
📍 비트(bit)란?
-
컴퓨터에서 정보를 디지털 신호로 다룰 때 데이터 양의 최소기본 단위
-
bit는 'binary digit'의 약자, 즉 이진수 라는 뜻
-
컴퓨터도 장비간에 의사소통을 하기 위해 언어가 필요함 == binary(이진수)
컴퓨터는 전자스위치로 구성된 전기장치이며, 전자식 스위치를 이용하여 데이터를 전달하는 것이 기본적
따라서 단순 전기적 신호에 대해서만 반응하여 전기적 충격은 컴퓨터에서 on 또는 off(1 또는 0)
즉, 컴퓨터는 두가지 상태(2진수의 0과 1) 형태만 이해하고 사용 가능 -
보통 1은 전원 on 상태, 0은 전원 off 상태를 표현하고 이것을 2진수(binary) 또는 비트(bit)라고 부름
📍 바이트(Byte)란?
-
컴퓨터가 실제로 사용할 수있는 데이터 중 가장 작은 주소
-
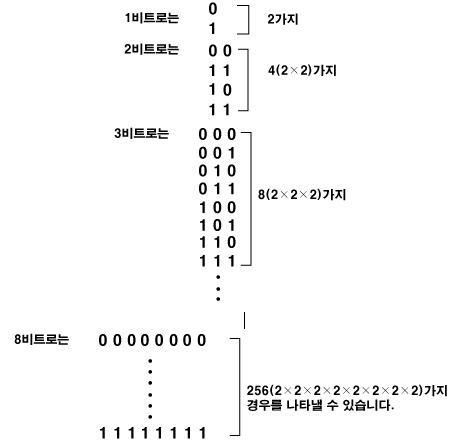
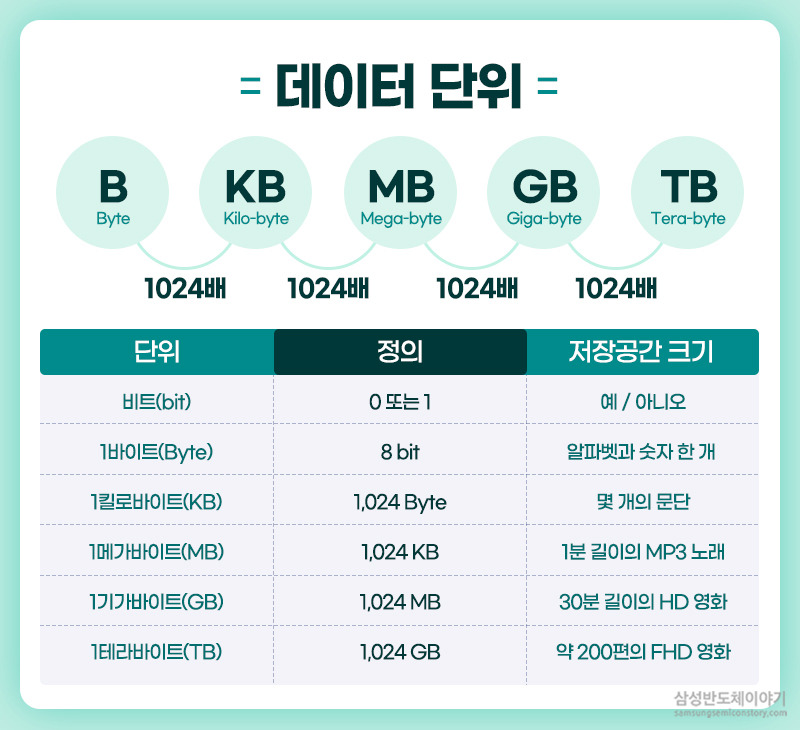
컴퓨터는 일반적으로 다양한 데이터를 표현하기위해 여러 비트를 묶어 정보를 나타낼 수 있는데, 8개 단위의 비트(8bit)를 하나의 그룹으로 사용하는 것이 바이트(bite)(8bit == 1Byte)
즉, 1바이트는 8개의 on/off상태를 조합하여 나타낼 수 있는 수는 총 256(2^8)가지가 되기 때문에 1바이트(byte)는 0부터 255 까지의 값을 갖게됨
-
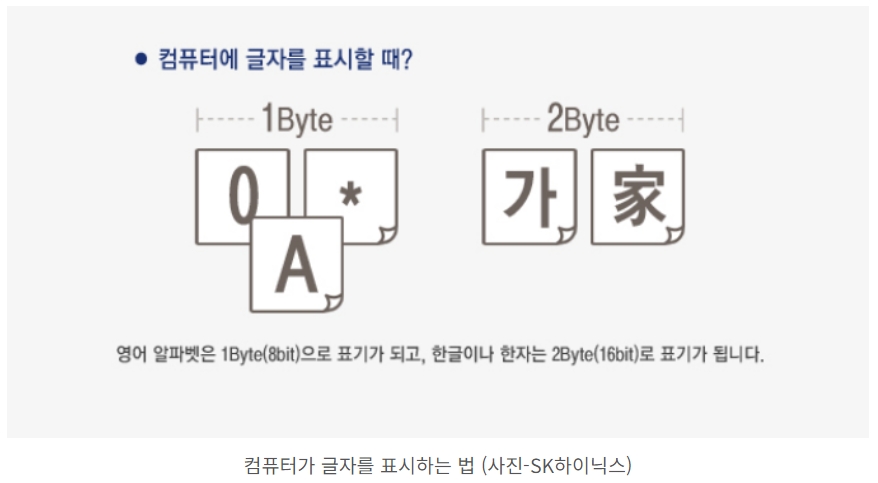
바이트(Byte)는 주소 지정이 가능한 단일저장소라고 부르며, ASCII 코드와 같은 데이터 문자를 표현
📍 비트와 바이트 요약
비트는 컴퓨터가 데이터를 저장할 수 있는 최소 단위
바이트는 컴퓨터가 데이터를 처리하기 위한 최소 단위

비트는 주로 인터넷 및 포트 속도와 같은 데이터 인터페이스 속도를 설명하는데 사용
