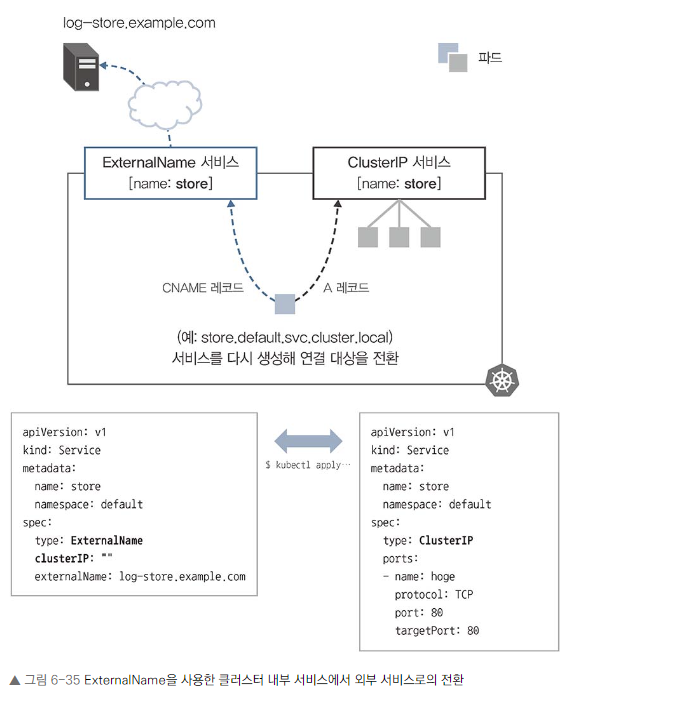
내부/외부 서비스 전환
- ExternalName을 사용하여 외부 서비스와 클러스터 내부 서비스 간 전환이 가능합니다.
- 애플리케이션은 동일한 FQDN을 사용하고, 서비스 설정만 변경하면 됩니다.
- ClusterIP에서 ExternalName으로 전환 시 spec.clusterIP를 명시적으로 비워야 합니다.
None-Selector Service
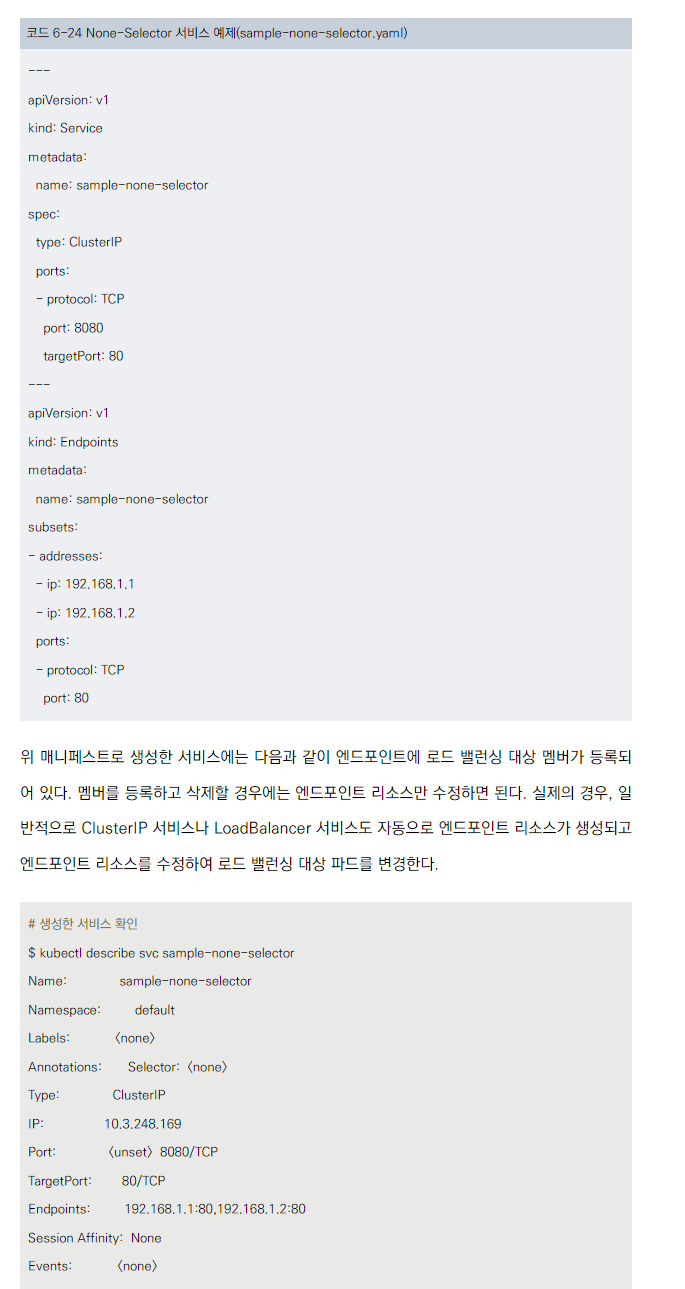
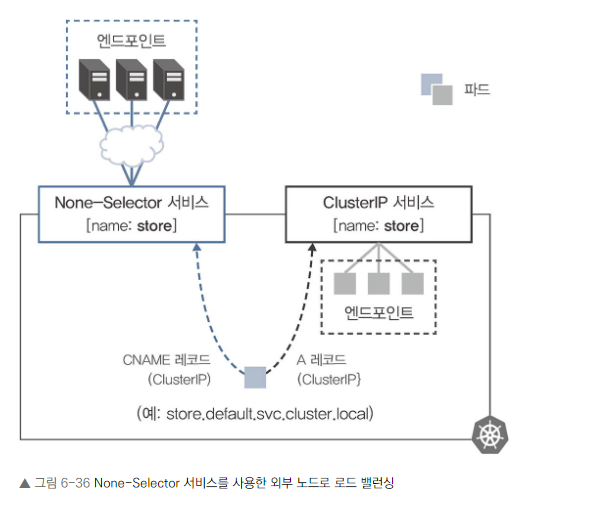
None-Selector 서비스 개요
- 서비스명으로 이름 해석 시 사용자가 설정한 멤버에 대해 로드 밸런싱을 수행합니다.
- 쿠버네티스 내에서 원하는 목적지로 로드 밸런서를 생성할 수 있는 기능입니다.
- 주로 ClusterIP 타입으로 사용되며, 클러스터 내부 로드 밸런서로 활용됩니다.
None-Selector 서비스의 특징
- ExternalName을 지정하지 않고 셀렉터가 존재하지 않는 서비스입니다.
