
Hadoop HA 구성하기 시리즈는 총 3편으로, HA의 의미 및 설치 방법 순으로 글을 작성할 예정입니다. 아래와 같은 순으로 글이 전개될 예정이니 순서대로 혹은 필요한 내용만 보시면 될 것 같습니다.
[1] HA 의미 및 Java, Hadoop, Zookeeper 설치
[2] Hadoop 설정 및 ssh, ufw 설정
[3] Zookeeper 설정 및 Hadoop 실행
개요
Hadoop HA란?
우선적으로 용어 설명부터 해야하는데, HA란 High Availability로서 고가용성으로 직역을 많이들 한다. 사실 고가용성이란 단어만 들었을 때는 그 의미가 와닿지 않는데, Hadoop이 오랜 시간동안 정상 작동하게끔 만드는 것이라고 이해하면 편하다.
HA 개념이 나오기 전에는?
Hadoop HA은 Hadoop 2.x 버전부터 나오기 시작했는데, 그 이전의 하둡은 클러스터 당 네임노드가 한 대 뿐이라 네임노드 머신이 다운되면 해당 머신을 재가동시키기 전까지는 하둡을 정상적으로 사용하기 어려운 문제점 등이 존재했다.
그렇다면 어떻게 하둡이 고가용성을 유지하게 만드는가?
- 2대 이상의 네임노드를 둔다. 한 대는 Active 네임노드이며, 다른 머신/머신들은 Standby 네임노드이다.
- Hadoop 3.x 부터는 2대 이상의 네임노드를 둘 수 있다.
Active는 클러스터 안에서 실질적인 연산(읽기, 쓰기 등)의 역할을 하며,Standby는 Active 네임노드와 싱크를 맞추기 위해서 Journalnode로부터 메타데이터의 변경 로그(EditLog)들을 읽어온다.- Active 네임노드가 모종의 이유(서버 다운 등..)로 죽는다면, Standby 네임노드가 Active 네임노드가 된다.
Zookeeper, ZKFC
사실 위의 설명에서 많은 것이 생략되었다. Active 네임노드가 죽으면 뿅하고 Standby가 Active가 되는 것이 아니라 이때의 Zookeeper, ZKFC의 역할이 중요하다.
Zookeeper
- 데이터의 변화를 클라이언트에게 보고함
- 클라이언트의 장애를 모니터링함
- 주키퍼는 각각의 네임노드들과 지속적인 session을 유지하고 있는데, 네임노드의 서버가 죽는다면 zookeeper session은 만료될 것이고, 다른 네임노드에게 failover가 일어날 것(Standby가 장애가 생긴 Active를 대체)임을 알린다.
ZKFC
- 네임노드의 상태를 모니터링하고 관리하는 주키퍼 클라이언트
- 네임노드가 돌아가는 서버는 zkfc 또한 같이 돌아감
- ZKFC는 네임노드에게 ping을 보내 health한 상태인지 아닌지를 체크함
노드 구성
서버의 수적 열세로..(하둡을 위한 서버로 라즈베리파이 2대를 사용) 서버 2대에, 네임노드 2 데이터노드 2로 구성하였습니다.
당연히 서버 2대에 모든 노드를 몰아넣는 것보다 3대 이상으로 구성하는 것이 안정적입니다만, 서버 2대로 구성하고 싶은 사람들이 있을 수 있으니 글을 적어보겠습니다. 노드 구성은 아래 그림과 같습니다.
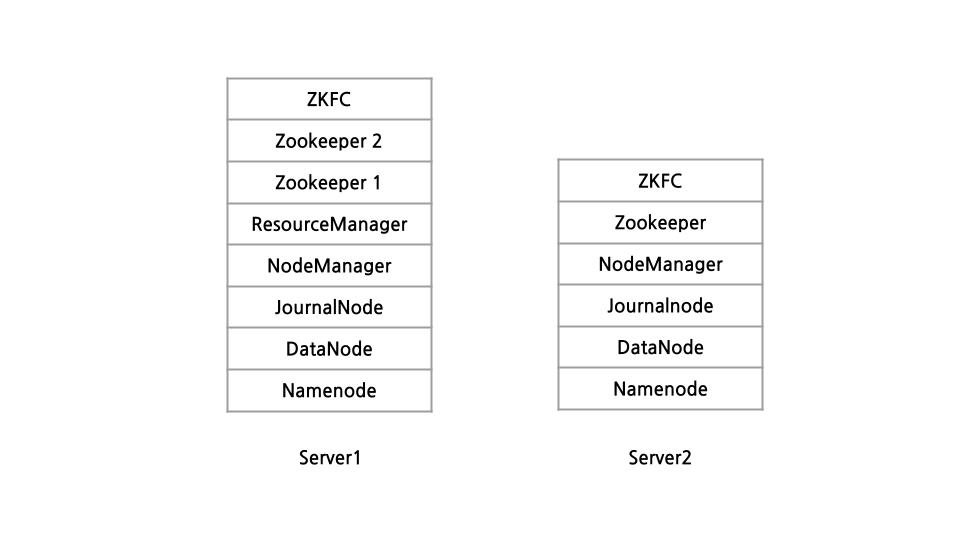
설치
설치 파트는 모든 서버에서 진행하시면 됩니다.
Java
sudo apt install openjdk-11-jdk하둡은 자바 기반 오픈소스 프로그램이기 때문에, 자바를 우선적으로 설치해줘야 하는데 하둡 버전에 맞는 Java 버전은 이 사이트를 참고하면 된다.
Hadoop 3.3 이상부터는 Java 11을 사용해야 한다. 참고로 Hadoop 3.0 ~ 3.2는 Java 11이 지원되지 않으며, Java 8을 설치해야 한다.
Hadoop 3.3.4
# 다운로드
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
# 압축 풀기
tar xvzf hadoop-3.3.4.tar.gz
# 폴더 이동
sudo mv hadoop-3.3.4 /usr/local/hadoop
# Hadoop 디렉토리 사용자 그룹 변경
sudo chown -R $USER:$USER /usr/local/hadoop하둡을 다운받기 위해서는 공식 문서를 참고하면 되는데, 해당 사이트의 binary를 클릭하면 다운로드 받을 수 있는 링크가 나오게 된다.
Zookeeper 3.8.0
# 다운로드
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz
# 압축 풀기
tar xzvf apache-zookeeper-3.8.0-bin.tar.gz
# 폴더 이동
sudo mv apache-zookeeper-3.8.0-bin /usr/local/zookeeper
# Zookeeper 디렉토리 사용자 그룹 변경
sudo chown -R $USER:$USER /usr/local/zookeeperZookeeper는 해당 공식 문서에서 다운받을 수 있다.
환경 변수
프로그램을 실행하기 쉽도록 bashrc에 환경변수를 등록해주겠습니다. 먼저 vim으로 bashrc를 열어야 합니다.
sudo vim ~/.bashrc아래의 환경변수들을 bashrc에 등록해줍니다.
# java
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export PATH=$PATH:$JAVA_HOME/bin
# hadoop
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/etc/hadoop
환경 변수를 활성화해줍니다.
source ~/.bashrc설치는 간단하게 끝이 났고, 다음 편에는 Hadoop HA 설정 및 property 의미에 대해 알아보겠습니다.
