boostcamp
1.Github으로 따라하는 버전 관리

소프트웨어 개발을 할 때, 여러 사람이 참여하는 방식으로 개발의 효율을 올린다. 개발 도중 수정된 내용을 바로 확인하고, 서비스에서는 배포된 소프트웨어의 버전 관리를 함으로써 개발의 효율성을 높일 수 있다. Git은 이러한 소프트웨어 버전 관리 시스템의 한 종류이다.
2. 문장 간 유사도 측정 프로젝트 회고

Semantic Text Similarity(STS)란 두 텍스트가 얼마나 유사한지 판단하는 NLP Task로, 이번 프로젝트는 STS 데이터셋을 활용해 두 문장의 유사도를 측정하는 AI 모델을 구축하는 것을 목표로 한다.
3.ODQA 프로젝트 Overview
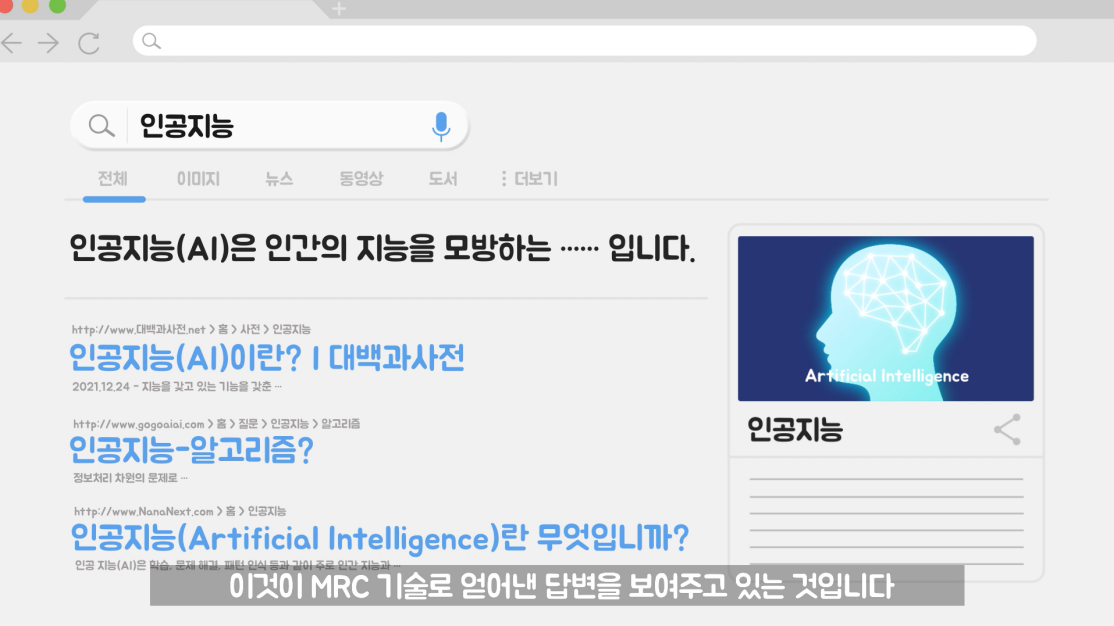
ODQA란 다양한 종류의 질문에 대해 방대한 World Knowledge resources 중 적절한 문서를 찾아 답변을 도출하는 NLP Task로, 이번 프로젝트는 이러한 검색엔진과 유사한 형태의 시스템을 만들어보는 것을 목표로 한다.