- 엔드포인트 리소스를 수동으로 만들어 유연한 서비스 구성이 가능합니다.
- 클러스터 외부의 애플리케이션 서버에 대한 요청 분산에도 사용할 수 있습니다.
- ExternalName 서비스와 달리 ClusterIP의 A 레코드가 반환됩니다.
None-Selector 서비스 생성
- 서비스와 엔드포인트 리소스를 각각 생성합니다.
- 서비스와 엔드포인트 리소스의 이름이 일치해야 합니다.
- 서비스에는 셀렉터를 지정하지 않습니다.
엔드포인트 관리
- 로드 밸런싱 대상 멤버는 엔드포인트 리소스에 등록됩니다.
- 멤버 추가/삭제는 엔드포인트 리소스 수정으로 가능합니다.
향후 발전 방향
- 쿠버네티스 1.18부터 엔드포인트슬라이스(EndpointSlice) 리소스가 도입되었습니다.
- IPv6 대응, 토폴로지 기반 라우팅, 대규모 환경에서의 확장성 등을 위해 도입되었습니다.
- 향후 엔드포인트 리소스를 대체할 것으로 예상됩니다.
인그레스
인그레스 개요
- L7 로드 밸런싱을 제공하는 독립된 리소스입니다.
- 서비스들을 묶는 상위 객체로 작동합니다.
- kind: Ingress 타입의 리소스로 지정됩니다.
