이번 시간에는 RIverVIEW 장고 프로젝트를 위한 각종 설정과 SQLite3 데이터베이스 구축의 과정에 대해 포스팅 하려 한다.
config.setting.py
config 디렉토리의 구조는 다음과 같다. 하지만 사실상 여기서 사용하는 파일은 settings.py 밖에 없다. setting.py 파일에서는 먼저 App을 생성했으면, 장고가 경로를 찾을수 있도록 등록을 해주어야 한다.
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'RIverVIEW'
]위와 같이 RiverVIEW 앱을 추가해 주었다.
사용자에게 보여줄 화면인 Template을 장고가 경로를 찾을 수 있도록 설정을 해줄수도 있다.
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [BASE_DIR / 'templates'],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},이곳에서는 기본 설정 그대로 사용해 주었다. 만약 Template으로 사용할 폴터의 이름이 templates이 아니거나, 경로를 바꿔야 한다면 여기서 설정해주면 된다.
정적파일에 대한 static 디렉토리의 경로도 설정해 줄 수 있다.
STATIC_URL = '/static/'
STATICFILES_DIRS = [
os.path.join(BASE_DIR, 'static')
]이 부분도 기본 설정을 사용하였다.
그리고 url 경로 설정을 따루 해주어야 한다. 스프링에서는 컨트롤러에서 url 호출 경로를 설정하여 주었는데 장고에서는 urls.py 파일에서 모든 url 경로를 한꺼번에 모아둔다. 아래는 RIverVIEW/urls.py의 코드이다.
urlpatterns = [
path('', views.foward_home),
path('search/', views.search),
path('details/<int:product_num>/',views.view_details),
path() 함수의 첫번째 파라미터는 url경로를 지정하는 것이고, 두번째 파라미터는 이 해당 url이 호출되었을 때 실행할 View를 설정한 것이다. 이와 같이 View를 연결할 수 있고, 실제로 views 디렉토리에 view 호출시 실행할 메서드를 정의해야 한다.
DataBase(SQLite3) 구축
장고에서는 기본적으로 SQLite를 사용하도록 구성되어 있고, 이는 setting.py에 기본적으로 설정되어 있다.
이제 데이터베이스 모델을 생성해야 하는데, 모델은 models.py 파일에서 정의할 수 잇다.
이번에 진행할 프로젝트에서는 두개의 테이블이 필요했다. 하나는 리뷰분석 요청된 상품에 대한 정보를 저장할 상품 테이블, 하나는 상품 리뷰에 대한 키워드에 대한 테이블이다. 상품 리뷰에 대한 키워드는 상품당 여러개가 있을 수 있으므로, FK(외래키)를 통해 일대다 관계를 매핑해 주었다.
class ProductModel(models.Model):
class Meta:
db_table = "product"
product_url = models.CharField(max_length=256, default='')
product_name = models.CharField(max_length=256, default='')
product_num = models.IntegerField(primary_key= True)
img_src = models.CharField(max_length=256, default='')
product_score = models.IntegerField(null=True)
updated_at = models.DateTimeField(auto_now=True)
class ProductKeyword(models.Model):
class Meta:
db_table = "PDkeyword"
ordering = ["-keyword_frequency"]
product_reference = models.ForeignKey(ProductModel, on_delete=models.CASCADE)
keyword = models.CharField(max_length=20, default='')
review = models.CharField(max_length=256, default='') #해당 키워드의 대표 리뷰
keyword_score = models.FloatField(default=0) #키워드의 점수 (긍정이면 + 부정이면 -)
keyword_frequency = models.IntegerField(null=True)위와 같이 스키마를 작성하여 주었다. 테이블 이름과 테이블의 각 컬럼들을 정의한다. PK(기본키)는 따로 설정하지 않으면, 자동으로 1,2,3,4...순서로 생성된다.이 프로젝트에서는 기본키를 product_num으로 사용할 것이기 때문에 이 속성을 정의 할 때primary_key=True로 설정하여 기본키를 명시해 두었다.상품 키워드 테이블의 기본키는 상품 테이블의 기본키를 외래키로 사용하였기 때문에 product_reference 컬럼을 정의할 때 설정해 주었다.
이렇게 테이블을 정의해 주었다면, 장고에게 모델이 생성되었다는 것을 알려주기 위해 터미널에서 makemigrations 명령어를 입력해 주어야 한다. 그 다음에 migrate 명령어를 사용하면 데이터베이스 모델을 생성하여 db.sqlite3이 생성된다. 만약 models.py에서 테이블 구조를 바꾸었는데 makemigrations와 migrate 명령어를 실행하지 않는다면 실제 데이터베이스에서는 적용되지 않기때문에 주의해야 한다.
SQLite 데이터베이스를 보기 쉽고, 편하게 관리할 수 있는 프로그램인 "DB Browser for SQLite" 을 깔면 훨씬 데이터베이스를 관리하기 쉬워진다.
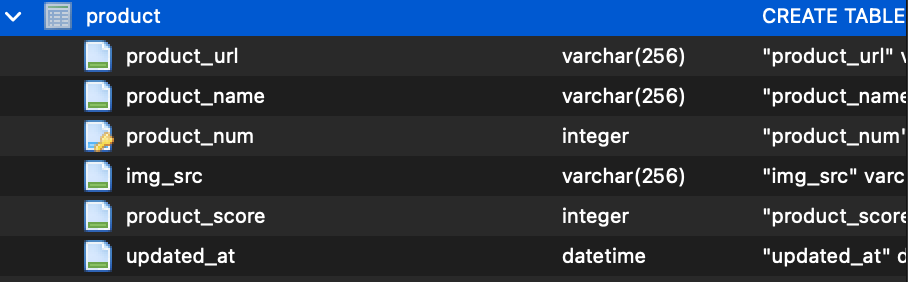
"DB Browser for SQLite"을 통해 db.sqlite3 파일을 확인하면 위와 같이 보기 쉽게 나온다. 테이블 구조 뿐만 아니라 db에 저장된 데이터도 볼 수 있고, 입력,수정,삭제도 여기서 가능하다.
이렇게 RiverViEW 프로젝트를 시작하기 위한 설정과 db를 구축하였다. 다음 포스팅에서는 네이버 쇼핑의 상품 리뷰를 크롤링 하는 과정에 대해 작성하려고 한다. 여기까지는 그래도 어느정도 익숙한 내용이라 어려움이 없었는데, 크롤링은 처음 해봤기 때문에 나에게 조금 어려웠던 것 같다. 다음 포스팅에서 크롤링에 대해 복습할 겸 다시 기억을 되살려봐야겠다.
