Project_RIverVIEW
1.RIverVIEW_(0)프로젝트 계획
이번 3-2학기에는 캡스톤디자인 과목을 들어서 프로젝트를 진행한다.주제는 딥러닝을 사용한 자유주제이다.2인 프로젝트이고, 학기 중 진행하다보니 어느 정도의 난이도와 퀄리티의 프로젝트를 선정해야 할지 고민이 많았다. 인공지능 수업을 듣긴 들었지만, 제대로 사용해보는건 이
2.RIverVIEW_(1)프로젝트 시작

현재 이 글을 포스팅하는 날짜는 1월 3일이다. 이미 학기가 마무리 되었고, 이 프로젝트 또한 마무리 된 시점이다. 핑계인 걸 알지만 너무 바빴다. 사실 velog를 프로젝트를 진행하면서 틈틈히 썼어야 했는데 그러지 못했다. 한번 미뤄지고 두번 미뤄지다 보니 그냥 방학
3.RIverVIEW_(2)각종 설정, db구축
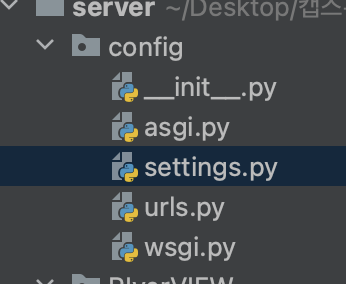
이번 시간에는 RIverVIEW 장고 프로젝트를 위한 각종 설정과 SQLite3 데이터베이스 구축의 과정에 대해 포스팅 하려 한다.config 디렉토리의 구조는 다음과 같다. 하지만 사실상 여기서 사용하는 파일은 settings.py 밖에 없다. setting.py 파
4.RIverVIEW_(3)크롤링

이 화면에서 네이버 쇼핑에서 리뷰를 분석하고 싶은 상품의 주소를 입력하면, /search url을 호출한다. 그리고 아래와 같이, urls.py 에서 설정해둔 View와 연결하여 view.py의 search 메소드를 실행한다. search 메소드에서는 먼저 입력받
5.RIverVIEW_(4)데이터 전처리
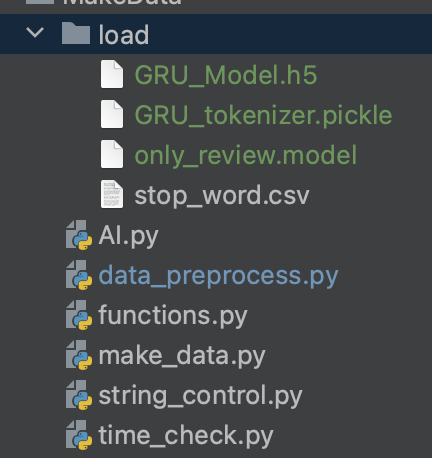
이번 시간에는 크롤링을 해서 받아온 상품의 리뷰를 이용해, 딥러닝 모델을 통한 분석 결과를 도출하기까지 어떤 과정을 거쳤는지 포스팅하려 한다.먼저, 리뷰를 분석하기 위해 사용되는 딥러닝 모델과 데이터 처리 함수를 구현한 파일 구조는 다음고 같다.우선 크롤링을 완료하면
6.RIverVIEW_(5)키워드 추출, 만족도 계산
이번에는 전처리가 완료된 리뷰 데이터를 통해서, 상품 리뷰의 키워드를 추출하고, 리뷰의 감성을 분석하여 키워드 별 만족도를 계산하는 과정에 대해서 알아보도록 하겠다.키워드를 추출하기 전에 먼저, 리뷰 세트마다 tf-idf를 적용하여 단어별 중요도를 뽑아야 한다.tf-i
7.RIverVIEW_(6)결과 페이지, 후기

사용자로부터 상품 페이지 url을 입력받아 결과를 출력하는 과정은 다음과 같다. (1) 상품 페이지 URL이 입력으로 들어옴 -> 해당 리뷰 페이지 크롤링 -> 상품 리뷰, 정보 등 추출 (2) 상품정보와 리뷰를 이용하여 키워드 추출 (3) 키워드별 만족도 계산