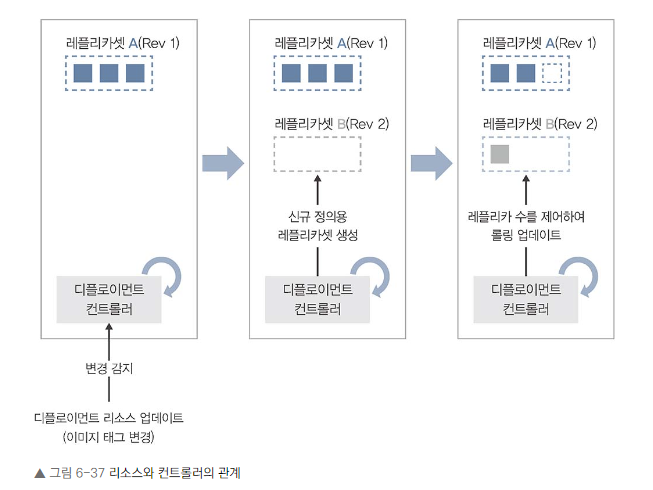
쿠버네티스 내부 구조
- 리소스: 매니페스트로 정의되어 쿠버네티스에 등록됩니다.
- 컨트롤러: 실제 처리를 수행하는 시스템 구성 요소입니다.
인그레스 리소스와 컨트롤러
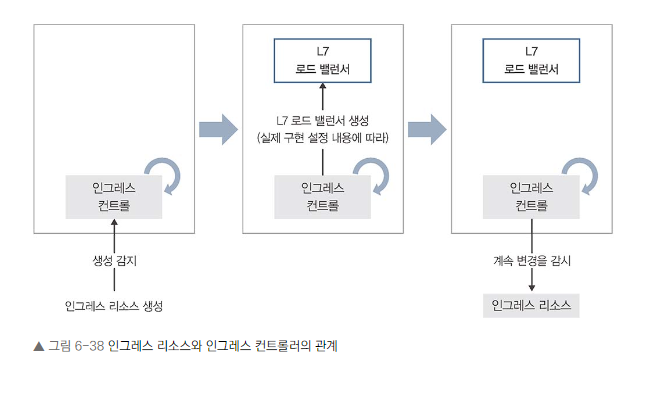
- 인그레스 리소스: API에 등록된 매니페스트입니다.
- 인그레스 컨트롤러: 리소스가 등록되었을 때 실제 처리를 수행합니다.
인그레스 종류
- GKE 인그레스 컨트롤러
- Nginx 인그레스 컨트롤러
인그레스 분류
- 클러스터 외부 로드 밸런서를 사용한 인그레스 (예: GKE 인그레스)
- 클러스터 내부 인그레스용 파드를 배포하는 인그레스 (예: Nginx 인그레스)
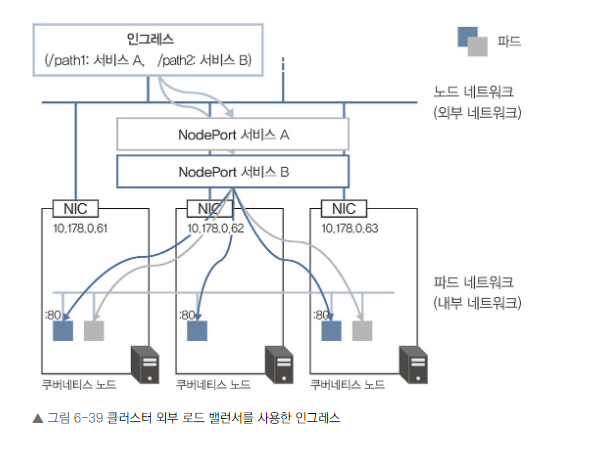
클러스터 외부 로드 밸런서를 사용한 인그레스
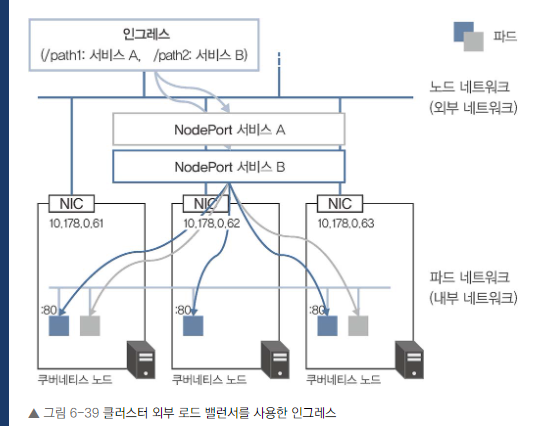
- 인그레스 리소스 생성만으로 로드 밸런서의 가상 IP가 할당됩니다.
