
서론
픽잇 사용자들이 많아졌을때를 가정해보고자 하였다. 많은 사용자들이 몰릴 수록 트래픽이 몰려 응답시간이 지연 될 수 있다. 또한 데이터 크기 자체가 늘어나 DB 성능이 떨어질 수 있다.
응답 시간이 사업에 주는 영향은 크다고 한다. 구글이 공개한 'Speed Matters for Google Web Search'에 따르면 검색 지연 시간이 감소할 수록 사용자당 검색 횟수가 줄어든다고 한다.
응답 시간에 영향을 주는 여러 요인이 있겠지만 대부분 외부 API 혹은 DB 연동이 많이 차지한다. 따라서 도메인 설계를 하면서 먼저 DB 연동의 시간을 줄여보고자한다.
DB연동에서의 지연 또한 여러 이유가 있겠지만 많은 데이터로 인해 조회 성능을 올려 총 응답시간을 줄이고자 하였다. 이 과정에서 인덱싱을 적용하여 해결해보려고 하였다.
픽잇 DB 환경
mysql을 사용하고 있으며 단일 DB를 사용중이다.
mysql 버전은 8.0.41을 사용하고 있기에 InnoDB를 사용중이다.
인덱싱을 위한 대량 데이터 준비 과정
팀원들과 많은 사용자들이 있는 상황을 가정하기로 하였다.이 상황속에서 유의미한 인덱싱을 확인하기 위해서 대량의 데이터를 삽입하여 인덱싱을 적용하는 것이 유의미하다고 생각하였다.
먼저 10만건의 데이터를 넣고 점진적으로 100만건의 데이터를 삽입하여 인덱스를 적용하기로 하였다.
데이터 삽입 과정에 대해서는 대량 데이터 삽입 글에 구체적으로 작성해두었다.
인덱싱 방식
먼저 인덱싱을 하기 위해서 모든 조회 쿼리들을 모았다.
원래라면 metric 모니터링을 통해서 api별 (요청량 × 응답 지연율) 을 기준으로 우선순위를 정해 적용해볼 수도 있었다.
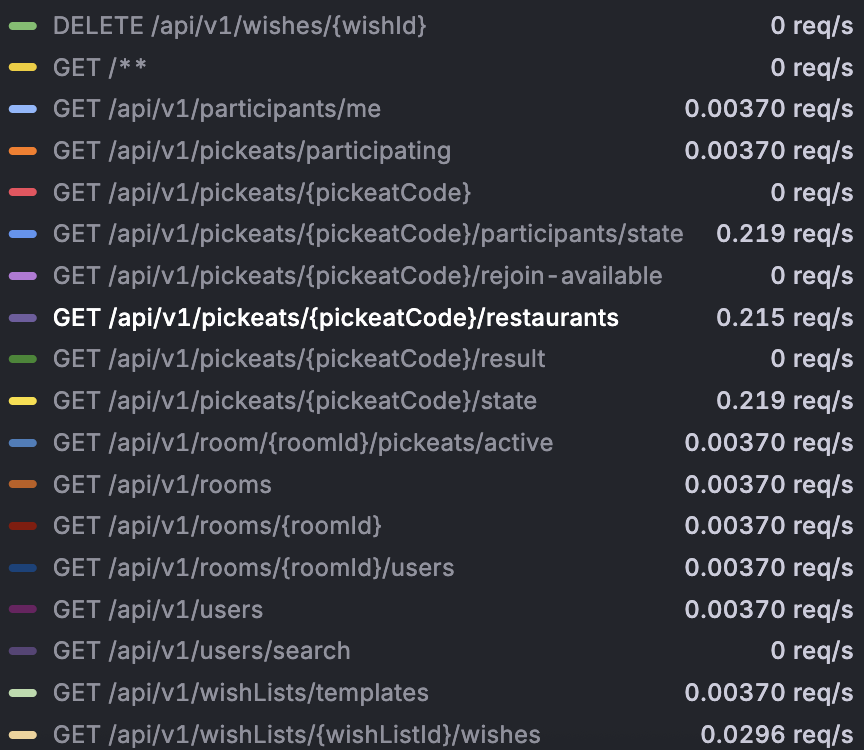
하지만 우리 프로젝트의 규모에서는 모든 조회 쿼리를 직접 확인하는 데 큰 시간이 들지 않았기 때문에 아예 전부 조사해보기로 했다.
