딥러닝 기초
신경망 -> Neural Net
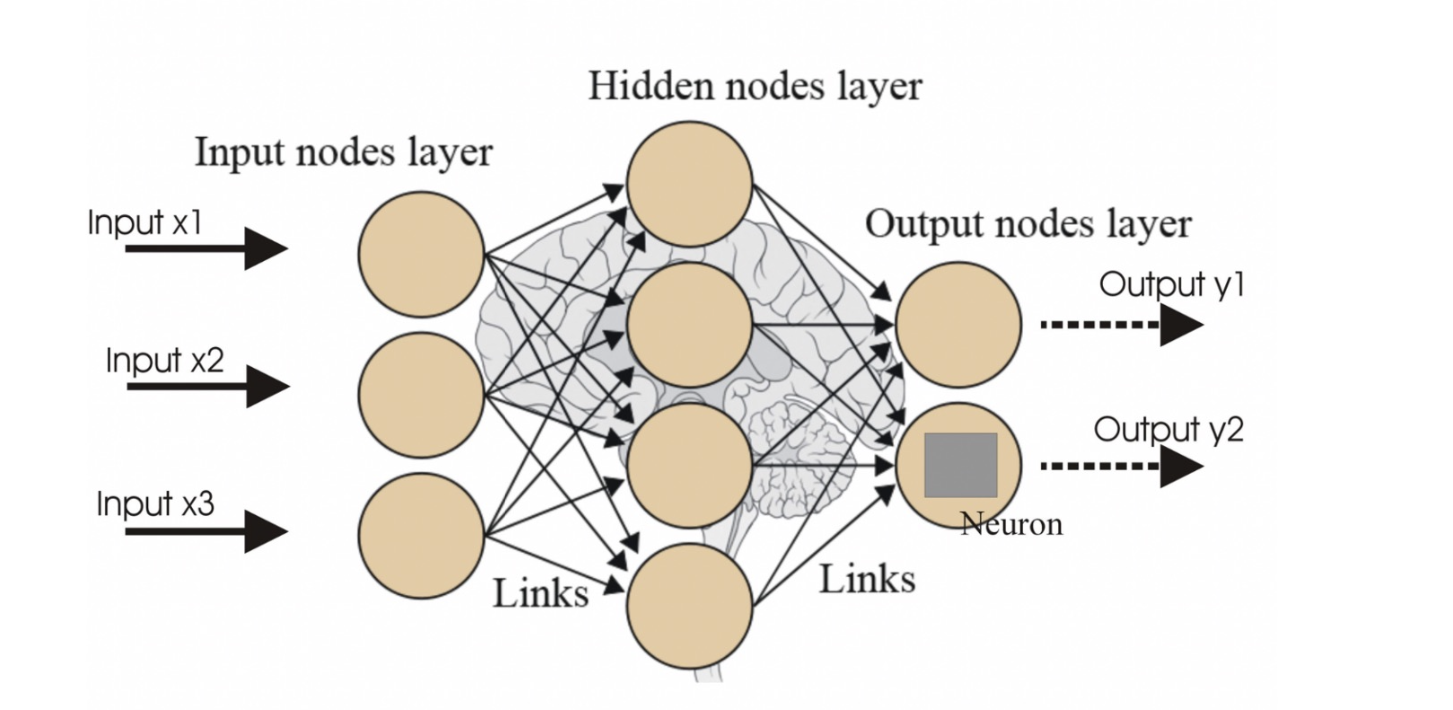
뉴런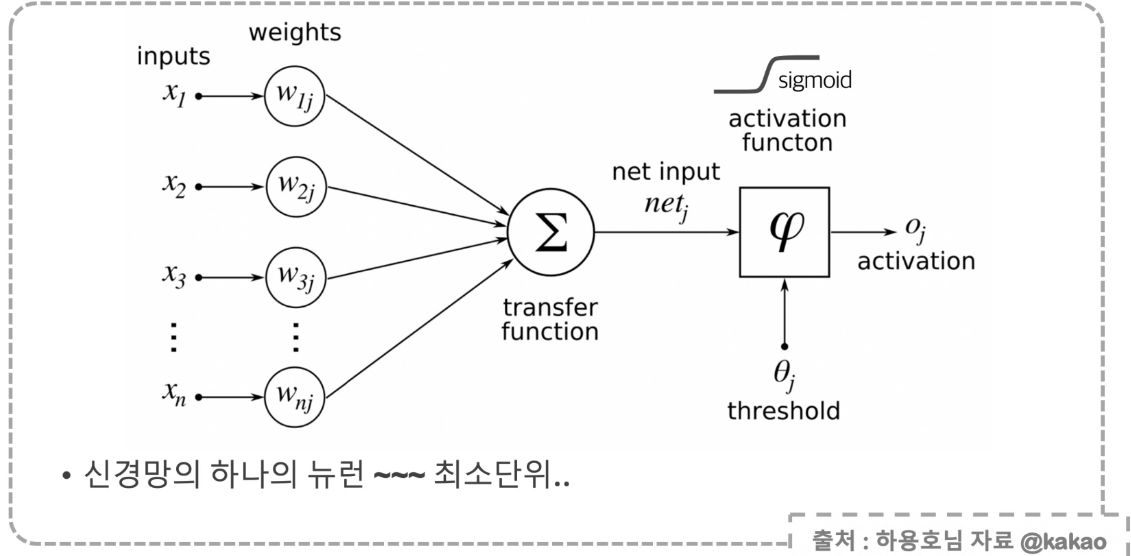
- 뉴런은 입력, 가중치, 활성화함수, 출력으로 구성
- 하나의 뉴런 끝에 activation 붙어있음
