논문 리뷰 - GPT-3 : Language Models are Few-Shot Learners
Abstract
- 기존의 가장 큰 모델보다 10배 많은 파라미터
- Scaling-up(모델 크기 확장)을 통해 few-shot learning에서도 task-specific한 기존의 fine-tuning 모델들의 성능에 필적하는 성능
Introduction
- 기존 NLP 연구: task에 무관한 representation을 학습하는 방향으로 발전
- task-agnostic model: task-agnostic model: 대규모 corpus를 이용해 pre-training 후 task-specific fine-tuning을 진행
- task-agnostic model 의 한계
- 각각의 task에 대해 fine-tuning이 필요하여 대규모 labeled dataset이 필수적
- out-of-distribution 데이터에 대한 일반화 성능 부족
한계 극복 방법
1) In-context learning
- 사전 학습된 모델에 문제와 관련 예시를 함께 제공하여 학습 없이 적용
- Zero-shot, One-shot, Few-shot 등의 다양한 접근 방법을 포함
2) 모델 크기 증가
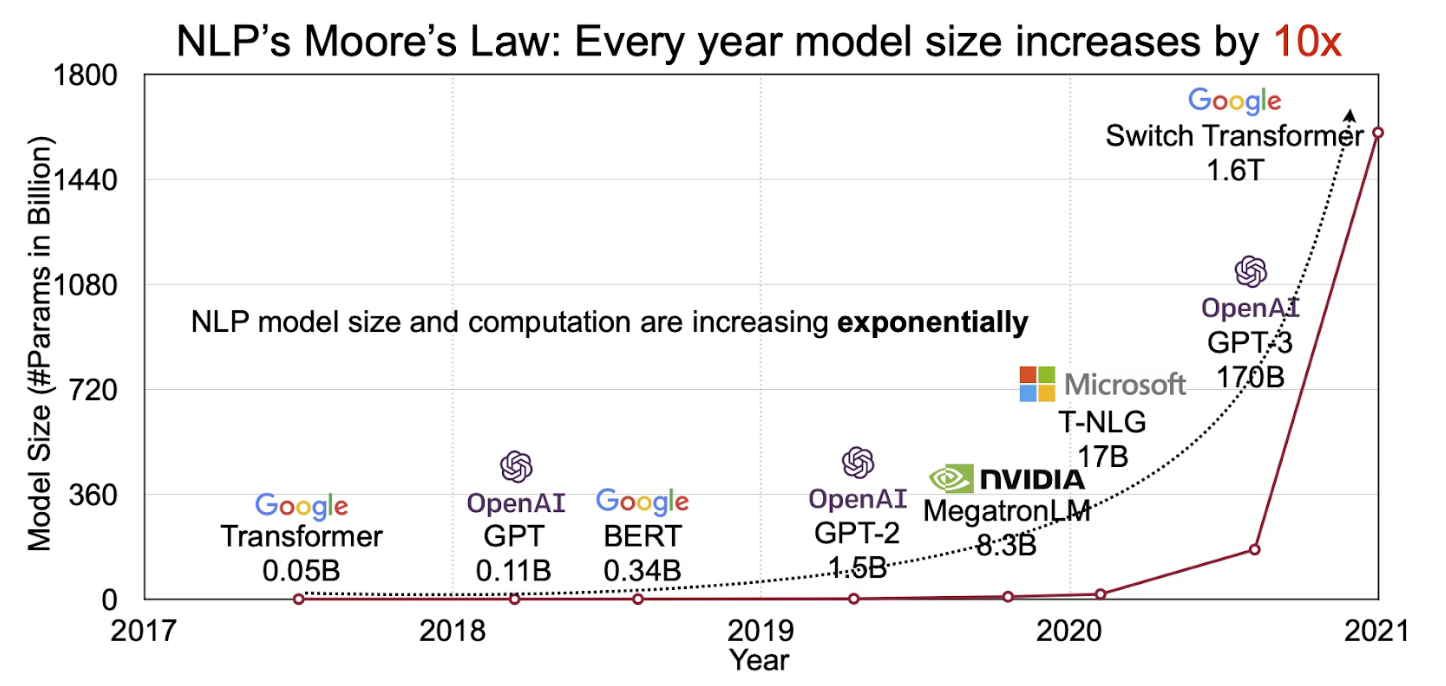
- 연도별 출시된 LLM들의 모델 사이즈를 표현한 그래프
- 큰 모델은 더 많은 파라미터와 복잡한 데이터 분포 학습 가능
GPT-3에서는 위의 두가지 트렌드를 모두 적용 -> Fine Tuning 없이 사전 학습만으로도 다양한 문제를 잘 푸는 범용적인 LLM 제작
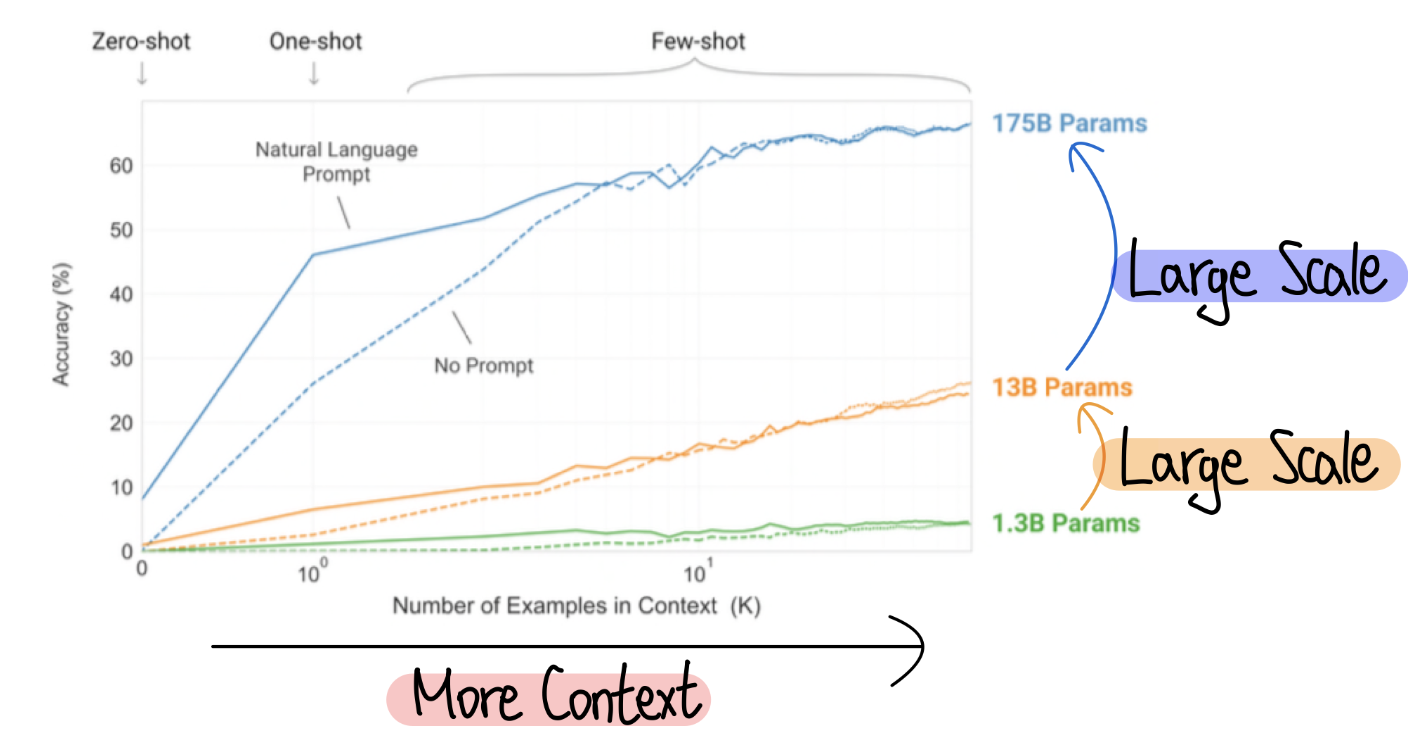
Approach
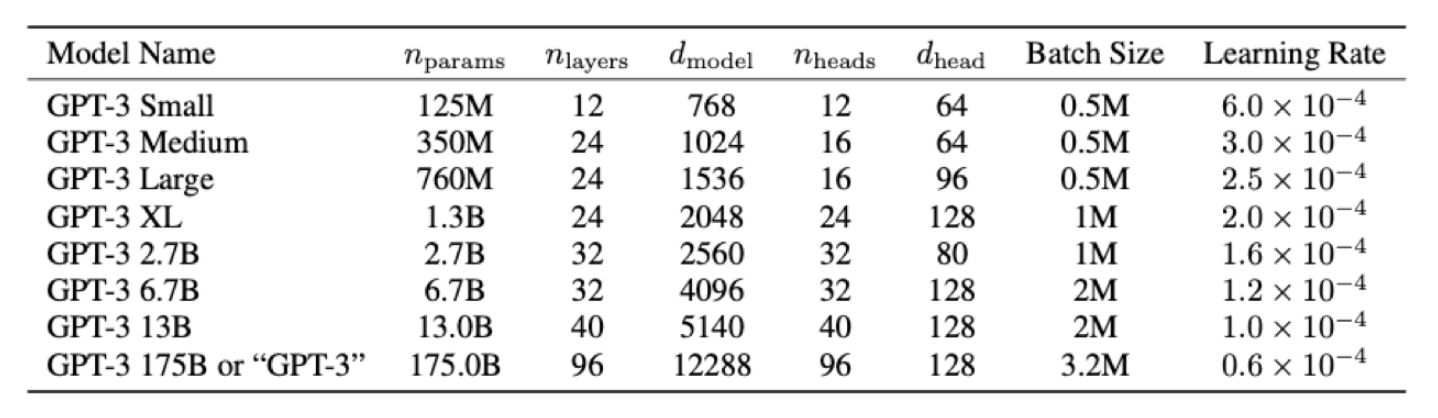
- 기본적으로 GPT-2와 유사한 구조 사용
- 차이점: transformer 레이어 내의 attention 패턴을 dense와 locally banded sparse attention 패턴을 번갈아 사용하여 모델의 효율성 증가
In Context Learning
- Zero shot: 모델이 특정 작업에 대한 사전 학습 예제를 받지 않고, 오직 작업에 대한 설명이나 메타데이터만을 가지고 해당 작업을 수행한다. 예를 들어, 특정 카테고리의 이미지를 분류하는 모델이 그 카테고리의 이미지를 보지 않고 오직 카테고리 설명만을 이용하여 이미지를 분류한다.
