[ML] Model Evaluation
모델 평가
- 회귀모델은 실제 값과의 에러치를 가지고 계산(간단)
- 분류 모델은 평가 항목 많음(정확도, 오차행렬, 정밀도, 재현율, F1 score, ROC AUC)
이진 분류 모델의 평가
- TP, FN, TN, FP
- 1종 오류(FP), 2종 오류(FN)
Accuracy, Precision, Recall, Fall-out
-
Accuracy
- TP + TN / 전체
-
Precision
- TP / (TP + FP)
- : 양성이라고 예측한 것 중 실제 양성의 비율
- 스팸메일 - 스팸이라고 예측한 것 중 스팸메일이 아닌 게 있으면 안됨
-
Recall 재현율, sensitivity, TPR(True Positive Ratio)
- : 실제 양성인 데이터 중 양성이라고 예측
- 암환자 예측시 중요 - 놓치면 안됨
-
Fall-out
- FP / (FP + TN)
분류모델: 그 결과에 속할 비율(확률) 반환
-
threshold
-
ex. threshold 0.3: 전부 암환자
-
recall 과 precision은 서로 영향을 줌.
F1-Score
- 조화평균
- F1-score는 recall과 precision을 결합한 지표
- recall 과 precision이 어느 한쪽으로 치우치지 않고 둘 다 높은 값 가지면 높은 값
ROC, AUC
- ROC 곡선: FPR(Fall-out) 이 변할 때 TPR(Recall) 의 변화를 그린 그림
- AUC: ROC 곡선 아래 면적, 1에 가까울수록 좋음
ROC 커브 그려보기
import pandas as pd
white_url = "https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-white.csv"
red_url = "https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/winequality-red.csv"
red_wine = pd.read_csv(red_url, sep=';')
white_wine = pd.read_csv(white_url, sep=';')
red_wine['color'] = 1
white_wine['color'] = 0
wine = pd.concat([red_wine, white_wine])
wine['taste'] = [1. if grade>5 else 0. for grade in wine['quality']]
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']
