문제

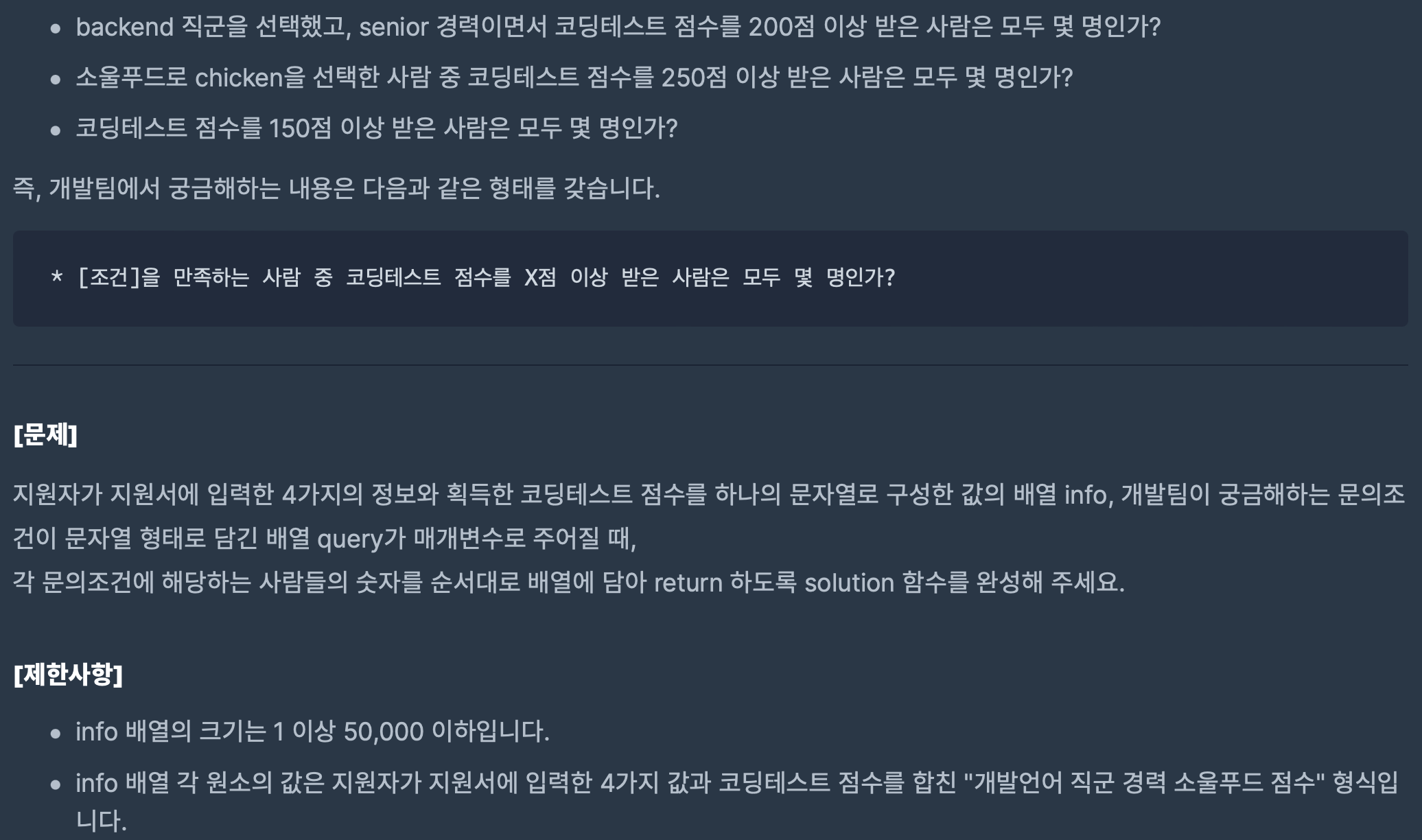

코드
import java.util.*;
class Solution {
Map<String,ArrayList<Integer>> map=new HashMap<>();
public int[] solution(String[] info, String[] query) {
int[] answer = new int[query.length];
for(String s:info)
dfs("",0,s.split(" "));
for(String key:map.keySet())
Collections.sort(map.get(key));
for(int i=0;i<query.length;i++){
String s=query[i].replaceAll(" and ","");
String[] required=s.split(" ");
if(map.containsKey(required[0])){
ArrayList<Integer> arr=map.get(required[0]);
int score=Integer.parseInt(required[1]);
int start=0;
int end=arr.size()-1;
while(start<=end){
int mid=(end+start)/2;
if(arr.get(mid)<score)
start=mid+1;
else
end=mid-1;
}
answer[i]=arr.size()-start;
}
}
return answer;
}
public void dfs(String str,int depth,String[] info){
if(depth==4)
{
if(map.containsKey(str))
map.get(str).add(Integer.parseInt(info[4]));
else{
ArrayList<Integer> arr=new ArrayList<>();
arr.add(Integer.parseInt(info[4]));
map.put(str,arr);
}
return;
}
dfs(str+info[depth],depth+1,info);
dfs(str+"-",depth+1,info);
}
}풀이
요구사항마다 각각 한명씩 요구사항을 충족하는지 검사하면 정확성 테스트는 통과하지만, 효율성 테스트에서 탈락하기 때문에 더 효율적인 방법을 사용해야 한다. 풀이 과정은 아래와 같다.