- One shot: 모델이 하나의 예제 또는 매우 제한된 데이터로부터 학습하며 그 작업을 수행한다. 예를 들어, 얼굴 인식 시스템에서 특정 인물의 하나의 이미지만을 학습한 후 그 인물을 다른 이미지에서 식별하게 한다.
- Few shot: 모델이 매우 적은 수의 예제(보통 몇 개에서 수십 개 사이)로 학습하는 경우를 말한다. 이는 원샷 학습보다는 더 많은 정보를 제공하지만, 전통적인 머신러닝에서 요구하는 수천 또는 수백만 개의 데이터보다는 훨씬 적다. 예를 들어, 새로운 개체를 인식하기 위해 소수의 사진으로 모델을 훈련시키는 경우가 이에 해당한다.
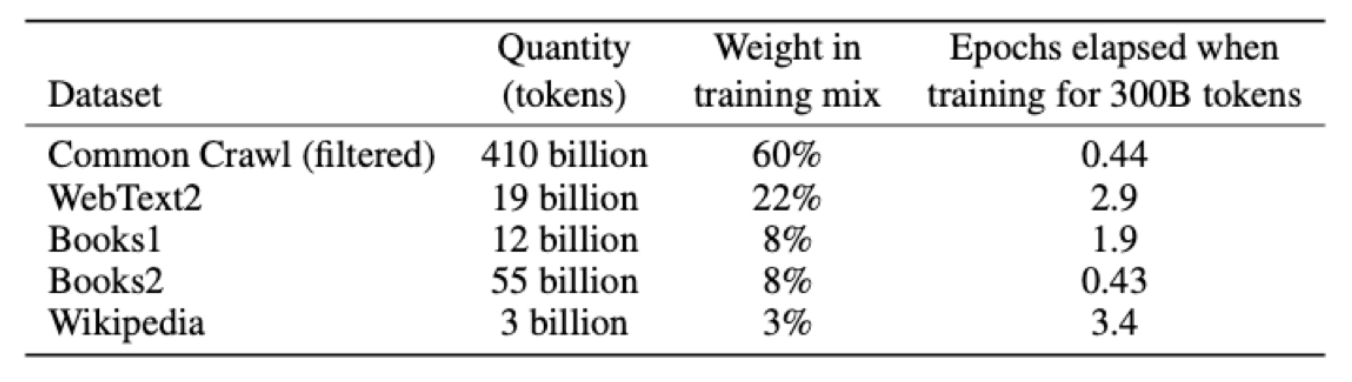
데이터셋
Results
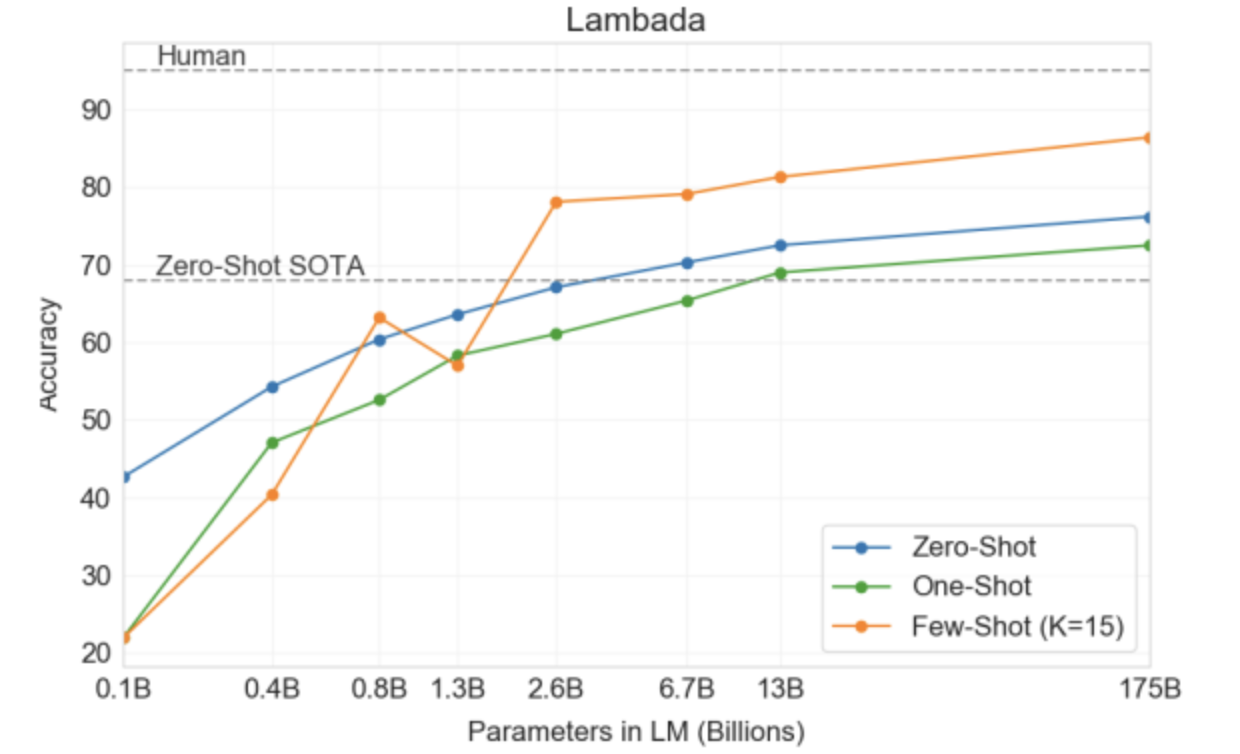
Language Moeling, Cloze, and Completion Tasks
Measuring and Preventing Memorization Of Benchmarks
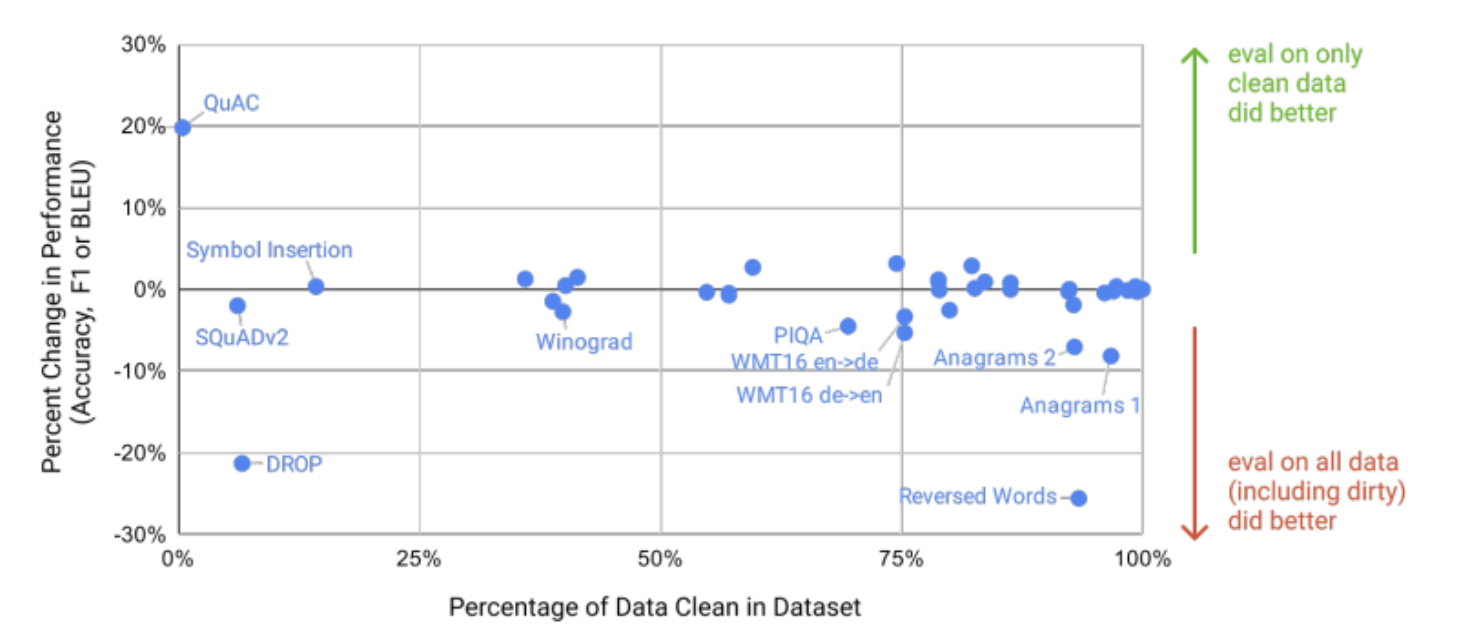
- 큰 모델의 potential memorization risk 평가
- 막대한 데이터 양으로 인해 실제로는 overfitting 최소화
- test set과의 potential contamination 평가를 통해 정량적 결과 제시
