
서론
많은 사용자를 가정하고 tps를 개선하고자 쿼리 인덱싱,부하테스트 혹은 여러 다양한 상황을 고려하기 위해서는 대량의 데이터를 DB에 넣는 작업이 필요하다.
사용자가 많을 수록 많은 데이터가 쌓이는 상황을 고려하는 것은 중요하다고 생각한다. I/O 작업은 지연율에서 항상 많은 비율을 차지하기 때문이다.
따라서 DB에 대량의 데이터를 삽입하기로 결정하였다.
데이터 삽입 과정
얼마만큼의 데이터를 넣을 것인가.
먼저 데이터를 어느정도 넣을 것인지를 결정해야했다.
테이블들을 나열하여 어떤 데이터를 몇건을 넣을지를 결정하였다. 픽잇의 도메인을 분석하며 어떤 테이블에 데이터가 제일 많아야하는지 결정하고 해당 테이블 데이터 크기에 맞춰 나머지 도메인의 데이터 비율을 예상하여 적절한 데이터들을 삽입하기로 하였다.
픽잇 서비스에서 가장 많이 생성될 도메인은 restaurants 였다. 매 픽잇(투표)가 생길때마다 1회성의 식당들이 생성되는데 사용자가 주로 사용하는 기능인 픽잇이 생성될때마다 최대 50개 정도의 데이터가 restaurant 테이블에 쌓일 예정이었다.
따라서 restaurant테이블의 데이터 크기를 100만건으로 잡고 나머지 테이블의 비율을 생각하여 계산하기로 하였다.
| 테이블명 | 데이터 건수 (rows) | 비고 |
|---|---|---|
| users | 30,000 | 사용자 데이터 |
| rooms | 50,000 | 방(모임방 등) 데이터 |
| pickeat | 100,000 | 음식 선택 / 피킷 데이터 |
| participants | 500,000 | 참여자 데이터 |
| restaurants | 1,000,000 | 음식점 데이터 |
| restaurants_likes | 500,000 | 식당 좋아요 데이터 |
| restaurants_results | 100,000 | 식당 결과 데이터 |
| room_users | 70,000 | 방-사용자 매핑 데이터 |
| template | 100 | 기본 템플릿 데이터 |
| template_wish | 5,000 | 위시 템플릿 데이터 |
| wish_v2 | 100,000 | 위시(v2) 데이터 |
어떻게 대량의 데이터를 삽입할 것인가.
대량의 데이터를 DB에 넣기 위해서는 단순히 INSERT문을 N번 반복하기에는 너무 많은 데이터를 넣어야한다. 말 그대로 100만건의 데이터를 직접 넣을 수는 없다.
대량의 데이터를 삽입하기 위해서는 다음과 같은 방법들을 고려할 수 있었다.
- CSV 파일 대량 적재 (LOAD DATA INFILE 등)
- 애플리케이션에서 Batch 처리로 삽입
- 멀티 insert문을 이용한 삽입
- 그 외에도 데이터 마이그레이션 툴이나 ETL 파이프라인을 활용하는 방법도 있다.
우리 팀은 CSV 파일을 생성한 뒤 DB에 적재하는 방식을 사용했다.
csv 더미 데이터로 DB에 적재하기로 한 이유
- MySQL의 LOAD DATA INFILE은 네이티브 기능이라 insert보다 훨씬 빠르다.
- 애플리케이션 레벨에서 batch job을 만들 필요가 없고, 코드 유지보수 부담도 없다.
- DB 레벨에서 바로 적재가 가능하므로 전체 구조가 단순하다.
- 추후에 대량의 데이터를 또 넣어야하는 상황에서 재활용이 가능할 것으로 예상했다.
실제 데이터와 유사하게 하기 위한 과정
데이터를 넣으려고 할때 실제 데이터와 매우 유사한 DB를 만드는 것이 중요하다고 생각하였다.
왜냐하면 인덱싱을 적용하게 되면 실제 데이터를 기준으로 삼게 된다. 이때 우리가 고려한 특정 칼럼의 특성에 따라 인덱싱을 적용한 부분이 생길 수있고 칼럼의 크기같은 특성도 영향을 미치기 때문이다.
따라서 대량의 데이터를 임의의 랜덤값으로 만드는 것이 아닌 실제 서비스를 이용할때 생기는 데이터와 유사하게 만드려고 노력하였다.
픽잇 서비스에서 실제 데이터와 유사하게 고려한 부분
- 자동 삭제되는 테이블의 데이터 비율 설정 스케줄링으로 인해 데이터가 자동으로 삭제되는 특정 테이블은 delete = true가 압도적으로 많은 환경으로 설정하였다. 예를 들어, restaurants처럼 1회성으로 사용되는 데이터가 많은 테이블의 경우 약 95%를 deleted = true, 나머지 5%를 false로 설정하였다.