- 트래픽 흐름: 클라이언트 -> L7 로드 밸런서(NodePort 경유) -> 목적지 파드
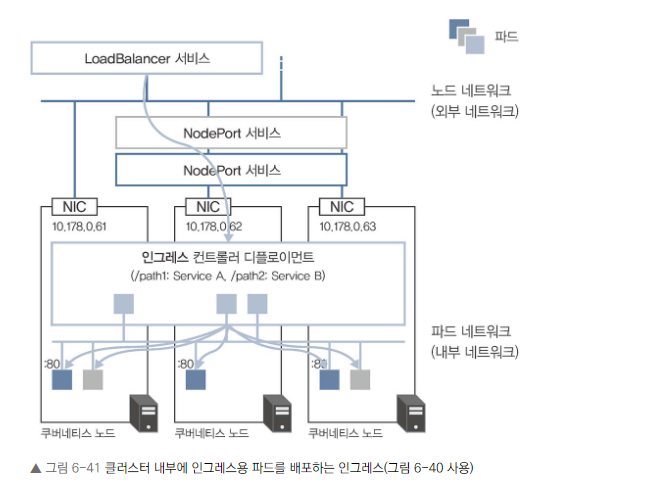
클러스터 내부에 인그레스용 파드를 배포하는 인그레스
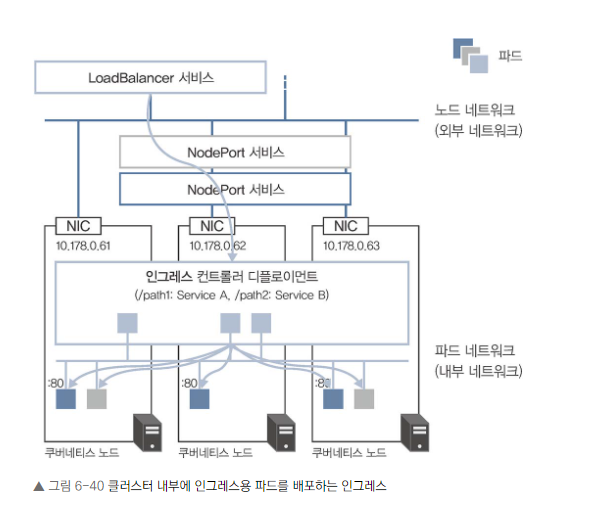
- 인그레스용 파드를 클러스터 내부에 생성합니다.
- 별도의 LoadBalancer 서비스가 필요합니다.
- 트래픽 흐름: 클라이언트 -> L4 로드 밸런서 -> Nginx 파드 -> 목적지 파드
인그레스 컨트롤러 배포