4.Extraction-based MRC
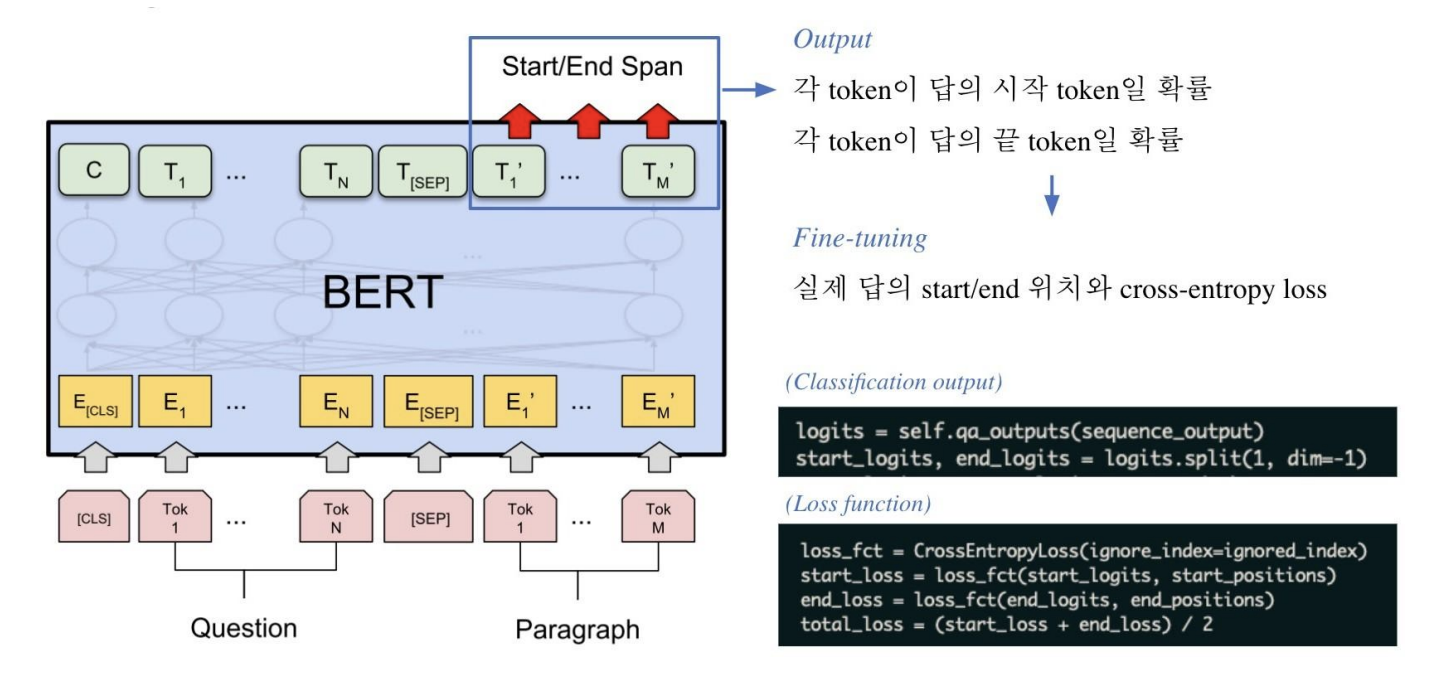
추출 기반으로 기계 독해를 푸는 방법
5.Generation-based MRC
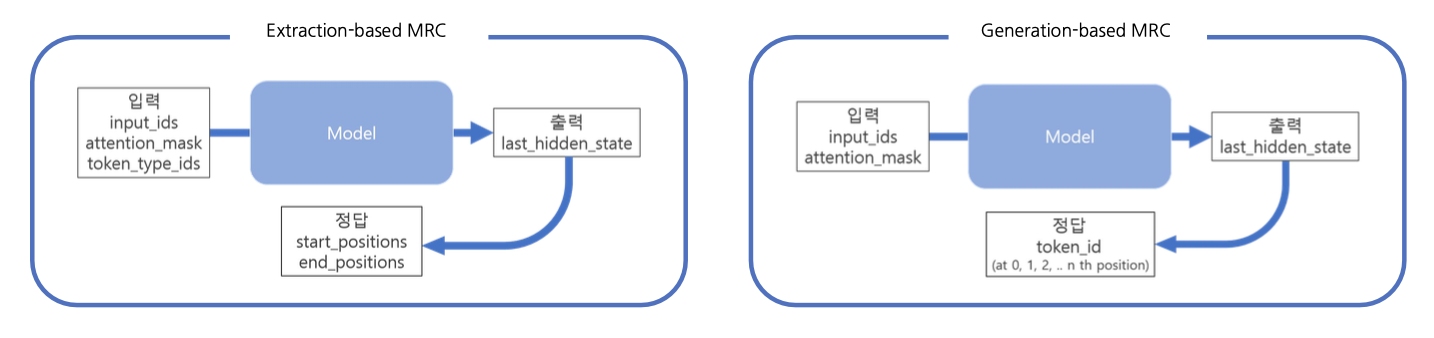
생성기반으로 기계독해를 푸는 방법