- 외래키 비율 반영 데이터 간의 연관관계를 고려하여 외래키의 비율을 조정하였다. 예를 들어, 1개의 pickeat은 약 50개의 restaurant와 연결되므로, 대량의 데이터를 삽입할 때 이러한 관계 비율을 유지하도록 설계하였다.
- isActive 필드 비율 설정 isActive 역시 비즈니스 로직상 false가 대부분을 차지하므로, deleted 비율과 유사하게 false 중심의 분포로 설정하였다.
실제 데이터 생성 방법 및 적재 과정
csv 파일을 만들기 위한 방법
대량의 데이터를 만들기 위해서 우리는 간단한 python 코드를 활용하기로 하였다.
이 과정에 AI의 도움을 받으며 빠르게 스크립트를 작성해나갔다.
각 테이블마다 고정된 크기만큼 데이터를 만들었다. 앞서 설명한 실제 데이터와 유사하게 하기 위한 과정들을 고려하여 코드로 적용하였다.
# generate_for_tests.py
import csv, random, uuid
from datetime import datetime, timedelta
from pathlib import Path
# ====== 고정 스케일 ======
NUM_USERS = 30_000
NUM_ROOMS = 50_000
NUM_PICKEAT = 100_000
NUM_PARTICIPANTS = 500_000
NUM_RESTAURANTS = 1_000_000
NUM_LIKES = 500_000
NUM_RESULTS = 100_000
NUM_ROOM_USERS = 70_000
NUM_TEMPLATE = 100
NUM_TEMPLATE_WISH = 5_000
NUM_WISH_V2 = 100_000
# ====== 공통 ======
now = datetime.now()
output_dir = Path("./dummy")
output_dir.mkdir(exist_ok=True)
def rtime():
return (now - timedelta(days=random.randint(0,30))).strftime("%Y-%m-%d %H:%M:%S")
WORDS = ["alpha","bravo","charlie","delta","echo","foxtrot","golf","hotel","india"]
CATEGORIES = ["KOREAN","JAPANESE","CHINESE","ITALIAN","AMERICAN","FUSION"]
RTYPES = ["RESTAURANT","CAFE"]
def fast_word(): return random.choice(WORDS)
def fast_company(i): return f"Company-{i % 10000:04d}"
def fast_address(i): return f"서울특별시 가상구 {1 + (i % 50)}로 {1 + (i % 300)}"
def fast_url(i): return f"https://example.com/{(i * 1315423911) % 1000000}"
def fast_image_url(i): return f"https://img.example.com/{(i * 2654435761) % 1000000}.jpg"
def fast_tags(i): return f"{WORDS[i%len(WORDS)]},{WORDS[(i+3)%len(WORDS)]},{WORDS[(i+5)%len(WORDS)]}"
# ====== 분배 유틸: 총량을 pickeat별로 고르게 배분(RR) ======
def slice_ranges(total_items, buckets):
base = total_items // buckets
rem = total_items % buckets
ranges=[]
start=1
for k in range(1, buckets+1):
count = base + (1 if k <= rem else 0)
end = start + count - 1
if count>0: ranges.append((k, start, end))
else: ranges.append((k, 0, -1))
start = end + 1
return ranges
# ====== room_id 분포 제어(중복/NULL 비율) ======
P_ROOM_NULL = 0.55 # room_id를 NULL로 만들 비율 (빈 문자열로 저장 → 로더에서 NULL 처리)
P_ROOM_DUP = 0.35 # 작은 풀에서 뽑아 중복을 많이 유도
ROOM_DUP_POOL_SIZE = 500 # 작은 풀 크기 (1..ROOM_DUP_POOL_SIZE)
def pick_room_id(i: int) -> str:
r = random.random()
if r < P_ROOM_NULL:
return "" # 빈 문자열 → LOAD DATA에서 NULL
elif r < P_ROOM_NULL + P_ROOM_DUP:
return str(1 + (i % ROOM_DUP_POOL_SIZE)) # 중복이 많이 발생
else:
return str(1 + (i % NUM_ROOMS)) # 넓은 범위
# ====== deleted 분포(선두 95% = 1, 후미 5% = 0) ======
def deleted95(index: int, total: int) -> int:
return 1 if index <= int(total * 0.95) else 0
# =========================
# 테이블 생성
# =========================
# users.csv (항상 deleted=0)
with open(output_dir/"users.csv","w",newline="",encoding="utf-8") as f:
w=csv.writer(f); w.writerow(["id","created_at","updated_at","nickname","provider_id","provider","deleted"])
for i in range(1, NUM_USERS+1):
ts=rtime()
w.writerow([i, ts, ts, f"user{i:06d}", random.randint(10_000_000,99_999_999),
random.choice(["KAKAO","GOOGLE","GITHUB"]), 0])
# room.csv (항상 deleted=0)
with open(output_dir/"room.csv","w",newline="",encoding="utf-8") as f:
w=csv.writer(f); w.writerow(["id","created_at","updated_at","name","deleted"])
for i in range(1, NUM_ROOMS+1):
ts=rtime()