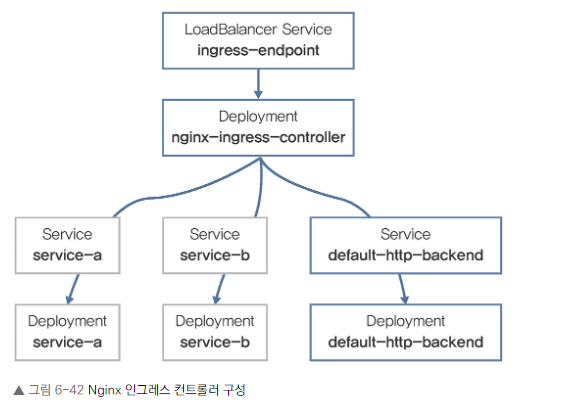
- GKE의 경우 HttpLoadBalancing 애드온으로 자동 배포됨
- Nginx 인그레스 컨트롤러는 수동 배포 필요
- Nginx 인그레스는 L7 처리를 하는 파드와 기본 백엔드용 파드 필요
- 로드 밸런서 서비스 생성 필요
인그레스 리소스 생성을 위한 사전 준비
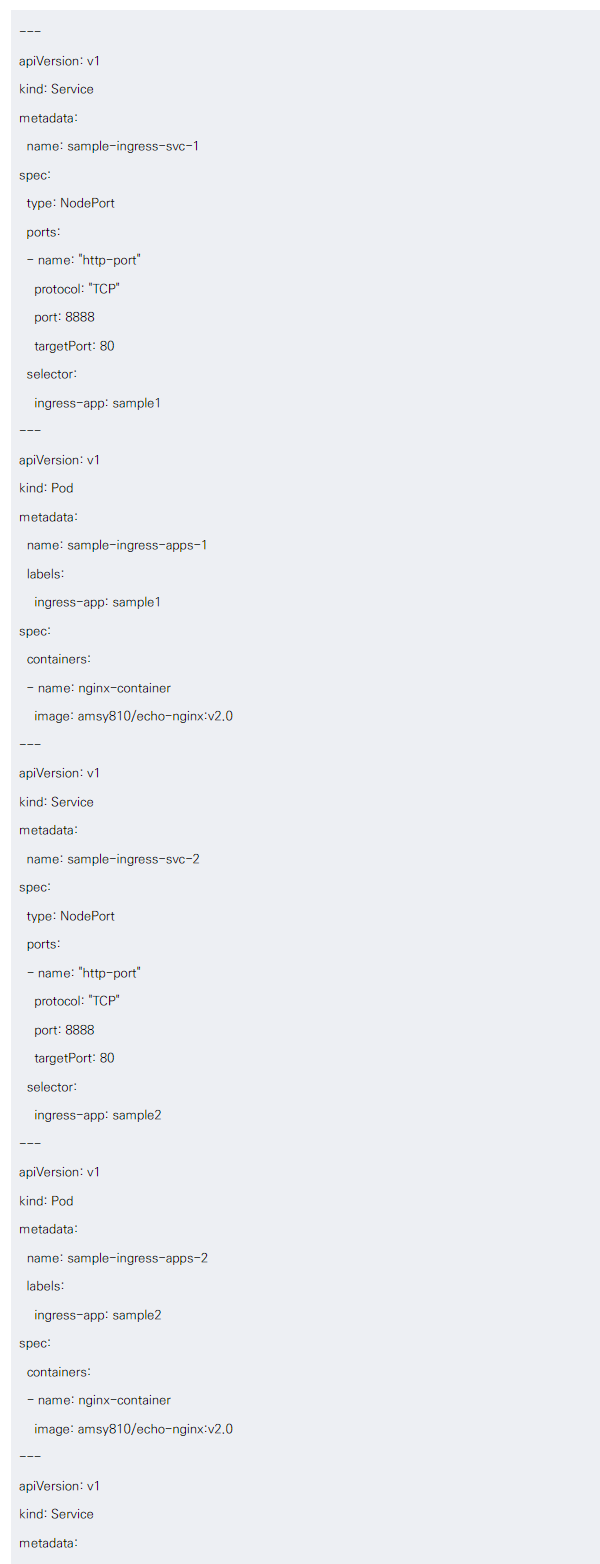
- 백엔드 서비스 (NodePort 타입) 생성 필요
-
지금까지의 작업을 정리해보면, 다음 세 가지 서비스와 파드가 쌍으로 생성되었다.