6.Sparse Embedding: Bag of Words, TF-IDF, BM25
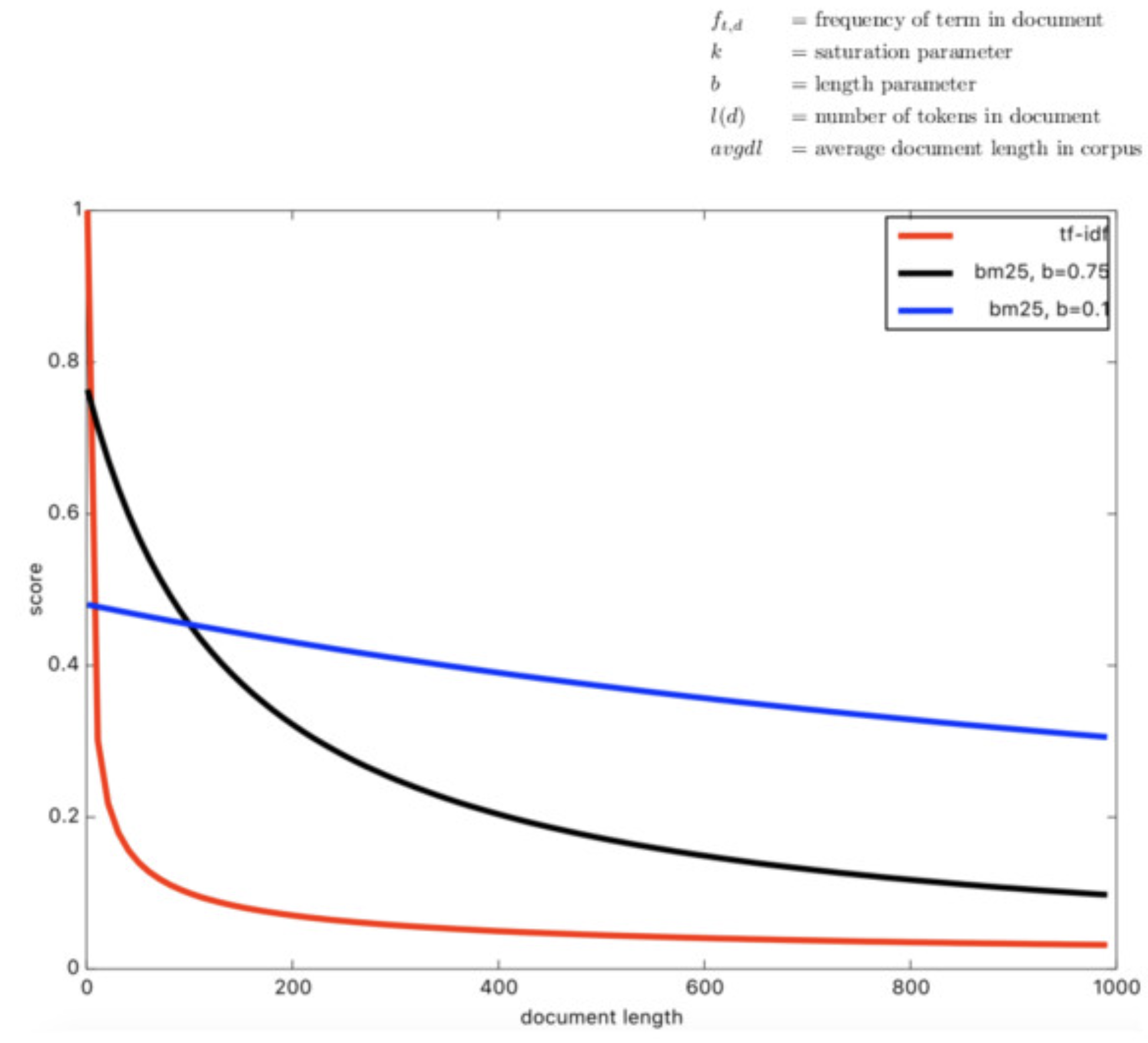
Sparse Embedding(희소 임베딩)은 벡터의 크기가 매우 크지만 많은 원소가 0이고, 소수의 원소만이 유의미한 값을 가진다.
