출처: 모두의 딥러닝
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense- from (라이브러리) import (함수)
- from tensorflow.keras.models import Sequential
- tensorflow: 라이브러리
- keras: API
- model: 클래스
- Sequential(): 함수
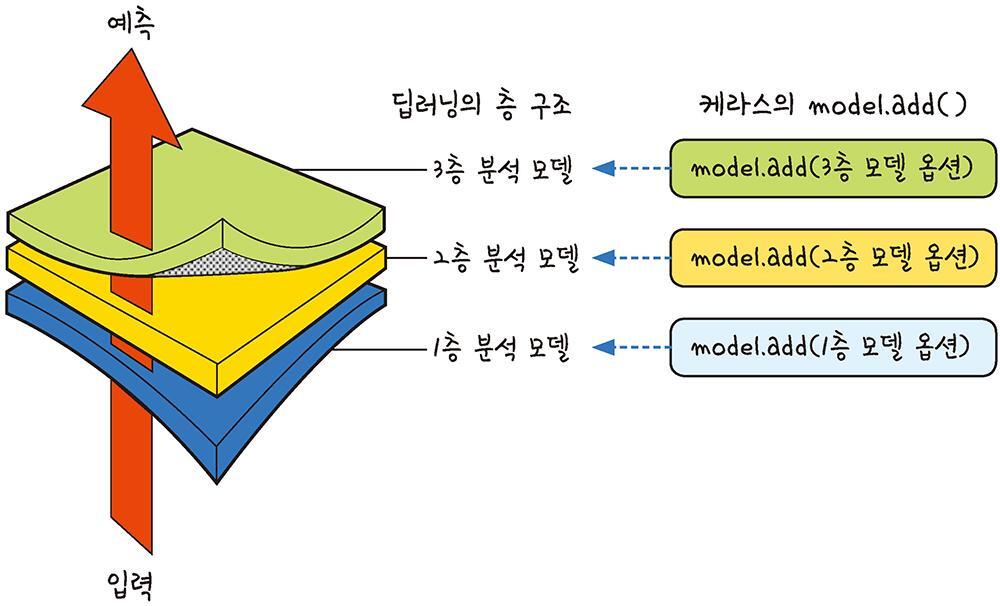 딥러닝의 층 구조
딥러닝의 층 구조
(출처: 모두의 딥러닝)
딥러닝 개괄하기
1. 환경 준비
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import numpy as np딥러닝을 구동하거나 데이터를 다루는 데 필요한 라이브러리들을 불러온다.
2. 데이터 준비
!git clone https://~~~/data.git
Data_set = np.loadtxt('./data/~~~.csv', delimiter=',')
X = Data_set[:, 0:16]
y = Data_set[:, 16]준비된 수술 환자 정보 데이터를 나의 구글 코랩 계정에 저장한다. 환자 상태의 기록에 해당하는 부분을 X로, 수술 1년 후 사망/생존 여부를 y로 지정한다.
3. 구조 결정
model = Sequential()
model.add(Dense(30, input_dim=16, activation='relu))
model.add(Dense(1, activation='sigmoid'))딥러닝 모델의 구조를 결정
4. 모델 실행
model.compile(loss='binary_crossentropy',
optimizer='adam', metrics=['accuracy'])
history = model.fit(X, y, epochs=5, batch_size=16)딥러닝 모델을 실행
🚀 회귀 분석
📘 선형회귀 (linear regression)
활성화 함수
linear: 입력값에 대해 아무런 변환을 가하지 않고 그대로 출력. (f(x) = x)오차함수
평균 제곱 계열
Mean Squared Error (MSE, 평균 제곱 오차)
- 예측값과 실제값 간의 차이의 제곱 평균 계산.
- 연속적인 값을 예측하는데에 적합
Mean Absolute Error (MAE, 평균 절대값 오차)
- 예측값과 실제값의 절대값 차이의 평균을 계산.
- 이상치에 덜 민감한 특성
Mean Absolute Percentage Error (MAPE, 평균 절대 백분율 오차)
- 절대값 오차를 절대값으로 나눈 후 평균
Mean Squared Logarithmic Error (MSLE, 평균 제곱 로그 오차)
- 실제 값과 예측 값에 로그를 적용한 값의 차이를 제곱한 값의 평균
단순선형회귀 (Simple Linear Regression)
import numpy as np
import matplotlib.pyplot as plt
# 텐서플로의 케라스 API에서 필요한 함수들을 불러옴
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
x = np.array([2, 4, 6, 8])
y = np.array([81, 93, 91, 97])
model = Sequential()
# 출력 값, 입력 변수, 분석 방법에 맞게끔 모델 설정
model.add(Dense(1, input_dim=1, activation='linear'))
# 오차 수정을 위해 경사하강법(sgd)을, 오차의 정도를 판단하기 위해
# 평균 제곱 오차(mse)를 사용
model.compile(optimizer='sgd', loss='mse')
# 오차를 최소화하는 과정을 2000번 반복
model.fit(X, y, epochs=2000)
plt.scatter(x, y)
plt.plot(x, model.predict(x), 'r')
plt.show() # 예측 결과를 그래프로 나타냄
# 임의의 변수를 넣어 결과 예측
hour = 7
prediction = model.predict([hour])다중선형회귀 (Multiple Linear Regression)
import numpy as np
import matplotlib.pyplot as plt
# 텐서플로의 케라스 API에서 필요한 함수들을 불러옴
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
x = np.array([2, 4, 6, 8])
y = np.array([81, 93, 91, 97])
model = Sequential()
# 입력 변수가 2개이므로 input_dim=2
model.add(Dense(1, input_dim=2, activation='linear'))
model.compile(optimizer='sgd', loss='mse')
model.fit(X, y, epochs=2000)
# 임의의 변수를 넣어 결과 예측
hour = 7
private_class = 4
prediction = model.predict([[hour, private_class]])📘 로지스틱 회귀 (logistic regression)
활성화 함수
Sigmoid
- 입력값을 받아 출력값을 0과 1사이의 값으로 제한
- 이진 분류 모델에 주로 사용, 결과값을 확률로 해석
Softmax
- 다중 클래스 분류 문제에서 사용
- 클래스 별 확률을 출력하여, 총합이 1이 되도록 함
오차함수
Binary Cross-Entropy (이진 교차 엔트로피)
- 이진 분류(이항 분류)에서 사용
- 실제 값과 예측 값의 차이 계산
Categorical Cross-Entropy (범주형 교차 엔트로피)
- 다중 클래스 분류(다항 분류) 문제에서 사용
- 실제 클래스 레이블과 예측 확률 간의 차이 계산
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
x = np.array([2, 4, 6, 8, 10, 12, 14])
y = np.array([0, 0, 0, 1, 1, 1, 1])
model = Sequential()
model.add(Dense(1, input_dim=1, activation='sigmoid')
# 교차 엔트로피 오차 함수를 이용하기 위해 'binary_crossentropy' 설정
model.compile(optimizer='sgd', loss='binary_crossentropy')
model.fit(x, y, epochs=5000)
# 그래프 확인
plt.scatter(x, y)
plt.plot(x, model.predict(x), 'r')
plt.show()
# 예측
hour = 7
prediction = model.predict([hour])