In-Context Learning (ICL)
모델이 별도의 추가 학습 없이 주어진 프롬프트 내 맥락(context)을 활용해 문제를 해결하는 능력으로, ICL의 성능은 프롬프트 설계(프롬프트 엔지니어링)에 크게 의존한다.
Few-shot Learning
-
Few-shot Learning 이란?
- 프롬프트에 몇 개의 예시를 제공해 모델이 일반화를 수행하도록 유도함
- 적은 수의 예시만으로도 모델이 새로운 작업을 수행할 수 있도록 함
- 모델의 사전 학습된 지식을 활용하여 최소한의 추가 정보로 작업을 수행할 수 있도록 함
-
Few-shot prompt 예시
이 집합 {4, 8, 9, 15, 12, 2, 1}에서 홀수의 합은 짝수입니다. A: 답은 거짓입니다. 이 집합 {17, 10, 19, 4, 8, 12, 24}에서 홀수의 합은 짝수입니다. A: 정답은 참입니다. 이 집합 {16, 11, 14, 4, 8, 13, 24}에서 홀수의 합은 짝수입니다. A: 답은 참입니다. 이 집합 {17, 9, 10, 12, 13, 4, 2}에서 홀수의 합은 짝수입니다. A: 답은 거짓입니다. 이 집합 {15, 32, 5, 13, 82, 7, 1}에서 홀수의 합은 짝수입니다. A:
프롬프트 엔지니어링
