MNIST 손글씨 인식하기
- 데이터 전처리
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
import sys
# MNIST 데이터셋을 불러와 학습셋과 테스트셋으로 저장
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 학습셋과 테스트셋이 각각 몇 개의 이미지로 되어 있는지 확인
print('학습셋 이미지 수: %d개' % (X_train.shape[0]))
print('테스트셋 이미지 수: %d개' % (X_test.shape[0]))
# 첫 번째 이미지 확인
plt.imshow(X_train[0], cmap='Greys')
plt.show()
# 이미지가 인식되는 원리 알아봄
for x in X_train[0]:
for i in x:
sys.stdout.write('%-3s' % i)
sys.stdout.write('\n')
# 차원 변환 과정
X_train = X_train.reshape(X_train.shape[0], 784).astype('float64') / 255
# 클래스 값 확인
print('class: %d' % (y_train[0]))
# 바이너리화 - 0~9의 정수형 값을 갖는 형태에서 0또는 1로만 이루어진 벡터로 값 수정
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
print(y_train[0])학습셋 이미지 수: 60000개
테스트셋 이미지 수: 10000개
- 딥러닝 모델 - 기본 프레임
- 총 784개의 속성, 10개의 클래스
- 입력 값(input_dim)이 784개, 은닉층이 512개, 출력이 10개
- 활성화 함수로 은닉층에서
relu, 출력층에서softmax - 딥러닝 실행 환경을 위해 오차 함수로
categorical_crossentropy, 최적화 함수로adam사용
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
import numpy as np
import os
# MNIST 데이터 불러옴
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 차원 변환 후, 테스트셋과 학습셋으로 나눔
X_train = X_train.reshape(X_train.shape[0], 784).astype('float32') / 255
X_test = X_test.reshape(X_test.shape[0], 784).astype('float32') / 255
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
# 모델 구조 설정
model = Sequential()
model.add(Dense(512, input_dim=784, activation='relu'))
model.add(Dense(10, activation='softmax'))
# 모델 실행 환경 설정
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 모델 최적화
MODEL_DIR = './model/'
if not os.path.exists(MODEL_DIR):
os.mkdir(MODEL_DIR)
modelpath = './MNIST_MLP.hdf5'