w.writerow([i, ts, ts, fast_word(), 0])
# room_user.csv (항상 deleted=0)
with open(output_dir/"room_user.csv","w",newline="",encoding="utf-8") as f:
w=csv.writer(f); w.writerow(["id","created_at","updated_at","room_id","user_id","deleted"])
for i in range(1, NUM_ROOM_USERS+1):
ts=rtime()
w.writerow([i, ts, ts, 1 + (i % NUM_ROOMS), 1 + (i % NUM_USERS), 0])
# template.csv (항상 deleted=0)
with open(output_dir/"template.csv","w",newline="",encoding="utf-8") as f:
w=csv.writer(f); w.writerow(["id","created_at","updated_at","name","deleted"])
for i in range(1, NUM_TEMPLATE+1):
ts=rtime()
w.writerow([i, ts, ts, f"tpl-{fast_word()}-{i}", 0])
# template_wish.csv (항상 deleted=0)
with open(output_dir/"template_wish.csv","w",newline="",encoding="utf-8") as f:
w=csv.writer(f); w.writerow([
"id","created_at","updated_at","template_id",
"name","food_category","distance","road_address_name","place_url","tags",
"picture_key","picture_url","deleted"
])
for i in range(1, NUM_TEMPLATE_WISH+1):
ts=rtime()
w.writerow([i, ts, ts, 1 + (i % NUM_TEMPLATE),
fast_company(i), random.choice(CATEGORIES), random.randint(10,500),
fast_address(i), fast_url(i), fast_tags(i),
f"pic_{100 + (i%900)}", fast_image_url(i), 0])
# wish_v2.csv (항상 deleted=0)
with open(output_dir/"wish_v2.csv","w",newline="",encoding="utf-8") as f:
w=csv.writer(f); w.writerow([
"id","created_at","updated_at","room_id",
"name","food_category","distance","road_address_name","place_url","tags",
"picture_key","picture_url","deleted"
])
for i in range(1, NUM_WISH_V2+1):
ts=rtime()
w.writerow([i, ts, ts, 1 + (i % NUM_ROOMS),
fast_company(i), random.choice(CATEGORIES), random.randint(10,500),
fast_address(i), fast_url(i), fast_tags(i),
f"pic_{100 + (i%900)}", fast_image_url(i), 0])
# pickeat.csv (deleted=95%:1, 5%:0) + room_id 분포 반영
with open(output_dir/"pickeat.csv","w",newline="",encoding="utf-8") as f:
w=csv.writer(f)
w.writerow(["id","created_at","updated_at","code","name","participant_count","is_active","room_id","deleted"])
for i in range(1, NUM_PICKEAT+1):
ts=rtime()
room_id_value = pick_room_id(i) # "" or "1..N"
del_flag = deleted95(i, NUM_PICKEAT)
w.writerow([i, ts, ts, str(uuid.uuid4()), fast_word(), random.randint(0,10),
random.choice([0,1]), room_id_value, del_flag])
# participant.csv (deleted=95%:1, 5%:0)
p_ranges = slice_ranges(NUM_PARTICIPANTS, NUM_PICKEAT)
with open(output_dir/"participant.csv","w",newline="",encoding="utf-8") as f:
w=csv.writer(f); w.writerow(["id","created_at","updated_at","pickeat_id","nickname","is_completed","deleted"])
pid=1
for pk, s, e in p_ranges:
if s<=e:
for _ in range(s, e+1):
ts=rtime()
del_flag = deleted95(pid, NUM_PARTICIPANTS)
w.writerow([pid, ts, ts, pk, f"nick{pid:06d}", random.choice([0,1]), del_flag])
pid+=1
# restaurant.csv (deleted=95%:1, 5%:0)
r_ranges = slice_ranges(NUM_RESTAURANTS, NUM_PICKEAT)
with open(output_dir/"restaurant.csv","w",newline="",encoding="utf-8") as f:
w=csv.writer(f)
w.writerow([
"id","created_at","updated_at","pickeat_id",
"name","food_category","distance","road_address_name","place_url","tags",
"picture_key","picture_url","is_excluded","like_count","type","deleted"
])
rid=1
for pk, s, e in r_ranges:
if s<=e:
for _ in range(s, e+1):
ts=rtime()
del_flag = deleted95(rid, NUM_RESTAURANTS)