AI가 사용자의 입력(프롬프트)을 보다 정확히 이해하고 적절한 응답을 생성할 수 있도록 프롬프트를 최적화하는 과정
Chain-of-Thought (CoT)
- CoT 란?
- 복잡한 문제 해결 과정에서 단계별 추론을 사용하여 AI의 답변 퀄리티를 높이는 프롬프트 엔지니어링 기법
- CoT는 사용자의 프롬프트에 대해 AI가 단순히 최종 답변을 제시하는 것이 아니라, 중간 단계의 사고 과정을 보여주는 것을 목표로 함
- 질문을 단계별로 분해하고, 각 단계에서 필요한 정보와 추론 과정을 명시하는 것이 핵심
- 복잡하고 추론이 필요한 작업에서 디코더 모델의 성능을 크게 향상시킴
- 모델은 각 단계의 추론 과정을 명시적으로 보여주면서 최종 답변에 도달함
- CoT 예시
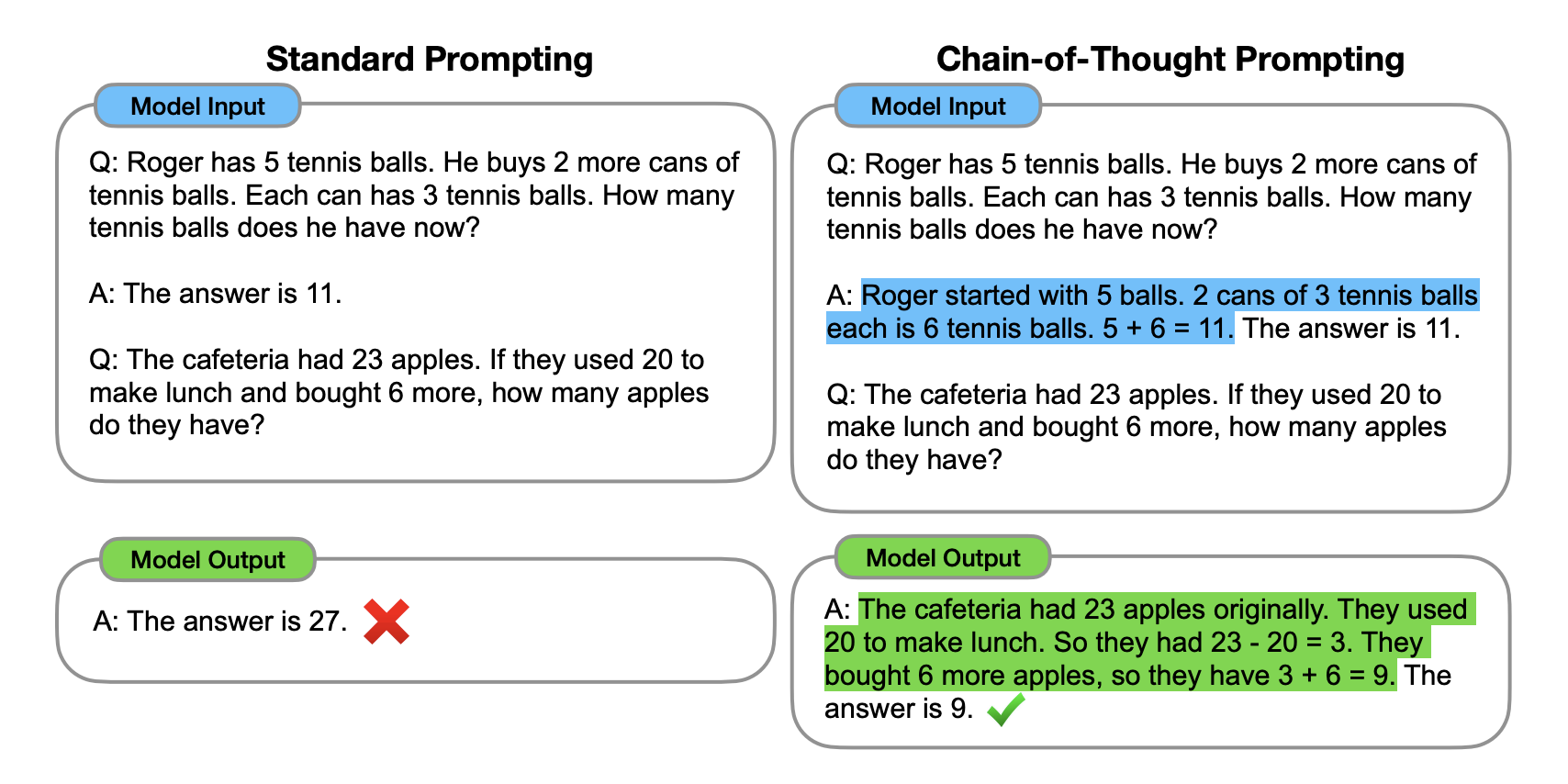
- CoT의 한계 및 개선점
- CoT는 단 하나의 추론 경로만을 가짐
- 즉, 간단한 형태의 Reasoning 추가만으로 문제해결 능력이 향상되나, 하나의 갈래의 Reasoning만 가능한 문제점을 개선해야 함
Tree-of-Thought (ToT)
- ToT 란?
- 복잡한 개념이나 문제를 계층적 구조로 분해하여 이해하고 해결하는 프롬프트 엔지니어링 기법