7.Dense Embedding: DPR(Dense Passage Retrieval)
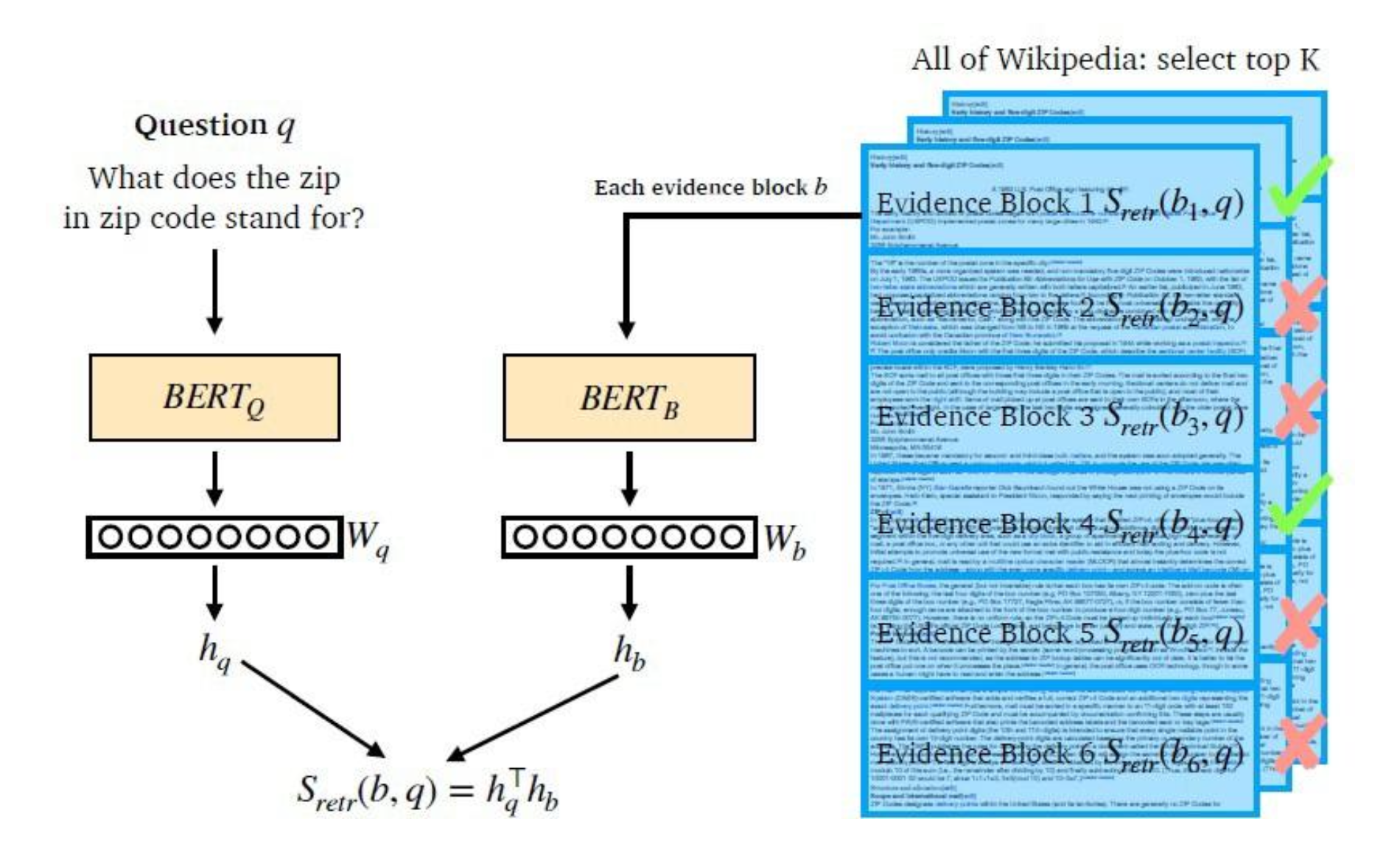
Dense Embedding(밀집 임베딩)은 저차원의 벡터에서 모든 값이 실수로 채워져 있고, 각 차원에 의미 있는 정보가 압축되어 표현된다.