w.writerow([rid, ts, ts, pk, fast_company(rid), CATEGORIES[rid % len(CATEGORIES)],
random.randint(10,500), fast_address(rid), fast_url(rid), fast_tags(rid),
f"pic_{100 + (rid%900)}", fast_image_url(rid),
random.choice([0,1]), random.randint(0,50), RTYPES[rid % len(RTYPES)], del_flag])
rid+=1
# participant / restaurant 의 pickeat 맵(역참조)
part_range_by_pickeat = {}
cum = 0
for pk, s, e in p_ranges:
count = (e - s + 1) if s<=e else 0
if count>0:
part_range_by_pickeat[pk] = (cum+1, cum+count)
cum += count
else:
part_range_by_pickeat[pk] = (0, -1)
rest_range_by_pickeat = {}
cum = 0
for pk, s, e in r_ranges:
count = (e - s + 1) if s<=e else 0
if count>0:
rest_range_by_pickeat[pk] = (cum+1, cum+count)
cum += count
else:
rest_range_by_pickeat[pk] = (0, -1)
def rand_id_in_range(rg):
a,b = rg
if a<=b: return random.randint(a,b)
return 0
# restaurant_like.csv (같은 pickeat 소속 보장, deleted=95%:1, 5%:0)
with open(output_dir/"restaurant_like.csv","w",newline="",encoding="utf-8") as f:
w=csv.writer(f); w.writerow(["id","created_at","updated_at","participant_id","restaurant_id","deleted"])
for i in range(1, NUM_LIKES+1):
ts=rtime()
pk = 1 + (i % NUM_PICKEAT)
p_rg = part_range_by_pickeat[pk]
r_rg = rest_range_by_pickeat[pk]
participant_id = rand_id_in_range(p_rg) or 1
restaurant_id = rand_id_in_range(r_rg) or 1
del_flag = deleted95(i, NUM_LIKES)
w.writerow([i, ts, ts, participant_id, restaurant_id, del_flag])
# pickeat_result.csv (같은 pickeat의 restaurant 사용, deleted=95%:1, 5%:0)
with open(output_dir/"pickeat_result.csv","w",newline="",encoding="utf-8") as f:
w=csv.writer(f); w.writerow(["id","created_at","updated_at","pickeat_id","restaurant_id","has_equal_like","deleted"])
for i in range(1, NUM_RESULTS+1):
ts=rtime()
pk = 1 + (i % NUM_PICKEAT)
r_rg = rest_range_by_pickeat[pk]
restaurant_id = rand_id_in_range(r_rg) or 1
del_flag = deleted95(i, NUM_RESULTS)
w.writerow([i, ts, ts, pk, restaurant_id, random.choice([0,1]), del_flag])
print("완료: 테스트용 CSV 생성 (deleted 분포: pickeat/participant/pickeat_result/restaurant/restaurant_like = 선두95%:1, 후미5%:0; 나머지=0).")
csv 파일을 import하는 과정에서 UUID로 인해 생긴 이슈
스크립트를 실행한 결과로 각 테이블당 데이터들이 모두 csv 파일로 만들어지게 된다.
이제 이 csv파일을 mysql로 옮기면 되었다. 우리는 cloudBeaver라는 DB GUI 오픈소스를 활용하고 있었다. GUI를 통해서 간편하게 csv의 데이터 파일을 import하면 테이블에 데이터를 옮기려고 하였다. 하지만 이때 문제가 발생하였다.
UUID를 삽입하는 과정에서 csv의 UUID 데이터에 넣으려고 할때 문자열을 이진 데이터 즉 BINARY(16)으로 변환해주어야 한다는 것이었다. csv의 데이터는 문자열로 되어있어서 단순 import 만으로는 변환 작업이 불가능하였다.
또 여러 csv 파일을 직접 하나씩 DB에 적재하는 과정이 반복되어 불편하였다.
두가지 문제를 해결하기 위해 우리팀은 쉘 스크립트를 활용하여 데이터를 적재하기로 결정하였다.
쉘 스크립트를 활용하여 여러 csv 파일을 DB에 적재하기
#!/bin/bash
set -e # 하나라도 실패하면 스크립트 종료
# -------------------------------
# 설정 부분
# -------------------------------
CONTAINER_NAME="mysqldb" # 컨테이너 이름
MYSQL_USER= # 사용자
MYSQL_PASSWORD= # 비밀번호
LOCAL_DIR="./dummy" # 로컬 CSV 저장 경로
CONTAINER_DIR="/var/lib/mysql-files" # 컨테이너 내부 경로 (secure-file-priv)
DATABASE_NAME= # 데이터베이스명
export MYSQL_PWD="${MYSQL_PASSWORD}"
# -------------------------------
# 1. CSV 파일 복사
# -------------------------------
echo "📂 ${LOCAL_DIR} → ${CONTAINER_NAME}:${CONTAINER_DIR} 로 파일 복사 시작..."
for file in ${LOCAL_DIR}/*; do
if [ -f "$file" ]; then
echo "→ $(basename "$file") 복사 중..."
docker cp "$file" "${CONTAINER_NAME}:${CONTAINER_DIR}/" || {
echo "❌ $(basename "$file") 복사 실패!"
exit 1
}
fi
done
echo "✅ 파일 복사 완료!"