- 뉴런에서 학습할 때 변하는 것은 가중치. 처음에는 초기화를 통해 랜덤값을 넣고, 학습과정에서 일정한 값으로 수렴
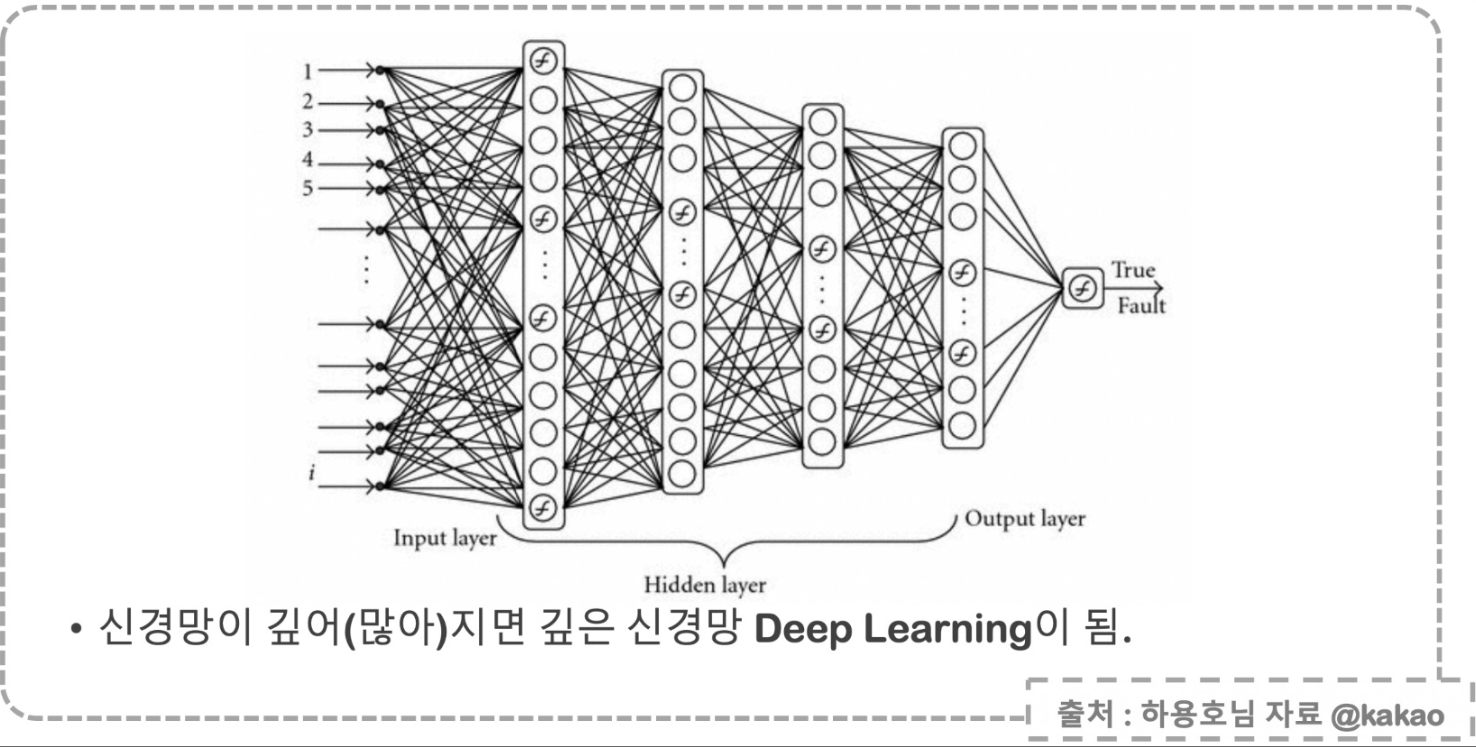
layer, 망(net), 딥러닝
 |  |
|---|
딥러닝 역사
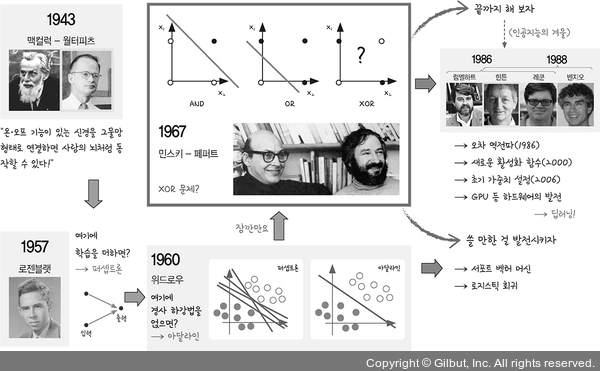
Perceptron, Adaline
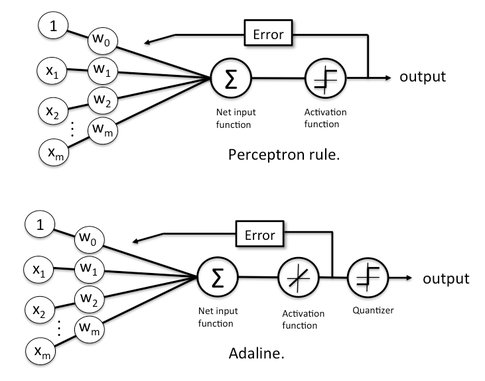 Perceptron (1957): 입력 값을 여러 개 받아 출력을 만듦. 이때 입력 값에 가중치를 조절할 수 있게 하여 최초로 학습을 하게 함.
Perceptron (1957): 입력 값을 여러 개 받아 출력을 만듦. 이때 입력 값에 가중치를 조절할 수 있게 하여 최초로 학습을 하게 함.