8.Linking MRC and Retrieval
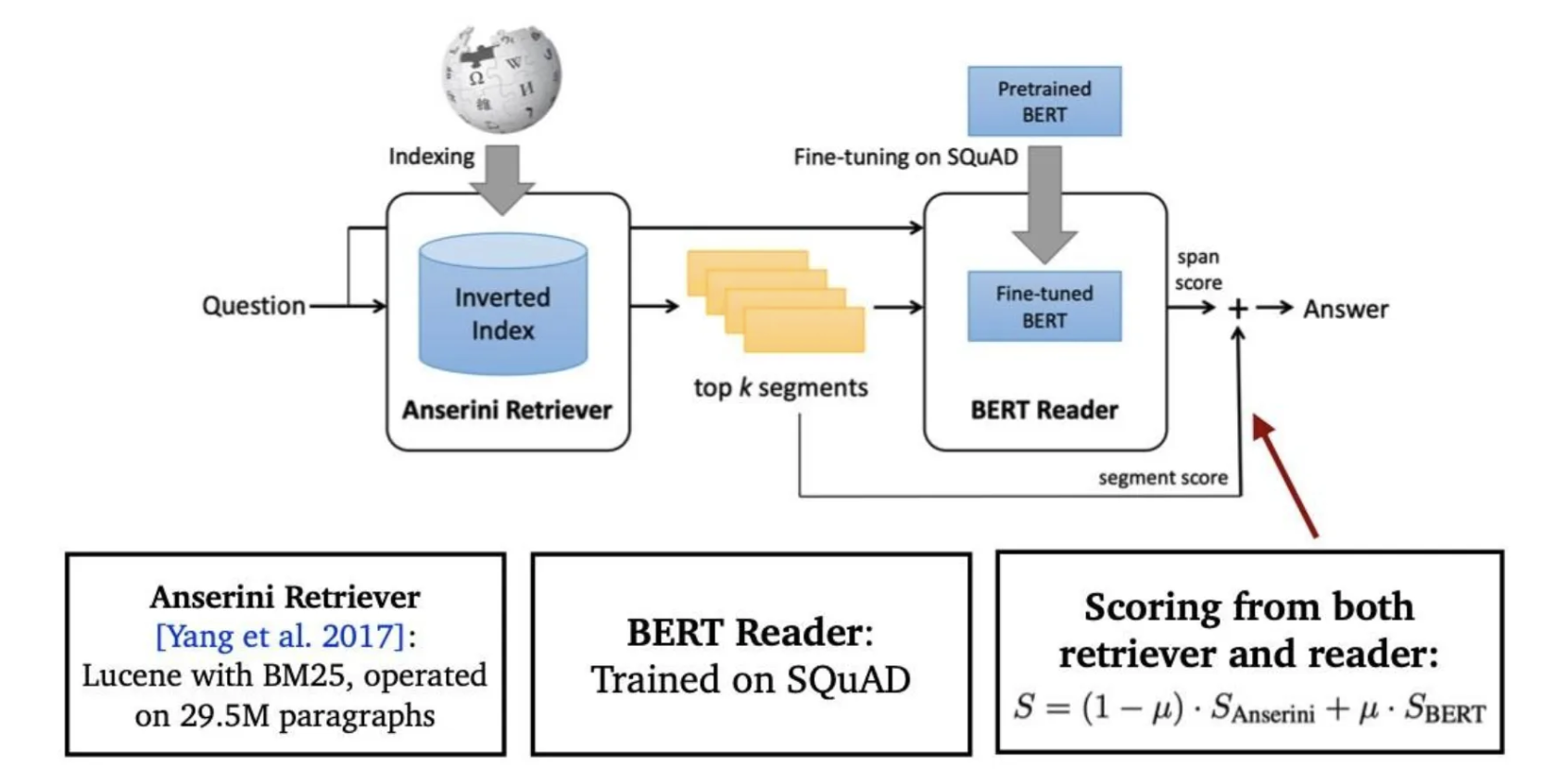
기계독해와 문서 검색을 연결해 Open-domain question answering(ODQA)를 푸는 방법
9.슬랙에 깃허브 알림 연동하기

슬랙에 깃허브 알림을 연동하는 방법
10.In-Context Learning and Human Alignment