# -------------------------------
# 2. local_infile 활성화
# -------------------------------
echo "⚙️ MySQL local_infile 설정 중..."
docker exec -e MYSQL_PWD=${MYSQL_PWD} -i ${CONTAINER_NAME} \
mysql -u${MYSQL_USER} --local-infile=1 \
-e "SET GLOBAL local_infile = 1; SHOW VARIABLES LIKE 'local_infile';"
echo "✅ local_infile 설정 완료!"
# -------------------------------
# 3. CSV → MySQL 적재
# -------------------------------
echo "⚙️ CSV 데이터를 MySQL 테이블에 삽입 중..."
docker exec -e MYSQL_PWD=${MYSQL_PWD} -i ${CONTAINER_NAME} \
mysql -u${MYSQL_USER} --local-infile=1 ${DATABASE_NAME} <<'EOF'
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS=0;
-- 초기화
TRUNCATE TABLE users;
TRUNCATE TABLE room;
TRUNCATE TABLE pickeat;
TRUNCATE TABLE participant;
TRUNCATE TABLE restaurant;
TRUNCATE TABLE restaurant_like;
TRUNCATE TABLE pickeat_result;
TRUNCATE TABLE room_user;
TRUNCATE TABLE template;
TRUNCATE TABLE template_wish;
TRUNCATE TABLE wish_v2;
-- ============================
-- users
-- ============================
LOAD DATA LOCAL INFILE '/var/lib/mysql-files/users.csv'
INTO TABLE users
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 LINES
(@id,@created_at,@updated_at,@nickname,@provider_id,@provider,@deleted)
SET id=NULLIF(@id,''),
created_at=STR_TO_DATE(@created_at,'%Y-%m-%d %H:%i:%s'),
updated_at=STR_TO_DATE(@updated_at,'%Y-%m-%d %H:%i:%s'),
nickname=@nickname,
provider_id=NULLIF(@provider_id,''),
provider=@provider,
deleted=IFNULL(NULLIF(TRIM(@deleted),''),0);
-- ============================
-- room
-- ============================
LOAD DATA LOCAL INFILE '/var/lib/mysql-files/room.csv'
INTO TABLE room
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 LINES
(@id,@created_at,@updated_at,@name,@deleted)
SET id=NULLIF(@id,''),
created_at=STR_TO_DATE(@created_at,'%Y-%m-%d %H:%i:%s'),
updated_at=STR_TO_DATE(@updated_at,'%Y-%m-%d %H:%i:%s'),
name=@name,
deleted=IFNULL(NULLIF(TRIM(@deleted),''),0);
-- ============================
-- pickeat
-- ============================
LOAD DATA LOCAL INFILE '/var/lib/mysql-files/pickeat.csv'
INTO TABLE pickeat
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 LINES
(@id,@created_at,@updated_at,@code,@name,@participant_count,@is_active,@room_id,@deleted)
SET id=NULLIF(@id,''),
created_at=STR_TO_DATE(@created_at,'%Y-%m-%d %H:%i:%s'),
updated_at=STR_TO_DATE(@updated_at,'%Y-%m-%d %H:%i:%s'),
code=UUID_TO_BIN(NULLIF(@code,'')),
name=@name,
participant_count=NULLIF(@participant_count,''),
is_active=NULLIF(@is_active,''),
room_id=NULLIF(@room_id,''),
deleted=IFNULL(NULLIF(TRIM(@deleted),''),0);
-- ============================
-- participant
-- ============================
LOAD DATA LOCAL INFILE '/var/lib/mysql-files/participant.csv'
INTO TABLE participant
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 LINES
(@id,@created_at,@updated_at,@pickeat_id,@nickname,@is_completed,@deleted)
SET id=NULLIF(@id,''),
created_at=STR_TO_DATE(@created_at,'%Y-%m-%d %H:%i:%s'),
updated_at=STR_TO_DATE(@updated_at,'%Y-%m-%d %H:%i:%s'),
pickeat_id=NULLIF(@pickeat_id,''),
nickname=@nickname,
is_completed=NULLIF(@is_completed,''),
deleted=IFNULL(NULLIF(TRIM(@deleted),''),0);
-- ============================
-- restaurant
-- ============================
LOAD DATA LOCAL INFILE '/var/lib/mysql-files/restaurant.csv'
INTO TABLE restaurant
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 LINES
