Algorithm
1.두 개 뽑아서 더하기 (월간 코드 챌린지 시즌1)
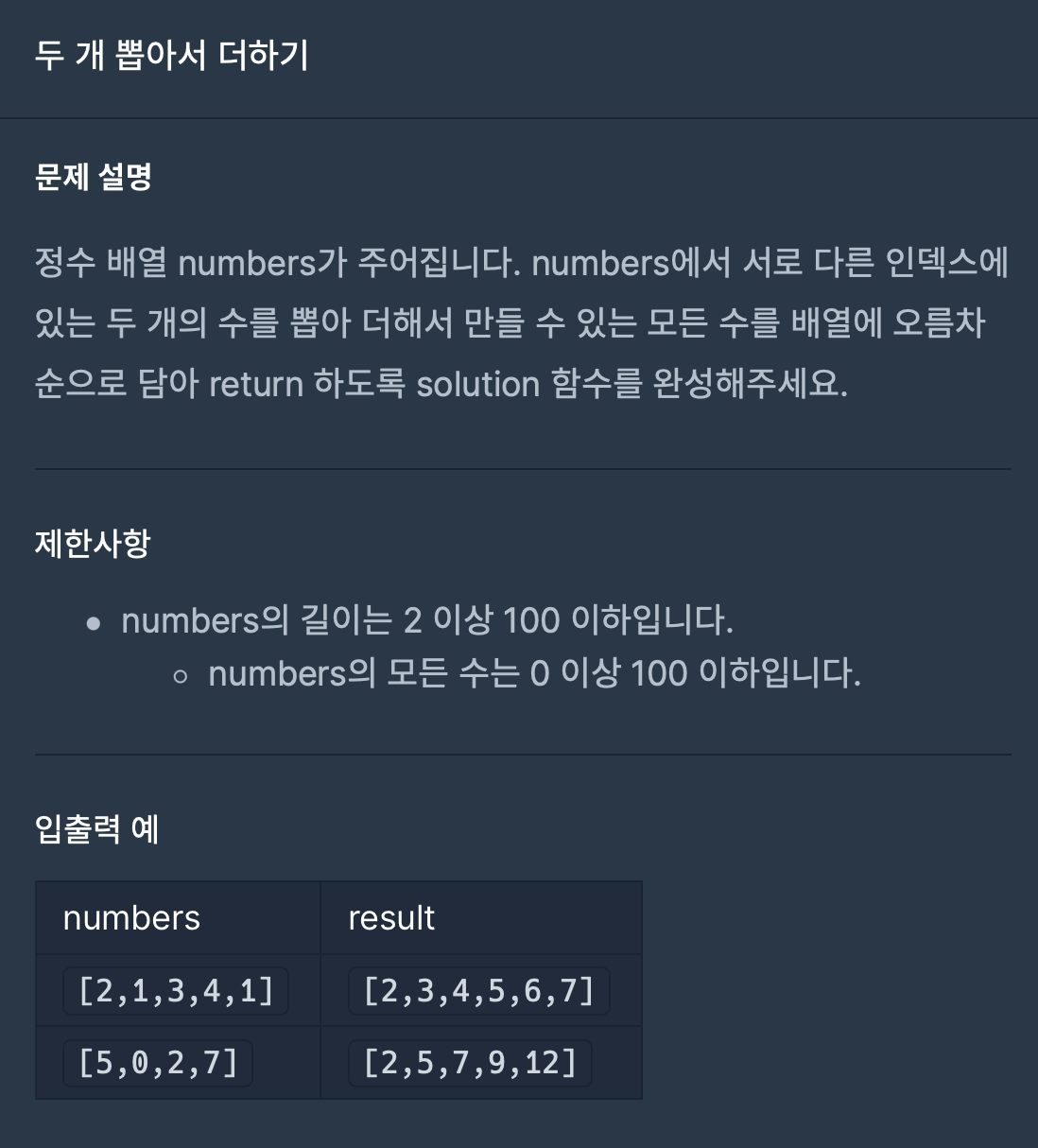
문제 자체는 크게 어렵지 않았다.어떻게 시간복잡도를 줄일지가 관건이었다.출력 결과에는 정렬이 되어있어야 하고, 중복을 포함하면 안된다.이 두가지를 모두 성립시키면서 시간복잡도를 줄일 수 있는 방법을 생각하고자 하였다.numbers의 모든 수는 0이상 100이하 라는 조
2.3진법 뒤집기(월간 코드 챌린지 시즌1)
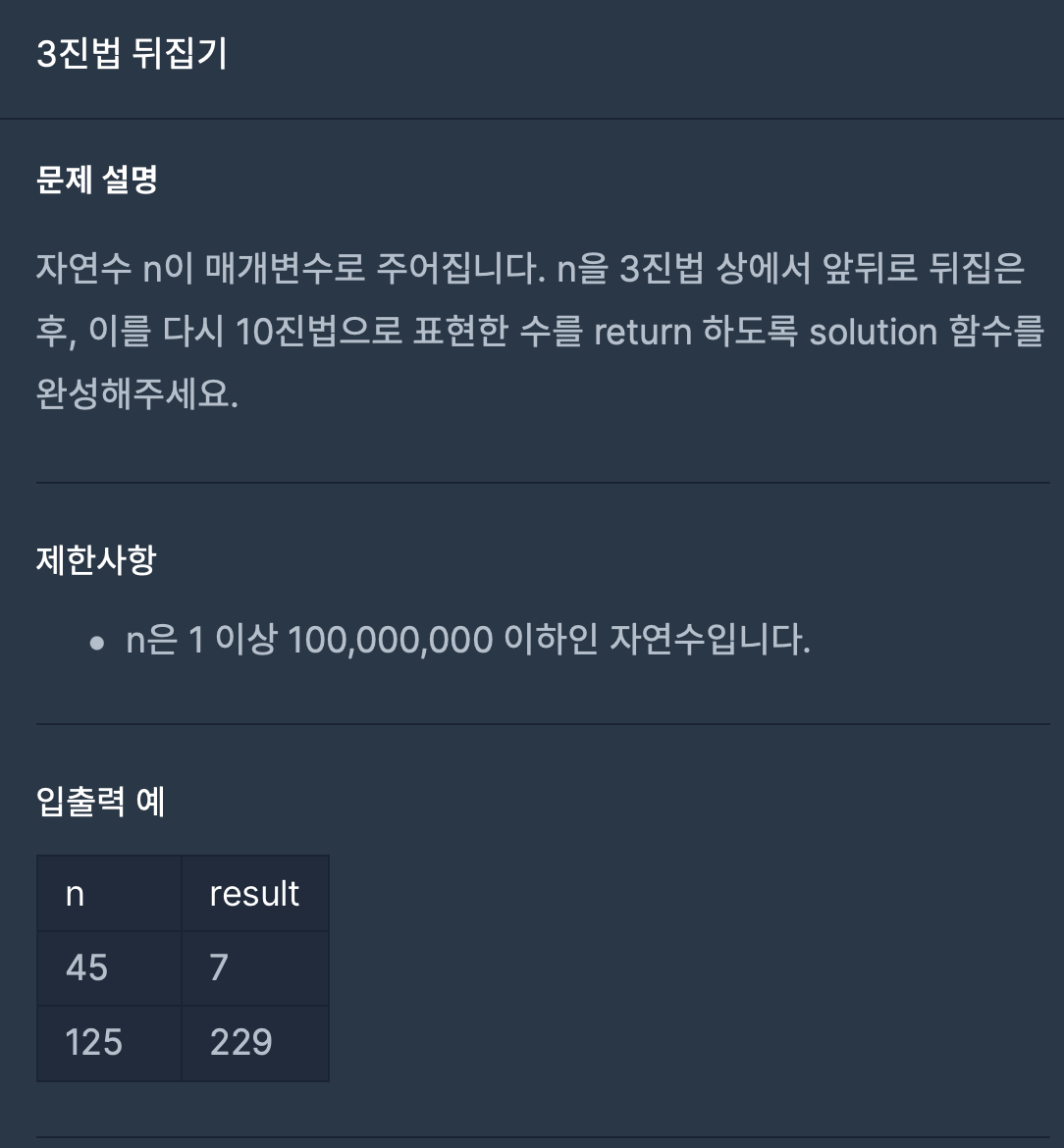
10진수를 읽어와 3진수로 변환하고, 변환한 것을 뒤집어서 다시 십진수로 읽어오는 문제이다. StringBuilder 와 Integer.parseInt() 메서드를 이용하면 쉽게 해결할 수 있지만, 만약 사용법을 모르고 있는 상태에서 시험 문제로 나왔다 생각하면 살짝
3.신규 아이디 추천(2021 KAKAO BLIND RECRUITMENT)

처음엔 별거 아닌 것 처럼 보였지만 조금 복잡하고 오래걸렸던 문제이다. 나는 아이디 판독을 할 때 아스키 코드를 사용하였고, StrinBuiler을 통해 문자열을 다루었다. 어찌어찌 답은 맞췄지만, 다른 사람들의 풀이를 보니, 정규식을 사용하면 정말 간단하게 풀 수 있
4.로또의 최고 순위와 최저 순위(2021 Dev-Matching: 웹 백엔드 개발자(상반기))

큰 어려움 없이 해결할 수 있었다. 이 문제의 핵심은 로또를 하나도 맞추지 못했을 때의 경우이다. 1~6개의 정답을 맞추었을 때 등수는 차례대로 6~1등이 부여가 되는데, 0개의 정답을 맞추었을때도 6등이 부여가 되어야 하기 때문에 따로 다뤄주어야 한다. 내가 알고 있
5.숫자 문자열과 영단어(2021 카카오 채용연계형 인턴십)

문제를 해결하는 것은 어려운 일이 아니었다. 다만 어떻게 시간복잡도를 줄일 수 있을지가 관건이었다.내 머리로는 그냥 String클래스의 replace() 메서드를 사용하는 것이 최선이라고 생각했다. 정답을 무난하게 맞춘 후 베스트 풀이를 보았더니 replaceAll()
6.신고 결과 받기(2022 KAKAO BLIND RECRUITMENT)
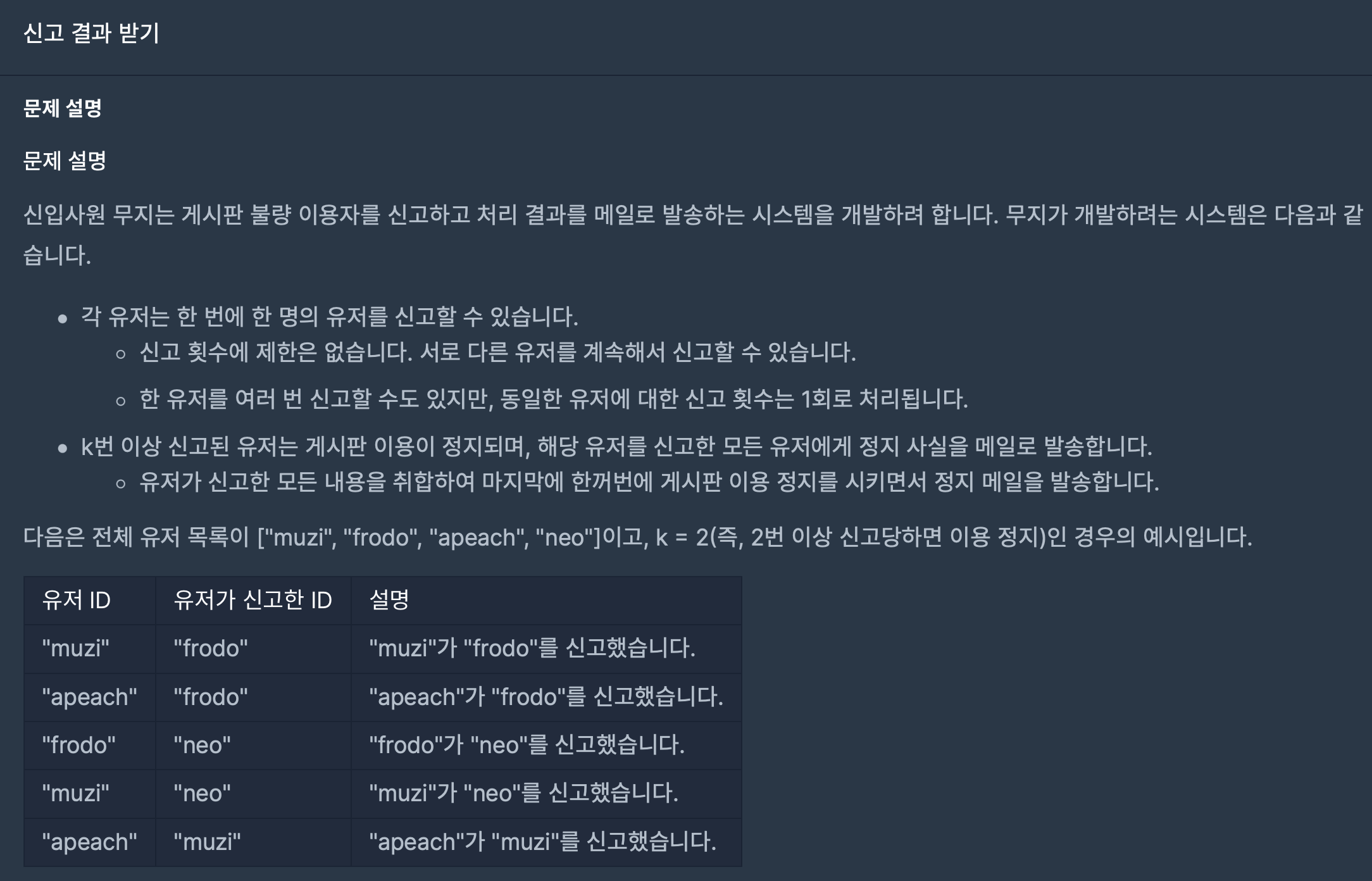
살짝 머리아픈 문제였다. 이 문제는 노트에 먼저 정리를 해놓고 코딩을 시작했다. 처음에는 HashMap을 사용해서 유저마다 신고당한 횟수를 저장하는 방법을 생각했다. (1) HashMap에 유저당 신고 횟수를 저장한다.(2) 유저 중 신고 당한 횟수가 k가 넘는 아이디
7.성격 유형 검사하기(2022 KAKAO TECH INTERNSHIP)