# DT
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
y_pred_tr = wine_tree.predict(X_train)
y_pred_test = wine_tree.predict(X_test)
print('Train Acc: ', accuracy_score(y_train, y_pred_tr))
print('Test Acc: ', accuracy_score(y_test, y_pred_test))
Train Acc: 0.7294593034442948
Test Acc: 0.7161538461538461
# 각 수치 구해보기
from sklearn.metrics import accuracy_score, precision_score
from sklearn.metrics import recall_score, f1_score
from sklearn.metrics import roc_auc_score, roc_curve
print('Accuracy: ', accuracy_score(y_test, y_pred_test))
print('Recall: ', recall_score(y_test, y_pred_test))
print('Precision: ', precision_score(y_test, y_pred_test))
print('AUC score: ', roc_auc_score(y_test, y_pred_test))
print('F1 score: ', f1_score(y_test, y_pred_test))Accuracy: 0.7161538461538461
Recall: 0.7314702308626975
Precision: 0.8026666666666666
AUC score: 0.7105988470875331
F1 score: 0.7654164017800381
# ROC curve
import matplotlib.pyplot as plt
%matplotlib inline
pred_prob = wine_tree.predict_proba(X_test)[:, 1] # [0일 확률, 1일 확률] 에서 1일 확률 추출
fpr, tpr, thresholds = roc_curve(y_test, pred_prob)plt.figure(figsize=(10, 8))
plt.plot([0,1], [0,1], 'c', ls='dashed') # 대각선 직선 (0, 0) 부터 (1, 1)
plt.plot(fpr, tpr, 'r')
plt.grid()