(@id,@created_at,@updated_at,@pickeat_id,
@name,@food_category,@distance,@road_address_name,@place_url,@tags,
@picture_key,@picture_url,
@is_excluded,@like_count,@type,@deleted)
SET id=NULLIF(@id,''),
created_at=STR_TO_DATE(@created_at,'%Y-%m-%d %H:%i:%s'),
updated_at=STR_TO_DATE(@updated_at,'%Y-%m-%d %H:%i:%s'),
pickeat_id=NULLIF(@pickeat_id,''),
name=@name,
food_category=@food_category,
distance=NULLIF(@distance,''),
road_address_name=@road_address_name,
place_url=@place_url,
tags=NULLIF(@tags,''),
picture_key=NULLIF(@picture_key,''),
picture_url=NULLIF(@picture_url,''),
is_excluded=NULLIF(@is_excluded,''),
like_count=NULLIF(@like_count,''),
type=@type,
deleted=IFNULL(NULLIF(TRIM(@deleted),''),0);
-- ============================
-- restaurant_like
-- ============================
LOAD DATA LOCAL INFILE '/var/lib/mysql-files/restaurant_like.csv'
INTO TABLE restaurant_like
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 LINES
(@id,@created_at,@updated_at,@participant_id,@restaurant_id,@deleted)
SET id=NULLIF(@id,''),
created_at=STR_TO_DATE(@created_at,'%Y-%m-%d %H:%i:%s'),
updated_at=STR_TO_DATE(@updated_at,'%Y-%m-%d %H:%i:%s'),
participant_id=NULLIF(@participant_id,''),
restaurant_id=NULLIF(@restaurant_id,''),
deleted=IFNULL(NULLIF(TRIM(@deleted),''),0);
-- ============================
-- pickeat_result
-- ============================
LOAD DATA LOCAL INFILE '/var/lib/mysql-files/pickeat_result.csv'
INTO TABLE pickeat_result
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 LINES
(@id,@created_at,@updated_at,@pickeat_id,@restaurant_id,@has_equal_like,@deleted)
SET id=NULLIF(@id,''),
created_at=STR_TO_DATE(@created_at,'%Y-%m-%d %H:%i:%s'),
updated_at=STR_TO_DATE(@updated_at,'%Y-%m-%d %H:%i:%s'),
pickeat_id=NULLIF(@pickeat_id,''),
restaurant_id=NULLIF(@restaurant_id,''),
has_equal_like=NULLIF(@has_equal_like,''),
deleted=IFNULL(NULLIF(TRIM(@deleted),''),0);
-- ============================
-- room_user
-- ============================
LOAD DATA LOCAL INFILE '/var/lib/mysql-files/room_user.csv'
INTO TABLE room_user
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 LINES
(@id,@created_at,@updated_at,@room_id,@user_id,@deleted)
SET id=NULLIF(@id,''),
created_at=STR_TO_DATE(@created_at,'%Y-%m-%d %H:%i:%s'),
updated_at=STR_TO_DATE(@updated_at,'%Y-%m-%d %H:%i:%s'),
room_id=NULLIF(@room_id,''),
user_id=NULLIF(@user_id,''),
deleted=IFNULL(NULLIF(TRIM(@deleted),''),0);
-- ============================
-- template
-- ============================
LOAD DATA LOCAL INFILE '/var/lib/mysql-files/template.csv'
INTO TABLE template
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 LINES
(@id,@created_at,@updated_at,@name,@deleted)
SET id=NULLIF(@id,''),
created_at=STR_TO_DATE(@created_at,'%Y-%m-%d %H:%i:%s'),
updated_at=STR_TO_DATE(@updated_at,'%Y-%m-%d %H:%i:%s'),
name=@name,
deleted=IFNULL(NULLIF(TRIM(@deleted),''),0);
-- ============================
-- template_wish
-- ============================
LOAD DATA LOCAL INFILE '/var/lib/mysql-files/template_wish.csv'
INTO TABLE template_wish
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 LINES
(@id,@created_at,@updated_at,@template_id,
@name,@food_category,@distance,@road_address_name,@place_url,@tags,
@picture_key,@picture_url,@deleted)
SET id=NULLIF(@id,''),
created_at=STR_TO_DATE(@created_at,'%Y-%m-%d %H:%i:%s'),