문제 코드 풀이 카카오 문제가 항상 신박해서 재미있는 것 같다. 이 문제는 어렵지 않게 해결할 수 있었다. 내가 생각한 방법은
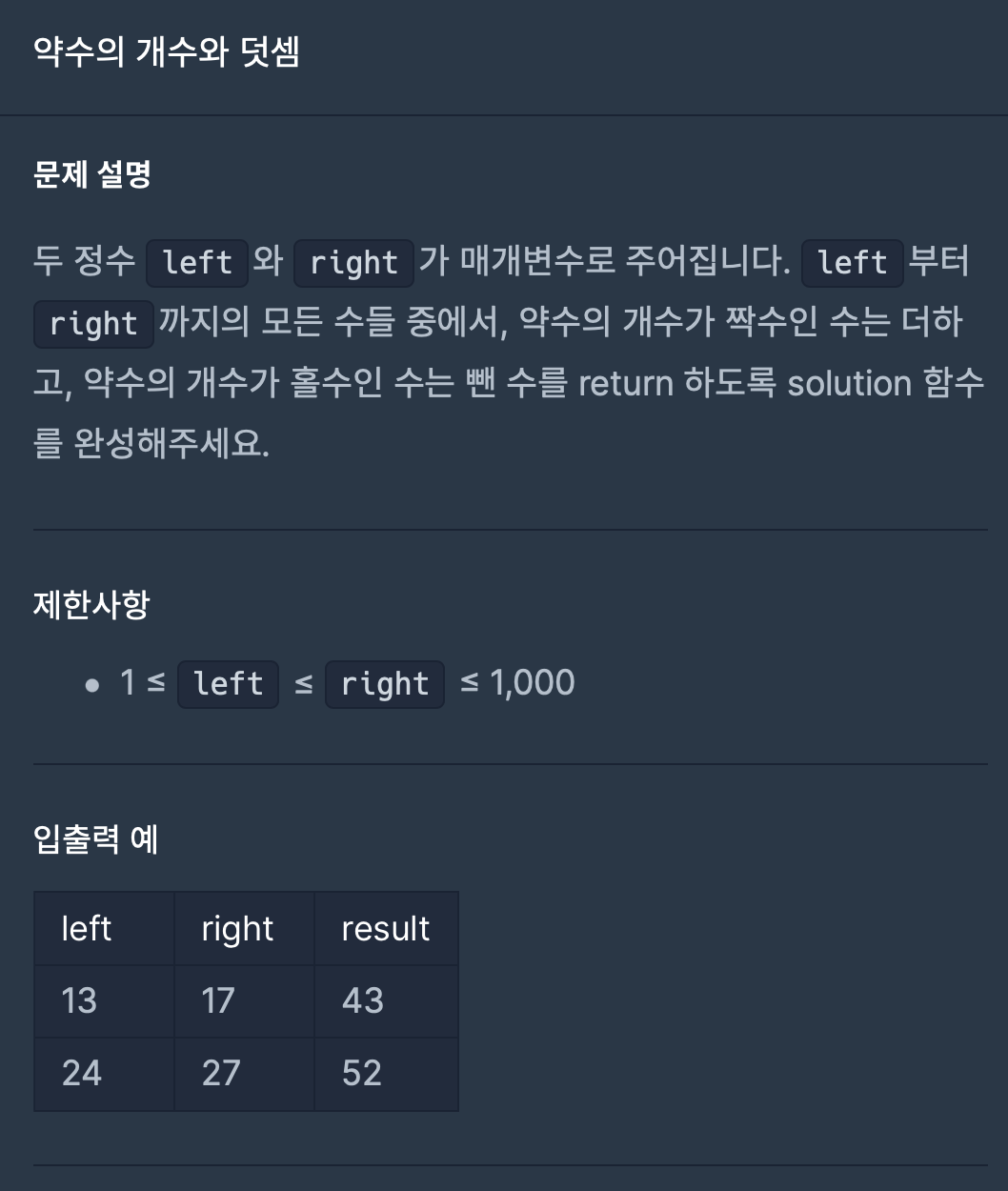
처음에는 약수의 개수를 하나하나 구해야 하나 생각했는데, 좋은 방법이 떠올라서 간단하게 해결할 수 있었다.사실 약수가 홀수가 되는 경우는, 주어진 수가 거듭제곱 인 경우밖에 없었다. 거듭제곱인 수를 판별하는 방법은, Math.sqrt 함수를 사용한 결과가 정수인지 확인
9.숫자 짝꿍(프로그래머스 연습문제)