초당 비트 수(bps)는 일정 기간 동안 인터페이스가 전송할 수 있는 데이터의 양을 나타내는데 사용되며 일반 비트와 동일한 접두사를 가질 수 있음
바이트는 컴퓨터에서 볼 수 있는 파일 크기 뿐만 아니라 메모리 단위 성능, 저장 장치 용량 및 전송 속도에서 거의 모든 곳에 사용
인터페이스는 다른 장치와 시스템 사이의 다리 일 뿐이지만 장치 자체는 전체 바이트만 사용하여 작동해야함
인터페이스란?
상호작용 하는 곳
전기 신호의 변환으로 중앙 처리 장치와 그 주변 장치를 서로 잇는 부분
일종의 매개체, 2개 이상의 장치나 소프트웨어 사이에 정보나 신호를 주고받을 수 있도록 함
비트(bit)와 바이트(Byte)는 모두 B로 시작하기때문에 비트는 소문자 b, 바이트는 대문자 B로 표기
그래서 1MB = 1Mega Byte, 1mb = 1 Mega bit를 의미
📍 메모리 용량 단위
10진법 체계에서 킬로라는 단위는 10³(1000)을 의미하는 단어
1킬로미터(1km)는 1000미터, 1킬로그램은 1000그램
즉, 1킬로는 1000이라는 단위 수를 말함
2진법 체계에서 킬로라는 단위는 2¹⁰바이트(1024바이트)가 1000바이트와 매우 유사하지만 엄연히 24라는 잉여바이트가 존재
처음은 24차이지만 단위가 커질수록 오차가 더욱 심해짐
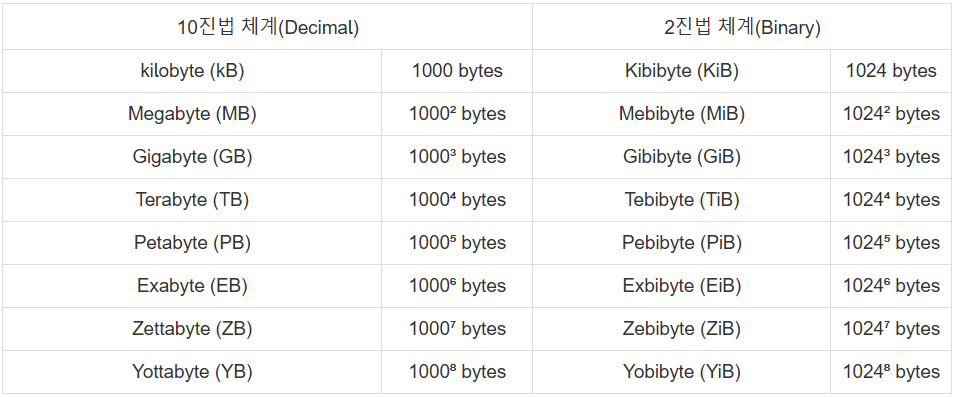
1KB(킬로바이트) = 1,024Byte
1MB(메가바이트) = 1,024KB = 1,048,576Byte
1GB(기가바이트) = 1,024MB = 1,048,576KB = 1,073,741,824Byte
1TB(테라바이트) = 1,024GB = 1,048,576MB = 1,073,741,824KB = 1,099,511,627,776Byte
즉, KB<MB<GB<TB는 1024배씩 증가!