Adaline (1960): 퍼셉트론에 경사하강법(gradient descent) 도입
XOR 문제 해결
아달라인 발전 (SVM, 서포트 벡터 머신), 오차 역전파
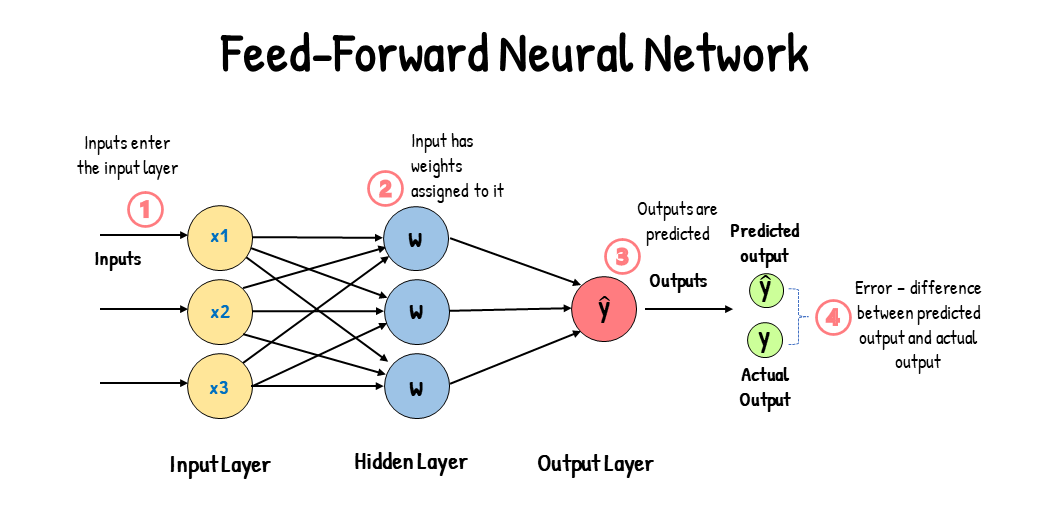
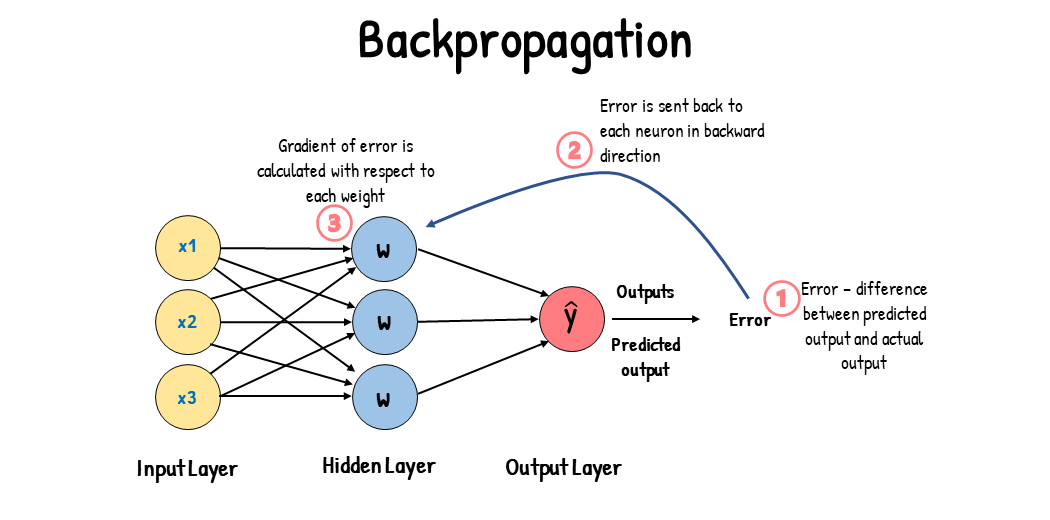
오차 역전파 (1986, back-propagation)
 |  |
|---|
-