생각보다 애를 좀 먹었다. 이 풀이는 처음 접근했던 방법과 완전히 다른 방법이다. 처음에는 이런 과정으로 문제를 풀었다.(1) X,Y 문자열을 하나하나 비교해가면서 겹치는 숫자를 Integer형 ArrayList에 차대로 담는다.(2) ArrayList를 Arrays.
10.개인정보 수집 유효기간(2023 KAKAO BLIND RECRUITMENT)
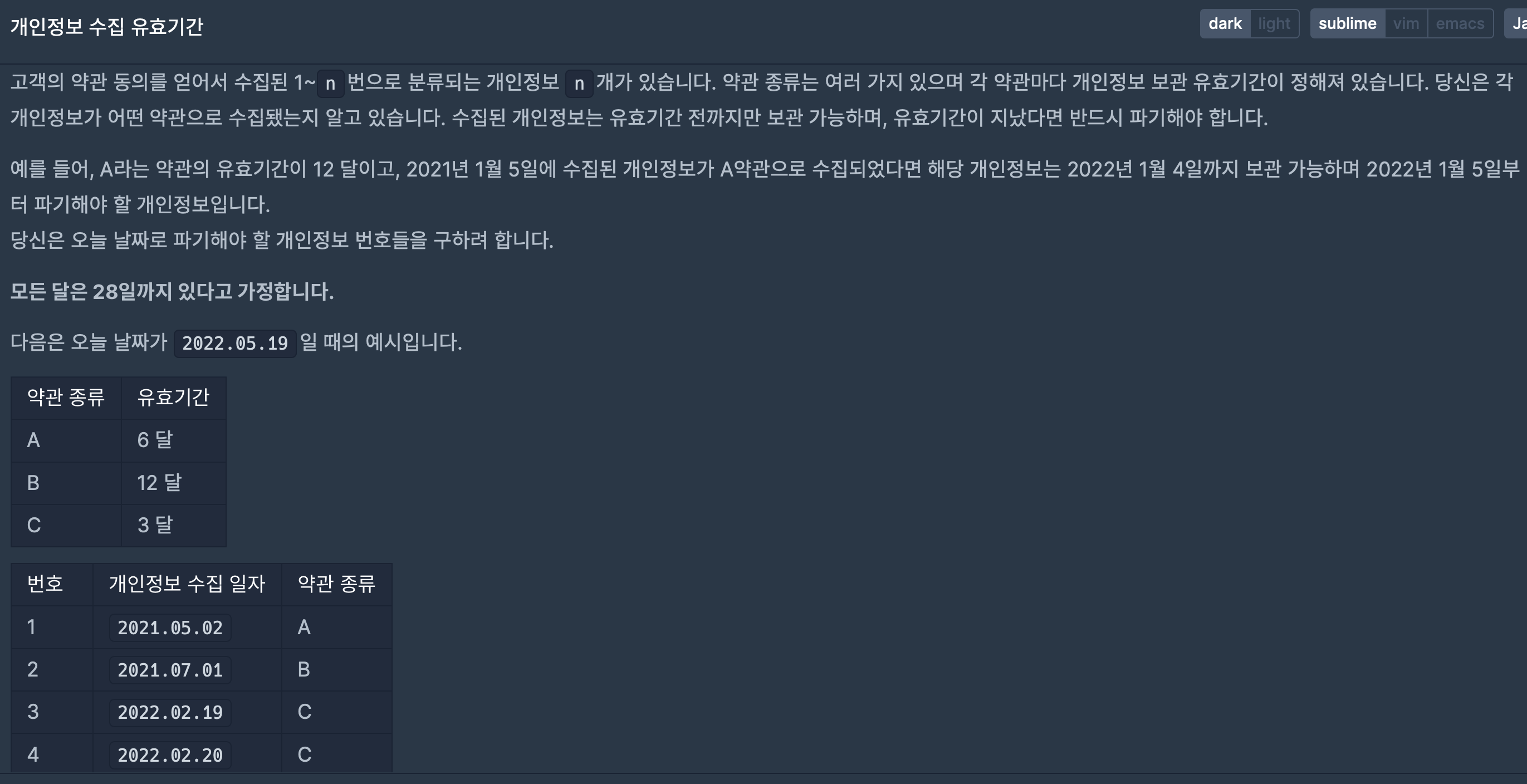
사실 조금 귀찮기는 하지만 크게 복잡한 문제는 아니었다.날짜가 지나가는 것을 관리해야 하다 보니 12월이 넘어가는 것과 28일을 넘어 가는 부분을 잘 처리해 주는 것이 중요했다.이번 문제에서는 최대한 가독성이 좋은 코드를 만들기 위해 객체지향적으로 작성하려 노력했다.(
11.순위 검색(2021 KAKAO BLIND RECRUITMENT)
문제 코드 풀이 요구사항마다 각각 한명씩 요구사항을 충족하는지 검사하면 정확성 테스트는 통과하지만, 효율성 테스트에서 탈락하기 때문에 더 효율적인 방법을 사용해야 한다. 풀이 과정은 아래와 같다. (1) info 배열 안에 있는 지원자들의 정보를 하나씩 순회하면서
12.거리두기 확인하기(2021 카카오 채용연계형 인턴십)
(1) 방에 있는 자리 하나씩 돌면서 'P'가 나오면 dfs() 메소드를 실행하여 거리두기 검사를 한다.(2) dfs() 함수에서는 다음을 실행한다.1.검사한 자리를 visited(방문을 검사하는 이차원 배열)배열에 true로 표시한다.2.dfs에 들어온 자리의 상하좌
13.전력망을 둘로 나누기(프로그래머스-완전탐색)
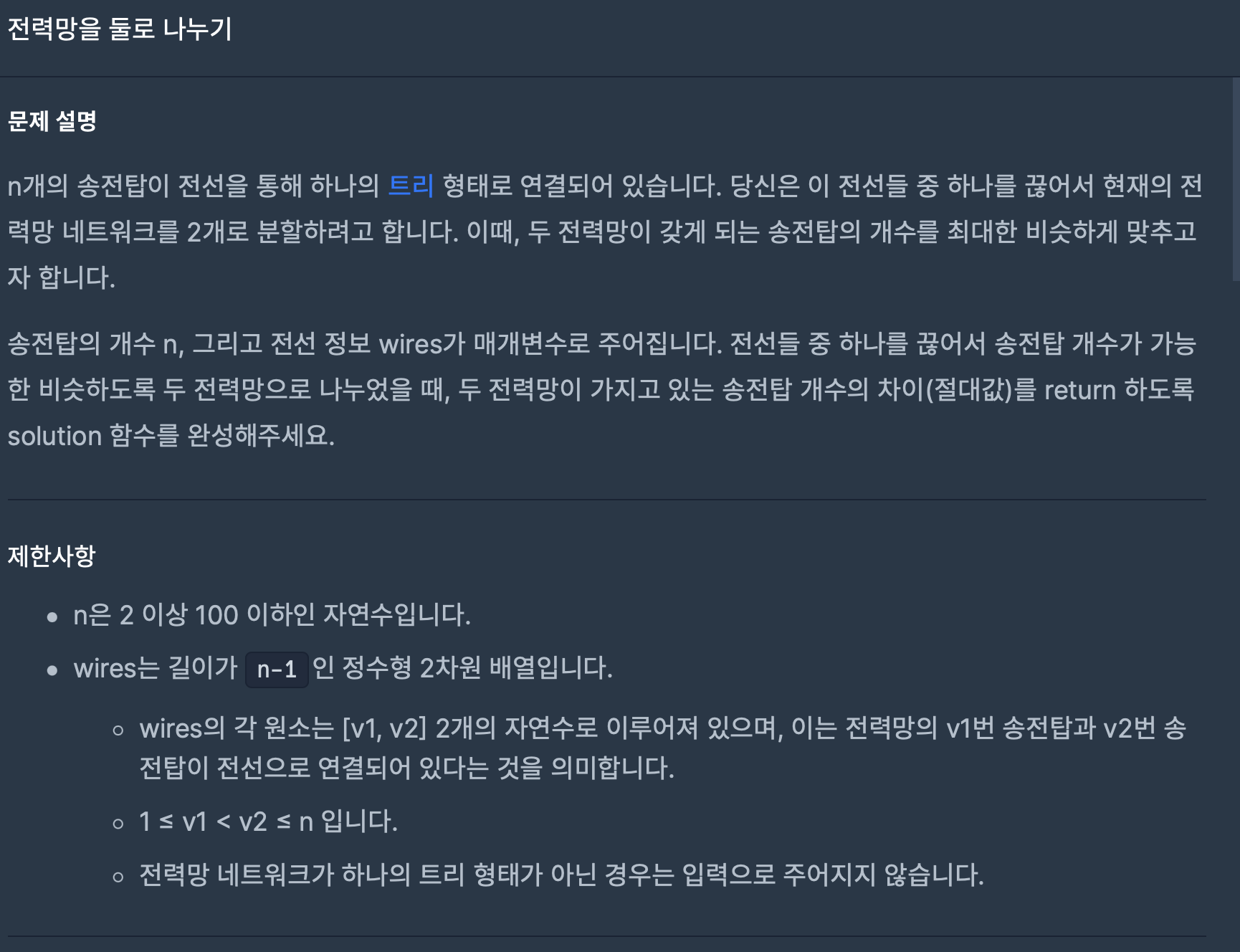
간선을 하나씩 다 끊어서 노드가 몇새씩 나뉘는지 계산하는 방법으로 해결했다.(1) 간선을 하나씩 끊고, 끊어진 간선 중 하나의 노드를 dfs 탐색한다.\-> 방문한 노드를 ArrayList(visited)에 추가하고, 다시 그 노드를 기준으로 탐색하는 과정을 반복한다.
14.교점에 별 만들기(위클리 챌린지 )
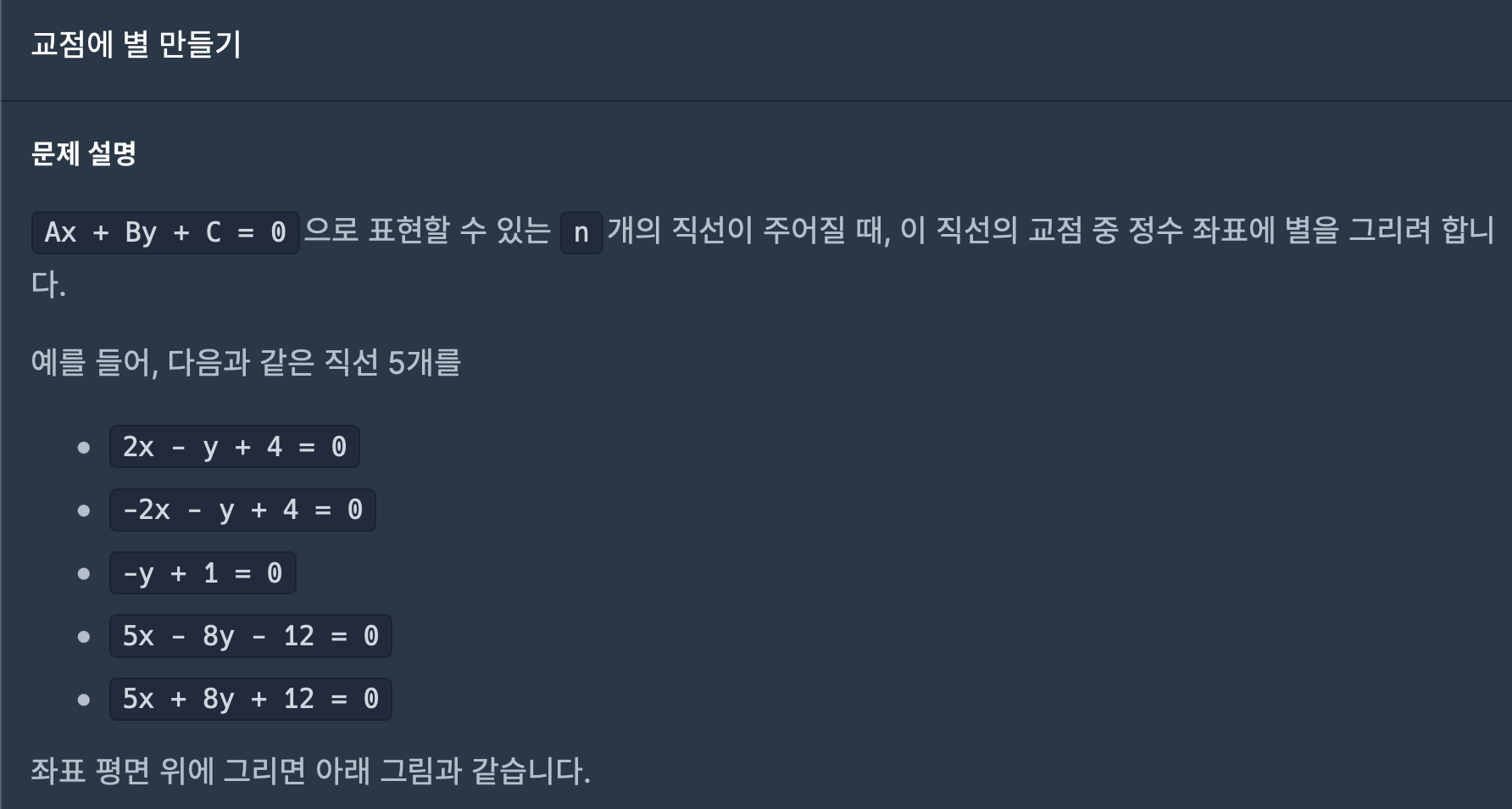
(1) 교점의 좌표를 저장할 Coordinate 클래스를 만들어 준다. 생성자와 멤버변수 x,y를 갖는다.(2) 문제에서 주어진 식을 이용해, 모든 식 간의 교점을 구해준다.(3) 그 교점이 정수인지 판단 후 x,y 좌표가 둘다 정수라면, Coordinate형 Arra
15.피로도(프로그래머스-완전탐색)

(1) 처음에 시작할 던전을 차례대로 정해서 dfs() 메소드를 실행한다.(2) dfs()에서는 방문할 던전에 입장할 수 있는지 확인하고, 던전에 입장이 가능하다면 count(입장한 던전 수)를 +1 해준다. 또한 hp(피로도)를 깎고, visited 리스트에도 입장한
16.k진수에서 소수 개수 구하기(2022 KAKAO BLIND RECRUITMENT)
문제 코드 풀이 (1) 주어진 n을 k진수로 만들어준다.(StringBuilder 이용) (2) k진수로 만든 StringBuilder을 한자리씩 확인하여 준다. -> 0이 아닌 숫자가 나오면 makeString() 메소드를 통해 판별할 숫자를 받아온다. -> 0이
17.주차 요금 계산(2022 KAKAO BLIND RECRUITMENT)
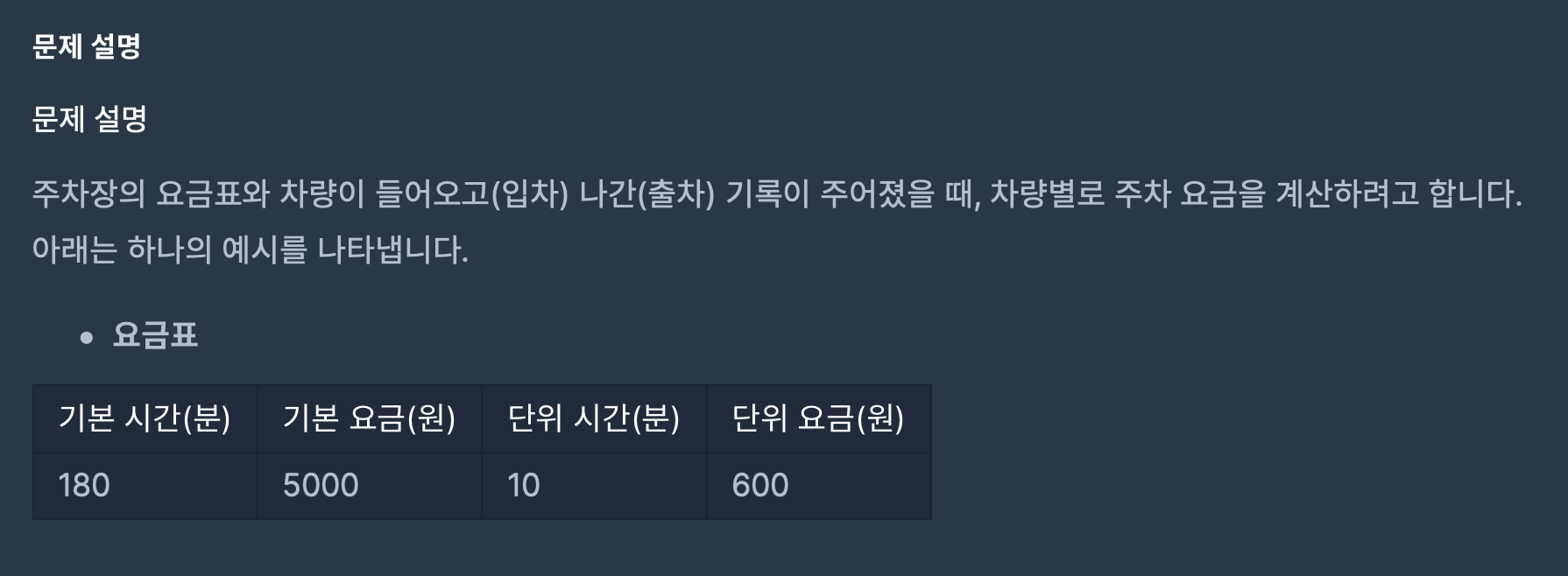
(1) records를 순회하며 "IN"이 들어온 경우에는 parking(HashMap)에 넣어주고, "OUT"이 들어온 경우에는 calcTime() 메소드를 호출하여 주차 시간을 계산한 뒤 result(HashMap)에 넣어준다.\-> 이 때, 두 번 이상 입,출차
18.양궁대회(2022 KAKAO BLIND RECRUITMENT)