- 문제를 트리 구조로 풀어 다양한 경로를 탐색하며 답을 도출하도록 유도
- 주어진 주제를 상위 개념부터 하위 개념까지 단계적으로 세분화하는 것이 핵심
- CoT와 달리, ToT는 여러 가능성을 동시에 탐색하므로 복잡한 문제에 적합
- ToT 프레임워크
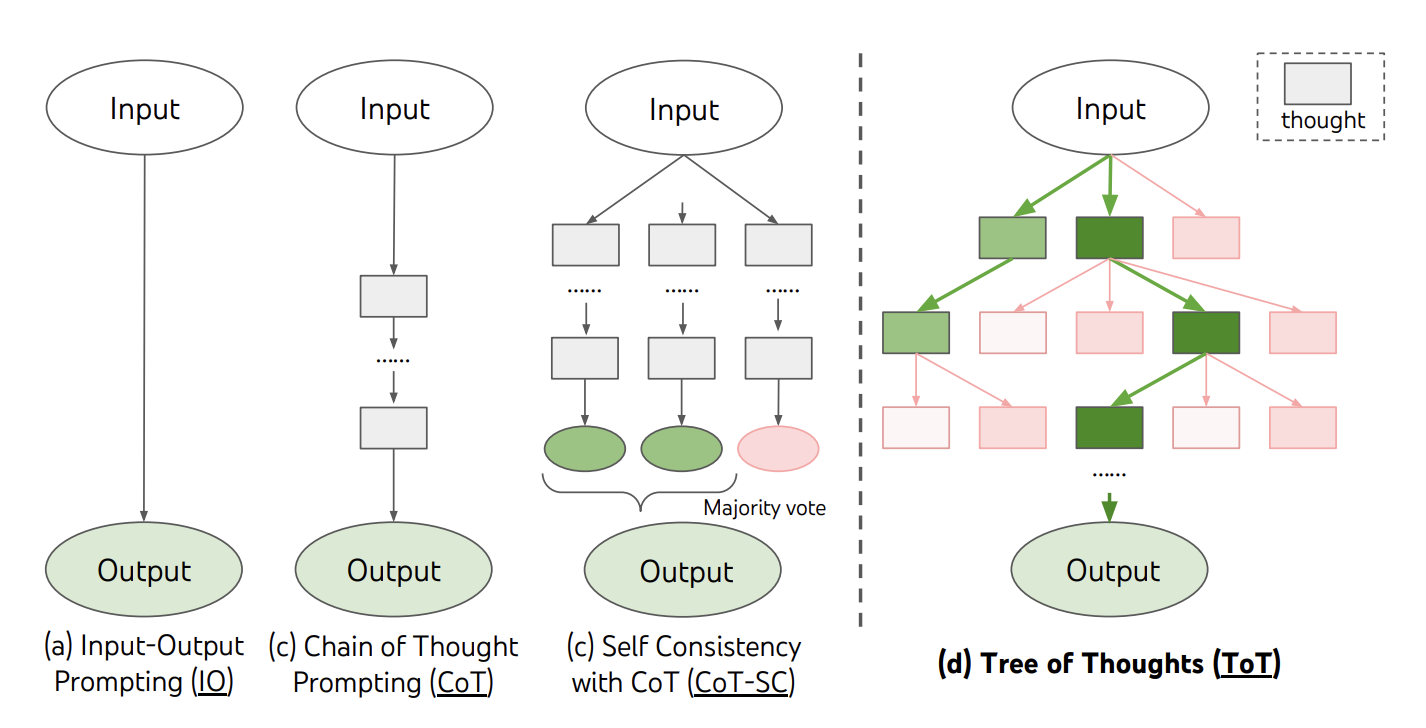
- ToT 예시
세 명의 다른 전문가들이 이 질문에 답하고 있다고 상상해보도록 해. 모든 전문가들은 자신의 생각의 한 단계를 적어내고, 그것을 그룹과 공유할거야. 그런 다음 모든 전문가들은 다음 단계로 넘어가. 등등. 만약 어떤 전문가가 어떤 시점에서든 자신이 틀렸다는 것을 깨닫게 되면 그들은 떠나. 그렇다면 질문은... - ToT의 한계 및 개선점
- 사고가 진행되는 추론 경로의 구조가 단조롭고 유연하지 않음
- 만들어지는 Thoughts의 대부분이 낭비됨
- 즉, 완성도 높은 reasoning path를 만들 수 있으나, 생각을 활용하는 구조가 단순하고 대부분이 낭비된다는 단점을 개선해야 함
Graph of Thought (GoT)
- GoT 란?
- 그래프를 활용하여 개념 간의 관계와 맥락을 표현함으로써 프롬프트를 설계하는 방법