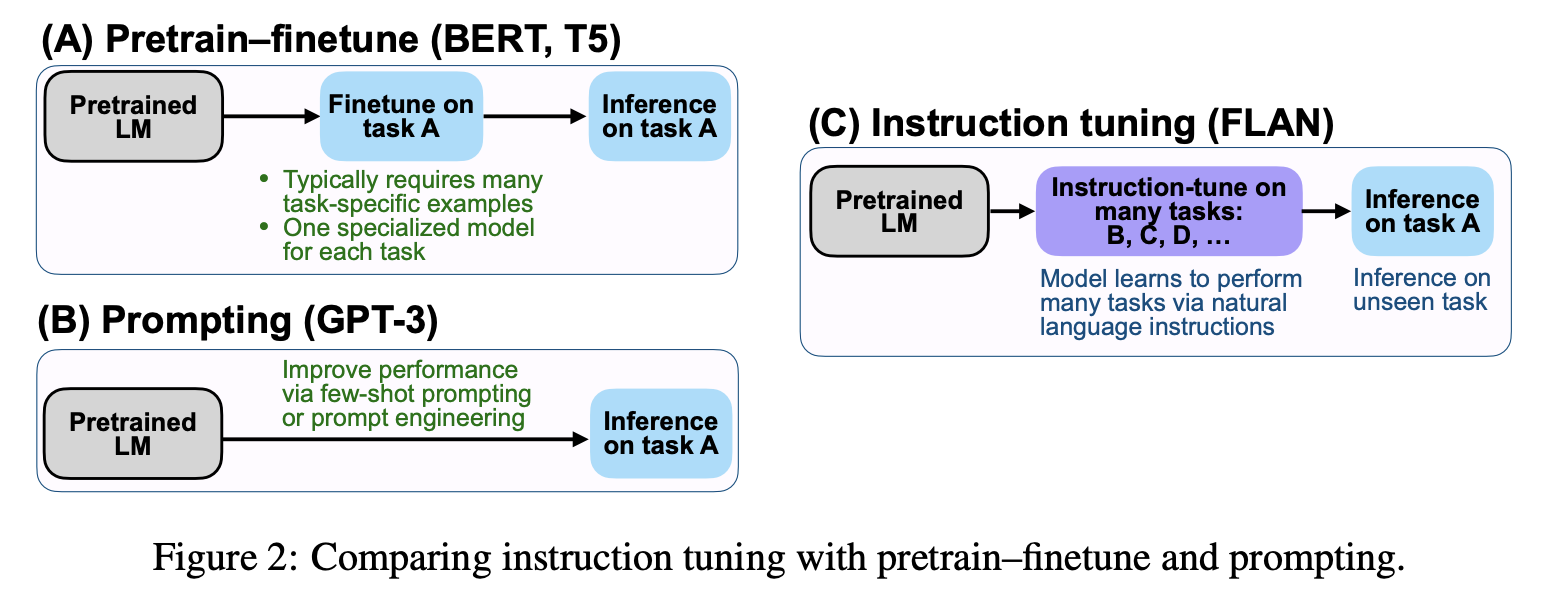
In-Context Learning이란 모델이 별도의 추가 학습 없이 주어진 프롬프트 내 맥락(context)을 활용해 문제를 해결하는 능력을 말하며, Human Alignment란 AI 모델을 인간의 의도와 가치에 맞추어 조정하는 과정을 의미한다.