(1) 전체적인 흐름은 dfs를 통해 라이언이 얻을 수 있는 모든 점수를 탐색한 후 한번 탐색이 끝날때마다 어피치와 라이언 의 결과를 채점 후, 점수차를 구해 결과를 새로 갱신한다.(2) 점수차이가 기존에 갱신되어있던 점수차이보다 크면 새로 갱신하고, 같으면 문제에서
19.두 큐 합 같게 만들기(2022 KAKAO TECH INTERNSHIP)
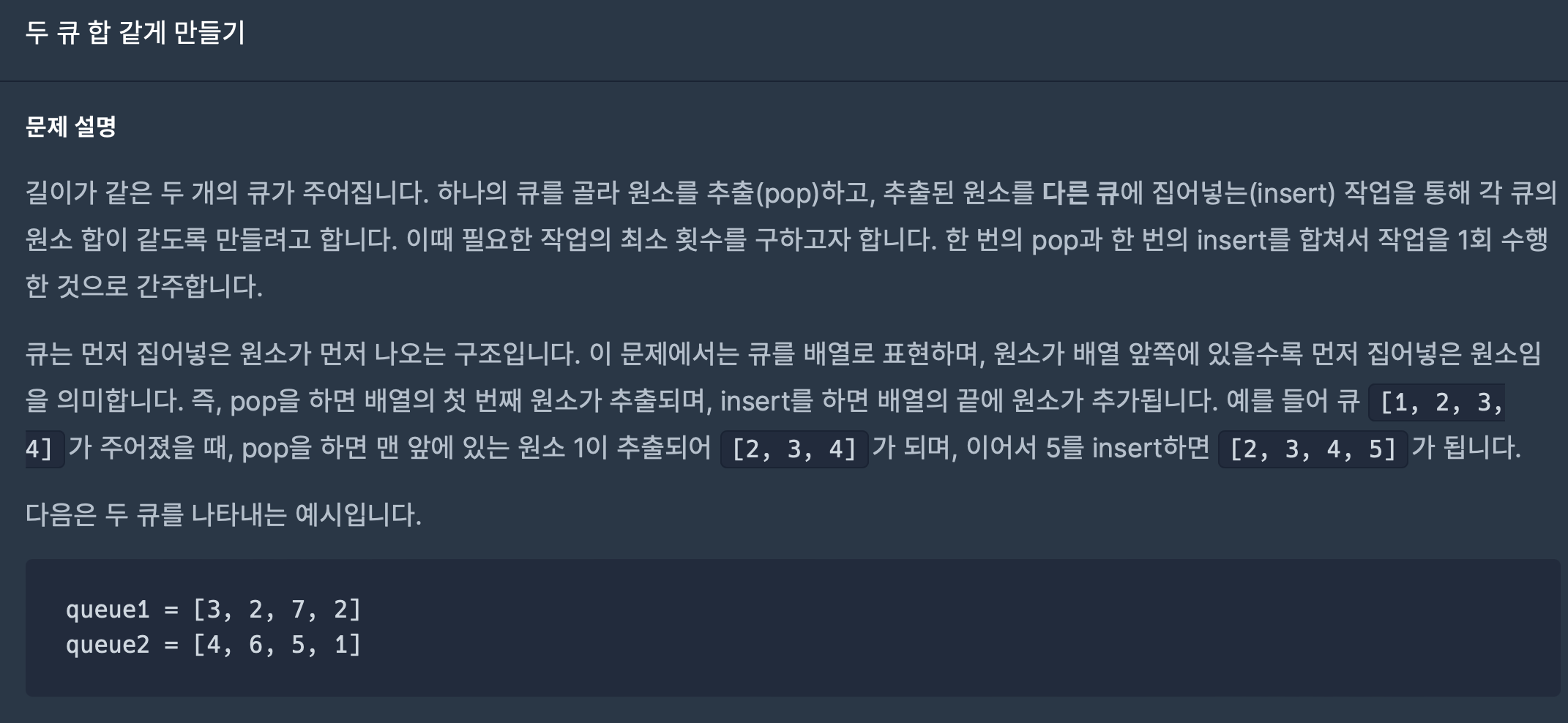
(1) 입력으로 들어온 배열을 큐(LinkedList)로 만들어준다.(queueA,queueB)(2) (queueA 원소들의 합 + queueB 원소들의 합)/2를 계산하여 half(각 큐의 원소의 합이 이 값이 되어야 함)변수를 선언해준다.(3) 두 큐에서 poll(
20.혼자 놀기의 달인(프로그래머스-연습문제)

(1) 방문한 상자를 체크할 visited 배열, 한 번 상자를 선택하여 빈 상자가 나올때까지의 상자 개수를 저장할 result(ArrayList)를 생성하여 dfs()함수에 보내준다.(사실 dfs문제는 아니지만, 내가 처음에 그렇게 풀어서 이름이 dfs로 되어있다.)
21.디펜스 게임(프로그래머스-연습문제)

(1) 일단 라운드를 진행하고, 적의 수만큼 n을 뺀다.(2) 만약 n<0 이고, k>0이면 지금까지 진행했던 라운드 중 가장 적의 수가 많았던 라운드의 적의 수 만큼 n에 더해주고, k에서 1을 뺀다.(3) 위처럼 진행 후에, n>=0이면 answer에 1을 더
22.유사 칸토어 비트열(프로그래머스-연습문제)
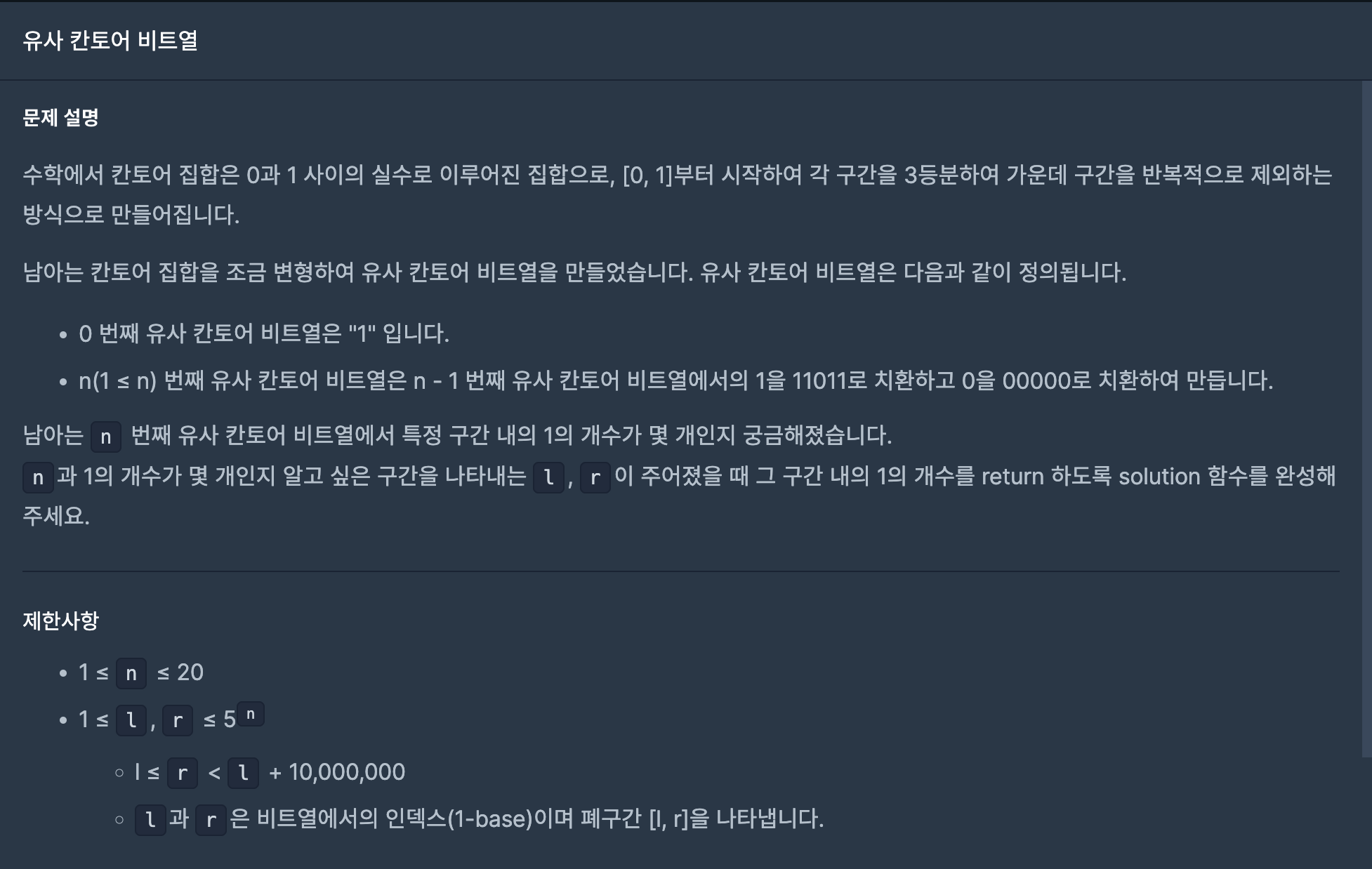
이 유사 칸토어 비트열의 전체적인 구조에 대해 파악해야 한다.글로 설명하기가 좀 힘든 내용이다. "ㅁ"이 하나의 "11011" 또는 "00000"이라고 하자.먼저, n이 1일때는 "11011" 이다.n이 2일때는 "ㅁㅁㅁㅁㅁ"이다.n이 3일때는 "ㅁㅁㅁㅁㅁ ㅁㅁㅁㅁㅁ
23.숫자 변환하기(프로그래머스-연습문제)
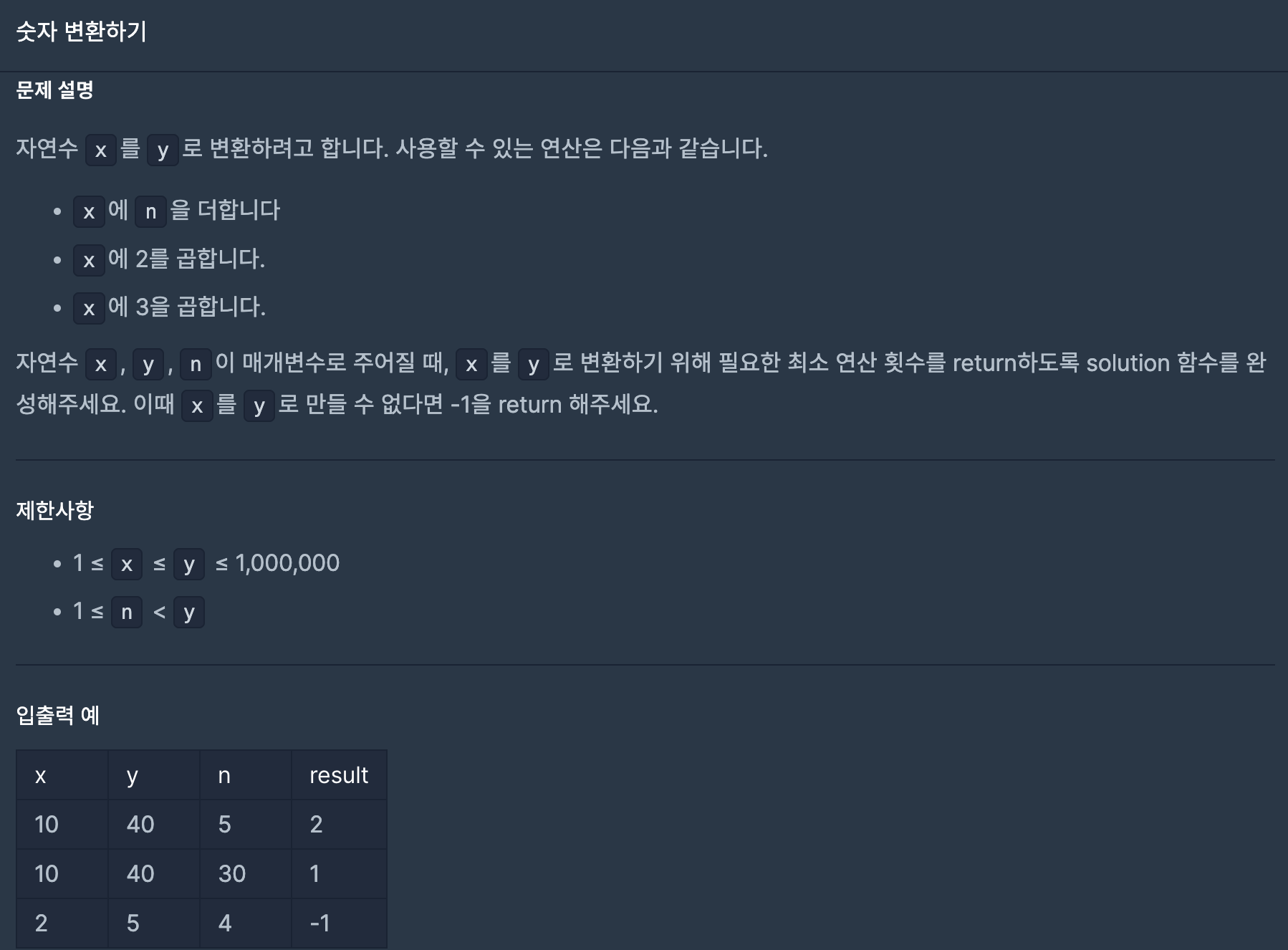
(1) y+1 크기의 배열을 만든다. ex) dp40에는 40을 만들 수 있는 최소 횟수가 들어간다.(2) x+1부터 y번째 인덱스까지 반복해서 dp과정을 반복한다.dpi에는 dpi-n,dpi/2,dpi/3중 가장 작은 값+1 이 들어간다. 만약 dpi-n,dpi/2,
24.이모티콘 할인행사(2023 KAKAO BLIND RECRUITMENT)

(1) 각 이모티콘의 할인율을 결정할 수 있는 모든 경우의 수를 담는 함수(makeSales())를 실행한다.ex) 이모티콘 3개의 할인율이 각각 40%,30%,20% 일때 40,30,20 배열을 ArrayList에 저장한다. 이와 같은 방식으로 모든 경우의 수를 sa
25.택배 배달과 수거하기(2023 KAKAO BLIND RECRUITMENT)

