표준 편차란 무엇일까?
표준 편차란, 평균(mean) 에 대한 오차이다.
즉, 실제 데이터 값이 평균을 기준으로 할때 얼마나 기복이 있는지 를 나타내는 것이다. 평균이 m이고, 표준편차가 3이라고 할때, 실제 값은 m+-3 값이라는 것이다.
편차는 원래의 값에서 평균을 뺀 값인데, +도 될 수 있고, -도 될 수 있다.
그러면 우리가 구하고자 하는 표준편차라는 것은 평균 값이 실제 값에서 부터 얼마나의 오류가 있느냐 인데 원하는 결과가 나오지 않는다.
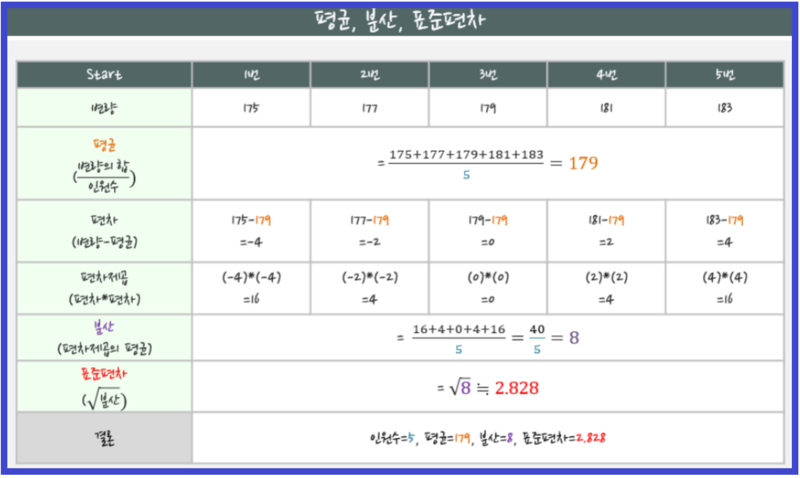
ex) 4개의 데이타가 있을 때 평균을 m이라고 가정하고, 각 값이 m+1, m-2, m+3, m-4 라고 할때 :
▶ 편차의 합은 실제로 1+2+3+4=10 이 되야 하지만, 실제 값이 -2,-4 가 있기 때문에, (값-m)을 합한 값으로 계산해보면 1-2+3-4로 전혀 엉뚱한 값이 나온다.
그러므로 이 음수를 양수화해야 하고, 그러한 방법중의 하나가 제곱이다.
각 편차들을 제곱을 해서 합하면 1+4+9+16이된다. 이것이 바로 분산(Variance)으로 "편차의 제곱의 합"이다.
분산(Variance)을 바로 쓰지 않고, 표준편차를 구하는 이유는?
분산은 편차에 제곱을 하여 계산을 하였기 때문에, 실제 값에서 너무 멀어져 있다. 그래서 실제 값으로 근접 시키기 위해서 제곱근(루트)를 씌워준 것이다. (분산에서 제곱했으니, 반대로 제곱근을 씌운다!)
즉 분산에 루트를 씌운것이 표준 편차(Standard deviation) 이며, 이 표준편차는 평균으로 부터 원래 데이타에 대한 오차범위의 근사값이다. (원래 데이타로 부터의 오차의 범위는 편차의 절대값들에 대한 평균값으로 절대편차라고 하며 Absolute deviation, 표준 편차와 값이 다소 다르지만, 평균값으로 부터의 얼마나 오차가 있는지를 표현한다는 의미에서는 같다. 그러면 왜 절대편차를 사용하지 않고 표준 편차를 사용하는가는 다른 글에서 다루도록 한다. 결론만 말하자면, 제곱을 한 표준편차가 모델링과 각종 통계 수식을 응용하기에 용이하다)
여기서 평균, 분산, 표준편차의 모집단과 표본의 개념을 짚고 넘어갈 필요가 있다.
통계학이란 굳이 다 조사하지 않더라도, 대략 결과를 예상할 수 있다. 일종의 prediction 의 개념이다.
조사대상인 모집단(population) 전체를 조사하는 경우를 전수조사라고 한다.
모집단이 커서 전수조사가 어려운 경우, 집단의 특성을 추정하기 위해서 일부 표본(sample)만 추출하여 하는 조사를 표본조사라고 한다. 이렇게 표본을 조사함으로써, 원래 모집단의 특성을 추측하는 것을 추정이라고 한다. (근대 통계학의 추론통계학 - inferential statistics의 개념)
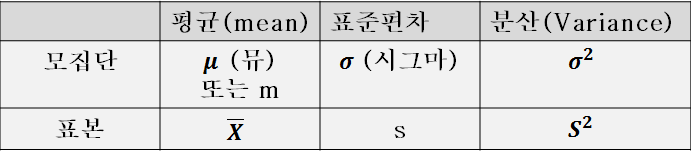
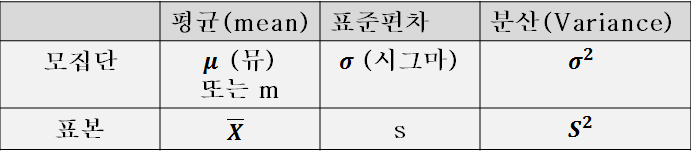
평균,표준편차,분산에 대해서 이것이 모집단에 대한 값이냐 표본에 대한 값이냐를 구별하기 위해서 기호를 분리 따로 사용하는데 하기 표와 같다.
표본 평균은 사실 고정값이 아니라, 표본의 크기에 따라 변화는 일종의 확률변수이다.
출처: https://bcho.tistory.com/972 [조대협의 블로그]
http://m.blog.naver.com/dalsapcho/20147545698
https://www.youtube.com/watch?v=b3O-dUlyl54
http://math7.tistory.com/14
http://ko.wikipedia.org/wiki/%EB%B6%84%EC%82%B0