-
sample-ingress-svc-1 서비스 -> sample-ingress-apps-1 파드
-
sample-ingress-svc-2 서비스 -> sample-ingress-apps-2 파드
-
sample-ingress-default 서비스 -> sample-ingress-default 파드
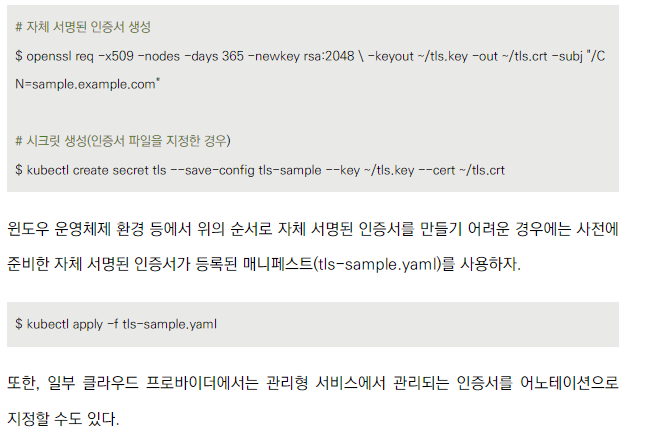
- HTTPS 사용 시 인증서를 시크릿으로 생성
- 시크릿은 인증서 정보로 매니페스트를 작성하고 등록하거나 인증서 파일을 지정하여 kubectl creater secret 명령어로 생성
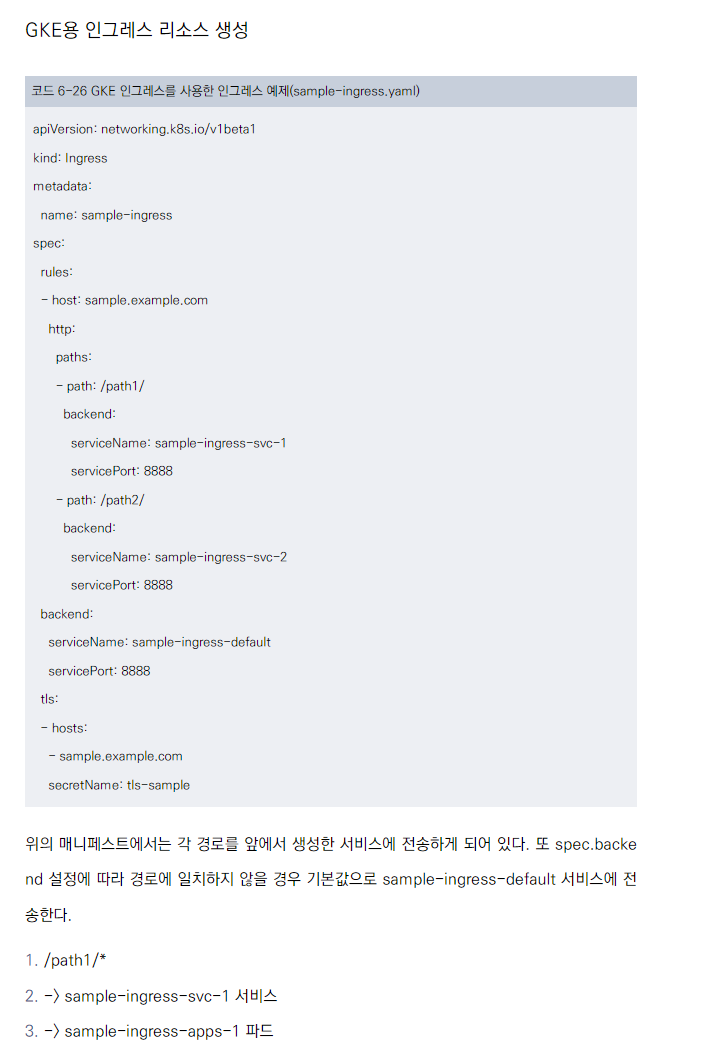
인그레스 리소스 생성

-
호스트명, 경로, 백엔드 서비스 지정
-
TLS 설정 가능
-
인그레스 리소스는 L7 로드 밸런서이기 때문에 특정 호스트명에 대해 ‘요청 경로 > 서비스 백엔드’ 형태의 쌍으로 전송 규칙을 설정한다
-
하나의 IP 주소에서 여러 호스트명을 처리할 수 있다. spec.rules[].http.paths[].backend.servicePort에 설정할 포트 번호는 서비스의
