
도입 배경
먼저 픽잇(도메인)이란?
서비스의 메인 기능으로 사용자들이 식당 소거 & 최종 투표를 진행하는 도메인 개념이다. 픽잇은 회원 or 비회원 모두 참여가 가능하며, URL 공유를 통해 픽잇에 접속하여 사람들과 식당을 결정할 수 있다.
픽잇을 공유하기 위해서는 특정 픽잇을 식별할 수 있는 값이 필요하였다. 현재 프로젝트의 설계 구조상 Id값은 모두 auto_increment를 활용하여 사용하고 있었다.
따라서 url을 생성하는 과정에서 식별할 수 있는 값이 오직 Id값만 존재하였는데 이를 Url에 삽입하게 되면 문제가 생길 수 있다고 생각하였다. auto_increment 특성상 단순하게 증가하는 정수의 형태이기에 다른 픽잇의 식별 값이 충분히 유추가 된다는 것이었다. 이를 악성 유저가 활용하게 된다면 다른 픽잇에 접속하여 다른 사용자들의 투표를 방해할 수 있다고 판단하였다.
따라서 이를 해결 하기 위해서는 픽잇의 새로운 식별자를 사용해야했다. (PK 에 관한 이야기는 회고에서 다루겠다.)
UUID를 사용하여 데이터의 고유성을 보장할 수 있고, 예측이 어렵다는 장점을 이용하기로 하였다.
설계 과정
PickeatCode 엔티티 설계
@Embeddable
@Getter
public class PickeatCode {
private final static int UUID_LENGTH = 36;
@Column(name = "code", nullable = false, unique = true, columnDefinition = "BINARY(16)")
private UUID value;
public PickeatCode() {
this.value = UUID.randomUUID();
}
public PickeatCode(String code) {
this.value = parsePickeatCode(code);
}
public Boolean isEqualCode(String code) {
return this.value.toString().equals(code);
}
@Override
public String toString() {
return value.toString();
}
private UUID parsePickeatCode(String pickeatCode) {
if (pickeatCode.length() != UUID_LENGTH) {
throw new BusinessException(ErrorCode.INVALID_PICKEAT_CODE);
}
try {
return UUID.fromString(pickeatCode);
} catch (IllegalArgumentException e) {
throw new BusinessException(ErrorCode.INVALID_PICKEAT_CODE);
}
}
}import java.util.UUID 에서 제공하는 UUID.v4를 활용하여 이를 사용하고 있었다.
public String toString() {
return value.toString();
} UUID란 128비트를 16진수로 표현한 것이다. 따라서 URL에 식별값으로 적힐 문자열은 16진수로 표현된 문자열을 반환해야하기에 uuid.toString()을 한 형태로 클라이언트에게 제공하게 하였다.
private UUID parsePickeatCode(String pickeatCode) {
if (pickeatCode.length() != UUID_LENGTH) {
throw new BusinessException(ErrorCode.INVALID_PICKEAT_CODE);
}
try {
return UUID.fromString(pickeatCode);
} catch (IllegalArgumentException e) {
throw new BusinessException(ErrorCode.INVALID_PICKEAT_CODE);
}
} 이 문자열을 가지고 클라이언트가 요청을 주었을 때 UUID 의 형식이 맞는지 확인하고, 이를 UUID 객체로 바꾸어 저장하였다.
이때 DB에 UUID를 저장하는 타입에 대한 고민을 하였었다. (문자열로 저장하기 vs UUID 타입으로 byte로 변환하여 저장하기)
DB에 UUID를 문자열로 저장하기
우리가 실제로 사용할 경우는 16진수로 표현된 문자열 형태로만 클라언트와 소통을 할 것이기에 문자열 형태만 보관하고 있어도 되지 않을까 고민하였다. 또 DB에서 데이터를 확인할때 문자열로 저장되어 있다면 어떤 url을 가진 픽잇이 문제인지 확인하기 편하지 않을까? 고민했다.
하지만 실제로 UUID를 문자열로 보관하게 된다면 36자 문자를 보관한다는 점에 식별값 데이터의 크기가 128 비트에서 36바이트로 늘어나게 될 것 같아 문자열 그대로 저장하지 않기로 하였다.