또 slow query log를 활용하는 방법도 있었지만, 인덱싱을 적용하기 전에는 slow query 데이터가 없었기 때문에 초반에는 활용할 수 없었다. 대신 인덱싱을 적용한 이후에도 여전히 문제가 되는 쿼리가 있으면 slow query log를 확인하는 용도로 쓰기로 했다.
1. EXPLAIN으로 문제 있는 쿼리 찾기
먼저 모든 조회 쿼리를 조사한 뒤, 각 쿼리 앞에 EXPLAIN을 붙여서 실행 계획을 확인했다.
그 중에서 주로 확인한 칼럼은 type, ref, rows, filtered였다.
- type → ALL이거나 INDEX인 경우 위주로 체크
- ref → null이 아닌 값 위주로 확인
- rows / filtered → rows가 비정상적으로 높은 경우, filtered 값이 낮은 경우 집중 관찰
이 기준으로 개선할 필요가 있다고 판단한 쿼리는 총 6개였다.
대부분 Full Scan을 사용하고 있거나 rows가 지나치게 많은 경우였다.
2. EXPLAIN ANALYZE로 실제 지연 시간 비교
다음에는 EXPLAIN ANALYZE를 사용해서 실제 쿼리 실행 시간까지 같이 확인했다.
이걸 통해서 인덱스를 적용했을 때 얼마나 성능이 개선됐는지 직접 비교할 수 있었고,
복합 인덱스 후보들 중에서 어떤 조합이 더 효율적인지도 확인할 수 있었다.
인덱스 적용 및 결과
1. 방에서 활성화된 픽잇 조회
(PickeatRepository#findByRoomIdAndIsActive)
1) 문제 상황 (Before)
EXPLAIN SELECT * FROM pickeat WHERE room_id = 123 AND is_active = true AND deleted = false;- 실행 계획:
type = ALL→ Full Table Scan
- rows = 99,587 / filtered = 2.5%
- 실행 시간: 54.7 ms
2) 분석 (Analysis)
현재 type 이 ALL이므로 full scan하고 있다는 것을 알 수 있다.
rows가 테이블 전체이면서 filtered는 단 2개이다.
현재 테이블에서 room_id 는 외래키 역할을 하고 있으나, DB에서 직접 외래키 제약조건을 선언하지 않아 자동 인덱스 생성이 이루어지지 않았었다.
isActive의 경우에는 true/false로 Cardinality가 매우 낮다. 따라서 인덱싱을 적용하지 않기로 결정하였다.
isDeleted 또한 true/false로 Cardinality가 낮게 나왔다.
실제로 isActive와 isDeleted를 복합인덱스로 만들어서 확인해보았을 때 조회 성능이 0.01ms만큼 좋아지긴 했다.
하지만 두 개의 값은 도메인 로직상 쉽게 변할 수 있는 값이었다. 픽잇이 종료되거나, 삭제될 경우 true/false가 변경되어 쓰기 작업 비용이 들 수 있다고 판단하였다. 따라서 인덱스 유지에 따른 쓰기 비용 증가가 발생할 수 있다고 생각하였다.
3) 해결 방법 (Solution)
쿼리에서 room_id 조건을 통한 조회가 빈번하게 발생하므로, 선택도를 높여 쿼리 성능을 개선하기 위해 room_id에 별도의 인덱스를 수동으로 등록하였다.
room_id는 1:N 관계이므로 UNIQUE 인덱스는 불가능 → 일반 인덱스를 사용하기로 결정.
4) 적용 결과 (After)
-> Index lookup on pickeat using idx_pickeat_room_id (room_id = 123)
- 실행 시간: 0.034 ms (54 ms → 0.034 ms, 약 1600배 개선)
2. 자신이 참여한 방에서 활성화된 픽잇 조회
(PickeatRepository#findByRoomIdInAndIsActive)
1) 문제 상황 (Before)
EXPLAIN SELECT * FROM pickeat WHERE room_id IN (1, 2, 3, 4) AND is_active = true AND deleted = false;- 실행 계획:
type = ALL→ Full Scan
- rows = 99,587 / filtered = 2.5%
- 실행 시간: 39.7 ms
2) 분석 (Analysis)
type이 ALL이고, rows와 filtered가 성능이 좋지 않아 보인다.
1번의 경우를 해결하고 나니 자연스럽게 2번의 경우도 해결되었다.
3) 해결 방법 (Solution)
room_id 인덱스를 적용.