(1) info 배열 안에 있는 지원자들의 정보를 하나씩 순회하면서 이 지원자가 통과할 수 있는 조건을 Key, 지원자의 점수를 Value로 지정하여 HashMap에 넣어준다.
- 해시맵은 HashMap<String(조건),ArrayList(이 조건을 만족하는 모든 참가자들의 점수들)> 형태이어야 한다.
- 통과하는 조건을 하나하나 전부 넣어주어야 한다. 통과할 수 있는 조건의 경우의 수는 2^4이므로 16가지이다.
- 통과하는 조건을 만드는 문자열은 dfs 방식으로 만들어 준다.
(2) (1)에서 만들어진 HashMap의 모든 항목들의 점수 리스트를 Collection.sort() 메소드로 오름차순 정렬을 시켜준다.
(3) query 항목을 하나씩 돌면서, 이 조건이 HashMap의 키 값으로 존재하면 value(점수 리스트)를 받아온다.
(4) query에서 요구하는 점수를 넘는 지원자들의 수를 세어 answer 배열에 넣어준다. (이 때, 이진탐색으로 요구점수를 검색한다.)
결과
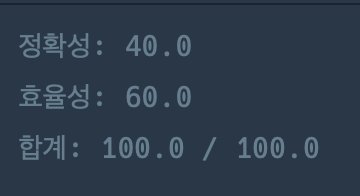
정말 애를 많이 먹었던 문제이다.
처음에는 지원자들 하나하나 돌면서 요구조건을 만족하는지 확인하면 되
는 것이 아닌가 생각했는데, 이 때 정확성 테스트는 통과하지만 효율성은 통과하지 못한다.(지원자 수가 n, 요구조건 개수가 m 이라고 했을 때, n*m번 조건을 확인하는 과정을 거쳐야 한다.) 그래서 다른 방법을 찾아야 했다.
도무지 다른방법이 생각나지 않아서, 다른사람의 풀이를 참고했다.(다른 사람의 풀이를 보면서 이해하는 것도 오래걸렸다.)
지원자 한명씩 돌면서, 이 지원자가 통과할 수 있는 요구 조건을 전부 HashMap에 미리 넣어 둔다는 방식을 생각할 수 있다는 것이 놀라웠다.
이때 연산 횟수를 대충 계산해보면 n(지원자 수) *16(이 지원자가 통과할 수 있는 조건의 모든 경우의 수) + m(요구조건 개수) 이다.
점수 리스트를 정렬하고, 이진 탐색으로 요구 점수를 점수리스트에서 찾는 연산을 생각하더라도, 요구 조건 하나하나를 지원자 한명한명 검사하는 것보다는 훨씬 더 효율적이다.
이 문제를 해결하는 방법 자체를 생각하는 것도 매우 어렵지만,
dfs와 이진탐색을 직접 구현해야 하는 것도 쉽지는 않았다.
이진 탐색같은 경우에는 Collections.binarySearch() 메소드를 사용하면 되는것이 아닌가 생각했는데, 예를 들어 {10,30,50,50,50,70} 점수 리스트에서 50점을 찾는다고 했을때 binarySearch() 함수는 3번째 요소의 인덱스를 반환하는 것이 아닌, 다른 50점의 인덱스를 반환한다. 그래서 50점을 통과하는 지원자의 수를 정확하게 알아낼 수 없다.
이와 같은 이유로 이진 탐색함수도 직접 구현해 주어야 했다.
어려웠고 푸는데 시간도 많이 소비했지만, 그만큼 얻을 것이 많은 문제라고 생각한다.
출처 : 프로그래머스 코딩 테스트 연습 https://school.programmers.co.kr/learn/challenges