- GoT는 개념들을 노드(node)로, 개념 간의 관계를 엣지(edge)로 표현하는 그래프 구조를 기반으로, 문제를 그래프 구조로 확장해 다양한 상호 연결된 아이디어를 고려하며 답을 찾음
- 먼저 주어진 태스크와 관련된 핵심 개념들을 식별하고, 이들 간의 관계를 정의하여 그래프를 구축
- 이후 그래프상에서 질의응답에 필요한 경로를 탐색하고, 관련 개념과 관계를 프롬프트에 반영하여 AI 시스템이 맥락을 고려한 응답을 생성할 수 있도록 함
- GoT 프레임워크
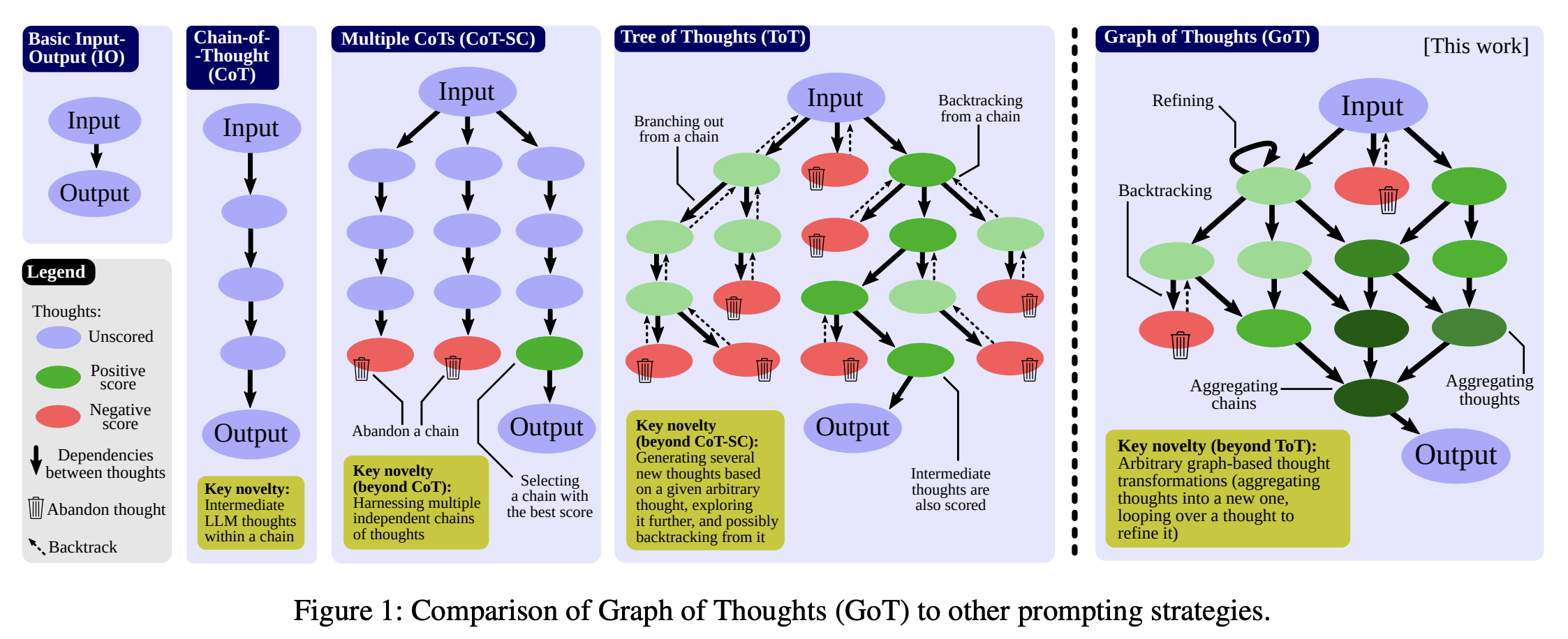
Human Alignment
AI 모델을 인간의 의도와 가치에 맞추어 조정하는 과정
Instruction Tuning
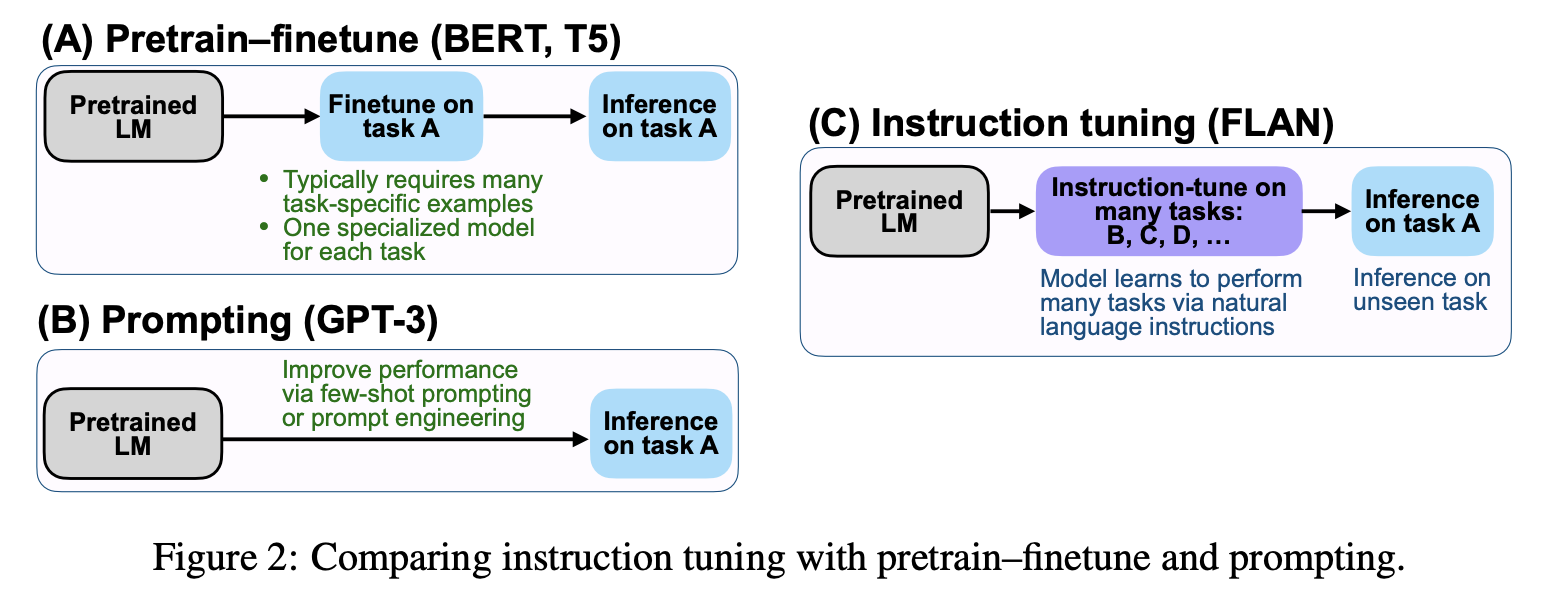
- Pretrain-Finetune (BERT, T5)
- 사전 학습된 언어 모델을 특정 작업(예: 스팸 분류)에 미세조정하는 방법
- 모델은 특정 작업에 대해 학습하고, 해당 작업의 추론을 수행할 수 있게 됨
- Prompting (GPT-3)
- 사전 학습된 언어 모델에 몇 가지 예시(Few-shot)나 프롬프트 엔지니어링을 통해 원하는 작업을 수행하게 하는 방법