4) 적용 결과 (After)
-> Index lookup on pickeat using idx_pickeat_room_id (room_id in (...))
- 실행 시간: 0.07 ms (39.7 ms → 0.07 ms)
3. 특정 날짜 이전의 픽잇 조회
(PickeatRepository#findByUpdatedAtBefore)
1) 문제 상황 (Before)
EXPLAIN SELECT * FROM pickeat WHERE updated_at < '2024-01-01 12:00:00' AND deleted = false;- 실행 계획:
type = ALL→ Full Scan
- rows = 99,587 / filtered = 16.6%
- 실행 시간: 61 ms
2) 분석 (Analysis)
해당 쿼리는 스케쥴링을 통해 더 이상 필요하지 않는 pickeat을 모두 삭제할 때 사용한다.
처음에는 updated_at을 인덱싱하려고 시도하였다.
하지만 팀원들과 얘기를 나누면서 쿼리문 자체가 과도하게 조회를 하고 있었다는 것을 알게 되었다.
3일 전의 픽잇들 중에 삭제되지 않은 픽잇들을 모두 삭제하는 작업인데, 이미 삭제된 픽잇들까지 모두 조회를 하고 있었다.
3) 해결 방법 (Solution)
쿼리문을 3일 전 모든 픽잇을 조회하는 것이 아니라, 3일 전 픽잇을 종료하는 방향으로 변경.
즉 WHERE updated_at = 3일전 으로 조건을 좁히고, updated_at에 인덱스를 걸어 성능 개선.
4) 적용 결과 (After)
Full Scan → Index Range Scan 으로 개선.
실행 시간 크게 단축됨.
4. provider 정보 기반 사용자 조회
(UserRepository#findByProviderIdAndProvider)
1) 문제 상황 (Before)
EXPLAIN SELECT * FROM users WHERE provider_id = 2730927362 AND provider = 'google';- 실행 계획:
type = ALL→ Full Scan
- rows = 99,655 / filtered = 0.5%
- 실행 시간: 50.6 ms
2) 분석 (Analysis)
소셜 로그인 특성상 provider별 provider_id는 고유하다.
두 컬럼이 항상 복합 조건으로 함께 조회되며, 개별 조건만으로는 Unique하지 않다.
따라서 provider + provider_id 복합 인덱스가 필요하다.
3) 해결 방법 (Solution)
provider, provider_id에 복합 인덱스 생성.
추가로 UNIQUE 제약 조건을 걸어 더 강력하게 최적화.
4) 적용 결과 (After)
- Index lookup: 0.056 ms (50.6 ms → 0.056 ms)
- UNIQUE 제약 적용 후: 0.0001 ms 수준
5. 닉네임 기반 사용자 조회
(UserRepository#findByNicknameContaining)
1) 문제 상황 (Before)
EXPLAIN ANALYZE SELECT * FROM users WHERE nickname LIKE '%search_term%';- 실행 계획:
type = ALL→ Full Scan
- rows = 99,655 / filtered = 5.56%
- 실행 시간: 32 ms
2) 분석 (Analysis)
방에서 사람을 초대할 때 사용하는 메서드.
%search_term%은 앞부분 와일드카드 때문에 인덱스 미활용.
도메인 관점으로 보니 nickname% 만으로도 충분히 의도한 검색이 가능했다.
검색 특화 서비스였다면 전문 검색 인덱스를 고려했겠지만, 초대용 검색이므로 불필요.
3) 해결 방법 (Solution)
검색 조건을 "LIKE 'search_term%'" 으로 변경.
앞부분 고정으로 인덱스 사용 가능하게 최적화.
4) 적용 결과 (After)
- Index Range Scan 사용
- 실행 시간: 0.015 ms (32 ms → 0.015 ms)
6. 템플릿 위시리스트 조회
(WishListRepository#findAllByIsTemplateTrue)
1) 문제 상황 (Before)
EXPLAIN SELECT * FROM wish_list WHERE is_template = true;- 실행 계획:
type = ALL→ Full Scan
- rows = 99,640 / filtered = 25%
- 실행 시간: 60 ms
2) 분석 (Analysis)
isTemplate은 boolean이라 일반적으로 인덱스 효율이 낮다.
하지만 도메인 특성상 true 비율이 극히 낮고, 조회는 대부분 true에 대해서만 발생했다.
false 조회는 room_id와 함께 조회되는 경우가 많아 room_id 인덱스로 커버 가능.