📍 ASCII Code
ASCII(American Standard Code for Information Interchange, 미국 정보 교환 표준 부호)
1963년 미국 ANSI에서 표준화한 정보교환용 7비트 부호체계(128개의 고유한 값)
8비트 컴퓨터에서도 활용되어 오늘날 문자 인코딩의 근간을 이루게 된다.
인코딩(encoding)문자나 기호들의 집합을 컴퓨터에서 저장하거나, 통신 목적으로 사용할 경우에는 부호로 바꾸어야한다.
이를 문자인코딩(encoding) 또는 부호화라고 하며 부호화된 문자를 복원하는 것을 복호화라고 함
000(0x00)부터 127(0x7F)까지 총 128개의 부호가 사용된다. 1바이트를 구성하는 8비트 중에서 7비트만 쓰도록 제정된 이유는, 나머지 1비트를 통신 에러 검출을 위한 용도로 비워두었기 때문이다.
Parity Bit라고 해서, 7개의 비트 중 1의 개수가 홀수면 1, 짝수면 0으로 하는 식의 패리티 비트를 붙여서, 전송 도중 신호가 변질된 것을 수신측에서 검출해낼 수 있도록 하였다.
BUT, ASCII Code를 이용해 다른 나라 언어를 표현하기에는 7비트로는 부족했다. 그래서 8비트(256개)로 확장된 아스키 코드가 나왔음 == ANSI 코드
그러나 비유럽 국가, 특히 한국, 중국, 일본과 같은 문자가 많은 국가에서는 여전히 제한적이었음. 그래서 유니코드(Unicode)라는 전 세계 언어의 문자를 정의하기 위한 국제 표준 코드 등장!
📍 유니코드(Unicode)
용량을 크게 확장한 2byte(2^16 = 65536가지)의 유니코드가 등장
전 세계의 모든 문자를 다루도록 설계된 표준 문자 전산 처리 방식
유니코드 컨소시엄(Unicode Consortium)에서 제정, 관리
주요 구성 요소는 ISO/IEC 10646 Universal Character Set과 UCS, UTF 등의 인코딩 방식, 문자 처리 알고리즘 등이다. 전 세계의 모든 문자를 담는 ISO/IEC 10646 코드표를 사용함으로써, 각 언어와 문자 체계에 따른 충돌 문제를 해결하였다. 따라서 유니코드를 사용하면 한글과 신자체·간체자, 아랍 문자 등을 통일된 환경에서 사용할 수 있다.
Unicode(유니코드)는 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 문자 인코딩 표준
이전에 사용되던 ASCII(American Standard Code for Information Interchange)는 주로 영어 알파벳과 일부 특수 문자만을 지원했지만, Unicode는 다양한 언어와 문자 체계를 포함하여 모든 언어를 지원할 수 있도록 설계
📖 유니코드 특징
① 전 세계 문자 지원 : 유니코드는 모든 주요 언어의 문자를 지원(ex. 라틴 문자, 한글, 중국어, 일본어, 아랍 문자 등..)
② 일관된 문자 표현 : 각 문자에는 고유한 코드 포인트(숫자)가 할당되어있음. 이 코드 포인트는 16진수로 표현되며 모든 컴퓨터 시스템에서 동일한 문자를 일관되게 표현할 수 있게 해줌
③ 멀티바이트 인코딩 : UTF-8, UTF-16, UTF-32와 같은 다양한 인코딩 스키마를 제공하여, 다양한 길이의 코드 유닛을 사용하여 Unicode 문자 표현 가능. UTF-8이 가장 널리 사용되며, 가변 길이의 인코딩 방식으로 ASCII와 호환되며, 대부분의 현대 시스템에서 표준으로 채택
④ 확장 가능성 : 유니코드는 지속적으로 확장되고 있어 새로운 문자나 이모티콘 등 추가 가능. 이는 전 세계에서 사용되는 언어와 문자 체계가 변화하거나 확장됨에 따라 필요한 기능
⑤ 표준화의 국제화 : ISO(International Organization for Standardization)와 유니코드 컨소시엄(Unicode Consortium)에 의해 관리되는 표준으로, 전 세계의 다양한 기술 기업과 개발자들에 의해 지속적으로 발전
