1회독 3주차 개발일지
링크텍스트
크롤링을 한 정보를 웹페이지에 붙여 넣기 해보았다.
그리고 파이썬의 기초.
파이썬도 변수, 자료형, 함수, 조건문, 반복문의 다섯가지 형태를 기본적으로 배웠다.
직관적인 형태라 let을 불러주지 않아도 되고, {}를 하지 않아도 된다는 점은 좋았지만,
아직 자바스크립트도 위태위태한 상태에서 파이썬을 밀어넣어도 되는 것인가 하는 불안감이 있었다.
일단 따라 쓰고 배울때는 재미있었다며...
크롤링을 하려면 다른 사람들이 만들어둔 라이브러리를 사용하면 편리하다고 한다.
그걸 패키지라고 부르는데, 별도로 설치가 가능했다.
1회독때 익혔던 터라 패키지를 설치하고 폴더를 만들고 하는건 익숙한 상황이었다.
프로젝트(폴더)마다 패키지를 설치해서 사용해야하기 때문에 필요한 패키지는 그때그때 설치를 해서 사용하는 것으로...
웹스크래핑(크롤링)의 기초에서 필요한 패키지는 beautifulsoup 이라는 라이브러리이다.
bs4라고 되어있는데 설치를 하면 된다. 지금 배우는 것은 파이썬 문법이 아닌 beautifulsoup의 사용방법이다.
설치법은 맥 기준이다.
Pycharm - preferences - 프로젝트 :pythonprac - python 인터프리터 - +버튼 - bs4 검색 - bs4선택 - 패키지 설치 클릭
가지고 오고 싶은 페이지의 요소를 오른쪽 마우스 버튼 클릭해서 검사 한다음 콘솔창을 띄워서 선택되어있는 부분에 대고 다시 오른쪽마우스 버튼을 클릭하면 복사 - selector 복사(copy) 하면 된다.
soup.select_one(요소 붙여넣기)
파이썬에서는 같지 않음을 !=로 써도 되지만, 더 직관적으로 is not을 써주어도 된다.
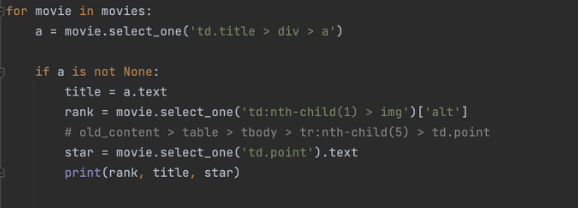
이제 mongoDB atlas를 연결해서, 본격적인 데이터베이스 쌓기를 연습해본다.
mongoDB는 NoSQL이다. 유연하게 변경가능하지만 체계적으로 쌓을순 없어서 빠르게 변화하는 초기 스타트업에서는 유용한 데이터베이스 저장방식이라고 한다.
1회독때 mongoDB atlas 연결하느라 12시간이 넘는 시간을 소요했었는데,
m1칩을 쓰고 있어서 그런것인지 내 노트북만 그런것인지 모르겠지만 certifi라는 패키지가 추가로 필요했다.
그때 만들어뒀던 코드를 그대로 가져와서 사용했다.
물론, 1회독때 만들었던 cluster0 말고 새로운 cluster1을 만들어서 새롭게 연결해주었다.
이렇게 쉬운것을...
저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
all_users = list(db.users.find({},{'_id':False}))
바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
지우기 - 예시
db.users.delete_one({'name':'bobby'})
이 코드들을 참고해서 데이터를 찾고, 찾아서 변경하고, 삭제하고 등등을 해볼수가 있다.
숙제로는 지니뮤직사이트에서 1위~50위권의 노래목록을 크롤링해서
순위, 노래명, 가수명을 쭉 리스트업하는 것이었다.
이 과제에서 가장 난제는 크롤링해온 정보가 띄어쓰기 없이 예쁘게 정리되는 것이었다.
중간에 19금 아이콘이 붙어있는 제목 때문에 시간이 조금 걸렸다.
strip()을 활용해서 전체 공백을 지워주고, lstrip(), rstrip(), lstrip('19금')을 붙여줘서 왼쪽 여백 지우고, 오른쪽 여백 지우고, 왼쪽 19금 문자열 지우는 방식으로 싹 정리를 해주면서 깨끗한 크롤링을 할수 있었다.
rank = song.select_one('td.number').text[0:2].strip().rstrip()
singer는 쉬웠다.
singer = song.select_one('td.info > a.artist.ellipsis').text
이런식으로...
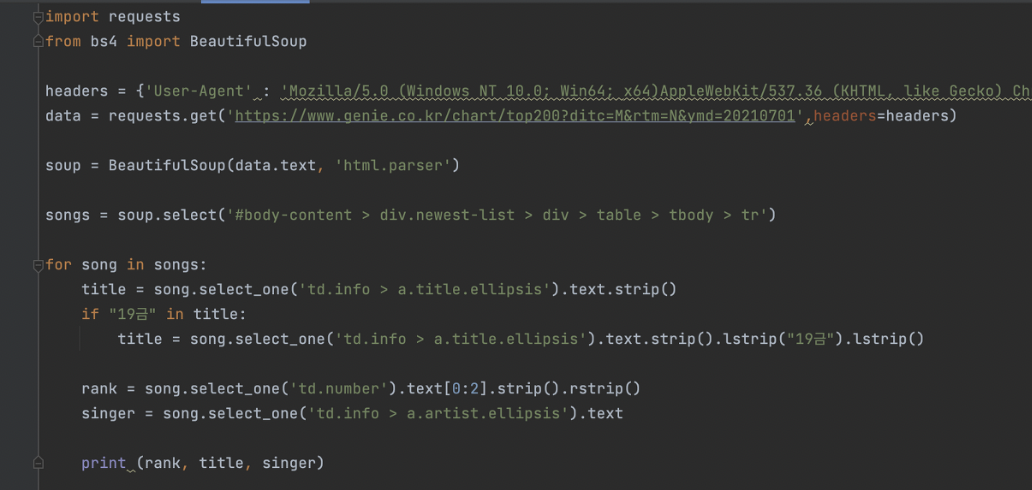
최종코드 화면이다.
