1. 상용로그의 뜻
기본적으로 숫자에서 10진법을 사용하는 것처럼, 밑이 10인 로그를 일상적으로 많이 사용하는 로그라고 하여 '상용로그'라고 하고 밑은 생략해도 된다는 것이다.
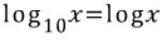
2. 진수에 따른 상용로그의 값
일반적으로 상용로그의 값이란 'y=logx'라고 해석한다면 x가 a일때 y값이 상용로그의 값이라고 생각하면 된다.

반면 10의 거듭제곱이 아닌 꼴이 상용로그의 진수가 되면 상용로그의 값은 정수가 아닌 무리수가 나오게 된다.
예를 들어 248에 상용로그를 취하여 log248을 만들면 그 값은 대략 2.XXXX이 나오게 되며 log248 = 2.XXXX 과 같이 나타낸다.
상용로그를 예측하는 방법
248은 10의 거듭제곱 중에서 100과 1000 사이의 수이다.
즉, 100 < 248 < 1000이다.
부등식에서 세 변에 상용로그를 취하면
log100 < log248 < log1000이며 그 값을 로그의 성질에 의해서 구하면
2 < log248 < 3 이므로
log248 = 2.XXXX...인 것을 볼 수 있다.
***로그란 지수를 다른 방법으로 표현한 것입니다.

3. 데이터 분석 시 로그를 사용하는 이유?
데이터 분석을 하기 위해 log를 취하는 이유는 한마디로 정규성을 높이고 분석(회귀분석 등)에서 정확한 값을 얻기 위함이다.
데이터 간 편차를 줄여 왜도(skewness-데이터가 한쪽으로 치우친 정도)와 첨도2(Kurtosis-분포가 얼마나 뾰족한지를 나타내는 정도)를 줄일 수 있기 때문에 정규성이 높아진다.
예를 들어, 연령 같은 경우에는 숫자의 범위가 약 0세~120세 이하 이겠지만, 재산 보유액 같은 경우에는 0원에서 몇 조단위까지 올라갈 수 있다. 즉, 데이터 간 단위가 달라지면 결과값이 이상해 질 수 있다.
log의 역할은 큰 수를 같은 비율의 작은 수로 바꿔 주는 것이다.
log는 큰 수를 작게 만들고 복잡한 계산을 간편하게 하기위해 사용한다. 로그를 취하는 순간 그 수는 지수가 되어버리니, 값이 작아 진다.
예를 들어, 100=102이다.
100에 상용로그를 취한다면 100을 10을 밑으로 하는 지수가 있는 값의 그 지수로 나타낸다. 그래서 100에 상용로그를 취하면 2 가 된다. ->log102
또한 로그를 취하면 로그의 성질에 의해 곱하기가 더하기로, 나누기가 빼기로 바뀐다.
결론적으로 식에 로그릴 취하는 이유는 큰 수를 작게 만들고, 복잡한 계산을 쉽게 만들고, 왜도와 첨도를 줄여서 데이터 분석 시 의미있는 결과를 도출하기 위한 것이다.
위의 재산 보유액 예와 같이 분석하려는 데이터 간의 편차가 큰 경우에 로그를 취하면 의미있는 결과를 얻을 가능성이 높아진다.
아래 차트와 같이, 로그를 취하면 큰 값은 작아지는 것을 볼 수 있다.
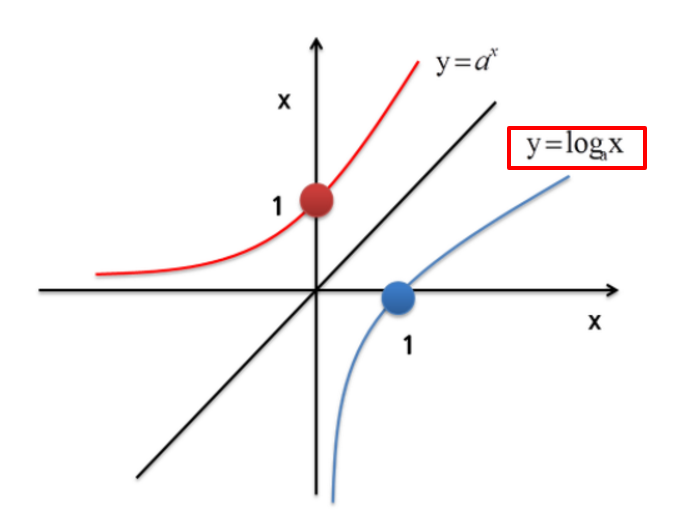
출처 :
https://leebaro.tistory.com/entry/%EB%8D%B0%EC%9D%B4%ED%84%B0-%EB%B6%84%EC%84%9D-%EC%8B%9C-%EC%8B%9D%EC%97%90-%EB%A1%9C%EA%B7%B8%EB%A5%BC-%EC%B7%A8%ED%95%98%EB%8A%94-%EC%9D%B4%EC%9C%A0
https://blog.naver.com/parbo/220602805699
http://www.studycode.net/bbs2/read.htm?cate_sub_idx=&cate_sub_idx2=&iframe_use=&list_mode=board&code=36&keyfield=&key=&page=282&side=1&lecture_yn=&idx=20484
http://blog.naver.com/PostView.nhn?blogId=istech7&logNo=50154573592
http://blog.naver.com/PostView.nhn?blogId=chochila&logNo=40144022678

유익한 정보 감사합니다~