checkpointer = ModelCheckpoint(filepath=modelpath, mointor='val_loss', verbose=1, save_best_only=True)
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=10)
# 모델 실행
history = model.fit(X_train, y_train, validation_split=0.25, epochs=30, batch_size=200, verbose=0,
callbacks=[early_stopping_callback, checkpointer])
# 테스트 정확도 출력
print('\n Test Accuracy: %.4f' % (model.evaluate(X_test, y_test)[1]))
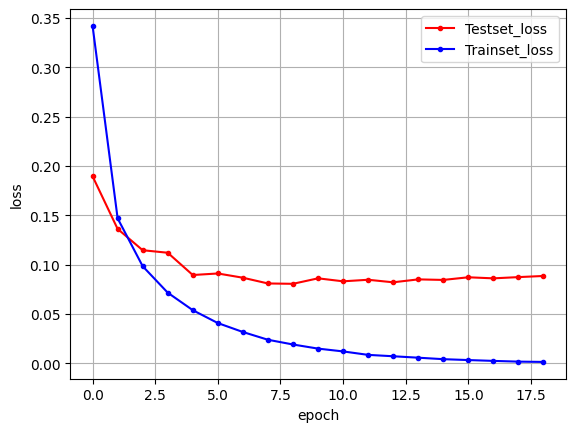
# 검증셋과 학습셋의 오차 저장
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
# 그래프로 표현
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c='red', label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c='blue', label='Trainset_loss')
# 그래프에 그리드를 주고 레이블을 표시
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()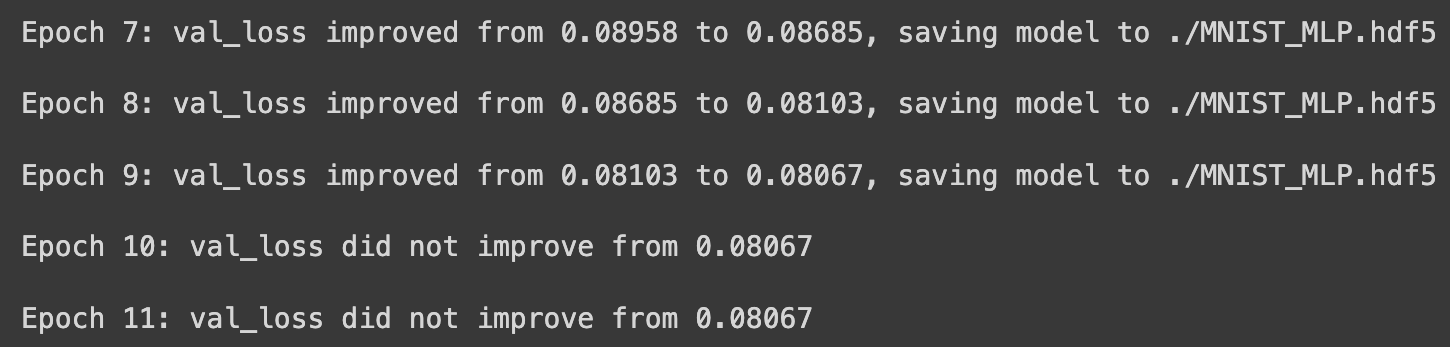
MNIST 손글씨 인식하기 - CNN 적용
CNN
- 컨볼루션 신경망
- 입력된 이미지에서 다시 한 번 특징을 추출하기 위해 커널(슬라이딩 윈도)을 도입
- keras에서 컨볼루션 층을 추가하는 함수: Conv2D
📍 Conv2d()
model.add(Conv2D(32, kernel_size=(3,3), input_shape=(28,28,1), activation='relu'))- 첫 번쨰 인자: 커널을 몇 개 적용할지 정함. 여기서는 32개의 커널
- kernel_size: 커널의 크기,
kernel_size=(행, 열). 여기서는 3x3 크기의 커널. - input_shape: Dense 층과 마찬가지로 맨 처음 층에는 입력되는 값을 알려주어야 함.
input_shape=(행, 열, 색상(3) 또는 흑백(1)). 여기서는 28x28 크기의 흑백 이미지. - activation: 사용할 활성화 함수를 정의함.
이어서 열결:
model.add(Conv2D(64, (3, 3), activation='relu'))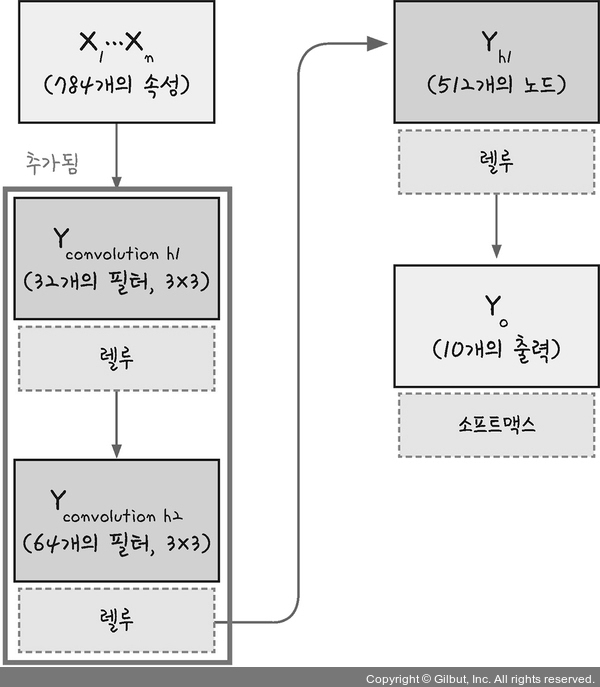
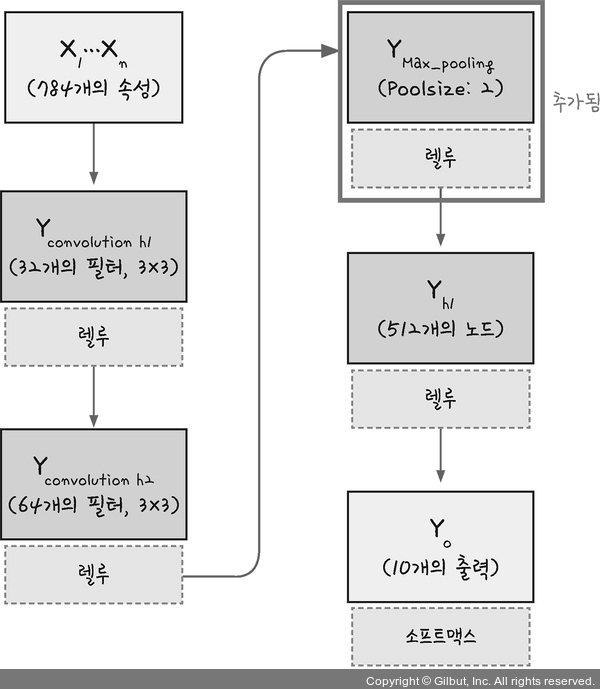
📍 max pooling
max pooling: 정해진 구역 안에서 최댓값을 뽑아냄
average pooling: 정해진 구역의 평균값을 뽑아냄
model.add(MaxPooling2D(pool_size=(2, 2)))- pool_size = 풀링 창의 크기. 여기서는 (2x2) 크기의 풀링 창을 통해 max pooling 진행
📍 dropout
dropout: 은닉층에 배치된 노드 중 일부를 임의로 꺼줌. 과적합 방지.