3) 해결 방법 (Solution)
room_id + is_template 복합 인덱스 생성.
true 값에 대해 바로 탐색 가능하게 최적화.
4) 적용 결과 (After)
- 실행 시간: 0.03 ms (60 ms → 0.03 ms)
추가 인덱싱 – PickeatCode(UUID) 조회 최적화
1) 문제 상황 (Before)
현재 Pickeat을 조회하는 주요 쿼리 중 하나는 pickeatCode 컬럼(UUID 타입)을 통해 값을 조회한다.
문제는 이 컬럼에 인덱스를 적용해도, UUID 버전 4 (랜덤 기반)를 사용하고 있어서 값이 전혀 정렬되지 않는다.
그 결과 인덱스 구조(B-Tree) 상에서 랜덤 쓰기, 랜덤 탐색이 반복되어 인덱스 효율이 급격히 떨어진다.
2) 분석 (Analysis)
- UUID v4: 랜덤 값 기반 → 인덱스가 페이지 split을 반복하게 되고, 캐시 효율도 낮다.
- 따라서 인덱스를 적용해도 실질적인 성능 개선 효과가 거의 없다.
- 대안: UUID v7 → 시간 순서 기반으로 생성되는 UUID
- 값이 정렬되므로 인덱스 삽입 시 순차적 저장 가능
- 범위 검색 및 정렬에도 더 유리
- 기존 랜덤 UUID 대비 인덱스 효율성을 극대화할 수 있다.
- 값이 정렬되므로 인덱스 삽입 시 순차적 저장 가능
3) 해결 방법 (Solution)
- 기존 PickeatCode를 UUID v4 → UUID v7로 마이그레이션후 pickeatCode 컬럼에 인덱스를 적용했다.
- 이렇게 하면 조회 쿼리가 pickeatCode 조건을 사용할 때 인덱스가 안정적으로 동작한다.
4) 적용 결과 (After)
- UUID v7 기반 인덱스로 정렬/탐색이 가능해져 인덱스 효율이 정상화됨
- 조회 시 Full Scan 또는 비효율적 Random IO가 아닌 Index Lookup 활용 가능
- 특히 대규모 Pickeat 테이블에서 코드 기반 조회 속도가 획기적으로 개선될 것으로 기대
회고
쓰기 작업에 대해서
인덱싱을 공부하다 보니 쓰기 작업에 대한 고려도 필요하다는 점을 자주 접했다. 하지만 나는 그동안 “쓰기 부하가 생기겠지” 정도로만 예상하고 깊게 따져보지 않고 넘어간 부분이 많았다.
물론 인덱스라는 게 본질적으로 조회 성능을 높이기 위해 쓰기 성능을 일정 부분 희생하는 구조라는 건 알고 있다. 하지만 만약 쓰기 작업이 많은 API라면, 단순히 직관으로 판단할 게 아니라 구체적인 수치와 리소스 소비량을 측정해서 판단해야 하지 않을까? 하는 의문이 생겼다.
물론 내가 살펴본 위의 쿼리들은 조회 빈도가 훨씬 많은 경우라 쓰기 부하까지 크게 고려하진 않았지만, 쓰기 쿼리에 대한 리소스를 정량적으로 측정할 방법도 고민해야 하는 것 아닐까 싶다.
부하 테스트를 진행할때 쓰기 작업에 대해 병목지점이 생기면 인덱싱을 걸었던 부분을 다시 고민해보아야할 것 같다.
그 전에는 인덱싱을 최소화 하는 방법으로 쓰기 부하를 최소화하도록 하는 것이 좋아보인다.
카디널리티가 낮은 인덱스에 관한 생각
앞선 예시에서 isActive, isDeleted처럼 true/false만 가지는 컬럼은 카디널리티가 1로 매우 낮다. 일반적으로는 카디널리티가 낮으면 인덱스를 걸어도 filter 성능이 떨어지기 때문에, 인덱스로 잘 지정하지 않는다고 알려져 있다.
하지만 우리의 경우처럼 true/false 비율이 99:1 정도로 극단적이고, 주로 1인 경우를 조회해야 한다면 이야기가 달라질 수 있다고 생각했다.