- 모델은 제공된 프롬프트를 기반으로 작업을 수행함
- Instruction Tuning (FLAN)
- 다양한 작업에 대해 모델을 Instruction Tuning하여 새로운 작업을 제로샷(Zero-shot)으로 수행할 수 있게 하는 방법
- 모델은 명시적인 예시 없이도 주어진 지시사항을 이해하고 수행할 수 있게 됨
Human Feedback 기반 최적화
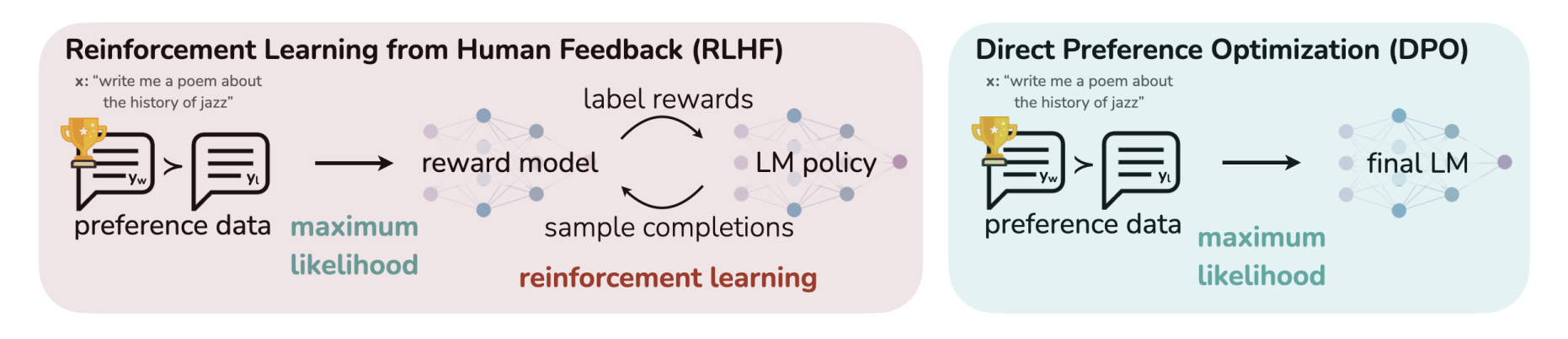
- Reinforcement Learning from Human Feedback (RLHF)
- 인간의 선호도 데이터를 사용하여 모델을 최적화하는 방법
- 선호도 데이터를 최대우도법으로 처리하고, 보상 모델을 통해 언어 모델의 정책을 조정함
- Direct Preference Optimization (DPO)
- 선호도 데이터를 직접 사용하여 최대우도법으로 최종 언어 모델을 최적화하는 접근법
- RLHF보다 더 직접적이고 간단한 방식으로 모델을 인간의 선호에 맞추어 조정함
In-Context Learning은 모델의 학습 능력을 확장하고, Human Alignment 기술은 모델이 인간의 의도와 가치에 더 잘 부합하도록 한다.
Reference

🌱 🐜