updated_at=STR_TO_DATE(@updated_at,'%Y-%m-%d %H:%i:%s'),
template_id=NULLIF(@template_id,''),
name=@name,
food_category=@food_category,
distance=NULLIF(@distance,''),
road_address_name=@road_address_name,
place_url=@place_url,
tags=NULLIF(@tags,''),
picture_key=NULLIF(@picture_key,''),
picture_url=NULLIF(@picture_url,''),
deleted=IFNULL(NULLIF(TRIM(@deleted),''),0);
-- ============================
-- wish_v2
-- ============================
LOAD DATA LOCAL INFILE '/var/lib/mysql-files/wish_v2.csv'
INTO TABLE wish_v2
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 LINES
(@id,@created_at,@updated_at,@room_id,
@name,@food_category,@distance,@road_address_name,@place_url,@tags,
@picture_key,@picture_url,@deleted)
SET id=NULLIF(@id,''),
created_at=STR_TO_DATE(@created_at,'%Y-%m-%d %H:%i:%s'),
updated_at=STR_TO_DATE(@updated_at,'%Y-%m-%d %H:%i:%s'),
room_id=NULLIF(@room_id,''),
name=@name,
food_category=@food_category,
distance=NULLIF(@distance,''),
road_address_name=@road_address_name,
place_url=@place_url,
tags=NULLIF(@tags,''),
picture_key=NULLIF(@picture_key,''),
picture_url=NULLIF(@picture_url,''),
deleted=IFNULL(NULLIF(TRIM(@deleted),''),0);
-- ============================
-- AUTO_INCREMENT 재설정 (MAX(id)+1)
-- ============================
SET @next := 0; SET @sql := '';
SELECT @next := IFNULL(MAX(id),0)+1 FROM users;
SET @sql := CONCAT('ALTER TABLE users AUTO_INCREMENT=', @next); PREPARE s FROM @sql; EXECUTE s; DEALLOCATE PREPARE s;
SELECT @next := IFNULL(MAX(id),0)+1 FROM room;
SET @sql := CONCAT('ALTER TABLE room AUTO_INCREMENT=', @next); PREPARE s FROM @sql; EXECUTE s; DEALLOCATE PREPARE s;
SELECT @next := IFNULL(MAX(id),0)+1 FROM pickeat;
SET @sql := CONCAT('ALTER TABLE pickeat AUTO_INCREMENT=', @next); PREPARE s FROM @sql; EXECUTE s; DEALLOCATE PREPARE s;
SELECT @next := IFNULL(MAX(id),0)+1 FROM participant;
SET @sql := CONCAT('ALTER TABLE participant AUTO_INCREMENT=', @next); PREPARE s FROM @sql; EXECUTE s; DEALLOCATE PREPARE s;
SELECT @next := IFNULL(MAX(id),0)+1 FROM restaurant;
SET @sql := CONCAT('ALTER TABLE restaurant AUTO_INCREMENT=', @next); PREPARE s FROM @sql; EXECUTE s; DEALLOCATE PREPARE s;
SELECT @next := IFNULL(MAX(id),0)+1 FROM restaurant_like;
SET @sql := CONCAT('ALTER TABLE restaurant_like AUTO_INCREMENT=', @next); PREPARE s FROM @sql; EXECUTE s; DEALLOCATE PREPARE s;
SELECT @next := IFNULL(MAX(id),0)+1 FROM pickeat_result;
SET @sql := CONCAT('ALTER TABLE pickeat_result AUTO_INCREMENT=', @next); PREPARE s FROM @sql; EXECUTE s; DEALLOCATE PREPARE s;
SELECT @next := IFNULL(MAX(id),0)+1 FROM room_user;
SET @sql := CONCAT('ALTER TABLE room_user AUTO_INCREMENT=', @next); PREPARE s FROM @sql; EXECUTE s; DEALLOCATE PREPARE s;
SELECT @next := IFNULL(MAX(id),0)+1 FROM template;
SET @sql := CONCAT('ALTER TABLE template AUTO_INCREMENT=', @next); PREPARE s FROM @sql; EXECUTE s; DEALLOCATE PREPARE s;
SELECT @next := IFNULL(MAX(id),0)+1 FROM template_wish;
SET @sql := CONCAT('ALTER TABLE template_wish AUTO_INCREMENT=', @next); PREPARE s FROM @sql; EXECUTE s; DEALLOCATE PREPARE s;
SELECT @next := IFNULL(MAX(id),0)+1 FROM wish_v2;
SET @sql := CONCAT('ALTER TABLE wish_v2 AUTO_INCREMENT=', @next); PREPARE s FROM @sql; EXECUTE s; DEALLOCATE PREPARE s;
SET FOREIGN_KEY_CHECKS=1;
EOF
echo "✅ CSV → MySQL 적재 완료! (deleted 강제 0 매핑, AUTO_INCREMENT 리셋 포함)"이 스크립트를 해당 csv 폴더에서 실행시킨다면 바로 적재시킬 수 있었다.