spec.ports[].port를 지정
Nginx 인그레스 리소스 생성
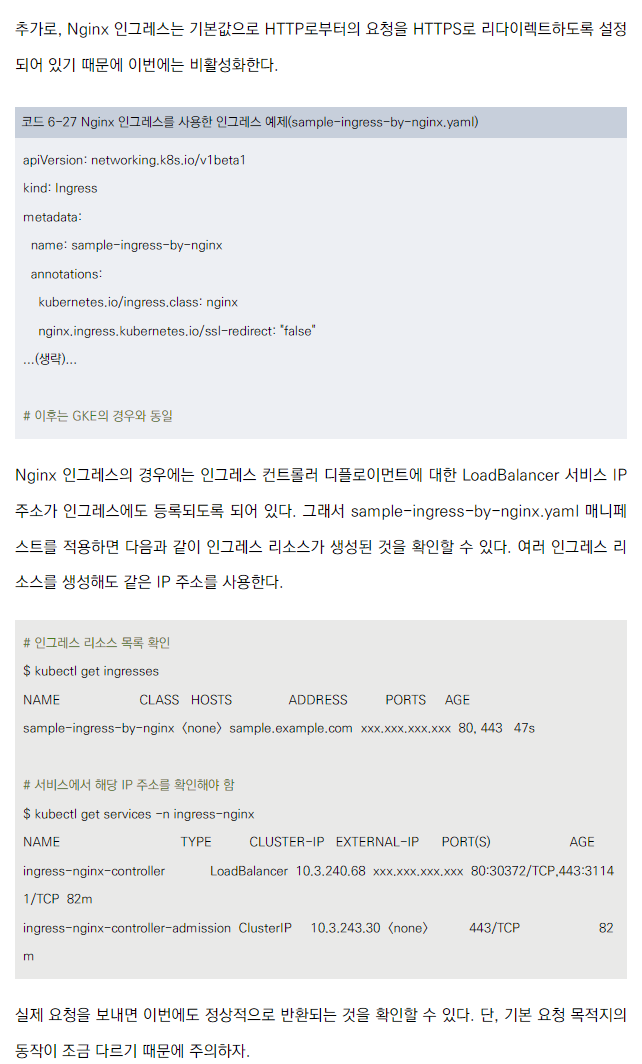
- 기본 설정은 GKE와 유사하지만, 몇 가지 차이점이 있습니다.
- kubernetes.io/ingress.class: nginx 어노테이션을 사용해 Nginx 인그레스 컨트롤러를 지정합니다.
- HTTP에서 HTTPS로의 자동 리다이렉트를 비활성화할 수 있습니다.
Nginx 인그레스의 IP 주소 할당
- Nginx 인그레스 컨트롤러의 LoadBalancer 서비스 IP 주소가 인그레스에 자동으로 등록됩니다.
- 여러 인그레스 리소스가 같은 IP 주소를 공유합니다.
X-Forwarded-For (XFF) 헤더
-
인그레스 경유로 들어오는 트래픽에는 기본적으로 X-Forwarded-For(XFF) 헤더가 지정되어 있으므로 클라이언트 IP 주소(발신 측 IP 주소)를 참조할 수 있게 되어 있다
-
클라이언트의 실제 IP 주소를 파악하는 데 사용됩니다.
-
환경에 따라 정확하지 않을 수 있으므로 주의가 필요합니다.
인그레스 클래스를 통한 분리