(1) 기본적인 공식은 가장 먼곳에 있는곳의 배달과 수거를 먼저 완료해야 한다는 것이다.(Greedy)(2) 가장 먼 집부터 배달해야하거나 수거해야할 상자가 있는지 확인한다. 있다면, 가장 먼 곳부터, 배달할 수 있는(cap만큼) 모든 택배를 deliveries 배열에
26.뒤에 있는 큰 수 찾기(프로그래머스-연습문제)
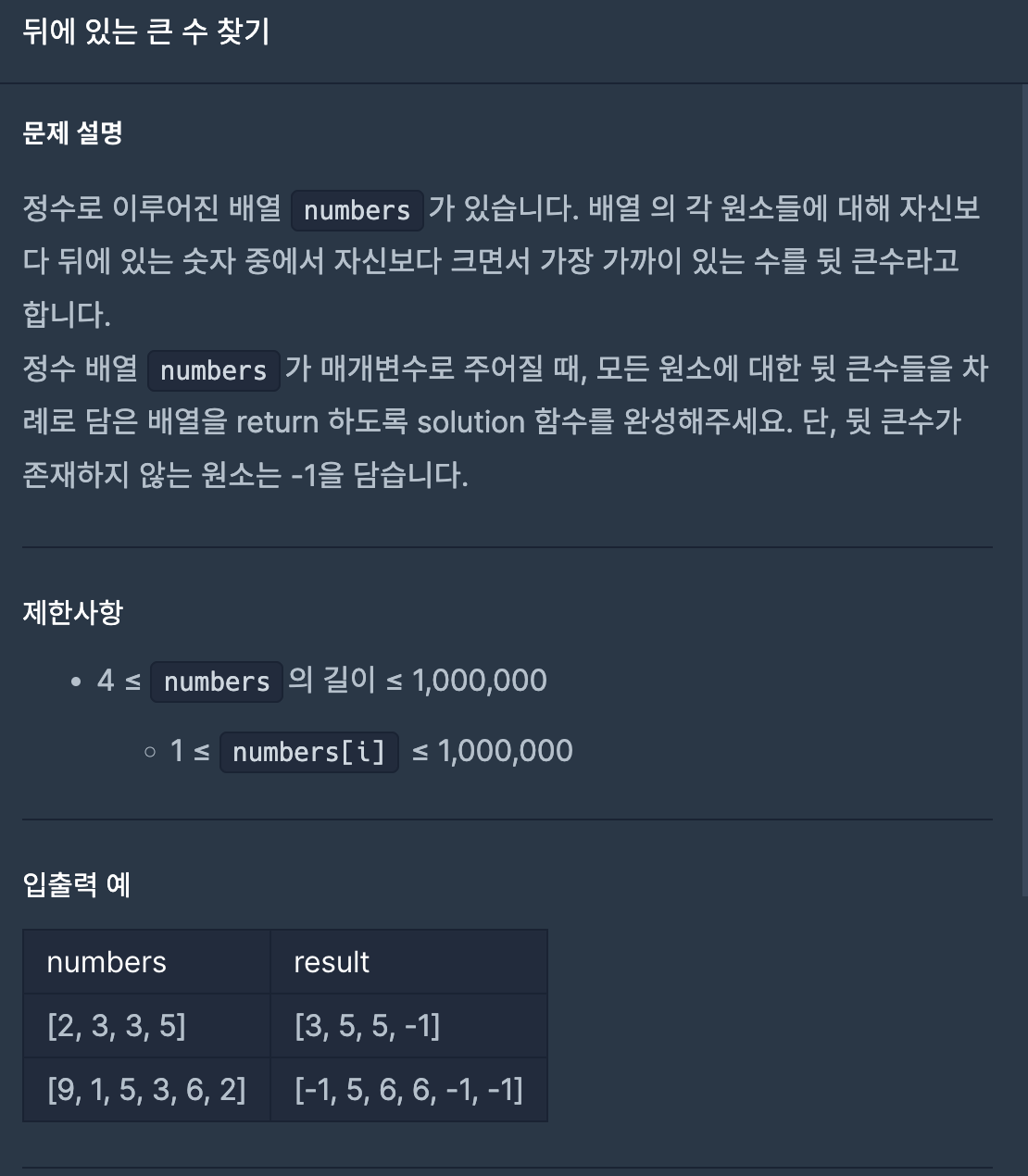
(1) 아직 다음 큰 수를 찾지 못한 인덱스를 모아둘 index(Stack) 를 만들어주고, numbers 배열을 앞부분부터 하나씩 순회한다.(2) 스택이 비어있거나, numbersindex.peek()가 numbersi 보다 크면, 다음 큰 수를 찾지 못한 것이므로
27.호텔 대실(프로그래머스-연습문제)
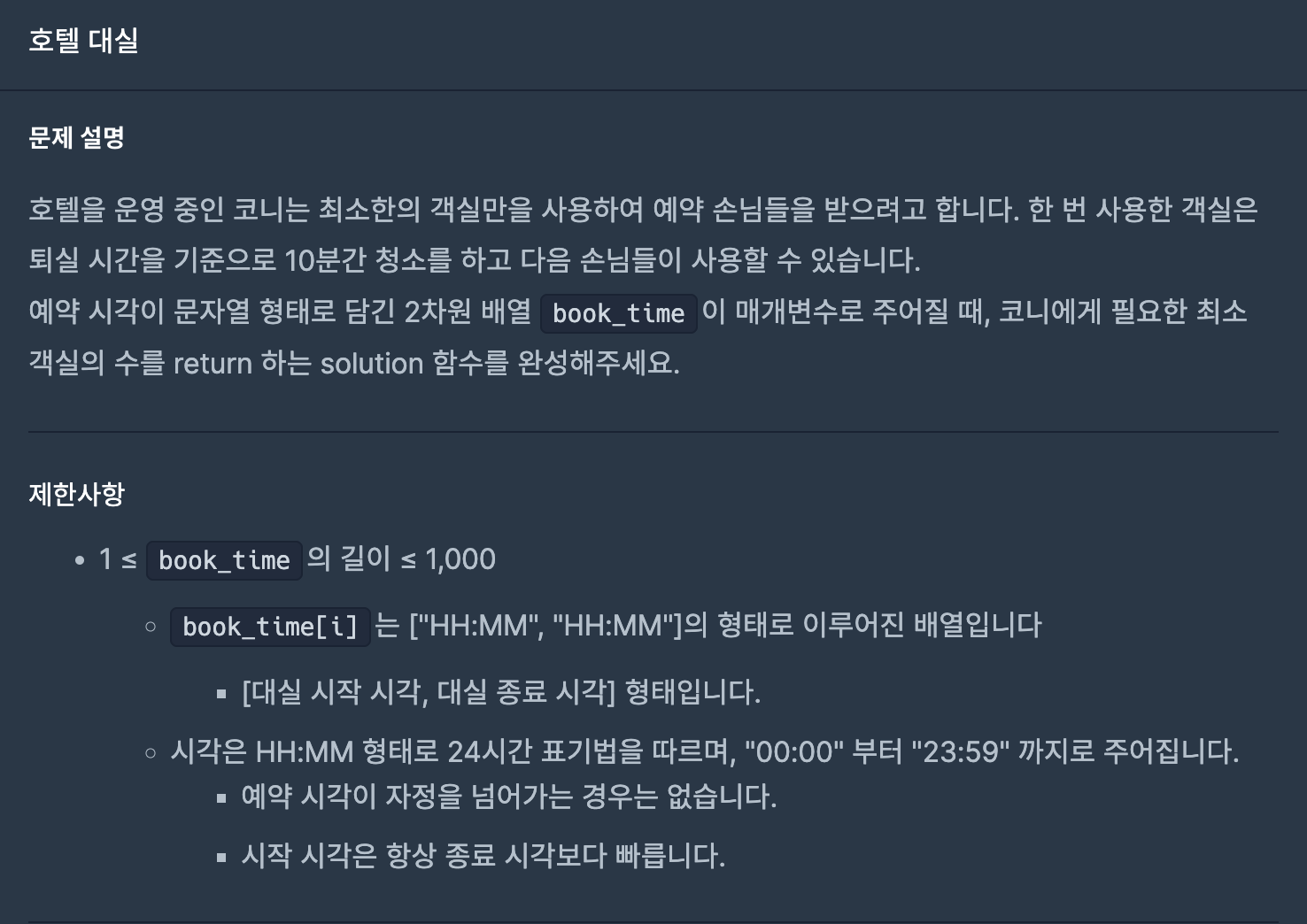
(1) 방 하나에 들어갈 예약들을 찾을 반복문을 실행한다. 그 방에 더이상 들어갈 수 있는 예약이 없으면 다음 방에서 다시 시작한다.(2) findBook()함수는 다음 예약을 찾는 함수이다. 다음 예약을 찾는 방법은 아래와 같다.아직 방이 할당되지 않은 예약이어야 하
28.미로 탈출(프로그래머스-연습문제)

(1) 시작점을 찾기 위해 maps를 순회한다. 'S'를 찾으면 레버를 찾기위한 bfs 탐색을 시작한다.(2) bfs() 함수에서는 bfs 알고리즘 방식으로 방문 노드를 큐에 넣고, visited 배열에 체크를 해주는 과정을 더 이상 큐에서 빼낼 노드가 없을 떄까지 반
29.조이스틱(프로그래머스-탐욕법(Greedy))
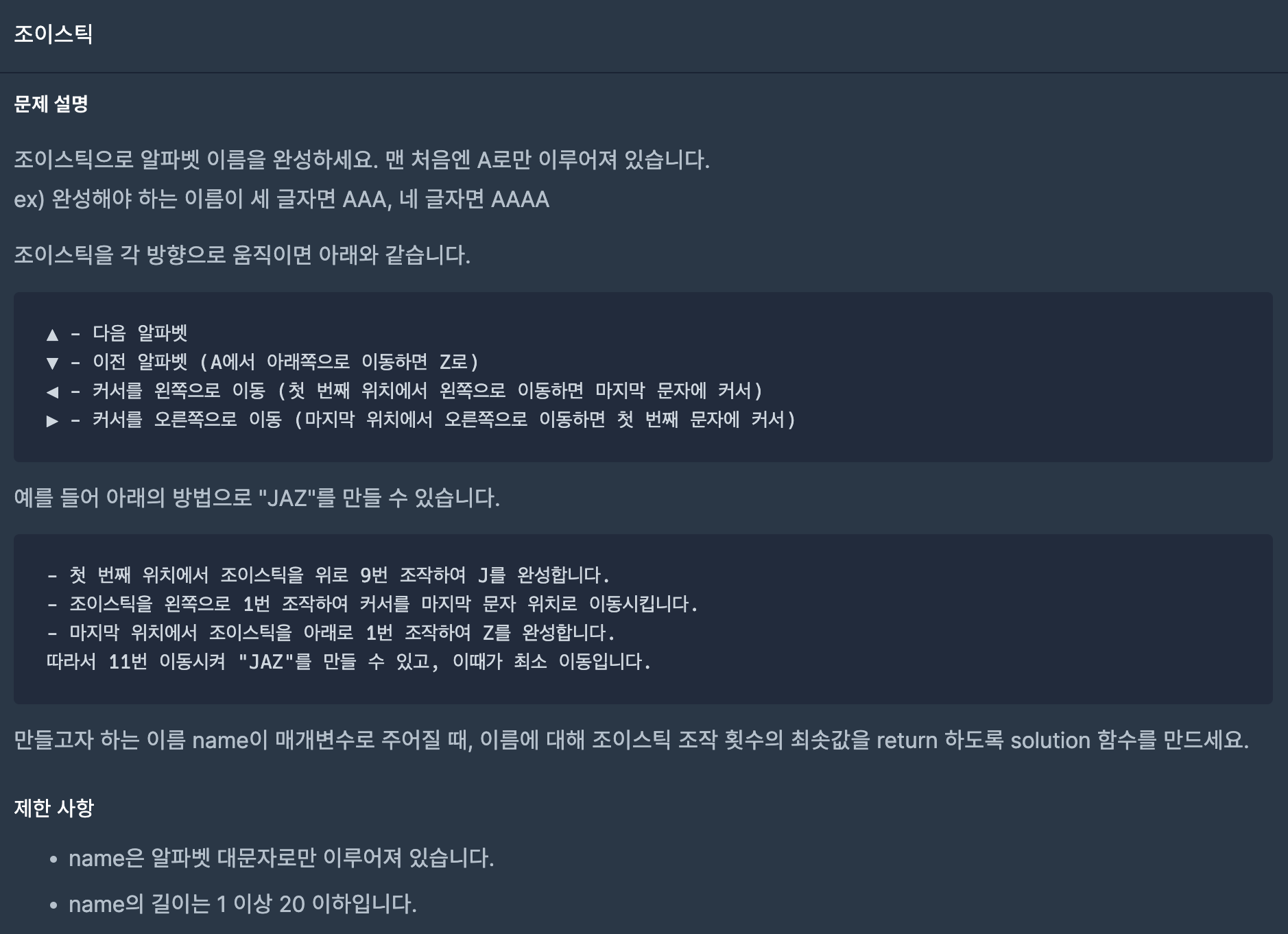
이 문제를 해결하기 위해서는 두가지를 최소화 해야 한다.1\. 조이스틱 위 아래(알파벳을 바꿀 때) 움직임 최소화2\. 조이스틱 좌 우(커서 교체) 움직임 최소화이를 염두해 두고 다음과 같은 과정을 거친다.(1) dfs 알고리즘을 사용하여 문제를 해결한다. 이 문제의
30.N으로 표현(동적계획법(Dynamic Programming))