plt.show()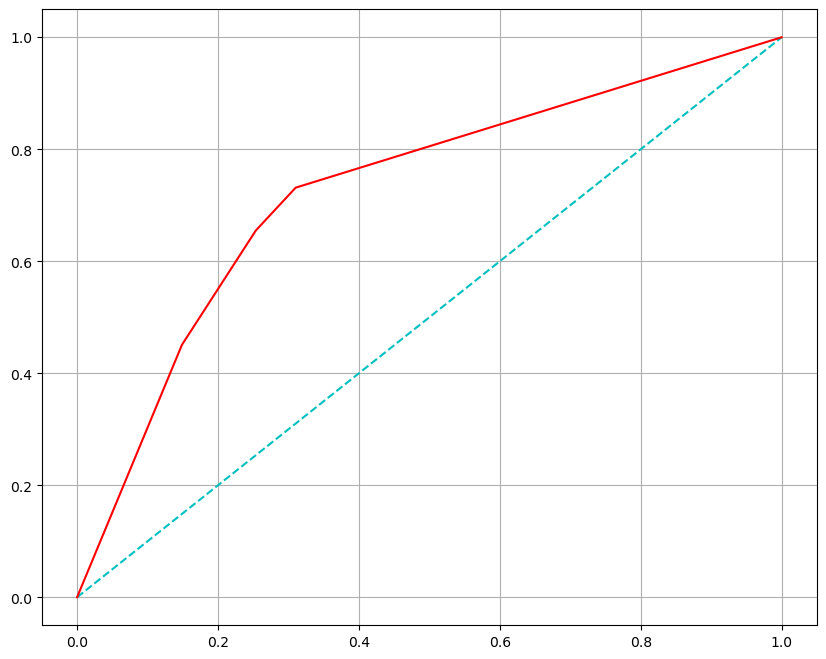
시그모이드 Sigmoid
- 0, 1 사이 값 가짐, 0, 1에 수렴
z = np.linspace(-10, 10, 100)
sigma = 1/(1+np.exp(-z))
plt.figure(figsize=(12, 8))
plt.plot(z, sigma)
plt.xlabel('$z$', fontsize=25)
plt.ylabel('$\sigma(z)$', fontsize=25)
plt.show()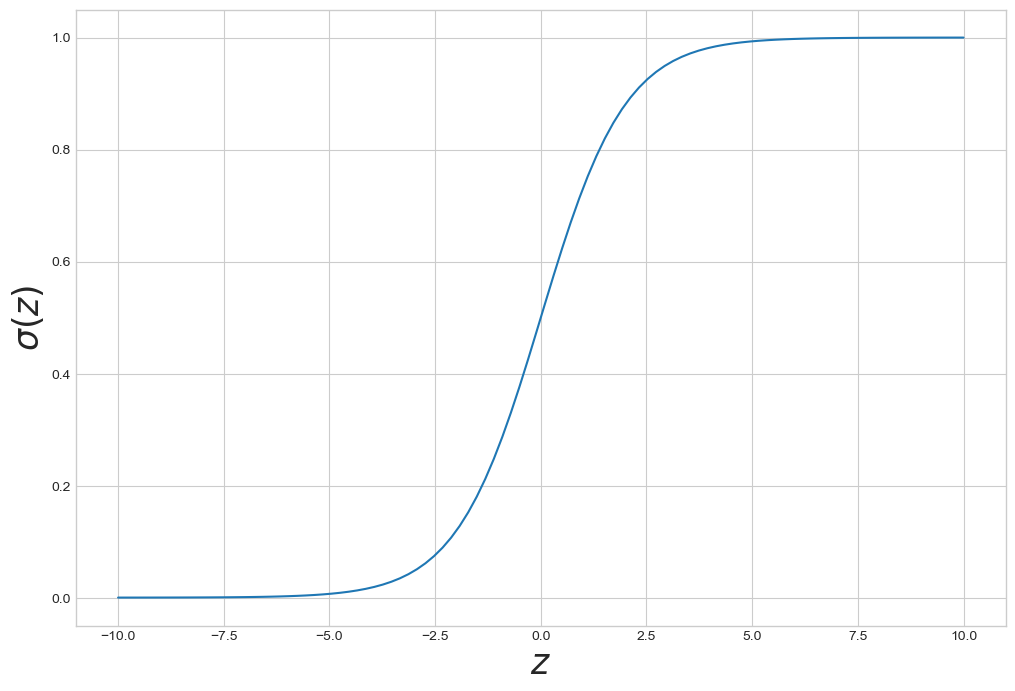
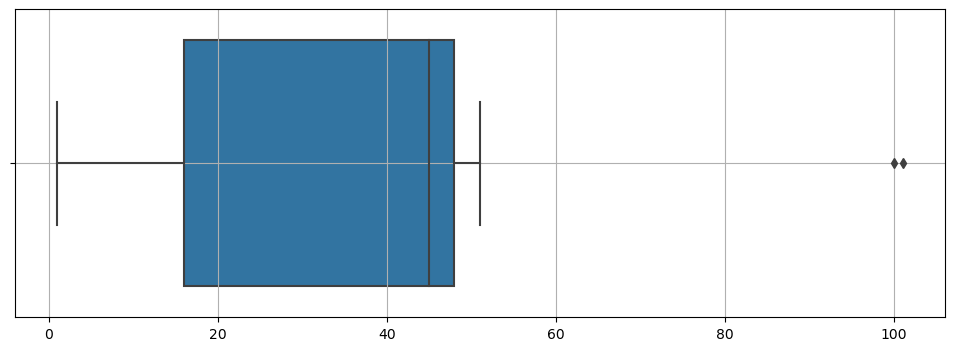
box plot
samples = [1, 7, 9, 16, 36, 39, 45, 45, 46, 48, 51, 100, 101]
tmp_y = [1]*len(samples)import matplotlib.pyplot as plt
import numpy as np
plt.figure(figsize=(12, 4))
plt.scatter(samples, tmp_y)
plt.show()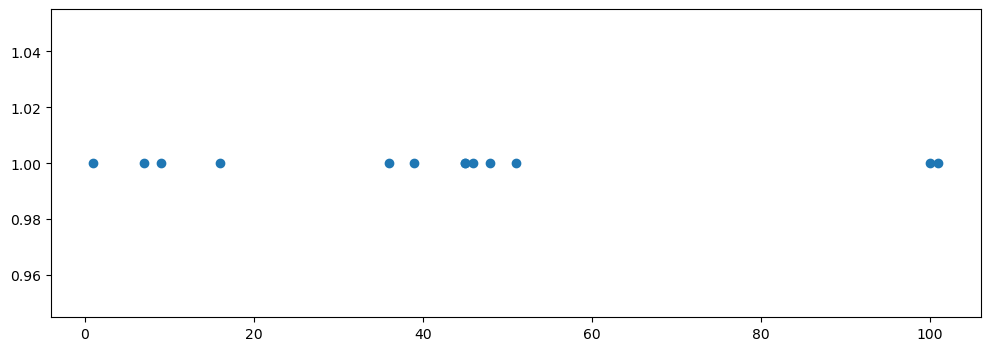
# IQR
np.percentile(samples, 75) - np.percentile(samples, 25)
# 그리기
q1 = np.percentile(samples, 25)
q2 = np.median(samples)
q3 = np.percentile(samples, 75)
iqr = q3 - q1
upper_fence = q3 + iqr*1.5
lower_fence = q1 - iqr*1.5
# box plot 그리기
plt.figure(figsize=(12, 4))
plt.scatter(samples, tmp_y)
plt.axvline(x=q1, color='black')
plt.axvline(x=q2, color='red')
plt.axvline(x=q3, color='black')
plt.axvline(x=upper_fence, color='black', ls='dashed')
plt.axvline(x=lower_fence, color='black', ls='dashed')
plt.grid()
plt.show()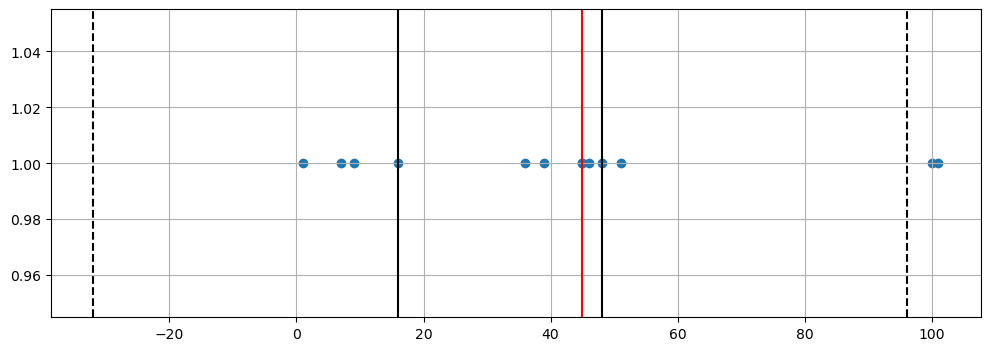
# framework 으로 그리기
import seaborn as sns
plt.figure(figsize=(12, 4))
sns.boxplot(x=samples)
plt.grid()
plt.show()