DB에 UUID 타입으로 저장하기
private final UUID 그대로 엔티티 타입으로 저장할 수 있었다. JPA를 사용하고 있는 상황이었으므로 UUID 타입을 저장할 때 Hiberante의 기본 매핑은 VARCHAR(36)이지만,
@Column(columnDefinition = "BINARY(16)")
을 지정해주게 된다면 16바이트 고정으로 바이트 그대로 저장할 수 있다. 별도의 파싱 과정이 필요 없고 저장 크기를 최소화하여 사용할 수 있다.
따라서 장기적으로 데이터가 점점 쌓일 것 같은 픽잇 테이블의 데이터 크기를 줄이는 방향으로 UUID 타입을 엔티티 칼럼으로 설정하고 columnDefinition 특성을 활용하여 설계하였다.
PickeatCode 사용 설계
요구사항이 먼저 픽잇 URL을 공유할때 필요한 식별값이었으므로 URL을 클라이언트에게 제공할때 PickeCode에 있는 UUID값을 제공하였다.

URL에서 이제 다른 PickeatCode를 예측할 수 없게 되며 식별까지 성공하였다.
클라이언트가 해당 PickeatCode를 통해 요청을 보내면 픽잇에 대한 정보를 제공하기 시작하는데, 이때 요청에 PickeatCode만 들어있기에 Repository에서 쿼리를 사용할때 pickeatCode를 통한 검색을 하게 되었다.
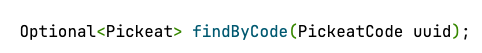
설계 회고
픽잇의 Id를 UUID로?
픽잇에 PickeatCode라는 UUID를 추가하면서 팀에서 한 번 고민이 생겼다. 이제 식별값이 두 개가 되는데, 그렇다면 기존의 auto_increment ID 대신 UUID를 메인 식별자로 쓰는 게 맞지 않을까 하는 생각이었다. 당시에 막연하게 식별값이 2개인 부분이 어색하다고 느꼈던 것 같다.
이전에 auto_increment를 쓰면서 문제를 겪은 적은 없었다. 서비스 규모가 크지 않고 분산 DB를 고려하지 않았기 때문이다. 또한 Id값이 직접적으로 사용자에게 보이는 경우가 적었다.
BaseEntity의 Id가 auto_increment였기에 UUID와 같은 랜덤성 Id가 필요없는 엔티티들까지 모두 UUID로 한번에 전환하기에는 단순히 Id 데이터 크기 측면에서도 효율성이 좋지 않은 것 같다.
auto_increment를 유지한다면 DB에서 확인할 때 각 row들이 쉽게 구별 가능하다는 점도 장점인 것 같다.
만약 Id값이 노출되고 보안에 더 신경써야하거나 분산 DB를 고려하게 되면 Id를 UUID로 교체했을 수도 있다. 하지만 당시 상황에서 기존 Id를 유지하고 별도의 UUID를 추가하는 방식이 가장 적절한 선택이라고 판단했다. 무엇보다 보조 식별값 UUID가 추가되는 것이 어색하다라는 이유가 크게 없는 것 같다.
이번 경험을 돌아보며 결국 “좋은 Id 설계란 무엇일까?”라는 질문을 다시 던지게 되었다. 이 고민은 더 공부를 하고 정리해서 블로그에 글로 남겨볼 생각이다.
UUID를 활용하여 DB 조회를 하고 있는 구조 회고
앞선 설계 과정에서 PickeatCode(UUID)를 통해 DB 검색을 하는 쿼리가 많이 사용된다고 했다. 실제로 프로젝트에 DB 인덱싱과 쿼리 튜닝을 적용해보니 문제점이 드러났다.
UUID v4를 그대로 사용하면 무작위 값 특성 때문에 인덱스가 정렬되지 못하고, 그 결과 인덱싱 성능이 크게 떨어지는 것이다. 특히 빈번하게 발생하는 UUID 기반 조회 쿼리에서는 이 문제가 더 뚜렷하게 보였다.
조회 성능을 높이려면 UUID v7처럼 시간 순으로 정렬이 가능한 버전을 사용하는 것이 대안이 될 수 있다. 이렇게 하면 삽입과 조회 모두에서 인덱스의 효율이 높아질 것이다.
따라서 PickeatCode의 UUID 버전을 재검토하고, 추후 리팩토링 과정에서 UUID v7 같은 시간 순 정렬 가능한 식별자로 교체하는 작업이 필요한 것 같다.