(1) dfs 알고리즘을 사용한다. 기본 원칙은 0부터 시작하여 N으로 만들 수 있는 모든 경우의 수를 탐색하는 것이다. 이 때, N을 사용한 횟수가 8회를 넘어가면 탐색을 종료하고, 그 전에 만들고자하는 수를 탐색했다면 그 횟수를 새로 갱신하는 것이다.(최소 횟수가
31.프린터(프로그래머스-스택/큐 )

(1) 큐를 사용하기 위해 배열의 요소들을 LinkedList를 생성하여 옮겨준다. 이 문제에서 (2) 맨 앞에 있는 문서를 poll()하고, 우선순위가 더 높은 문서가 있는지 검사한다. 우선순위가 더 높은 문서가 있다면, 맨 뒤로 보낸다.(한칸씩 땡겨졌기 때문에, l
32.다리를 지나는 트럭(프로그래머스-스택/큐)
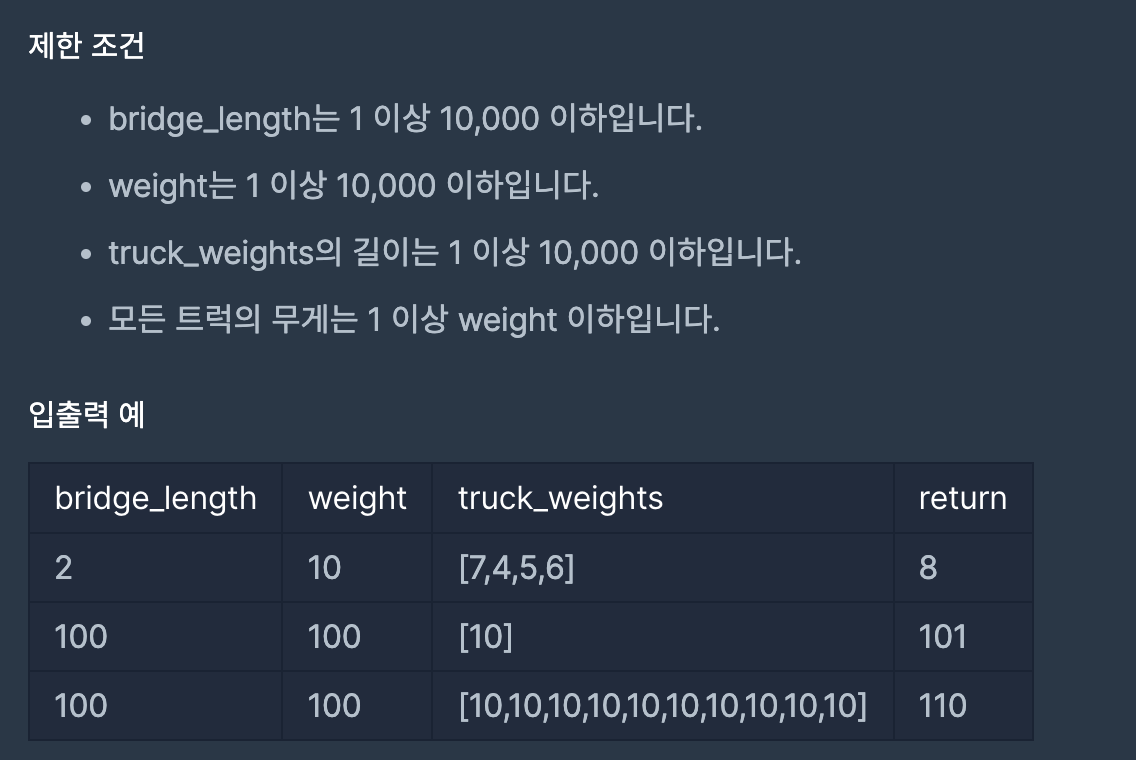
문제 코드 풀이 결과 출처 : 프로그래머스 코딩 테스트 연습 https://school.programmers.co.kr/learn/challenges
33.디스크 컨트롤러(프로그래머스-힙)
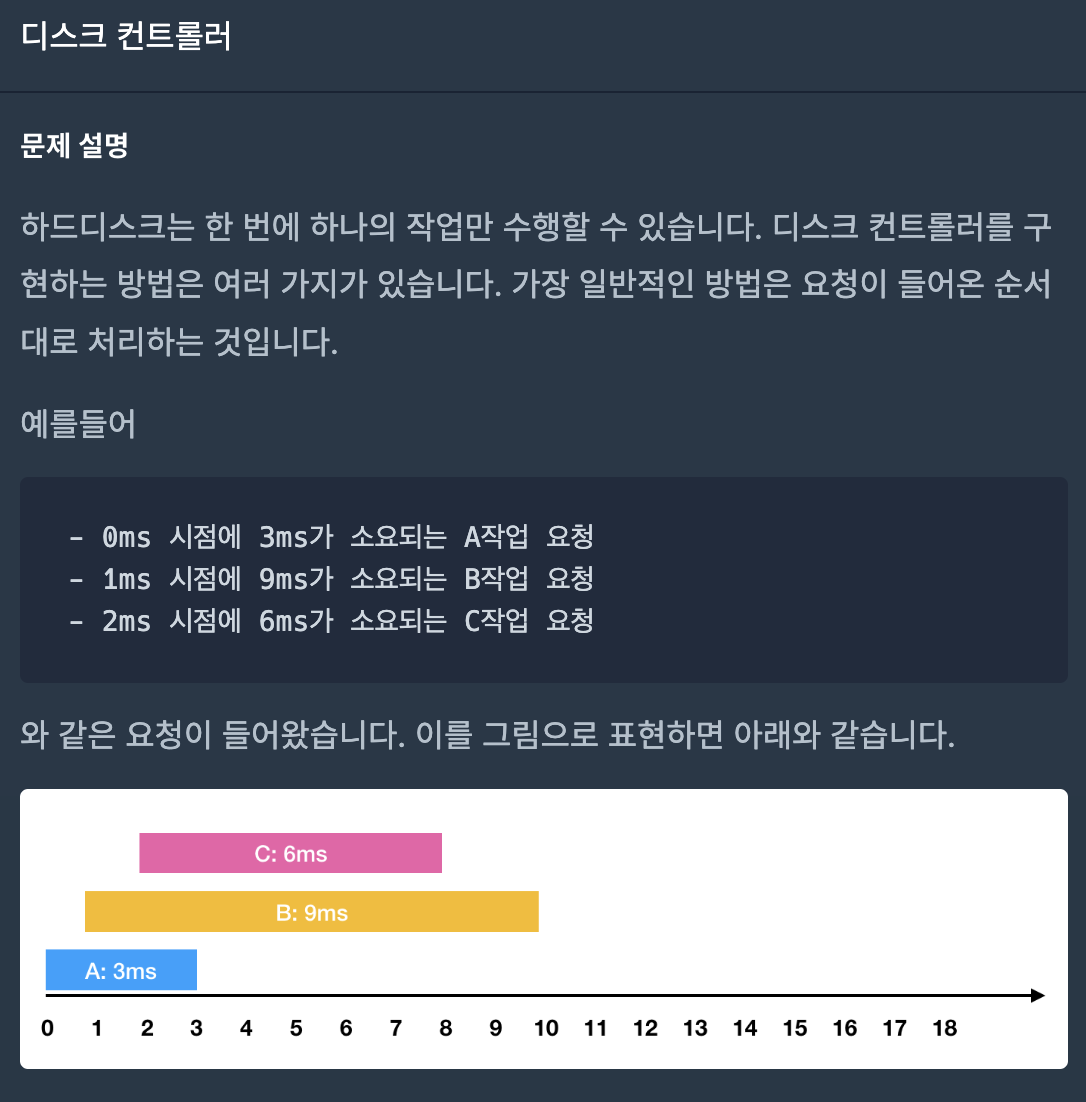
(1) 입력으로 들어온 작업들을 ArrayList형으로 만들어 준다. (완료된 작업은 제거해 주기 위해서)(2) ArrayList를 소요시간이 짧은 순대로 오름차순 정렬해준다.(3) 모든 작업이 완료될때 까지 반복문을 실행한다.지금 실행할 수 있는 작업(작업 요청시간이
34.정수 삼각형(프로그래머스-동적계획법)
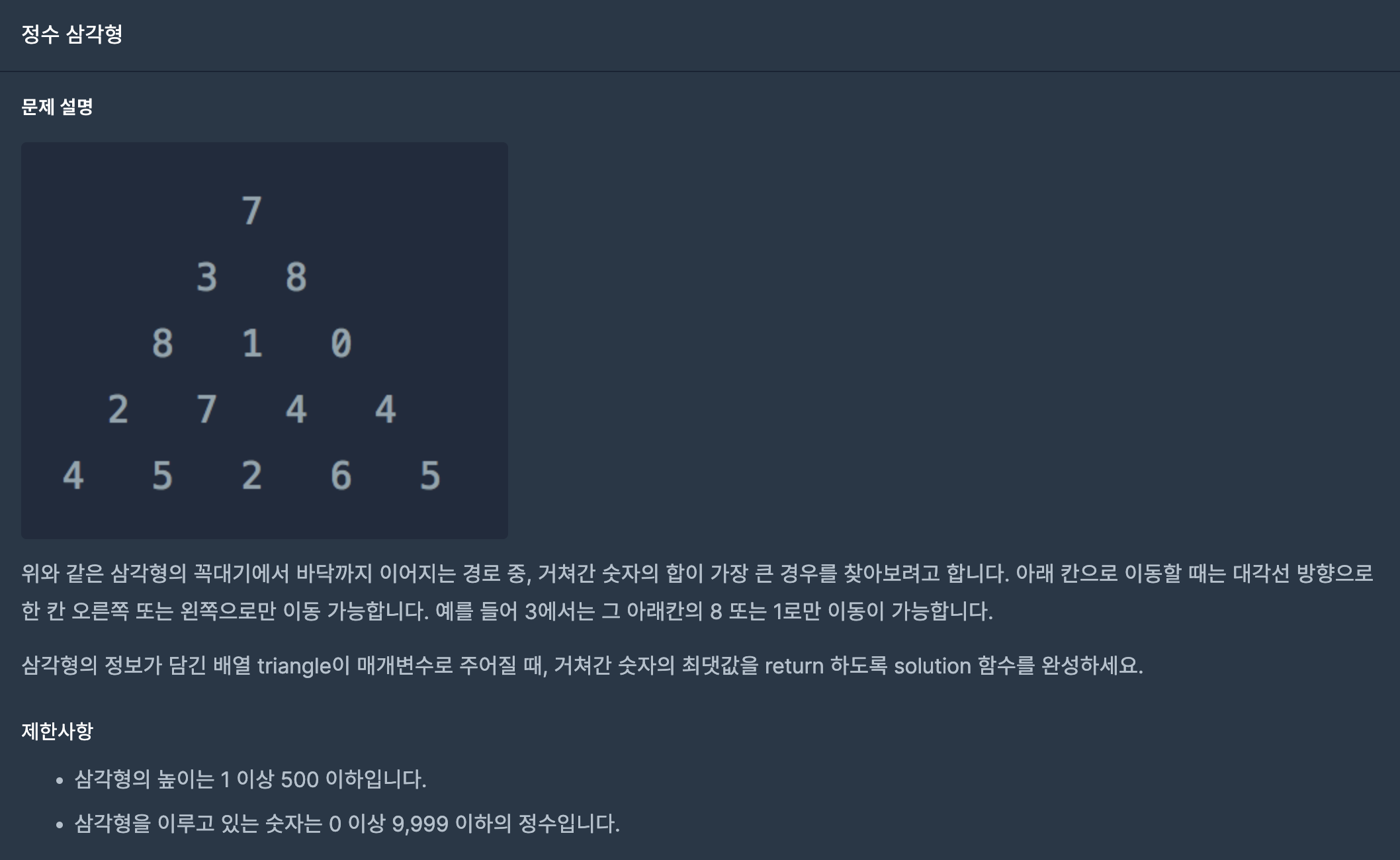
(1) triangle 배열과 같은 크기의 dp 배열을 만들어 준다. (dp 배열의 각 요소에는 누적 합의 최댓값이 들어갈 예정이다.)(2) 반복문으로 dp의 한 행씩 돌면서, 다음 행의 누적 합의 최댓값을 갱신한다.(3) 마지막 행까지 완료하면, 마지막 행의 요소들
35.단어 변환(프로그래머스-DFS/BFS)