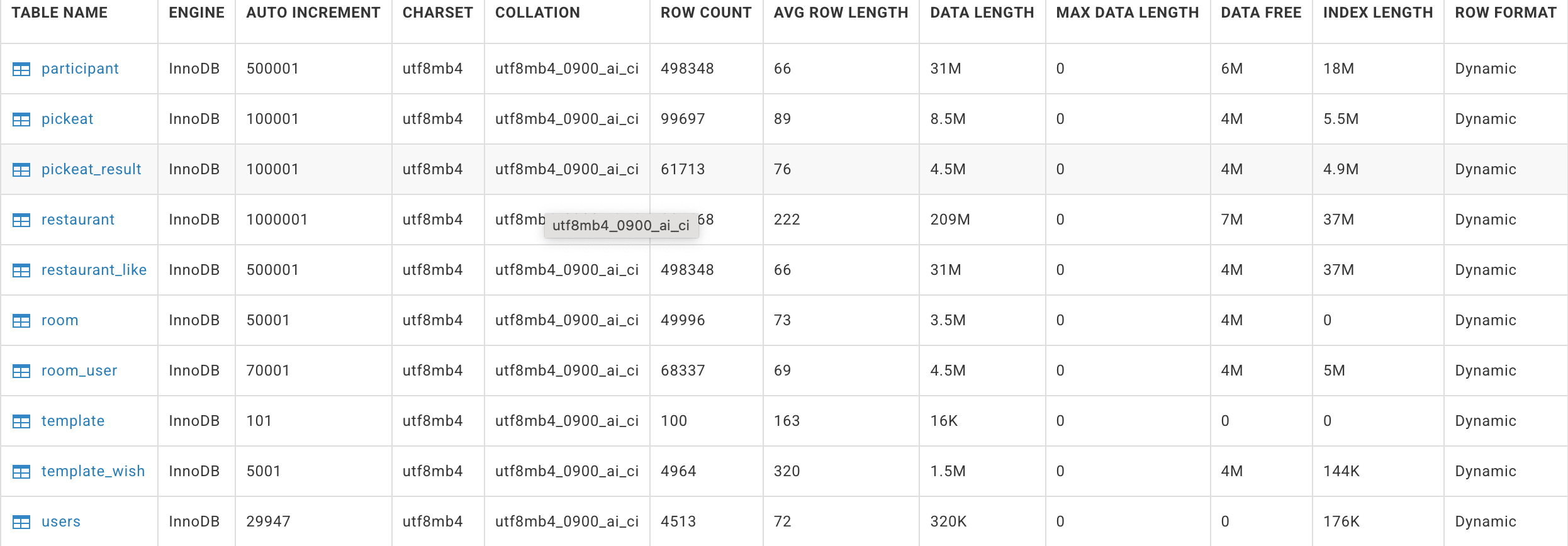
스크립트를 활용하여 얻은 효율성
앞선 두 python스크립트와 쉘스크립트가 있다면 앞으로 우리는 어느 DB에서든 쉽게 대량의 데이터를 적재할 수 있었다.
스크립트를 작성하는 과정이 매우 번거롭고 생각보다 작업시간이 많이 소요되었는데 이후 자주 사용할 수 있게 되어 활용성이 좋았다.
회고
실제 데이터 환경과 유사성은 생각보다 중요하다.
대량의 데이터를 적재하다 보면 실제 데이터와 유사하지 않게 구현하는것이 편할 수는 있지만, 인덱싱 및 부하테스트에서 성능이 다르게 나올 수 있다고 생각했다.
사용자들이 쌓일 수록 완벽하게 일치하는 데이터를 얻기에는 어려울 것 같지만, 도메인을 따라가면서 최대한 상황을 가정하고 데이터를 만드는 것이 유의미한 결과를 만들어내는데 도움을 준다고 생각한다.
대량의 데이터 작업의 복잡성을 위한 스크립트에 대한 회고
대량의 데이터를 적재하다 보면 큰 데이터를 생성하고 직접 넣고 확인하는 작업이 반복되었다.
예상과는 다르게 데이터가 생겼는지를 직접 확인하기 위해서 100만건의 데이터를 모두 확인할 수는 없었다. 또 도메인 설계를 보고 테이블 데이터를 생성할때 도메인과 다르게 놓친 부분이 있다면 실제 어플리케이션을 실행시켜 테스트해보기 전까지 확인하기 어려웠다.
부하테스트 과정에서 데이터에 문제가 생길 수 있고(비즈니스 로직으로 인한) UUID를 적재하는 과정에서도 많은 문제가 생겼다.
대량의 데이터 작업은 이처럼 예상하기 어렵고 시간이 오래 걸리는 작업이므로 시간을 투자하더라도 서비스에 유연한 스크립트 파일을 작성해두는 것이 이런 작업을 반복하지 않는 방법일 것 같다.
상황마다 다른 데이터의 크기
대량의 데이터를 적재해야하는 상황에서 현재 100만건 규모의 데이터를 넣고 있었고, 또 모든 테이블마다 100만건의 데이터를 삽입하고 있지는 않았다. 제일 많이 쌓일 것 같은 도메인을 기준으로 적절히 예상 비율로 데이터 크기를 정하였지만 이는 상황마다 다를 것 같다.
원하는 테스트 상황마다 얼만큼의 데이터를 넣을지 다를 것 같다. 쿼리 인덱싱을 위해서는 점진적으로 데이터 크기를 늘려나갈 수 있을 것이고, 부하 테스트를 위해서는 원하는 tps에 맞는 데이터의 크기를 넣는 것이 좋을 것이다.

회고하신 부분이 저도 공감되네요👍🏻 잘 읽었습니다