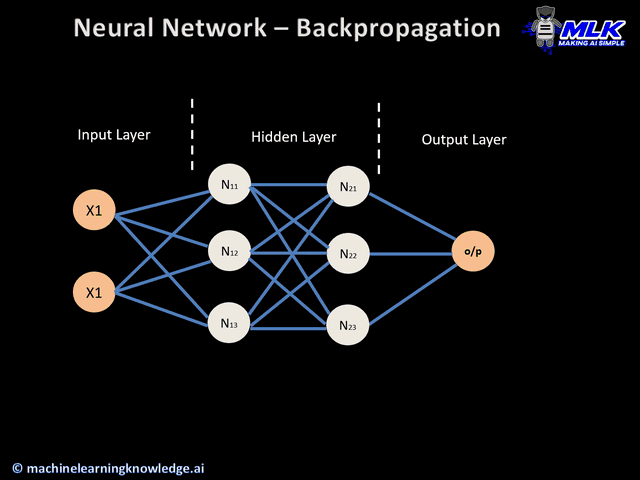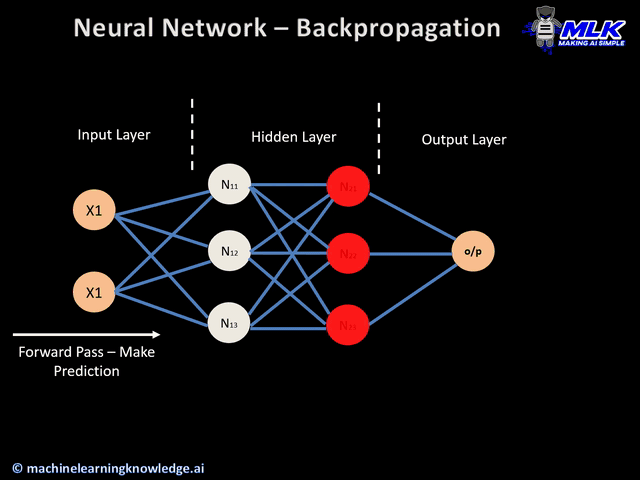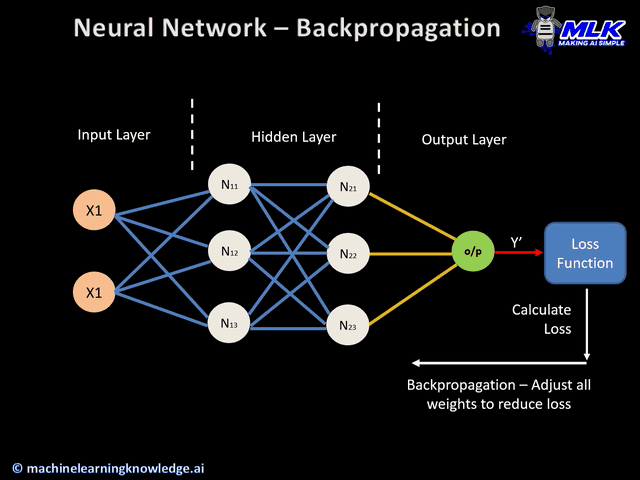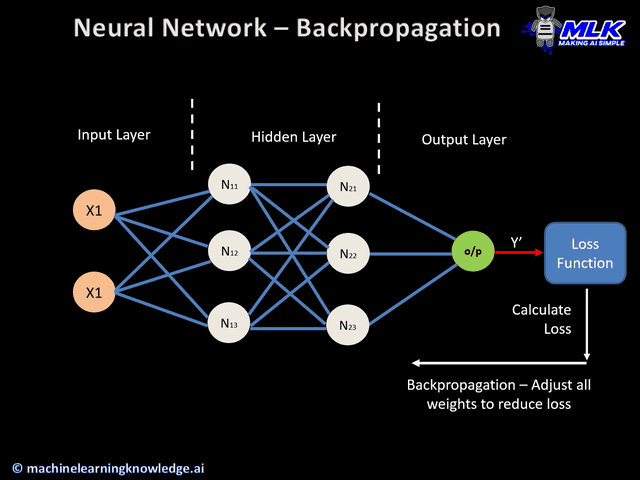
한 번의 순전파
- 각 가중치의 초기값 정해짐
- 초기값의 가중치로 만들어진 값과 실제 값을 비교해 출력층의 오차 게산
-
역전파1: 첫 번째 가중치 수정
-
역전파2: 두 번째 가중치 수정
-
...