model.add(Dropout(0.25))- 25%의 노드 끄기
📍 flatten
- convolution 층이나 max pooling 층은 주어진 이미지를 2차원 배열인 채로 다룸. 이를 1차원 배열로 바꿔줘야만 활성화 함수가 있는 층에서 사요할 수 있음. 따라서 Flatten() 함수로 2차원 배열을 1차원 배열로 바꿔줌.
model.add(Flatten())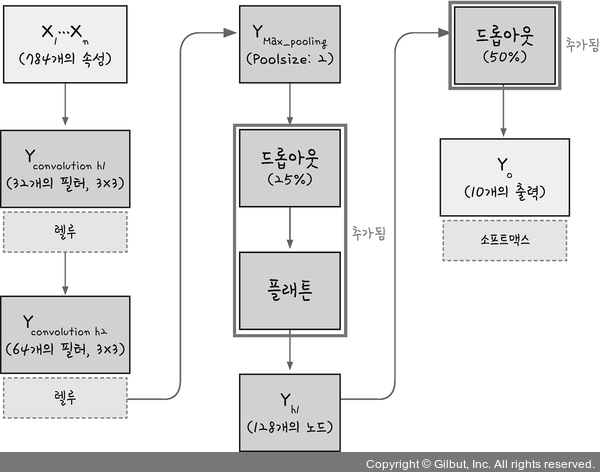
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
import numpy as np
import os
# 데이터 불러옴
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float') / 255
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1).astype('float') / 255
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# 컨볼루션 신경망의 설정
model = Sequential()
model.add(Conv2D(32, kernel_size=(3,3), input_shape=(28,28,1), activation='relu'))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
# 모델의 실행 옵션 설정
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 모델 최적화를 위한 설정 구간
MODEL_DIR = './model/'
if not os.path.exists(MODEL_DIR):
os.mkdir(MODEL_DIR)
modelpath = './MNIST_CNN.hdf5'
checkpointer = ModelCheckpoint(filepath=modelpath, mointor='val_loss', verbose=1, save_best_only=True)
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=10)
# 모델 실행
history = model.fit(X_train, y_train, validation_split=0.25, epochs=30,
batch_size=200, verbose=0, callbacks=[early_stopping_callback, checkpointer])
# 테스트 정확도 출력
print('\n Test Accuracy: %.4f' % (model.evaluate(X_test, y_test)[1]))
# 검증셋과 학습셋의 오차를 저장
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
# 그래프로 표현
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c='red', label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c='blue', label='Trainset_loss')
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()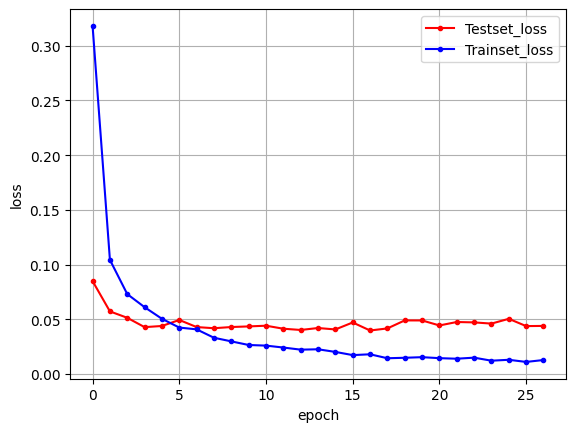
- 오차 작아짐.