(1) words 배열 안에 target이 존재하면, dfs() 함수를 호출한다.(2) dfs()함수에서는 다음을 실행한다.입력으로 받아온 단어가 target과 일치하면, count와 answer을 비교하여 최솟값을 갱신한다.words배열을 하나씩 돌면서 방문하지 않았
36.입국심사(프로그래머스-이분탐색)
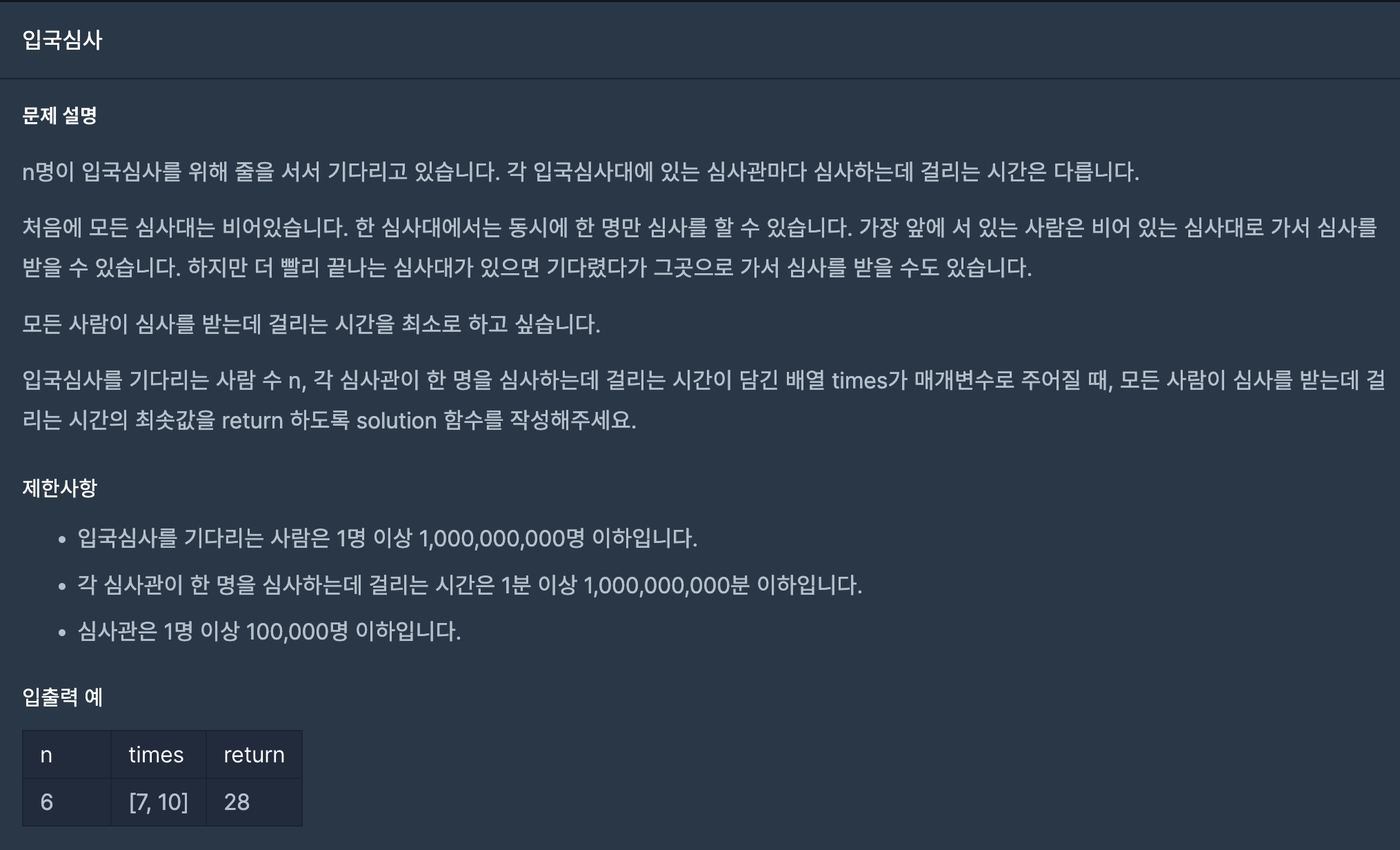
(1) 전체적인 로직은 이분 탐색을 통해 걸리는 최소 시간을 찾는 것이다. 이분탐색을 하기 위해서는 start와 end를 설정해주어야 한다. 문제 상 나올 수 있는 가장 작은 시간은 1분이다. 그리고 걸리는 시간의 최댓값은 한 심사관이 모든 사람을 심사하는 경우이다.
37.[프로그래머스] 코딩전문역량인증(PCCP) 시험 후기(230319)
시험 정보 알고리즘을 공부하면서 목표도 세우고, 코딩 테스트 경험이 한번도 없없었기 때문에 경험도 할겸 해서 프로그래머스에서 제공하는 코딩전문역량인증시험(PCCP)에 지원했다. 이 자격증으로 우대해주는 기업도 많다고 한다. 대부분의 기업에서 Lv3 정도면 우대를 해
38.리코쳇 로봇(프로그래머스-연습문제)