활성화 함수, 고급 경사하강법
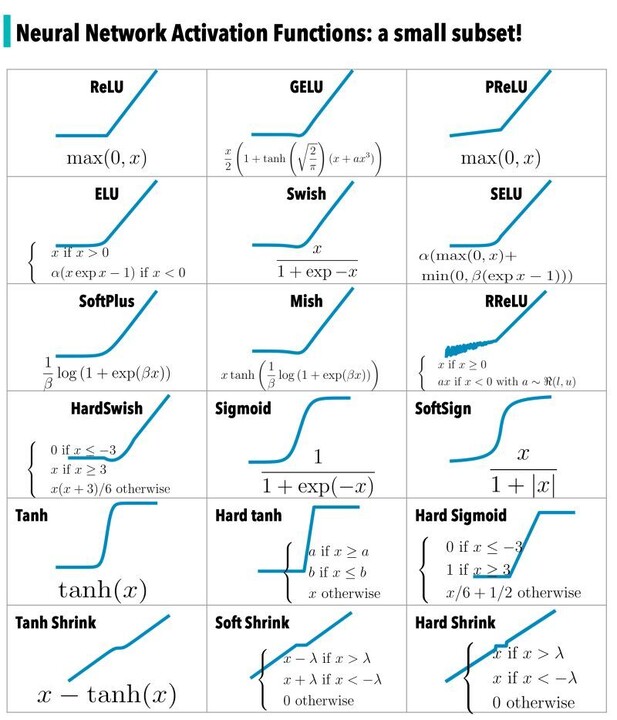
여러 활성화 함수, activation
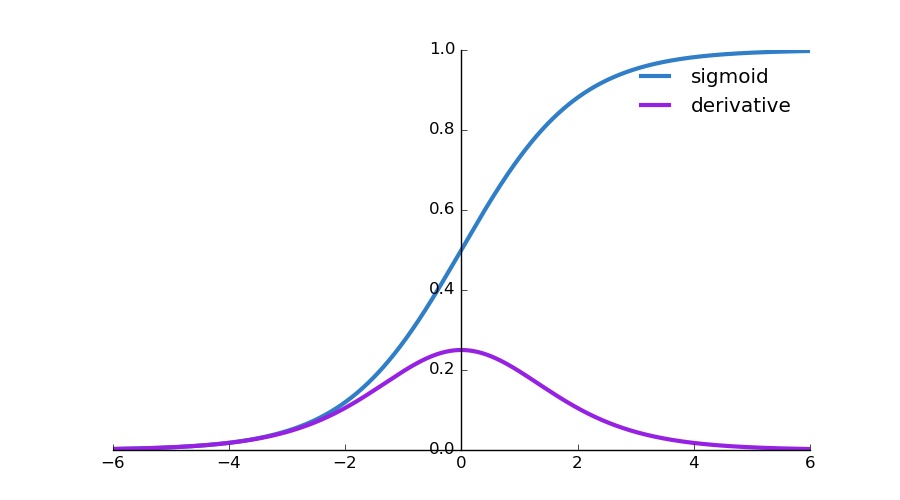
sigmoid 함수의 Vanishing Gradient Problem: 역전파를 진행할수록 점점 기울기가 소실됨.