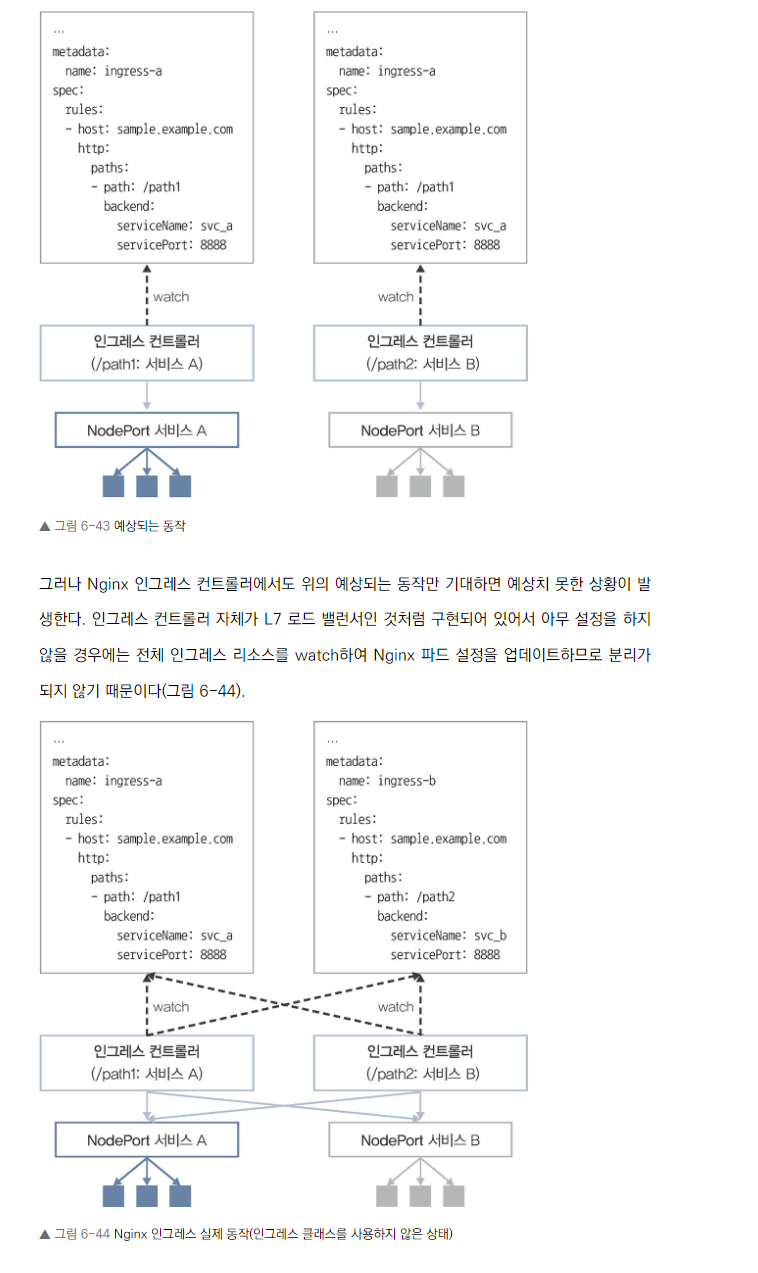

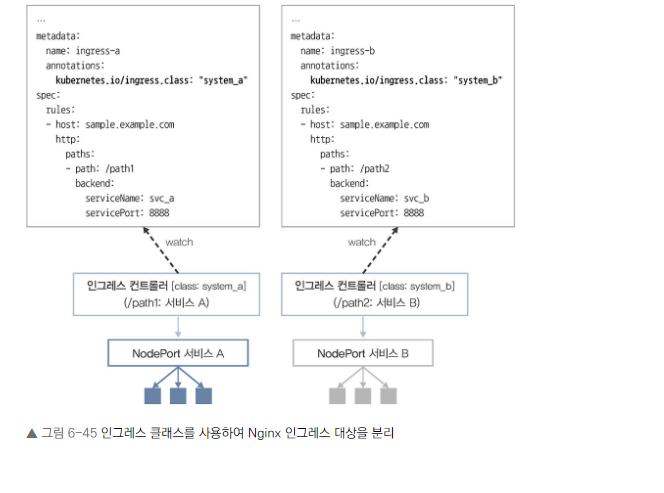
- 여러 인그레스 컨트롤러가 있을 때 충돌을 방지합니다.
- 어노테이션을 사용해 특정 인그레스 컨트롤러에 인그레스 리소스를 할당할 수 있습니다.
쿠버네티스 1.18 이후의 변경사항
- IngressClass 리소스 도입
- pathType을 통한 URL 경로 매칭 방식 지정
- 호스트 이름의 와일드카드 매칭 지원
정리
서비스와 인그레스의 주요 기능
- 서비스: L4 로드 밸런싱, 내부 DNS를 통한 이름 해석, 레이블 기반 파드 디스커버리
- 인그레스: L7 로드 밸런싱, SSL 종료, 경로 기반 라우팅
서비스 타입
- ClusterIP: 내부 통신용 (가장 기본적인 타입)
- LoadBalancer: 외부 접근용 (클라우드 환경에서 주로 사용)
- 그 외: ExternalIP, NodePort, Headless, ExternalName, None-Selector 등
인그레스 구현
- 클러스터 외부 로드 밸런서 사용 (예: GKE)
- 클러스터 내부에 인그레스 파드 배포 (예: Nginx 인그레스)