앞선 사례에서는 어차피 id와 함께 조회하는 쿼리라서, id 인덱스가 이미 걸려 있어 isActive나 isDeleted를 복합 인덱스로 포함해도 큰 차이가 없었다. 하지만 만약 boolean 값 자체를 조건으로 직접 조회해야 한다면, 이 경우에는 인덱스를 걸어두는 것이 의미 있다고 판단했다.
복합 인덱스 순서
복합 인덱스 순서에서도 유의미한 결과가 나왔다. 복합 인덱스 순서에서는 cardinality가 높은 순으로 차례로 하는 것이 좋다고 생각한다. 물론 이 또한 서비스마다 다를 수 있는 결과이기에 직접 해보는 것이 유의미 할 것 같다. 앞으로 복합 인덱스를 고려해야한다면 순서를 다르게 적용할 텐데, 복합 인덱스가 많을 수록 순서의 경우의 수가 많을 테니 이러한 기준을 우선순위로 적용해보면 최적의 복합 인덱스를 금방 찾을 수 있을 것 같다.
application 코드 상 놓친 부분들을 발견
쿼리 튜닝을 하다 보면 단순히 인덱스만의 문제가 아니라, 서비스 로직 자체 설계가 잘못됐거나 더 나은 도메인 모델링이 가능하다는 걸 깨달을 때가 있었다. 단순히 쿼리를 빠르게 만드는 걸 넘어서, 서비스 흐름과 데이터 구조 자체를 다시 보게 되는 계기가 된 것 같다.
DB 성능 개선은 아직 남았다.
인덱스 쿼리를 통해서 DB 조회 성능을 개선하였지만 궁극적인 목표인 DB 성능 개선에는 아직 할 일이 많아보인다.
오래된 데이터는 삭제
pickeat의 대부분은 deleted true이고 더이상 조회될 일 없는 데이터이다. 따라서 사용자가 해당 record를 조회하지 않는데도 db에 저장되어 있다면 쿼리 성능을 개선하더라도 지연이 생기는 요인이 될 수 있다. 따라서 s3와 같은 외부 저장소로 삭제되거나 더이상 사용되지 않는 데이터를 옮기는 작업이 필요하다. soft delete 되면서 테이블에 남아있는 데이터에 대한 처리가 중요해보인다.
또 disk에 파편화 된 부분들을 최적화 해주는 작업으로도 db를 정리해야할 것 같다.
해당 부분은 팀원들과 진행중이다.
만약 조회 쿼리가 너무 많다면?
이번 쿼리 성능 개선은 서비스 규모가 크지 않아서 모든 조회 쿼리를 확인하고 인덱싱을 적용할 수 있었다. 하지만 실제 큰 규모의 서비스에서 조회 쿼리가 많다면 모든 쿼리를 직접 확인하기 어려울 것이다. 이 경우에 metric의 모니터링 or slow query log를 활용하는 과정이 필요하다고 생각한다.
혹은 배포 전이라 매트릭 데이터나 log를 확인 할 수 없다면 어떤 도메인이 가장 많이 사용될지를 예측해서 적용해야할 것 같다.
전문 검색, 커버링 인덱스 활용
앞선 쿼리 최적화의 경우에는 전문 검색,커버링 인덱스를 활용할 일이 없어서 적용하지 않았지만 2가지 방법을 통해서 최적화 할 수 있는 사례가 생길 수 있으므로 잘 기억해두어야겠다.
- FULLTEXT 인덱스: 긴 텍스트 컬럼에서 단어/문장 단위로 색인을 만들어, %word% 같은 포함 검색이나 자연어 기반 키워드 검색을 빠르게 해주는 인덱스.
- 커버링 인덱스: 쿼리에 필요한 컬럼이 전부 인덱스 안에 있어서, 테이블 데이터까지 가지 않고 인덱스만으로 결과를 바로 반환할 수 있는 인덱스.

5장에서 비즈니스를 고려해
LIKE '검색어%'형태로 인덱스를 사용할 수 있게 만든 부분 좋은데요?덕분에 인덱스의 정렬 순서상 앞부분(예: '가')이나 뒷부분(예: '하')에 위치한 닉네임이라도 비교적 일정한 속도로 탐색이 가능해졌을 것 같네요.
그러나 닉네임의 분포(예: '김'으로 시작하는 사용자가 압도적으로 많을 때)에 따라 인덱스 스캔 범위나 실제 응답 속도에 차이가 생길 수도 있을 것 같은데, 이런 데이터 분포에 따른 성능 편차도 혹시 함께 검토하셨는지 궁금합니다!