Limitations
1) 성능적 한계
- 대부분 다른 모델들에 비해 NLP task 성능 향상이 있었지만, 여전히 어려워하는 task들이 존재
- 물리학 일반 상식 문제에서 성능 좋지 않았음
2) 모델의 구조/알고리즘적 한계
- GPT-3은 in-context learning을 적용하고, bidirectional 구조나 denoising 등의 NLP 분야의 성능을 향상하는 방식 사용하지 않음 (autoregressive 방식으로 학습하고 동작함)
- GPT-3가 약한 모습을 보였던 빈칸 채우기, 두 문단 비교하기, 긴 문단 읽고 답변하기 등의 문제들은 양방향 구조의 LLM들이 강한 면모를 보였음
3) 본질적 한계
- 토큰 예측을 학습하는 방법, 실제 세상에 대한 컨텍스트 부족에 대한 한계
- GPT-3은 인터넷 언어 데이터를 가지고 학습했으므로, 실제 세상과 거리가 있음
- -> GPT-3.5에서는 강화학습을 사용하여 인간의 피드백을 반영하여 더 현실적인 LLM을 제작하고, GPT-4에서는 이미지 등의 다양한 모달리티를 처리할 수 있는 LLM으로 발전
4) 효율성
- 학습을 위해 필요한 방대한 학습 데이터 (논문에서 ‘인간이 평생 보게 될 데이터보다 많은 양’이라고 표현)
5) few-shot setting의 불확실성
- Few shot 세팅에서의 효과 불분명 - Few Shot 세팅의 성능이 좋은 이유를 명확하게 알 수 없음
- GPT-3에서 Few Shot 세팅의 중요성을 강조하고 있고, 앞으로 이를 적극적으로 활용할 것이 분명한 만큼 Few Shot 세팅에서 모델이 어떻게 동작하는 것인지, 왜 성능이 좋아지는 것인지에 대한 명확한 분석이 필요
6) 비용
- 모델의 거대한 사이즈(170B): 학습, 추론 과정에서 엄청난 연산량을 필요로 함
- 논문에서는 Distillation 방식 등 제시
7) 해석 가능성
- 설명력이 떨어진다.
- 새로운 입력에 대한 Calibration이 잘 안됨 -> 사람보다 예측의 분산이 큰 경향이 있음 (동일한 문제에 대한 대답이 매번 바뀜)
Broader Impacts
- 오남용, 편향, 에너지 소모 문제 지적
References
https://velog.io/@lee9843/GPT-3-Language-Models-are-Few-Shot-Learners-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
https://ffighting.net/deep-learning-paper-review/language-model/gpt-3/