- 시그모이드를 미분하면 최대치는 0.25 -> 계속 곱하다 보면 0에 가까워짐

고급 경사하강법, optimizer
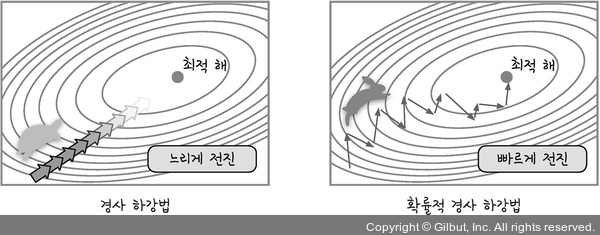
경사하강법: 가중치 업데이트
--> loss function의 현 가중치에서의 기울기(gradient)를 구해서 loss를 줄이는 방향으로 업데이트. 경사하강법은 한 번 업데이트할 때마다 전체 데이터를 미분하므로 속도가 느림 & 최적 해를 찾기 전에 최적화 과정이 멈출 수도 있음
-
확률적 경사하강법 (Stochastic Gradient Descent, SGD)
보폭 조정 - 랜덤하게 추출한 일부 데이터만 사용하여 빠르고, 더 자주 업데이트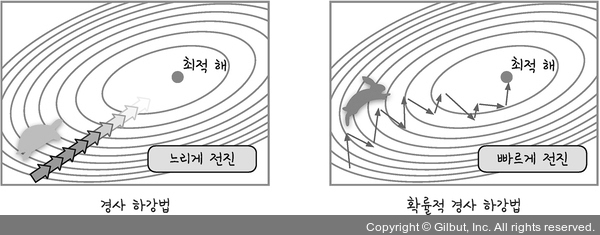
-
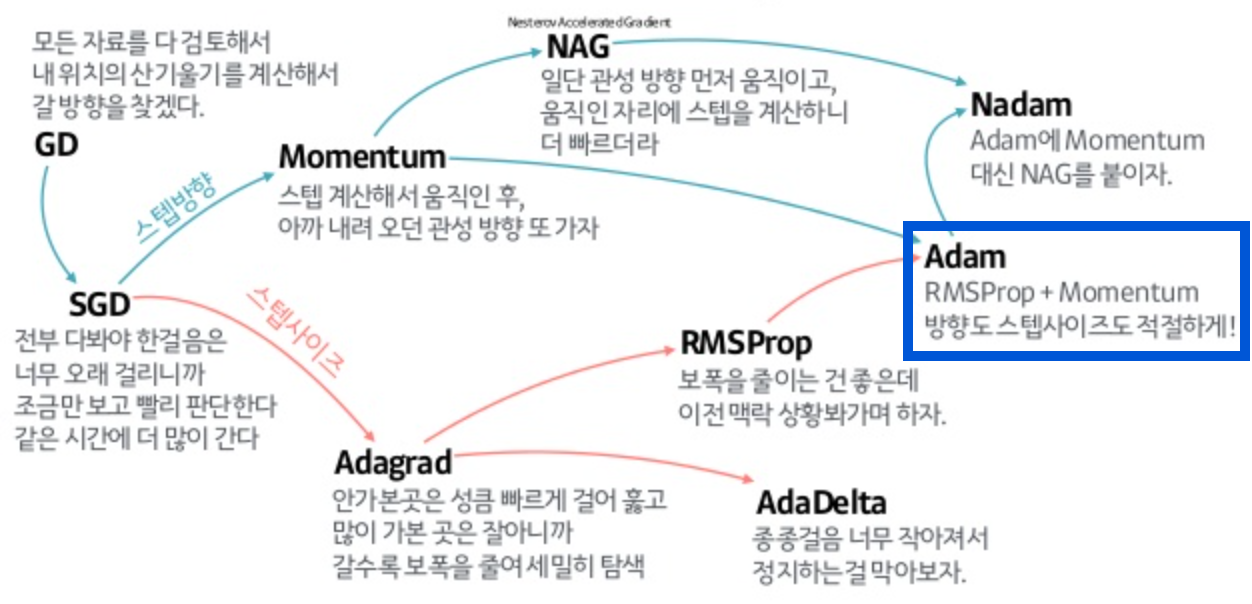
모멘텀 (momentum)
방향 조정 - 오차를 수정하기 전 바로 앞 수정 값과 방향(+, -)을 참고해 같은 방향으로 일정한 비율만 수정.
softmax
뉴럴넷에게 답을 회신받는 3가지 방법
- Value: output 그냥 받음
- O/X: output & sigmoid
- Category: output & softmax
출처: 모두의 딥러닝, https://www.analyticsvidhya.com/blog/2023/01/gradient-descent-vs-backpropagation-whats-the-difference/
https://medium.com/@tensorashish/activate-that-ai-for-success-46a71b4fab0b
https://www.linkedin.com/posts/danleedata_which-activation-function-do-you-use-often-activity-7124783582253846528-3MMa/