최단거리 문제이다. 당연히 bfs를 사용해야 한다.하지만, 제한사항에서 맵의 크기가 별로 크지 않아 나는 dfs로 해결했다.(1) 맵을 순회하면서 시작지점을 찾는다. 시작 지점을 찾으면 dfs 탐색을 시작한다.(dfs() 함수의 매개변수는 현재 위치, 이전 위치, 이동
39.베스트앨범(프로그래머스-해시)
어렵게 생각할 것이 없다. 의식의 흐름대로 구현해주면 된다.(1) 먼저, 가장 많이 재생된 순서대로 장르를 나열해야 한다.Genre 클래스를 구현하여 준다.(멤버변수로는 장르이름과 재생횟수가 있다.)Genre형 ArrayList(arr)를 생성하여 준다.배열을 돌면서
40.섬 연결하기(프로그래머스-탐욕법)
문제 코드 풀이 크루스칼 알고리즘으로 해결하였다. (1) 먼저, 간선을 새로 저장할 ArrayList(arr)을 만들고, 비용이 적은 순서대로 정렬한다. (2) 크루스칼 알고리즘을 실행한다. 크루스칼 알고리즘을 시작하기 전에 먼저, 가장 비용이 적게드는 간선 하나를
41.광물 캐기(프로그래머스-연습문제)
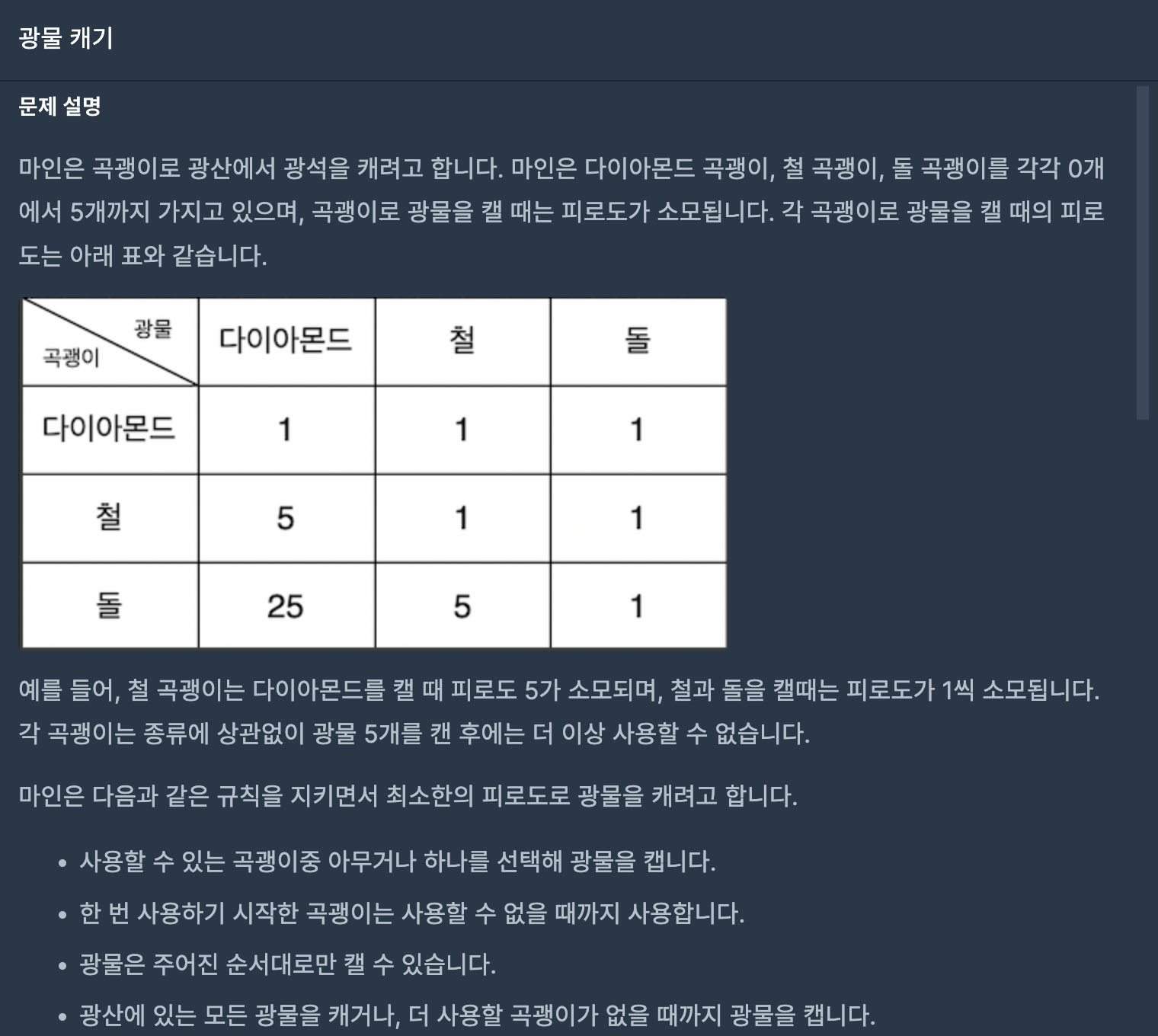
dfs 알고리즘을 통해 다음 선택할 곡괭이 종류 3가지를 모두 선택해주면서 탐색하는 풀이를 사용하였다.(1) 제일 처음 탐색할 곡괭이를 선택해서 dfs탐색을 시작해야 한다. 다이아,철,돌 곡괭이가 각각 0개가 아니면 시작 곡괭이로 하여 dfs 탐색을 보내준다. dfs
42.양과 늑대(2022 KAKAO BLIND RECRUITMENT)
문제 코드 풀이 인접 리스트를 활용한 dfs 알고리즘으로 문제를 해결해야 한다. (1) 인접리스트(ArrayList)를 생성하고 0번 노드를 추가 한 뒤, dfs탐색을 시작한다
43.과제 진행하기(프로그래머스-연습문제)
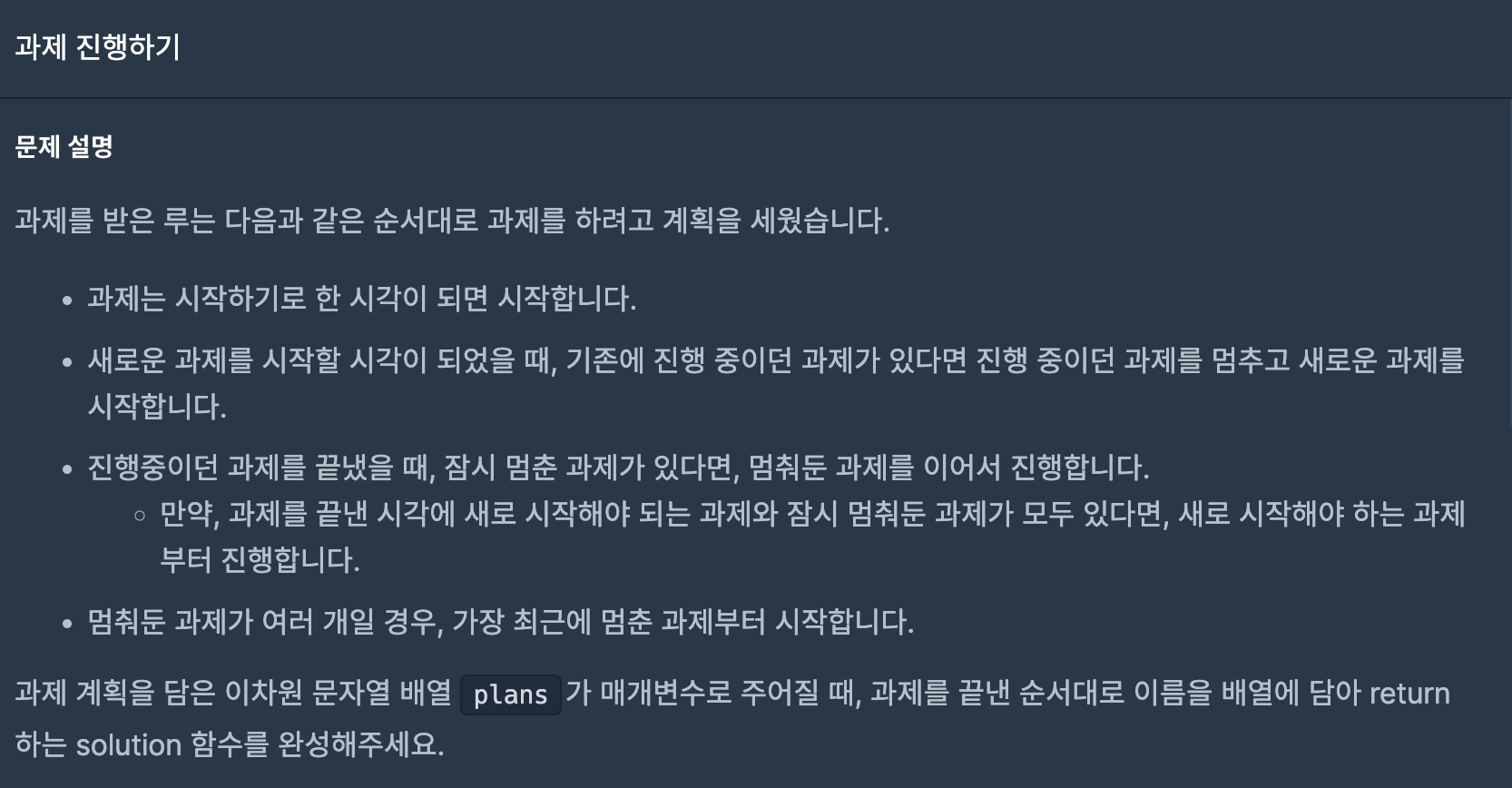
문제에서 요구한 대로 의식의 흐름대로 풀면 된다.나는 대기중인 과제를 큐에, 시작한 과제는 스택을 활용해서 다루었다.(1) 과제 리스트를 시작 시각 순서대로 정렬한 후, 큐(대기중인 과제)에 넣어준다.(2) 대기중인 과제가 없을 때까지 반복문을 실행한다. 다음 시작할
44.미로 탈출 명령어(2023 KAKAO BLIND RECRUITMENT)
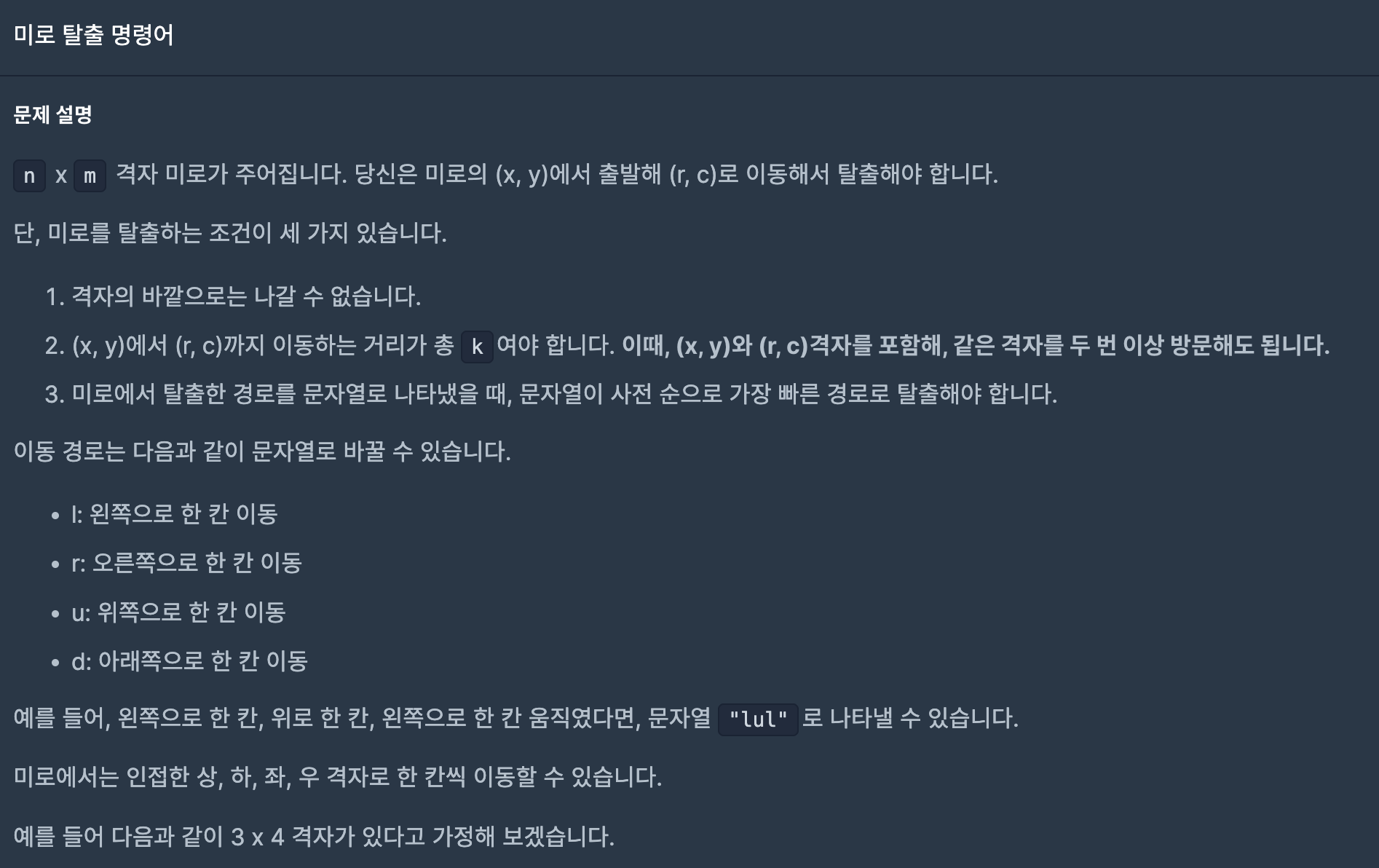
최적화가 필요한 dfs문제이다. 그냥 dfs로만 풀면 시간초과가 난다.일단 이 문제는 찾은 답 중에서 사전 순으로 가장 빠른 답을 구하는 문제이다. 하지만, 모든 답을 찾고 정렬을 해버리면 시간초과가 난다.그래서 탐색 자체를 d(하)-l(좌)-r(우)-u(상) 순서대로
45.연속 펄스 부분 수열의 합(프로그래머스- 연습문제)
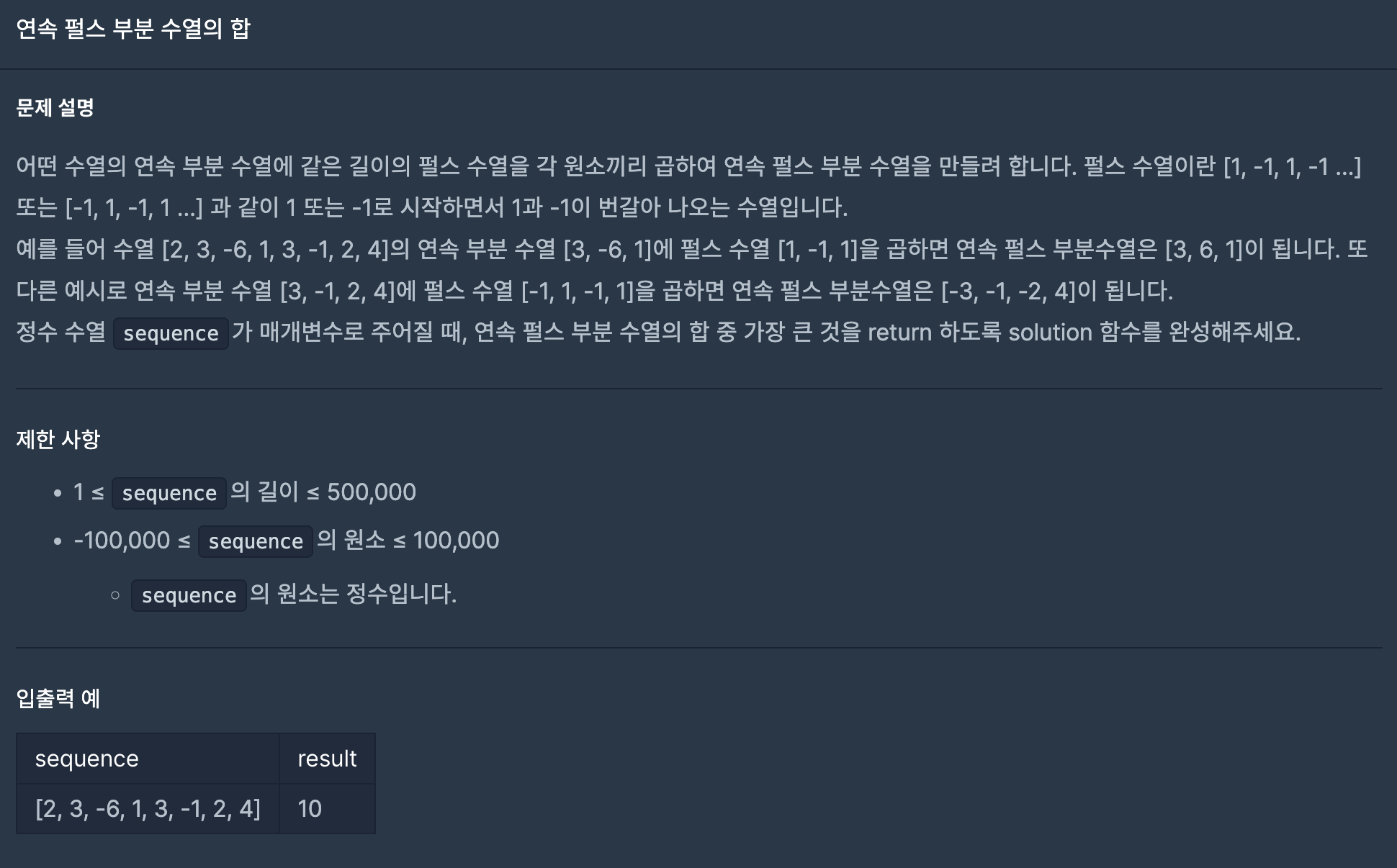
(1) 1로 시작하는 전체 펄스 수열, -1로 시작하는 전체 펄스 수열을 저장할 배열을 2개 생성한다(arr1, arr2). (2) arr1, arr2 의 각 인덱스별 최댓값을 저장할 배열을 2개 생성한다.(dp1, dp2)(3) arr1에는 sequence배열에서 0
46.두 원 사이의 정수 쌍(프로그래머스-연습문제)
문제 코드 풀이 일단 1사분면에 찍히는 점만 구해서 X4배를 해주면 되겠구나 라는 생각을 할 수 있다. 중요한 것은 1사분면에 찍히는 점을 어떻게 구할것이냐다. 그냥 모든 좌표를 돌면서 큰 원과 작은 원 사이에 존재하는지 검사하여 구할 수 있겠지만, for문을 두번
47.인사고과(프로그래머스-연습문제)
생각해야 할 것은 두가지이다. 인센티브를 받지 못하는 사람을 제외할 것.그 중 완호의 석차는 몇등인가.인센티브를 받지 못하는 경우는 근무 태도 점수와 동료 평가 점수 모두 더 높은 사원이 존재할 때이다.한명 한명 다 검사해 주기에는 시간복잡도가 n^2이 나오기 때문에
48.부대복귀(프로그래머스-연습문제)
이 문제는 인접리스트를 이용한 다익스트라 알고리즘을 통해 해결할 수 있다.이 문제의 핵심은 각 지역에서 도착지까지의 거리를 일일히 구하는 것이 아닌, 도착지에서 각 지역까지의 거리를 구해주는 것이다.만약, 각 지역마다 도착지까지의 거리를 구하는 작업을 일일히 한다면 아
49.[PCCP 모의고사 1] 4번 - 운영체제
(1) 우선순위 큐 두개를 만든다. wait큐는 아직 호출되지 않은 작업들이 들어간다.(호출 시간 순)arrive 큐는 호출 되었지만 아직 진행되지 않은 작업들이 들어간다.(우선 순위 순, 우선 순위가 같을 시 호출 시간순(2) wait 큐에 모든 작업들을 넣어주고,